本文约8000字,建议阅读15+分钟
本次分享将着重介绍如何利用美团大脑中已建设的商品图谱,发挥知识数据的价值,提供更加精准的商品理解能力。
美团大脑是正在构建中的全球最大的生活服务领域知识图谱。随着美团新零售场景的扩展,美团大脑中围绕商品领域的知识图谱逐步建立,并广泛应用于搜索、推荐、广告和运营等场景。
本次分享将着重介绍如何利用美团大脑中已建设的商品图谱,发挥知识数据的价值,提供更加精准的商品理解能力。- 在模型探索方面,我们将介绍基于知识增强的商品理解模型,通过多阶段知识增强,提升模型准确性和泛化性。
- 在模型训练方面,我们将分享一些样本治理方面的经验和心得,以更加高效、低成本的方式提升模型能力。
由此所建立的更加精准的商品理解能力,一方面会应用于搜推等下游场景,另一方面也会反哺到商品图谱的数据建设,通过已有知识不断提升自身,伴随业务一同成长。美团大脑是正在构建中的全球最大的生活服务领域知识图谱,用人工智能技术赋能业务,改进用户体验。我们希望帮大家吃得更好,生活更好。美团大脑包含了餐饮、商品、药品、酒旅、到综、常识等各领域的图谱。接下来将主要介绍美团在新零售场景下利用知识图谱进行商品理解。
美团的新零售场景包含:美团外卖、闪购、买菜、优选、团好货、快驴、买药,逐步实现了“万物到家”的愿景。在此场景下,商品数量更多、覆盖领域更宽,如生鲜/果蔬、鲜花/绿植、酒水/冲调等,但是我们可以显式地利用的信息很少(标题、图片)。我们需要从这些信息中抽取出结构化数据(如品牌、口味、产地等)和商品之间的上下位信息,才可以将它们更好地赋能于下游应用,包括搜索中的精确筛选以及无结果的扩召回。总而言之,美团的新零售场景更加依赖知识图谱,所以商品知识图谱在新零售领域发展之初就着手构架。
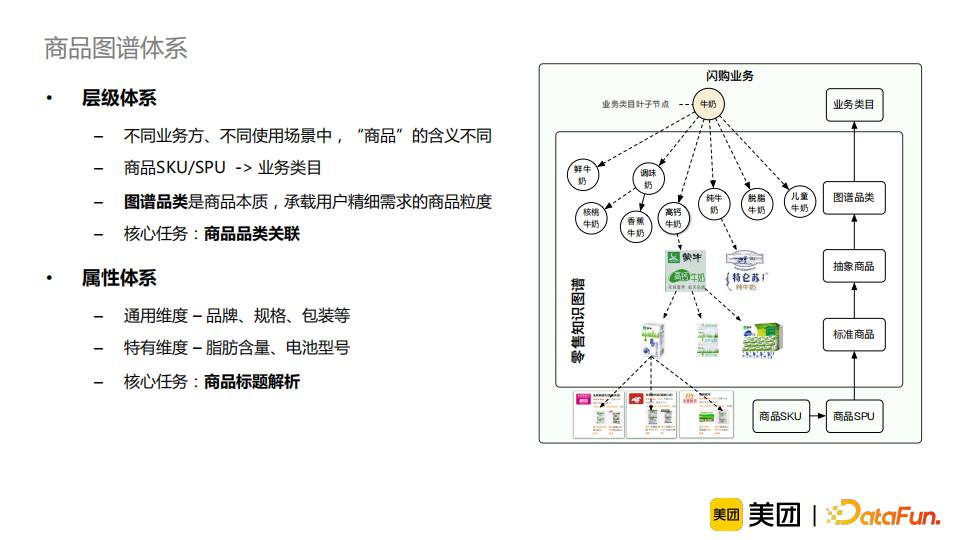
商品知识图谱分为层级体系和属性体系。层级体系用于解决不同业务方、不同使用场景中,“商品”的含义不同的问题。最细粒度的层级是商品的SKU/SPU,如“蒙牛高钙牛奶500ml”;最粗粒度的层级为业务类目,例如“牛奶”、“饮品”、“乳品”。其中,图谱品类是非常重要的层级,它是商品的本质,是承载了用户精细需求的商品粒度,例如“高钙牛奶”、“纯牛奶”等。构建图谱品类的核心任务是做商品的品类关联。属性体系包含如品牌、规格、包装等通用维度属性,以及如脂肪含量、电池型号等特有维度的属性。它的核心任务是做商品标题解析,因为大部分商品标题都包含了丰富的属性信息。
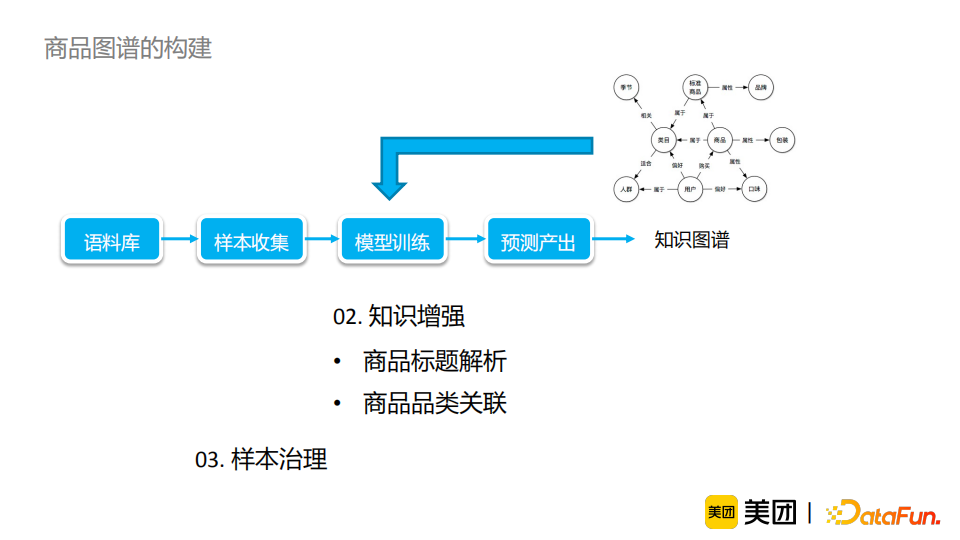
