
深度学习模型大小与模型推理速度的探讨
导读
作者:田子宸,毕业于浙江大学,就职于商汤,文章经过作者同意转载。
前言
常用的模型大小评估指标
1. 计算量

2. 参数量
3. 访存量

4. 内存占用
5. 小结
计算量越小,模型推理就越快吗
计算密度与 RoofLine 模型
计算密集型算子与访存密集型算子
推理时间
1. 计算密度与 RoofLine 模型
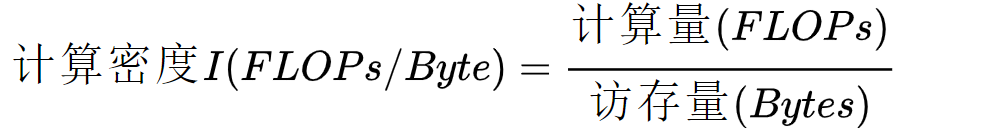
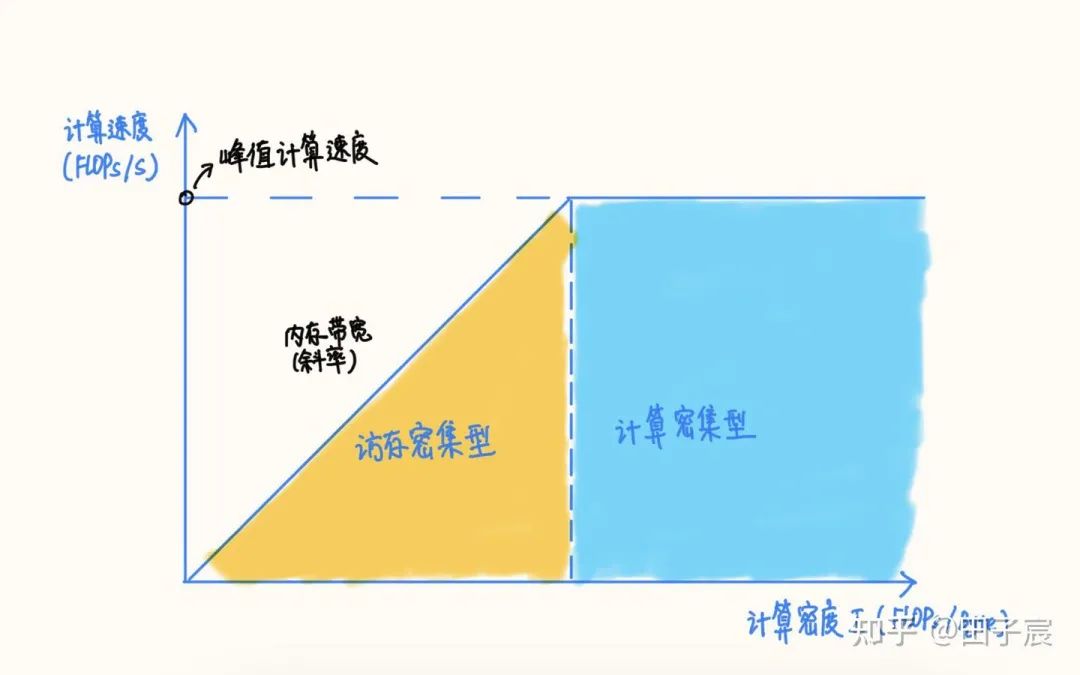 RoofLine 模型
RoofLine 模型
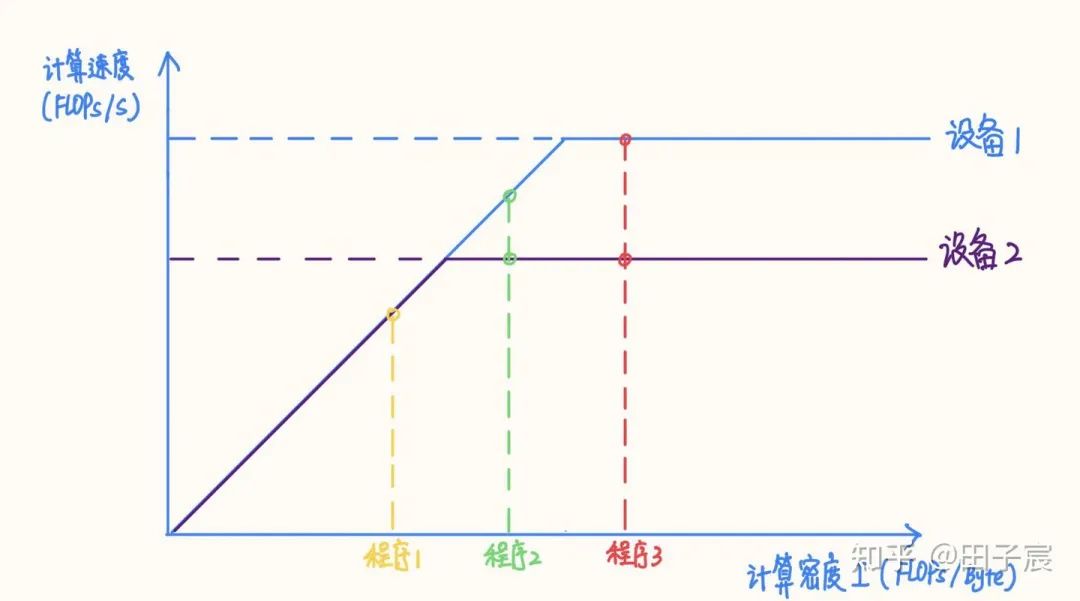
2. 计算密集型算子与访存密集型算子

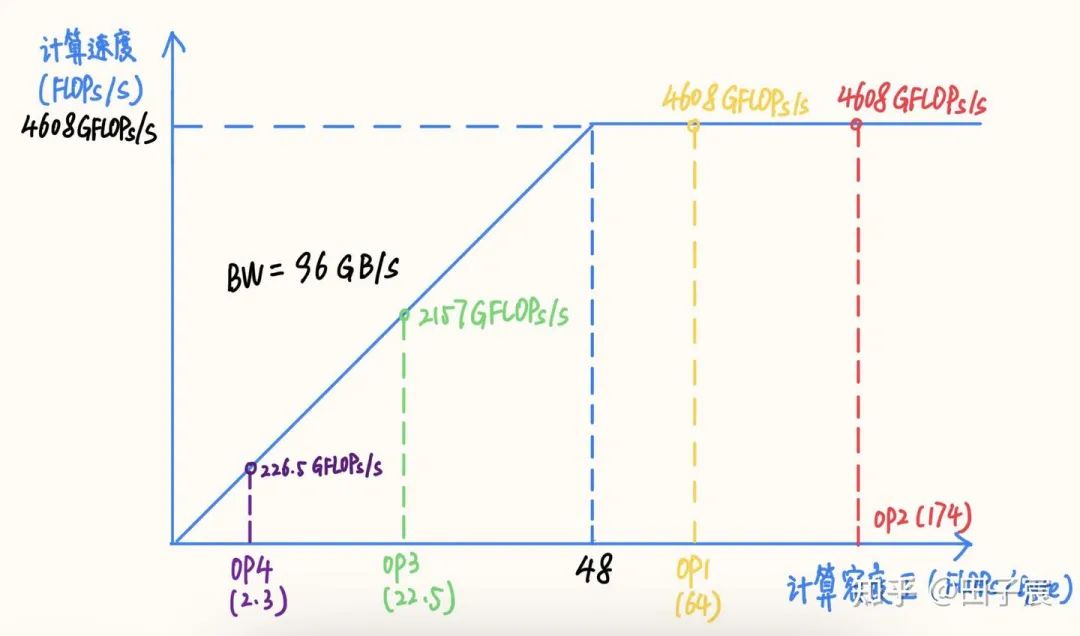
3. 推理时间




4. 小结
影响模型推理性能的其他因素
1. 硬件限制对性能上界的影响
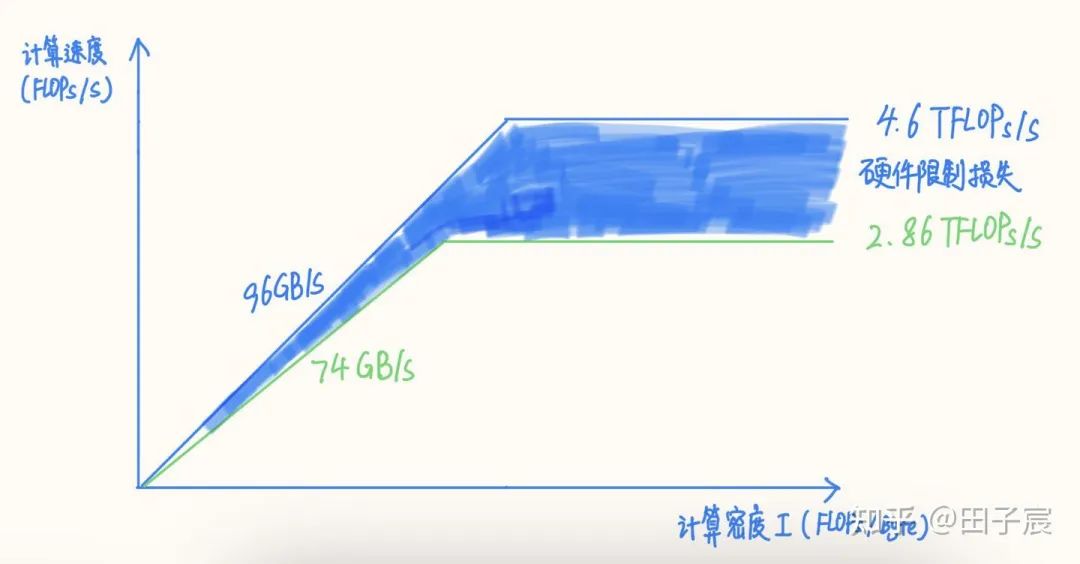
2. 系统环境对性能的影响
3. 软件实现对性能的影响
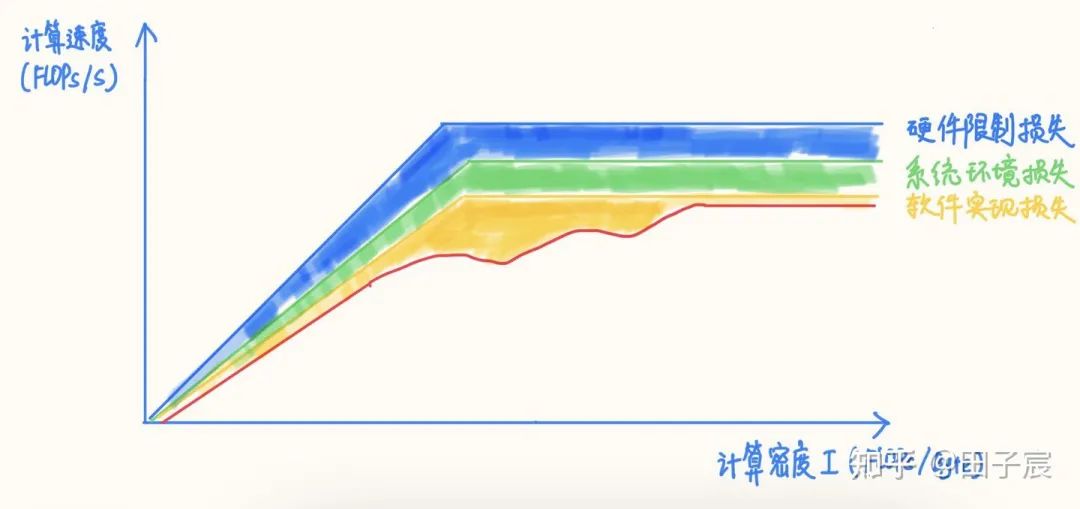
对于一些访存非常密集且访存 pattern 连续的算子,如 Concat、Eltwise Sum、ReLU、LeakyReLU、ReflectionPad 等,在 Tensor 数据量很大的情况下,软件实现的损失会非常小,正常情况下基本都能达到内存带宽实测上限;如果框架采用了融合策略的话,基本可以达到 0 开销。
对于 Conv/FC/Deconv 等算子,在计算密度很高的情况下,大多数框架是能够很接近算力峰值的。但对于计算密度不是特别高的 case,不同框架的表现不一,需要实测才能确定。不过从大趋势而言,都是计算密度越高,硬件的利用率越高的。
