
深度学习中GPU和显存分析

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
何为“资源”
不同操作都耗费什么资源
如何充分的利用有限的资源
如何合理选择显卡
显存和GPU等价,使用GPU主要看显存的使用?
Batch Size 越大,程序越快,而且近似成正比?
显存占用越多,程序越快?
显存占用大小和batch size大小成正比?
0 预备知识
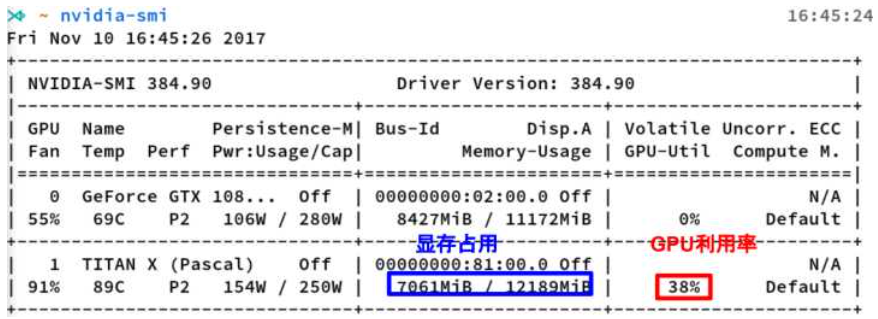
nvidia-smi的输出
显存占用
GPU利用率
watch --color -n1 gpustat -cpu
gpustat 输出
显存用于存放模型,数据
显存越大,所能运行的网络也就越大

1. 显存分析
1.1 存储指标

Type:有Int,Float,Double等
Num: 一般是 8,16,32,64,128,表示该类型所占据的比特数目
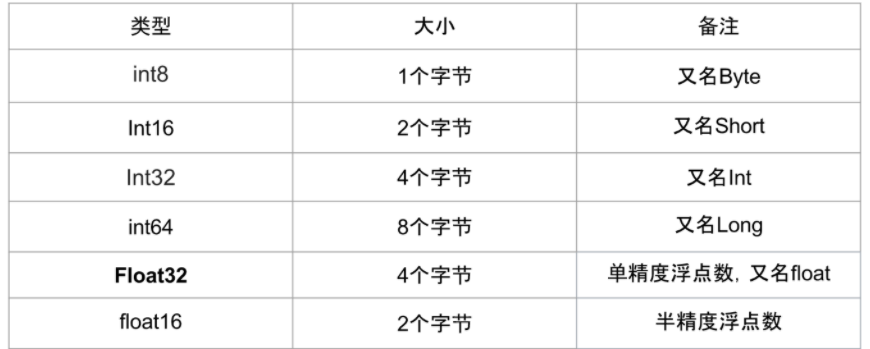
常用的数值类型

1.2 神经网络显存占用
模型自身的参数
模型的输出
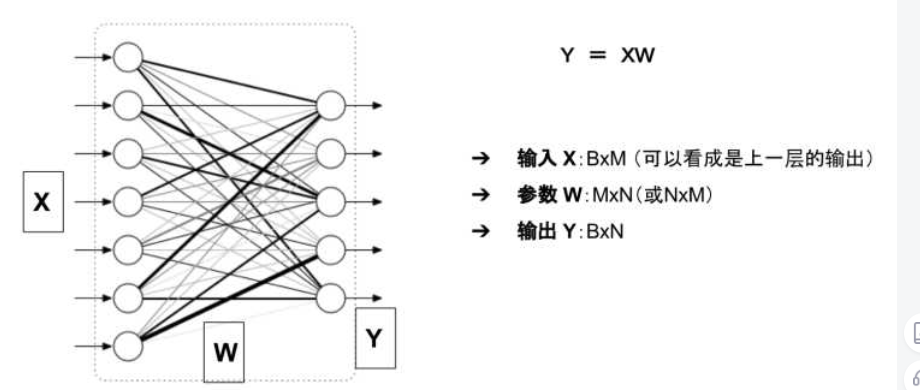
模型的输入输出和参数
参数:二维数组 W
模型的输出:二维数组 Y
1.2.1 参数的显存占用
卷积
全连接
BatchNorm
Embedding层
... ...