商品知识图谱的构建流程如上图所示。大致的流程为:构建语料库->样本收集->模型训练->预测产出->生成知识图谱。在构建出知识图谱之后,我们还可以使用沉淀出的知识来进一步增强模型,使得模型能够构建出更好的知识图谱。整个流程中最核心的两个模块是样本收集和模型训练。接下来会着重介绍模型训练中知识增强的相关技术以及样本收集阶段有关样本治理的工作。首先,来介绍一下“商品标题解析”。商品的标题一般会包含品牌、品类等有意义的信息。对标题信息的识别可以建模为实体识别任务。我们首先使用bert+CRF做了实体识别任务的baseline,得到了一些相对有意义的结果。但是,这一方法存在以下问题:
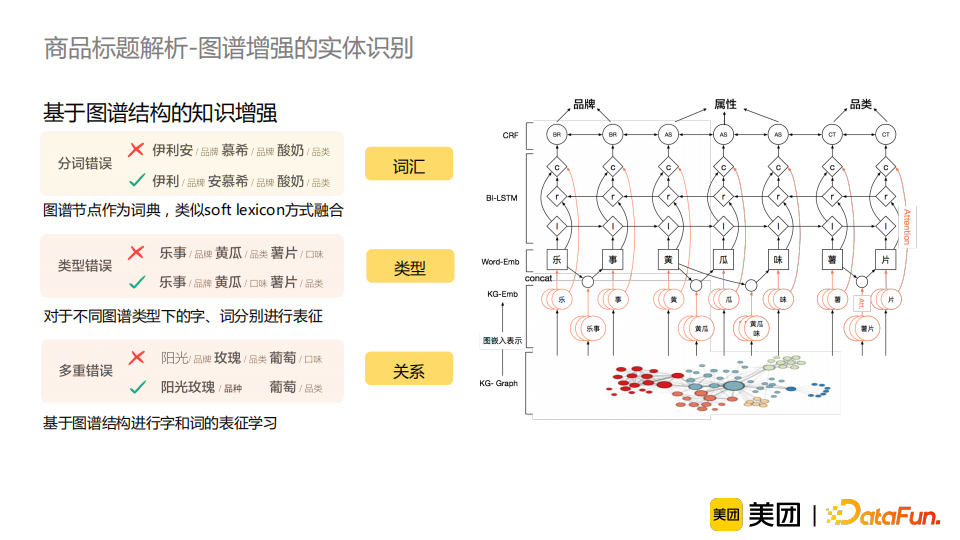
- 商品中品类、品牌垂域特有的词汇较多。如“伊利”“安慕希”“酸奶”这一例子,若模型没有见过“伊利”、“安慕希”这一类词汇,它很难对标题做出正确的切分;
- 消歧需要依赖常识知识。比如“乐事”“黄瓜”“薯片”这一例子,“黄瓜”可以是一个品类或者是一个口味,这需要知识来辅助模型进行正确地消歧;
- 标注数据少且含有较多噪音。这是因为实体识别任务标注难度较大,所以样本中难免包含错误信息。这就意味着我们的模型不能仅仅依赖标注的数据来进行实体识别任务,还应适当地引入外部的知识作为辅助。
已有一些方法可以通过外部词汇信息来提升实体识别的效果。Soft lexicon通过外部语料进行预训练得到字向量,然后通过每一个字来确定相关词汇,随后将每一个相关词汇通过其在句子中的位置进行分桶。同一个桶内的词汇会进行聚合操作,不同桶的词汇会进行拼接。最后,将处理完毕的向量进行编码传入如transformer、bi-lstm等模型。这一方法可以将外部词汇信息融入至模型中。LexBert不仅使用了词汇信息,还使用了词汇的类型信息。它将识别出的词汇和其对应的词汇类型在原文本中进行标记,或者将标记的词汇使用位置编码的方式拼接在原文本之后,对应的编码与原文本的词汇进行对齐。通过上述简单的处理方式,LexBert将词汇和类型信息引入到模型中。此外还有其他词汇增强类模型,不再一一赘述。
经过实验,我们发现上述方法对实体识别的效果仅有有限的提升。这是因为在我们的场景中:(1)词汇歧义问题严重;(2)商品标题短,使得它提供的有用信息较少;(3)标注数据少且存在噪声,无法有效地对引入的词汇进行消歧。因此,我们需要考虑引入更多的知识来帮助模型作出判断。我们提出了基于图谱结构的知识增强。对于词汇层面,我们借鉴了soft lexicon的做法,将图谱节点作为词典引入模型中;对于类型层面,我们分别对不同图谱类型下的字、词进行了向量表征,使他们在不同类型中具有区分性;此外,我们还考虑了图谱中包含的关系信息,将图谱中的实体与关系信息构造成一个图,采用图学习的方法将关系知识映射到字和词的向量表征中。最后,我们将这些信息在输入端进行融合。通过这种方式,我们缓解了词汇歧义问题,但是歧义问题并没有完全地被解决。