尽量使用常用的算子参数,例如 Conv 尽量使用 3x3_s1/s2,1x1_s1/s2 等,这些常用参数往往会被特殊优化,性能更好。
4. 小结
面向推理速度的模型设计建议
了解目标硬件的峰值算力和内存带宽,最好是实测值,用于指导网络设计和算子参数选择。
明确测试环境和实际部署环境的差异,最好能够在实际部署环境下测试性能,或者在测试环境下模拟实际部署环境。
针对不同的硬件平台,可以设计不同计算密度的网络,以在各个平台上充分发挥硬件计算能力(虽然工作量可能会翻好几倍【捂脸)。
除了使用计算量来表示/对比模型大小外,建议引入访存量、特定平台执行时间,来综合反映模型大小。
实测是最准确的性能评估方式,如果有条件快速实测的话,建议以实测与理论分析相结合的方式设计并迭代网络。
遇到性能问题时,可以逐层 profiling,并与部署/优化同学保持紧密沟通,具体问题具体分析(适当了解一下计算相关理论的话,可以更高效的沟通)。
对于低算力平台(CPU、低端 GPU 等),模型很容易受限于硬件计算能力,因此可以采用计算量低的网络来降低推理时间。
对于高算力平台(GPU、DSP 等),一味降低计算量来降低推理时间就并不可取了,往往更需要关注访存量。单纯降低计算量,很容易导致网络落到硬件的访存密集区,导致推理时间与计算量不成线性关系,反而跟访存量呈强相关(而这类硬件往往内存弱于计算)。相对于低计算密度网络而言,高计算密度网络有可能因为硬件效率更高,耗时不变乃至于更短。
面向推理性能设计网络结构时,尽量采用经典结构,大部分框架会对这类结构进行图优化,能够有效减少计算量与访存量。例如 Conv->BN->ReLU 就会融合成一个算子,但 Conv->ReLU->BN 就无法直接融合 BN 层
算子的参数尽量使用常用配置,如 Conv 尽量使用 3x3_s1/s2、1x1_s1/s2 等,软件会对这些特殊参数做特殊优化。