多数的激活层(Sigmoid/ReLU)
池化层
Dropout
... ...
Linear(M->N): 参数数目:M×N
Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K
BatchNorm(N): 参数数目:2N
Embedding(N,W): 参数数目:N × W
1.2.2 梯度与动量的显存占用

参数 W
梯度 dW(一般与参数一样)
优化器的动量(普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
1.2.3 输入输出的显存占用
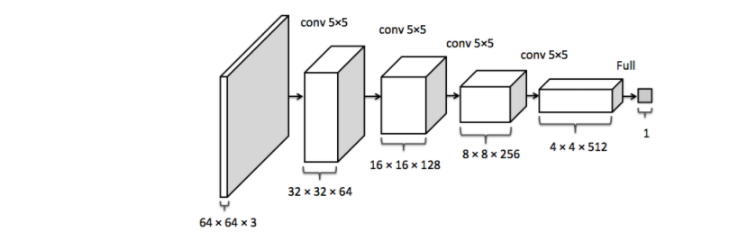
feature map
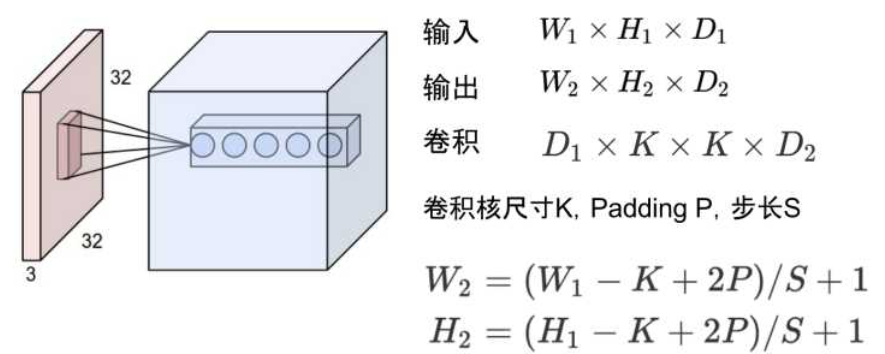
需要计算每一层的feature map的形状(多维数组的形状)
模型输出的显存占用与 batch size 成正比
需要保存输出对应的梯度用以反向传播(链式法则)
模型输出不需要存储相应的动量信息(因为不需要执行优化)
显存占用 = 模型显存占用 + batch_size × 每个样本的显存占用
输入(数据,图片)一般不需要计算梯度
神经网络的每一层输入输出都需要保存下来,用来反向传播,但是在某些特殊的情况下,我们可以不要保存输入。比如ReLU,在PyTorch中,使用