虽然我们在前述方法中将所有可以利用的外部知识都融入了模型中,但是模型并没有真正学习到这些额外知识。究其原因,是因为我们在构图、图学习以及信息融合阶段都会造成信息损失,而这些损失很难被衡量与控制。因此,我们考虑采用一种可解释可控的方法,并迎合工业级的产品要求,使得模型可以被在线干预,例如在发现一些bad case后可以改动一些配置来快速地解决一类问题。
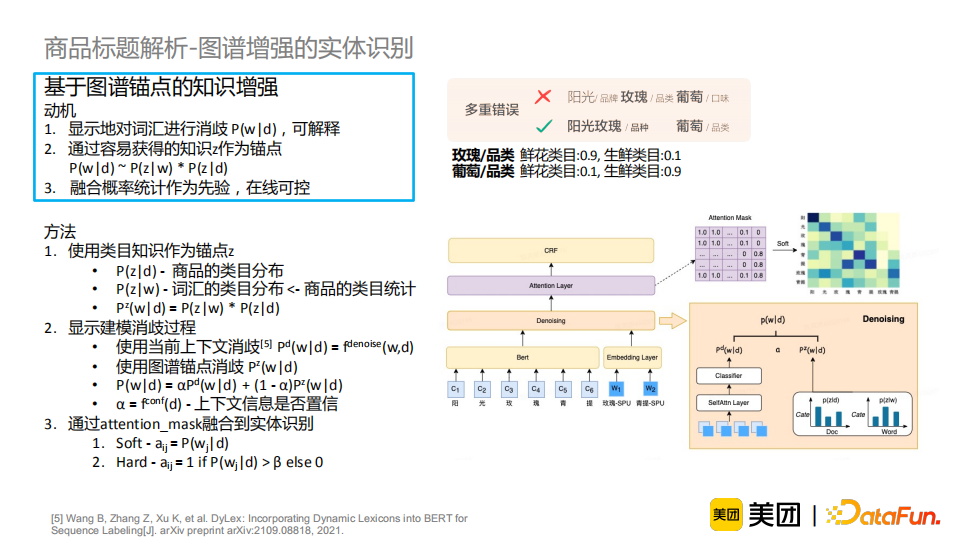
我们提出了基于图谱锚点的知识增强,其动机总结为以下三点:- 通过衡量在当前的商品下词汇的相关度,显式地对词汇进行消岐,使这个过程变得可解释;
- 通过融入容易获得的知识z作为锚点,计算商品到知识z的分布和词汇到知识z的分布,间接地得到商品与词汇的关联;
- 通过融合统计特征作为先验知识,达到在线可控的目的。例如对于一个新词或者发现一类有错误的词汇,我们可以通过改变其对应的统计特征来在线干预一类问题。
具体地,这里我们选择类目知识作为锚点。在实体识别任务中,类目是具有区分性的知识,例如“玫瑰”更可能在“鲜花”类目中出现,而“葡萄”更可能在生鲜类目中出现,那么我们通过类目就可以将“玫瑰葡萄”做一个区分。商品的类目可以通过商家运营或训练分类模型得到,也是商品图谱的一部分,并且这个过程相对容易,准确率也高。词汇的类目分布可以由商品的类目统计得到。通过将商品的类目分布与词汇的类目分布的乘积,我们就可以得到基于类目知识锚点的词汇与商品的相关性。随后,我们可以显式地建模消歧过程,这一模块分为两部分:基于上下文消歧和基于图谱锚点消歧。基于图谱锚点消歧的上面介绍过了。基于上下文消歧借鉴了DyLex的方法,使用上下文信息经过soft attention与一个分类器建模当前商品与词汇的相关性。两个相关性分数经过线性加权的方式进行融合,加权参数代表上下文信息的置信度(若上下文信息越置信,则参数越大,模型更偏向利用上下文信息)。最后我们通过attention_mask将相关性分布融入实体识别模型中,其中soft fusion直接使用相关性得分,hard fusion通过预先定义的阈值进行0-1化处理再进行使用。
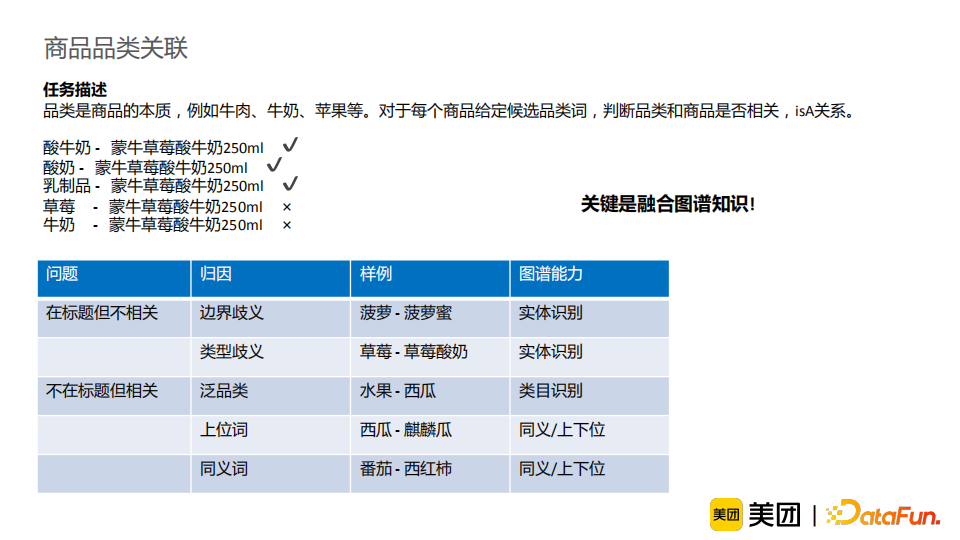