CNN 网络 channel 数尽量选择 4/8/16/32 的幂次,很多框架的很多算子实现在这样的 channel 数下效果更好(具体用多少不同平台不同框架不太一样)。
框架除了计算耗时外,也处理网络拓扑、内存池、线程池等开销,这些开销跟网络层数成正比。因此相比于“大而浅”的网络,“小而深”的网络这部分开销更大。一般情况下这部分开销占比不大。但在网络算子非常碎、层数非常多的时候,这部分开销有可能会影响多线程的扩展性,乃至于成为不可忽视的耗时因素。
除了优化网络结构、推理框架性能外,还可以考虑通过一些其他工程技巧来提升系统整体的性能。例如:对推理服务流水化,并行数据读取与计算的过程,掩盖 IO 延时。
看到评论区有人问有没有访存量小的模型结构。一些研究工作,例如 ShuffleNetV2, 已经在设计网络的时候兼顾访存量了。但据我所知目前还没有像 DepthWise Conv 一样经典的节省访存量的模型结构。
关于这个问题,我个人是这么看的:
1. 访存量可以减小,但网络精度很难保证不变,因此需要一系列的研究来探索
2. 一些白给访存量的技巧可以用上,一些白白浪费访存量的操作不要搞
3. 低精度/量化有的时候节省访存量的意义远大于节省计算量
回顾 Xception/ MobileNet 的研究就可以看出,DWConv 3X3 + Conv 1X1 的结构之所以成为经典结构,一方面是计算量确实减少了,另一方面也是其精度确实没有太大的损失。计算量可以在设计完网络时就可以算出,但网络精度只有在网络训练完之后才能评估,需要花费大量的时间与精力反复探索才能找到这一结构。
一些研究确实开始关注访存量对推理速度的影响,例如 ShuffleNetV2 在选定 group 的时候就是以访存量为依据的,但并不是整体的 block 都是围绕降低访存量来设计的。由于本人很久没有关注算法的研究进展了,据我所知目前是没有专注于减少放存量的模型结构及研究工作的(如果有的话欢迎在评论区留言)。
