
浙大图谱讲义 | 第一讲-知识图谱概论 — 第1节-语言与知识
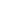
本讲义系列主要整理自浙江大学《知识图谱导论》(浙江省优秀研究生课程)的课程讲义。作为一门导论性质课程,该课程希望帮助初学者梳理知识图谱基本知识点和关键技术要素,帮助技术决策者建立知识图谱的整体视图和系统工程观,帮助前沿科研人员拓展创新视野和研究方向。
本次推文主要介绍讲义的“第一讲 知识图谱概论 第1节 语言与知识”,更多内容请点击文末“往期推荐”。
在这一讲中我们希望首先对知识图谱的来龙去脉做一个概论性的介绍,我们将首先从语言和知识两个视角阐明知识图谱是实现认知人工智能的关键一环,然后我们会追溯知识图谱的发展历史,来说明知识图谱不仅和人工智能有关系,而且具有非常强烈的互联网基因。
接下来我们希望全面的探讨知识图谱的广泛应用价值。同时,知识图谱也并非是一个抽象空洞的概念,它有自己非常明晰的技术内涵和技术边界。我们希望通过第一讲,让大家充分认识到不论是从人工智能、大数据、还是互联网的视角,知识图谱都是非常重要的技术发展方向。

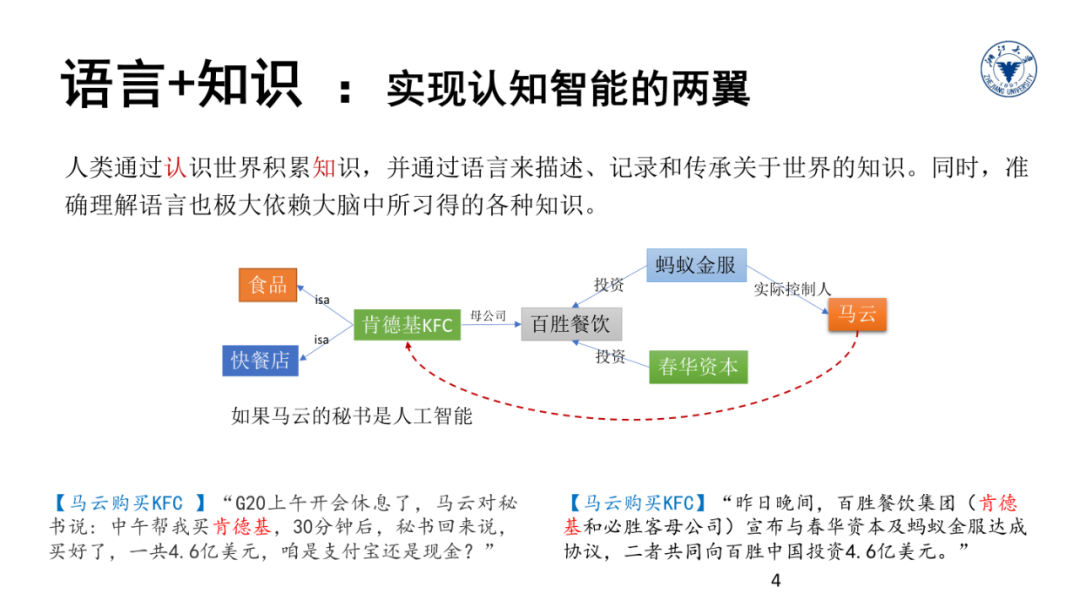
另外一个流派称为符号主义,主张智能的实现应该模拟人类的心智,即用计算机符号记录人脑的记忆,表示人脑中的知识等,即所谓知识工程与专家系统等。
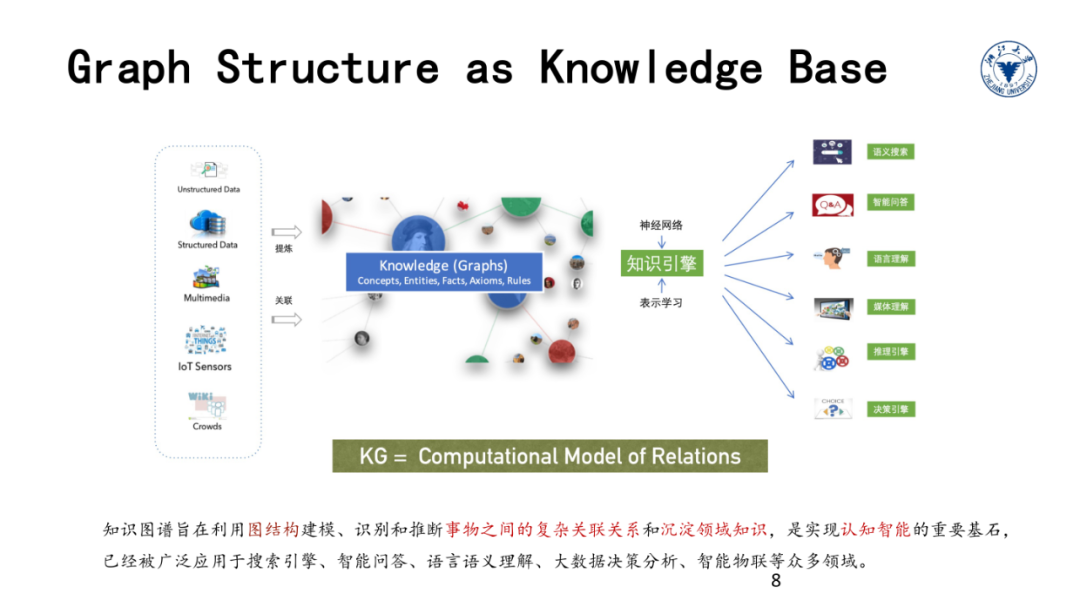
我们这门课的主角知识图谱可以归属于符号主义的流派。深度学习首先在视觉、听觉等感知任务中获得成功,本质上解决的是识别和判断问题,我们可以打比方为实现的是一种聪明的AI。但感知还是低级的智能,人的大脑依赖所学的知识进行思考、推理、理解语言等等。
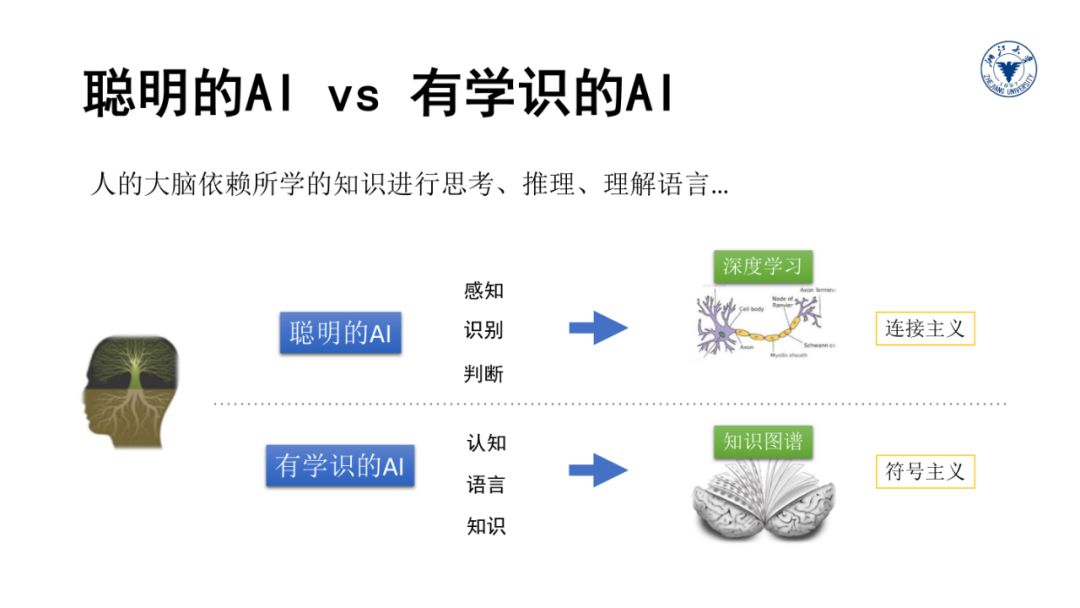
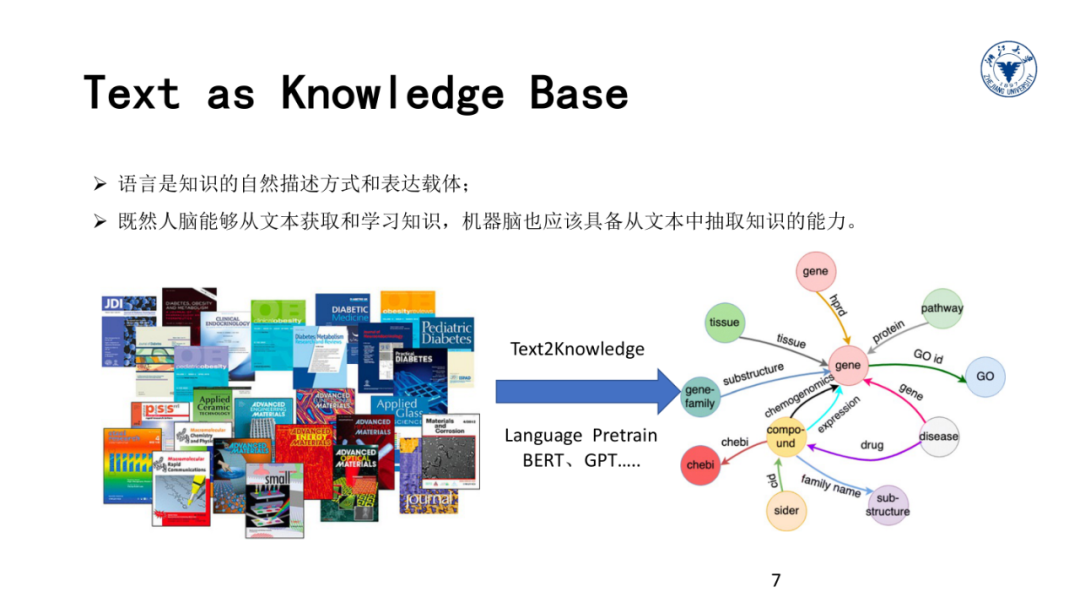
而语言则是知识最直接的载体,目前为止,人类的绝大部分知识都是通过自然语言来描述、记录和传承的。同时反过来,正确理解语言又需要知识的帮助。