经过实验,我们发现若仅使用soft lexicon的方法融入词汇信息,实体识别的指标上升了1PP;使用LexBert额外融入词汇类型信息,指标提升了1.5PP;使用图谱结果融入词汇、类型以及关系信息后提升达到了2PP(但是无法做到在线更新,可解释性不足);基于图谱锚点的方法的性能提升最为明显,达到了4PP,而且它可以做到在线干预。通过上述方法的迭代,我们发现将知识产生影响的链路做得更加透明可以使得知识得到更有效的利用,模型变得更可解释,在线可控性强。它的优点在于我们可以更容易分析问题,知道模型的“天花板”在哪里;此外模型更容易更新,维护成本较低;最后,模型可以被快速地被干预,及时响应业务需求。下面介绍一下知识图谱在商品品类关联中的应用。商品品类是商品的本质,例如牛肉、牛奶、苹果等。对于每个商品,给定候选品类词,商品品类关联任务旨在判断品类和商品是否相关(isA关系)。比如“蒙牛草莓酸牛奶250ml”是一个酸牛奶、酸奶、乳制品,但不是一个草莓也不是一个牛奶。这个任务的难点可以分为两类。首先,两个不相关的词汇有字面上的包含关系,具有边界歧义或类型歧义。其次,两个相关的词汇字面上不相关,存在泛品类、上位词或者同义词关系。通过分析问题,我们发现以上问题都可以通过融合图谱知识进行解决,包括实体识别、类目识别、同义词/上下位关系识别等能力。于是,任务的重心就转变为如何利用图谱知识。
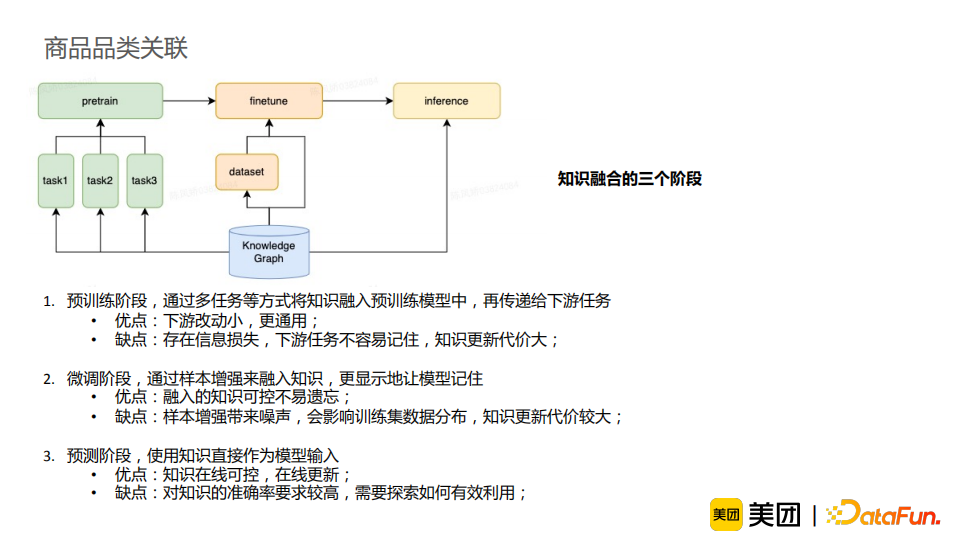
经过调研,我们总结了知识图谱融合的三个阶段。第一阶段是预训练阶段,它通过多任务等方式将知识融入预训练模型中,再间接地传递给下游任务。它的优点在于对下游任务改动较小,所以更加通用,但是它存在一定的信息损失,下游任务容易遗忘知识,且知识更新的代价很大(需要重新训练模型)。第二阶段是微调阶段,它通过样本增强的方法融入知识,更显式地让模型记住知识信息。它的优点在于融入的知识可控且不容易被模型遗忘,但是样本增强会引入噪声,影响训练数据的分布,且知识更新的代价较大。第三阶段是在线/预测阶段,它使用知识直接作为模型输入。它的优点是知识在线可控,且可以达到在线更新的效果,但是这一方法对知识的准确率要求高,需要探索如何有效利用外部知识。
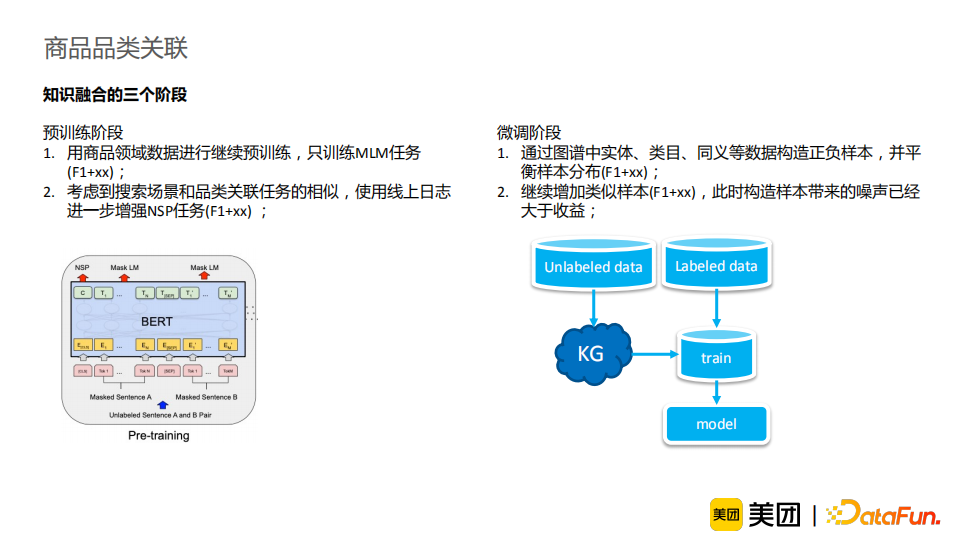
在预训练阶段,我们引入了商品领域的数据进行对bert预训练。这里我们只采用了MLM任务,得到了1.4PP的提升。此外,考虑到搜索场景和品类关联任务的相似性,我们使用线上点击日志进一步增强NSP任务,得到了0.5PP的提升。在微调阶段,我们通过图谱中实体、类目、同义词等数据构造正负样本,并平衡样本分布,得到了2.6PP的提升。但是继续增加类似的样本对效果提升不大,这是因为此时继续构造样本带来的噪声已经大于收益。
