
手把手教你用Python网络爬虫进行多线程采集高清游戏壁纸
点击上方“IT共享之家”,进行关注
回复“资料”可获赠Python学习福利
禁门宫树月痕过,媚眼惟看宿鹭窠。

一、背景介绍
大家好,我是皮皮。对于不同的数据我们使用的抓取方式不一样,图片,视频,音频,文本,都有所不同,由于网站图片素材过多,所以今天我们使用多线程的方式采集某站4K高清壁纸。
二、页面分析
目标网站:
http://www.bizhi88.com/3840x2160/如图所示,有278个页面,这里我们爬取前100页的壁纸图片,保存到本地;
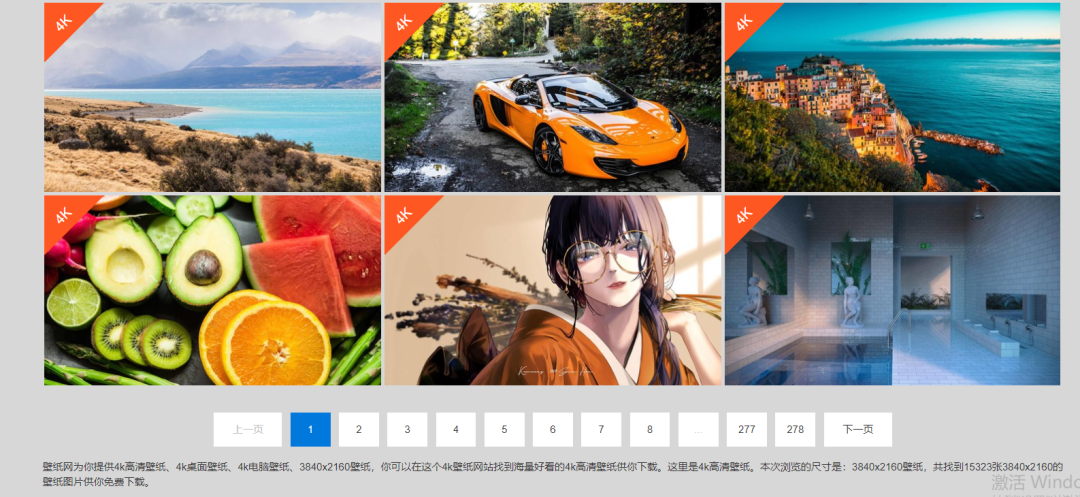
解析页面
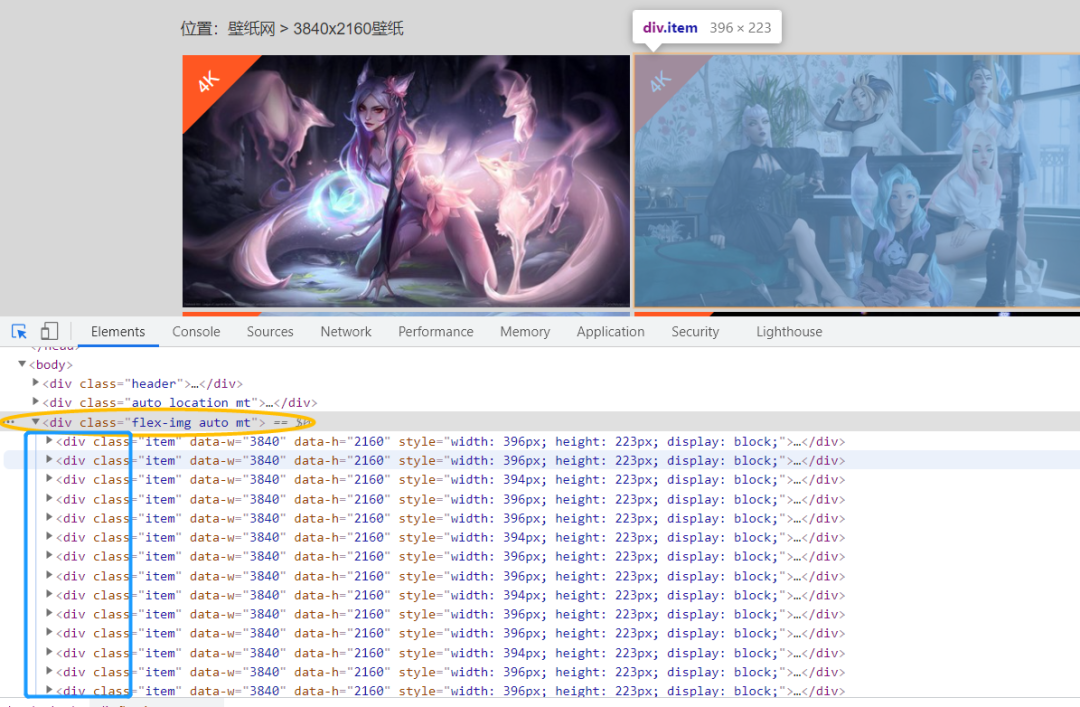
如图所示所哟鱼的图片在一个大盒子里面(
然后每页div标签里面的壁纸图片数据的各种信息:1.链接;2.名称;下面是xpath的解析;
imgLink = each.xpath("./a[1]/img/@data-original")[0]name = each.xpath("./a[1]/img/@alt")[0]
有一个注意点:
图片标签有src属性也有data-original属性,都对应图片的url地址,我们一般使用后者,因为data-original-src是自定义属性,图片的实际地址,而src属性需要页面加载完全才会全部显现,不然得不到对应地址;
三、抓取思路
上面已经说过,图片数据过多,我们不可能写个for循环一个一个的下载,所以必然要使用多线程或者是多进程,然后把这么多的数据队列丢给线程池或者进程池去处理;在python中,multiprocessing Pool进程池,multiprocessing.dummy非常好用,
multiprocessing.dummy模块:dummy模块是多线程;multiprocessing模块:multiprocessing是多进程;
multiprocessing.dummy 模块与 multiprocessing 模块两者的api 都是通用的;代码的切换使用上比较灵活;
页面url规律:
'http://www.bizhi88.com/s/470/1.html' # 第一页'http://www.bizhi88.com/s/470/2.html' # 第二页'http://www.bizhi88.com/s/470/3.html' # 第三页
构建的url:
page = 'http://www.bizhi88.com/s/470/{}.html'.format(i)那么我们定制两个函数一个用于爬取并且解析页面(spider),一个用于下载数据 (download),开启线程池,使用for循环构建13页的url,储存在列表中,作为url队列,使用pool.map()方法进行spider,爬虫的操作;