我个人认为这可以成为一个很好的研究主题,可以为模型部署带来很大的帮助。一种方法是可以通过手工设计网络结构,另一种方法是可以将访存量作为 NAS 的一个参数进行搜索。前者可解释性更强一些,后者可能研究起来更容易。但是有一点请务必注意:降低访存量的最终目的一定是为了减少模型的推理时间。如果模型处在目标设备的计算密集区,降低访存量的意义有限。
关于实际工程部署,有一些技巧/注意的点可以保证不浪费访存量:
1. channel 数尽量保持在 4/8/16/32 的倍数,不要设计 channel = 23 这种结构。目前大部分推理框架为了加速计算,都会用特殊的数据排布,channel 会向上 pad。比如框架会把 channel pad 到 4 的倍数,那么 channel = 23 和 24 在访存量上其实是一致的。
2. 一些非常细碎乃至毫无意义的后处理算子,例如 Gather、Squeeze、Unsqueeze 等,最好给融合掉。这种现象往往见于 PyTorch 导出 onnx 的时候,可以尝试使用 onnxsim 等工具来进行融合,或者手动添加大算子。
3. 尝试一些部署无感的技巧,例如蒸馏、RepVGG(感谢
@OLDPAN
)等。
最后想聊一下低精度/量化。对于设备算力很强但模型很小的情况,低精度/量化我个人认为其降低访存量的作用要远大于节省计算量,可以有效加快模型推理速度。但是要注意两点:一个是框架如果不支持 requant,而是每次计算前都量化一次,计算完之后再反量化,那么使用低精度/量化反而会增加访存量,可能造成推理性能的下降;另一个是对于支持混合精度推理的框架,要注意不同精度转换时是否会有额外的性能开销。如果有的话,要尽量减少精度的转换。
END

你的每一个“在看”,我都当成了喜欢
▼