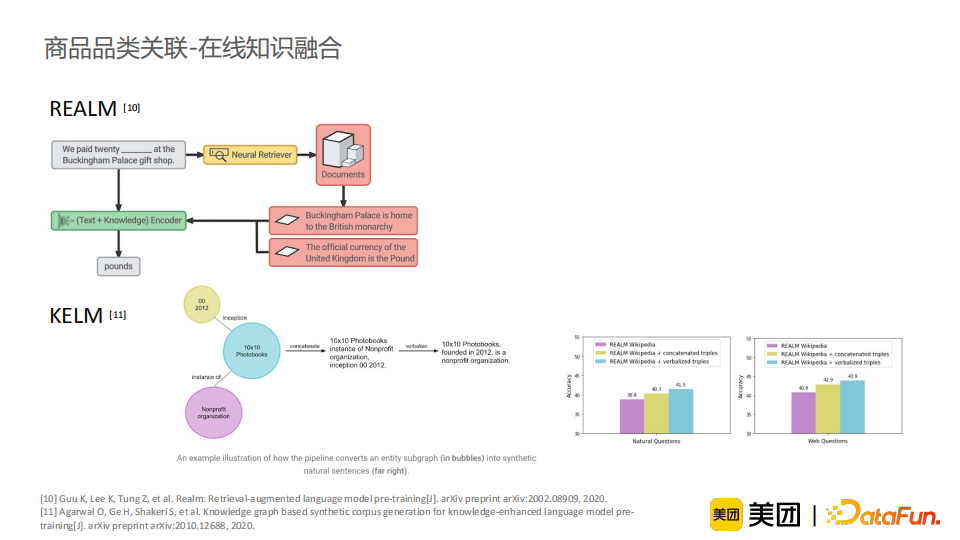
接下来,我们考虑了在在线阶段进行知识融合的方法。工业界与学术界已经有类似的方法,比如Google在2020年提出了REALM,它针对的是QA任务。首先,它会对query进行向量检索,找到相关文档;随后,它将相关文档进行拼接,通过文本抽取的方式得到最后的答案。此外,KELM模型融合了一个外部知识库,将知识库中的相关知识对预设的模板进行填充,再使用语言模型进行润色,得到更多样性的知识表征。
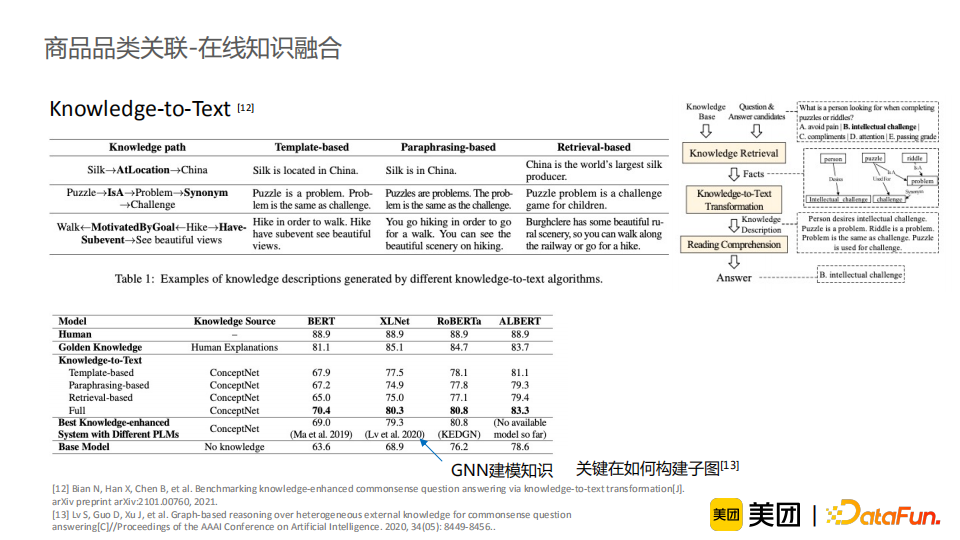
Knowledge-to-Text方法将上述两个方法进行了融合,同时考虑了模板拼接与文档检索。实验结果表明使用模板拼接的方法已经可以取得较好的结果,说明引入足够多的外部知识在QA任务中模型性能的提升帮助很大。此外,我们注意到,显式地将外部知识直接拼接为一个句子作为输入与采用GNN隐式建模知识的方法都可以得到相近的效果。也有研究指出通过GNN的知识建模方法的关键在于如何构建子图。
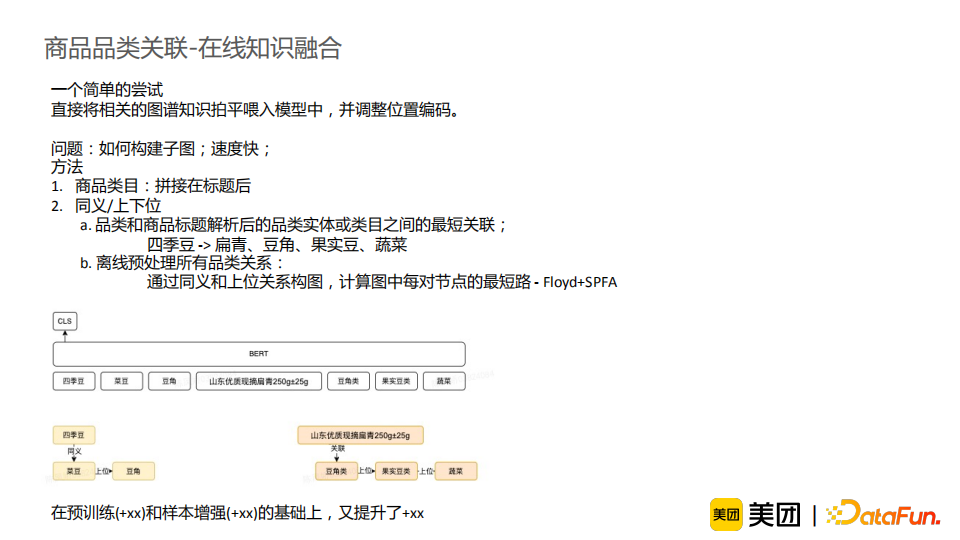
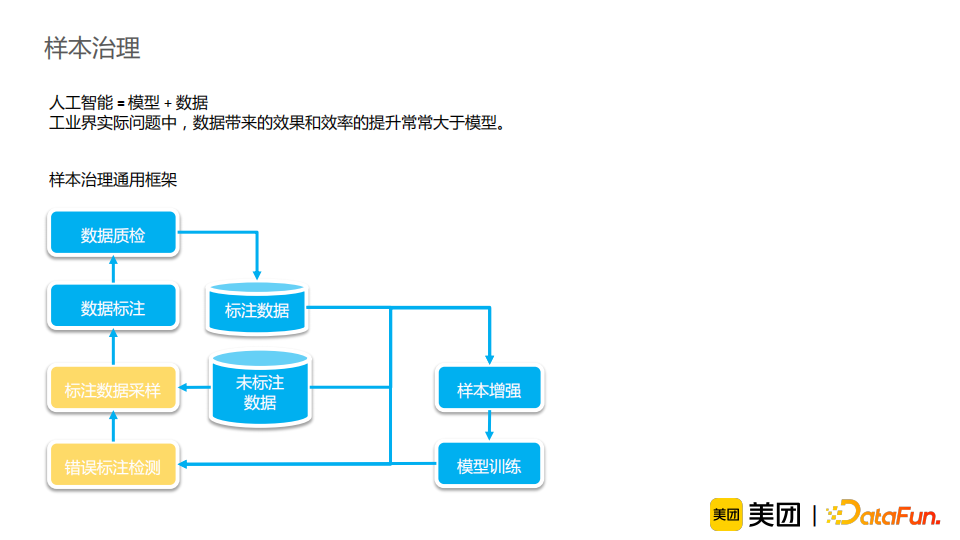
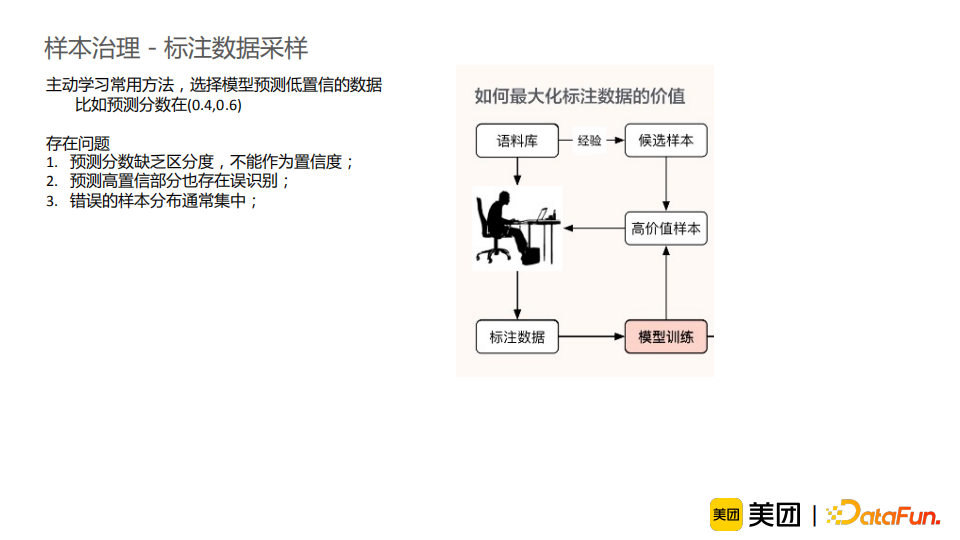
在商品品类关联任务中,我们借鉴了上述思路,直接将相关图谱知识拍平喂入模型中,并调整了位置编码。以上图例子来阐述我们的思路。商品的品类是“四季豆”,标题是“山东优质现摘扁青250g”,我们的目标是判断它们之间是否存在关联关系。我们面对的核心问题是如何构建子图,并由于我们需要在线进行知识融合,构建子图的速度需要足够快。我们考虑将商品类目的知识与同义词/上下位知识融入模型。前者较为简单,我们直接将商品类目在标题中识别并拼接在标题后即可。后者较为复杂,因为如果简单地将一“跳”的图谱上下位信息拼接在标题后是不足以对标题进行消歧的;但是如果将所有“跳”的图谱关系都融入输入,信息量过多且存在很多噪声。因此,我们选择融入品类和商品标题解析后的品类实体或者类目之间的最短关联路径组成的子图。具体地,我们通过同义词和上位关系进行构图,使用Floyd+SPFA算法计算每对节点的最短路径。为了达到快速地在线知识融合,我们离线预处理所有品类关系。通过这一方法,我们的模型效果在预训练与样本增强的基础上又进一步提升了1.4PP。