事实上,我们每个人的大脑里面都有大量这种类型的关于万事万物的知识图谱,我们极大的依赖这些背景知识来准确理解语言和正确做出判断。

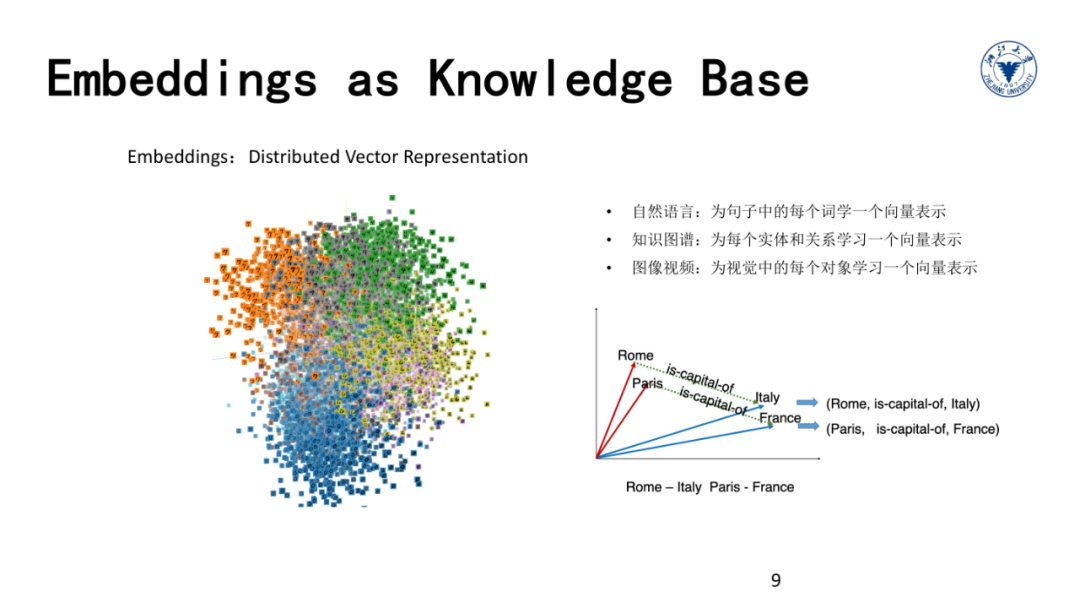
比如,我们在自然语言中,可以为每个词学一个向量表示,我们也可以为视觉场景中的每一个对象学习一个向量表示,为知识图谱中的每一个实体学习一个向量表示。我们通常把这些对象的向量化表示称为Embedding或“Distributed Vector Representation”。

# OpenKG开源系列 | 轻量级知识图谱抽取开源工具OpenUE
# Expert Systems With Applications | 基于级联双向胶囊网络的鲁棒三元组知识抽取
# ACMMM2021|在多模态训练中融入“知识+图谱”:方法及电商应用实践
# TASLP | 从判别到生成:基于对比学习的生成式知识抽取方法
# AZFT知识引擎实验室与AZDH智能药学实验室在顶刊Nucleic Acid Research发表合作论文

浙江大学知识图谱创新研究团队
评论