nn.ReLU(inplace = True)能将激活函数ReLU的输出直接覆盖保存于模型的输入之中,节省不少显存。感兴趣的读者可以思考一下,这时候是如何反向传播的(提示:y=relu(x) -> dx = dy.copy();dx[y<=0]=0)
1.3 节省显存的方法
降低batch-size
下采样(NCHW -> (1/4)*NCHW)
减少全连接层(一般只留最后一层分类用的全连接层)
2 计算量分析
2.1 常用操作的计算量
全连接层:BxMxN , B是batch size,M是输入形状,N是输出形状。
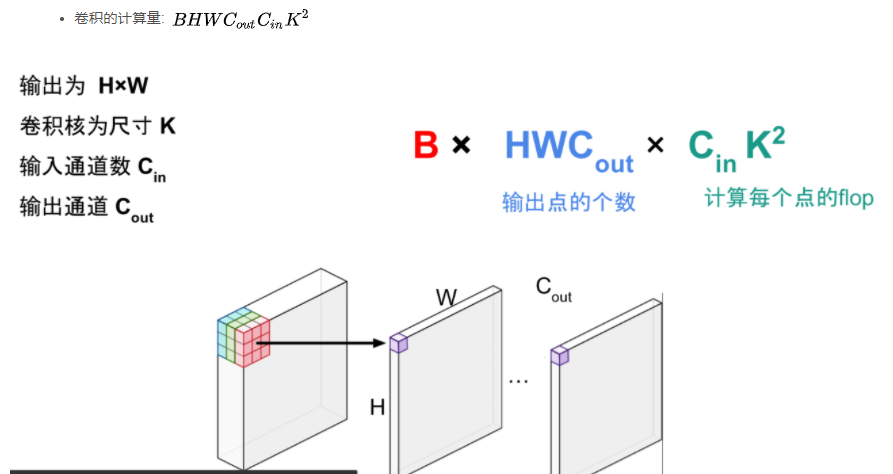
卷积的计算量分析
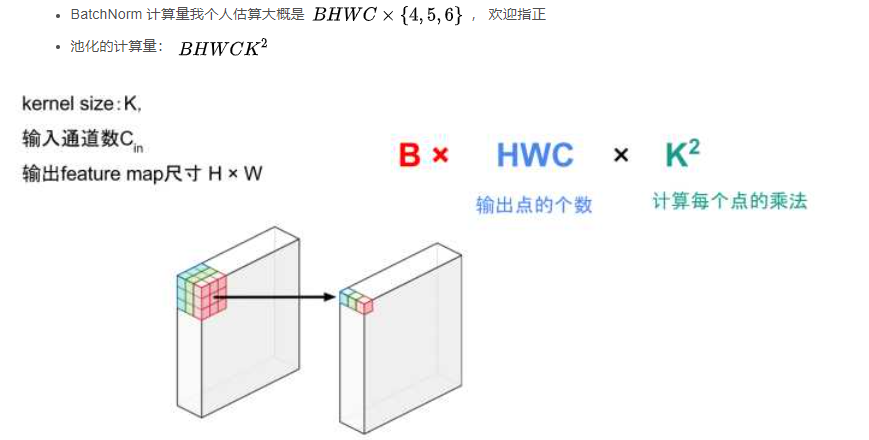
ReLU的计算量:BHWC
2.2 AlexNet 分析

AlexNet分析
全连接层占据了绝大多数的参数
卷积层的计算量最大
2.3 减少卷积层的计算量
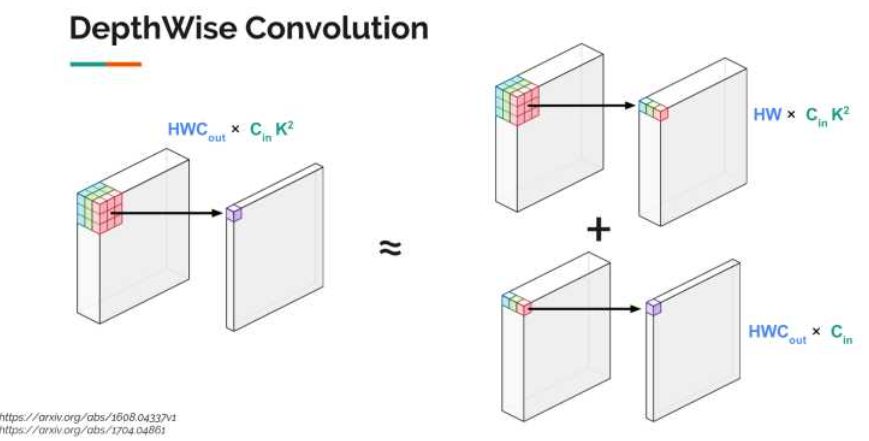
Depthwise Convolution
显存占用变多(每一步的输出都要保存
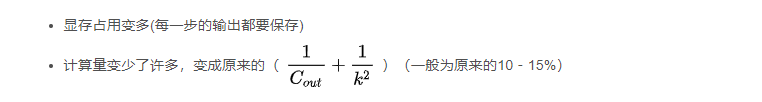
2.4 常用模型 显存/计算复杂度/准确率
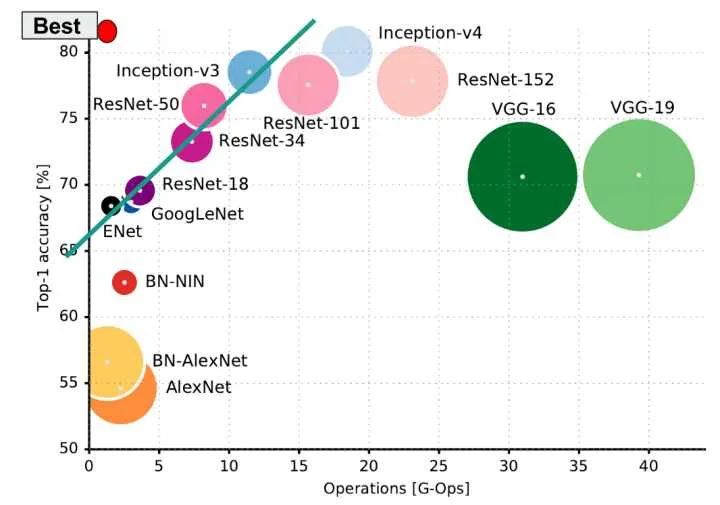
常见模型计算量/显存/准确率
3 总结
3.1 建议
时间更宝贵,尽可能使模型变快(减少flop)