这一结果让我们看到了在线知识融合的潜力,它可以更直接地将知识融入模型中,使得信息损失相对较少,并且能做到在线干预,是一个后期值得继续探索的思路。接下来,来介绍一下样本治理的相关工作。我们都知道人工智能的核心是模型+数据,二者缺一不可。在工业界实际问题中,数据带来的效果和效率的提升常常大于模型,所以我们很重视数据治理方面的经验积累。一个样本治理的通用框架如上图所示。首先我们从未标注的数据中采样一些数据进行标注,然后进行数据质检,生成标注数据,之后我们会通过样本增强的方法进一步优化样本,并使用它们进行模型的训练。由于训练数据并不一定保证百分之百准确,所以我们还需要在模型训练后进行错误标注检测,对标注错误的数据进行进一步采样与标注,从而形成一个正向循环,使得模型质量与样本质量进一步增强。在这个框架中,标注数据采样与错误标注检测模块十分重要。首先介绍标注数据采样。标注是有代价的,所以我们希望用尽量少的人力、尽量快的速度来最大化标注数据的价值。通常我们会使用主动学习的方法,选择模型预测低置信的数据来进行标注。例如对于分类问题,预测分数在(0.4,0.6)这一区间内的样本就被认为是低置信的数据。但是这一方法存在以下问题:(1)预测分数缺乏区分度,不能作为置信度,尤其是在使用预训练模型时,它给出的分数通常趋于极端,导致我们很难选择出低置信度的数据;(2)预测高置信部分也存在误识别,同时我们也更希望标注这些高置信度的错误样本;(3)错误的样本分布较为集中,导致我们在标注采样时很容易采样到很多相似的样本,造成标注冗余。
针对前述三个问题,我们设计了对于主动学习方法的改进思路。
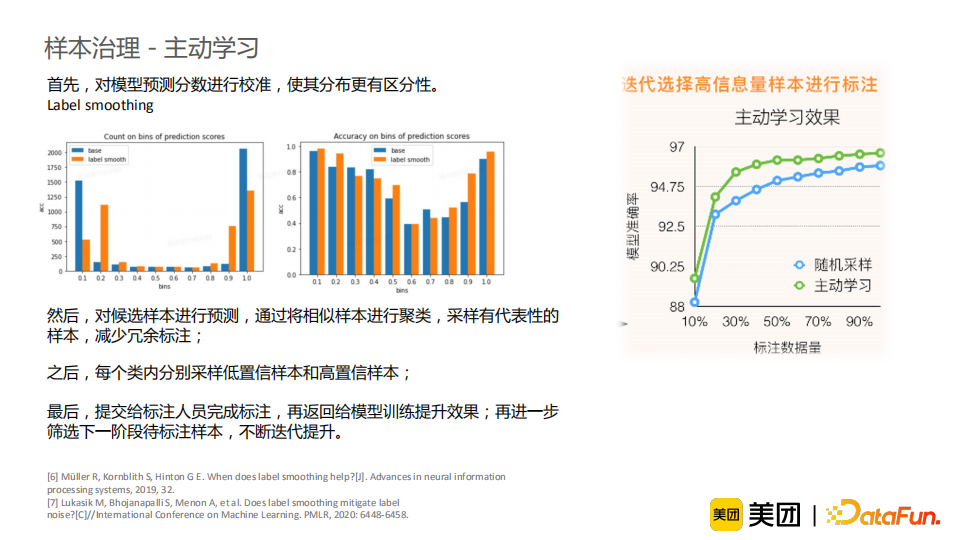
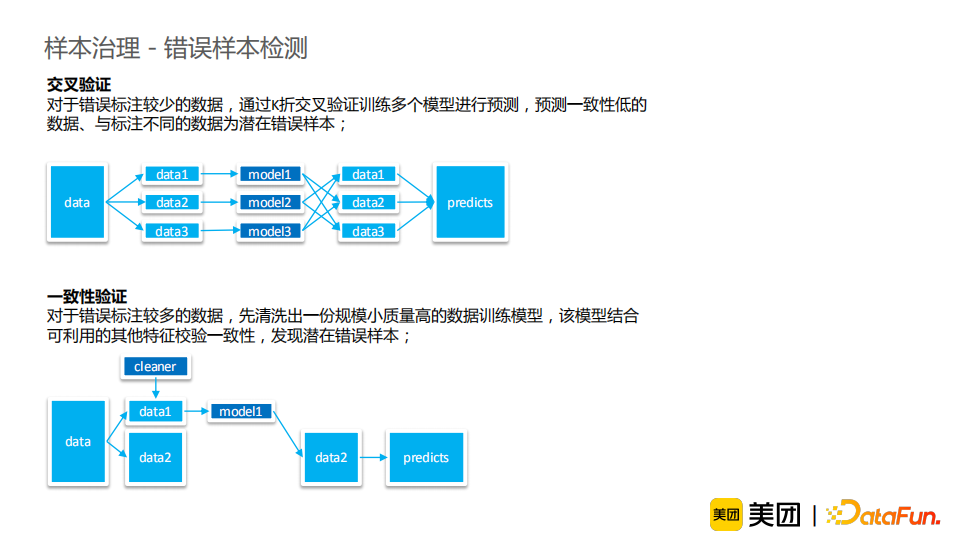
首先,我们对模型预测分数进行了校准,使得其分布更具有区分性。具体地,我们使用了label smoothing的方法,其理论解释较优雅且对模型侵入性低。校准后的数据相较于原始数据分布会向中间区间靠拢,并且更具有区分性。此外,label smoothing后依然位于高置信区间的数据的分类准确率也有了一定提升。然后,我们对候选样本进行预测,通过将相似样本进行聚类,采样有代表性的样本,从而减少冗余标注。对于每个类内的采样时,我们不仅会采样低置信样本,还会采样一些高置信的样本,使得高置信但识别错误的数据有一定几率被人工标注。最后,待标注的数据提交给标注人员完成标注,再返回给模型训练提升效果;之后再进一步筛选下一阶段待标注样本,不断迭代提升。从实验结果来看,我们使用少量的标准数据就可以达到相较于随机采样更好的模型准确率;并且,随着样本标注量的增长,主动学习的质量依然优于随机采样。虽然我们已经对数据进行了层层标注和质检,但是我们依然无法保证数据被百分之百地标注正确,所以我们需要对其进行进一步校验。对于错误标注较少的数据,我们可以通过K折交叉验证的方法训练多个模型进行预测,将预测一致性低的数据和与标注标签不同的数据作为潜在错误样本。对于错误标注较多的数据(极端情况下,错误样本数量比正确样本数量还要多),我们先清洗出一份规模小、质量高的数据来训练模型。之后将这一模型的预测作为label,结合其他可利用的特征,来验证剩余数据的一致性,发现潜在错误样本。通过这一方法可以纠正大部分错误标注,那么此时剩余的错误样本属于较难分辨的少量错误样本,可以使用交叉验证的方法做进一步校正。
首先,我们可以采用“遗忘次数”,即本轮识别正确但后续轮数识别错误的次数。有研究表明噪声样本是模型最容易遗忘的,因为模型无法记忆那些本身就是错误的少量样本。如上图分布图所示,红色柱状图即为错误样本的遗忘次数分布,绿色柱状图对应正确样本的遗忘次数,可以发现错误样本的遗忘次数明显高于正确样本的遗忘次数。因此,我们可以统计“遗忘次数”来区分噪声样本。对于多分类问题,我们还可以使用“置信学习”中的混淆矩阵进行进一步优化。因为对于多分类任务,模型往往会在个别类别中出现混淆,所以我们可以通过计算验证集上识别的混淆矩阵,有倾向地多采样易混淆类别之间的样本。此外,我们自己通过经验探索出基于多任务检测的错误样本检测方法。在单任务标注较少且样本错误很难被识别的情况下,我们可以通过多个相似任务的联合训练来辅助单任务检测出其样本中的错误标注。我们在实验过程中发现,通过多任务检测方法将单任务的样本识别并纠正后,单任务模型的训练效果甚至可以达到多任务联合训练的训练效果。在样本多样性充足的情况下(例如经过主动学习采样),这一过程相当于将多任务联合训练的知识融入了标注样本。- 知识增强:介绍了如何充分利用图谱知识丰富信息,并借助容易获取的知识来解决较难的任务。进一步地,我们将知识融合分为三个阶段,并进行相应使用的介绍。从结果来看,知识增强能有效提升模型效果,并使模型解释性更强,并且在线可控,适合工业界需求,其潜力仍待挖掘。
- 样本治理:介绍了标注数据采样和错误样本检测的经验和方法。模型与数据是缺一不可的,样本治理的工作应当受到重视并得到积累。
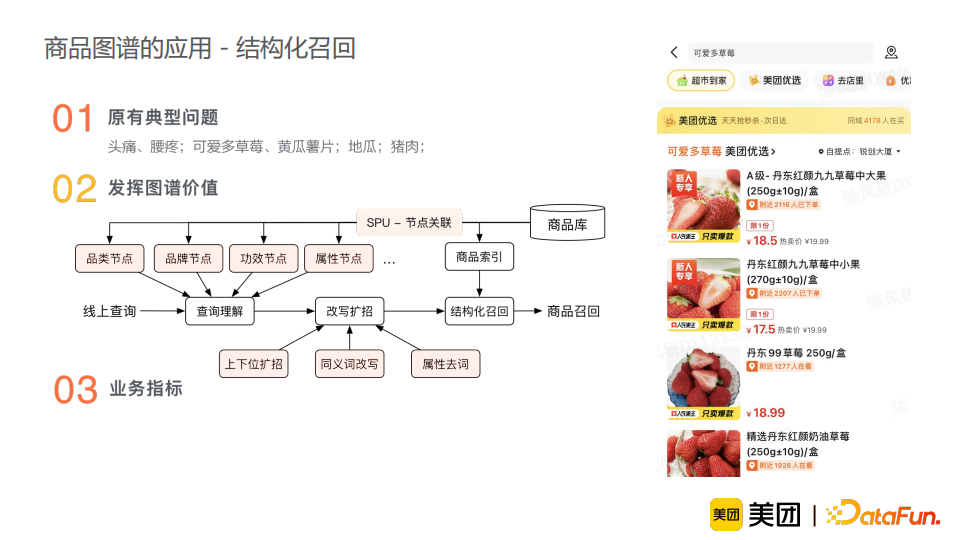
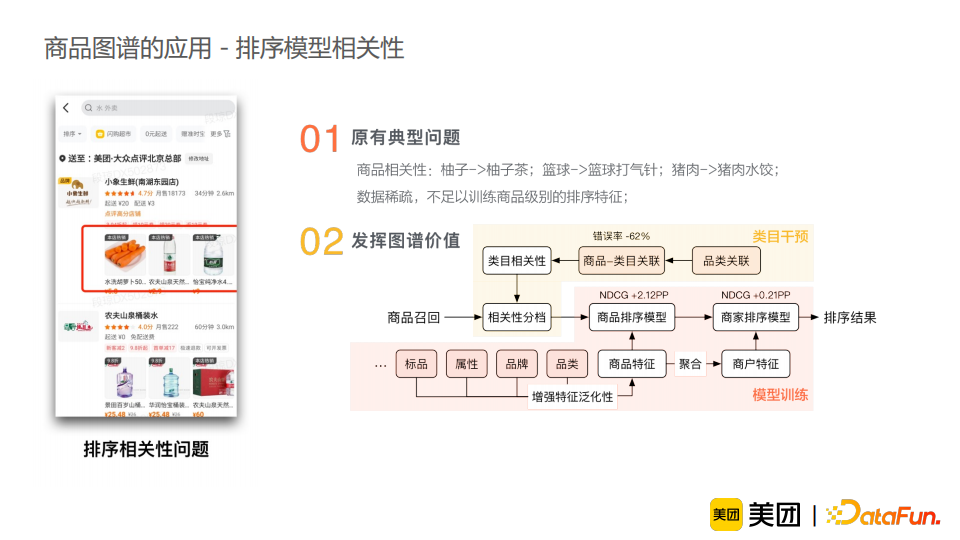