显存占用不是和batch size简单成正比,模型自身的参数及其延伸出来的数据也要占据显存
batch size越大,速度未必越快。在你充分利用计算资源的时候,加大batch size在速度上的提升很有限
增大batch size能增大速度,但是很有限(主要是并行计算的优化)
增大batch size能减缓梯度震荡,需要更少的迭代优化次数,收敛的更快,但是每次迭代耗时更长。
增大batch size使得一个epoch所能进行的优化次数变少,收敛可能变慢,从而需要更多时间才能收敛(比如batch_size 变成全部样本数目)。
3.2 关于显卡选购
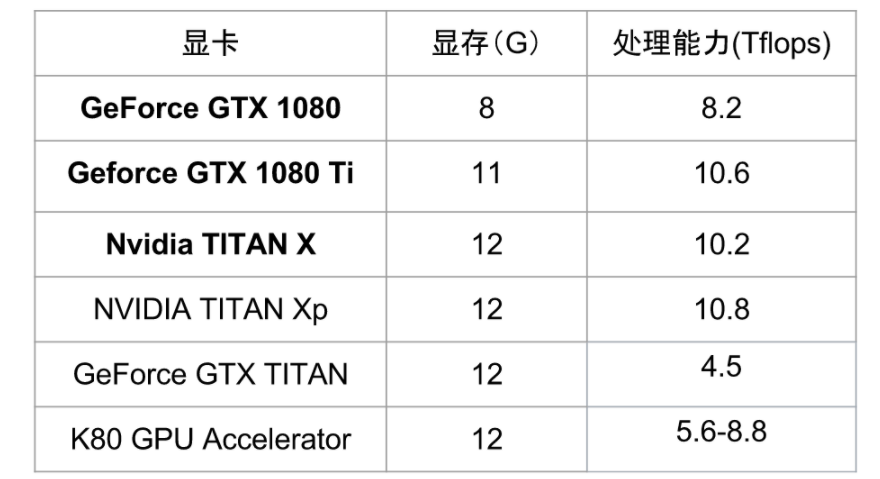
常见显卡指标
K80性价比很低(速度慢,而且贼贵)
注意GTX TITAN和Nvidia TITAN的区别,别被骗
另外,针对本文,我做了一个Google 幻灯片:神经网络性能分析,国内用户可以点此下载ppt
http://link.zhihu.com/?target=http%3A//misc-1252820389.cosbj.myqcloud.com/%25E7%25A5%259E%25E7%25BB%258F%25E7%25BD%2591%25E7%25BB%259C%25E5%2588%2586%25E6%259E%2590.pptx
Google幻灯片格式更好,后者格式可能不太正常。
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码