下面来简单介绍一些商品图谱的落地应用。商品图谱在商品优化专项之初就启动建设,其落地范围广泛,相关场景包括:数据治理、模型增强、产品优化、分析决策等。比如在搜索场景下,用户输入“可爱多草莓”这个query,模型可能会误识别为“草莓”这个品类,但实际上用户想搜索“可爱多冰激凌”,而“草莓”只是一个口味。这时,我们可以分别在查询理解端和数据检索端融入商品图谱知识,使模型正确识别出“可爱多”是一个品牌,“草莓”是一个口味,而用户搜索的重点在于“可爱多”冰激凌上。通过引入图谱知识,我们可以有效地降低不相关的误召回。相同的图谱知识还可以使用在排序模型的相关性上。比如用户搜索“水”,误召回会显示“水洗胡萝卜”。有可能“水洗胡萝卜”在召回过程中无法被完全过滤,但是我们可以通过排序将其放置在末尾,解决用户体验不好的问题。具体地,我们可以将图谱的品类信息融入排序特征中,从而使得品类不相关的商品的排序分数降低。
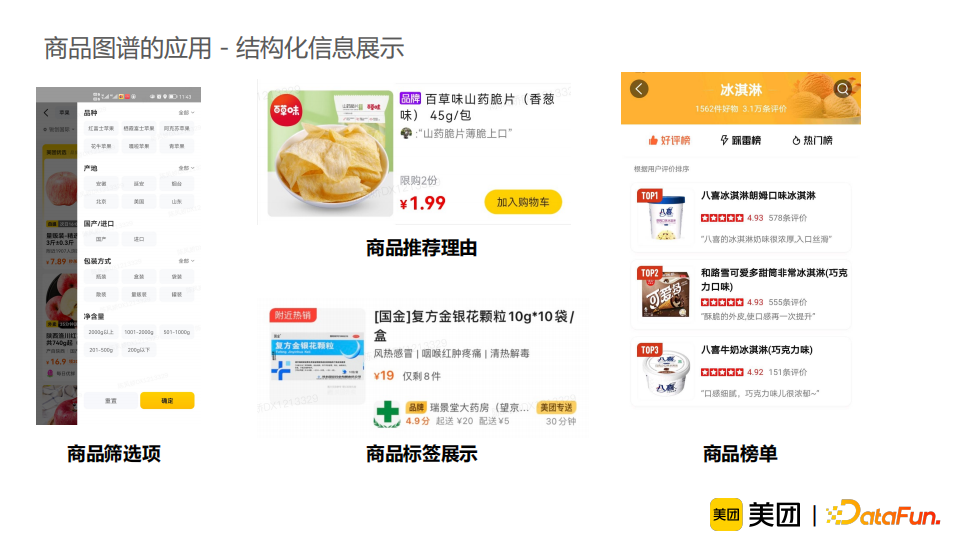
除了召回-排序链路,我们还将图谱知识融入商品结构化信息展示中,比如商品筛选项、商品推荐理由、商品标签展示、商品榜单等。
本次分享我们以美团大脑中的商品领域知识图谱为例,介绍了如何利用知识图谱数据实现更加精准的商品理解,从而更好的支持下游搜推应用,同时反哺知识图谱的进行更加准确的数据建设。从结果来看,知识增强能切实有效地提升模型效果,并使模型更可解释并且在线可控,适合工业界需求,其潜力仍待挖掘。
美团大脑是正在构建中的全球最大的生活服务领域知识图谱,除了商品领域以外,美团大脑也覆盖了餐饮、酒店、旅游等领域,我们后续也会就其他领域、其他技术方向,持续为大家分享美团在知识图谱方面的工作。美团大脑知识图谱团队大量岗位持续招聘中,实习、校招、社招均可,坐标北京/上海,欢迎感兴趣的同学加入我们,利用自然语言和知识图谱技术,帮大家吃得更好,生活更好。简历可投递至:chenfengjiao02@meituan.com。A:图谱中的关系是预先定义的。定义会参考对业务的理解设定。比如说,我们在图谱体系拆分为多个层级体系的原因之一是业务需求,它促使我们将商品分为不同粒度的层级。当然,我们还会根据商品的客观属性定义其他维度的关系。A:在我们的图谱体系中,由于商品SPU已经达到数十亿量级,所以它与商品的关联无法一个个进行人工审核。此时,我们会设置一些benchmark,并做定期的抽检来保证图谱的整体准确率在90%以上,关键数据可以达到95%。对于层级体系中品类与业务类目,它的数量并不是很多,并且由于它处于层级体系的上游,所以它的准确性对于下游任务十分重要。为了避免错误传递,我们会使用人工审核来确保高准确率。