def map(self, fn, *iterables, timeout=None, chunksize=1):"""Returns an iterator equivalent to map(fn, iter)”“”这里我们的使用是:pool.map(spider,page) # spider:爬虫函数;page:url队列
作用:将列表中的每个元素提取出来当作函数的参数,创建一个个进程,放进进程池中;
参数1:要执行的函数;
参数2:迭代器,将迭代器中的数字作为参数依次传入函数中;
四、数据采集
导入相关第三方库
from lxml import etree # 解析import requests # 请求from multiprocessing.dummy import Pool as ThreadPool # 并发import time # 效率
页面数据解析
def spider(url):html = requests.get(url, headers=headers)selector = etree.HTML(html.text)contents = selector.xpath("//div[@class='flex-img auto mt']/div")item = {}for each in contents:imgLink = each.xpath("./a[1]/img/@data-original")[0]name = each.xpath("./a[1]/img/@alt")[0]item['Link'] = imgLinkitem['name'] = nametowrite(item)
download下载图片
def download_pic(contdict):name = contdict['name']link = contdict['Link']with open('img/' + name + '.jpg','wb') as f:data = requests.get(link)cont = data.contentf.write(cont)print('图片' + name + '下载成功!')
main() 主函数
pool = ThreadPool(6)page = []for i in range(1, 101):newpage = 'http://www.bizhi88.com/s/470/{}.html'.format(i)page.append(newpage)result = pool.map(spider, page)pool.close()pool.join()
说明:
在主函数里我们首选创建了六个线程池;
通过for循环动态构建100条url;
使用map() 函数对线程池中的url进行数据解析存储操作;
当线程池close的时候并未关闭线程池,只是会把状态改为不可再插入元素的状态;
五、程序运行
if __name__ == '__main__':start = time.time() # 开始计时main()print(end - start) # 时间差
结果如下: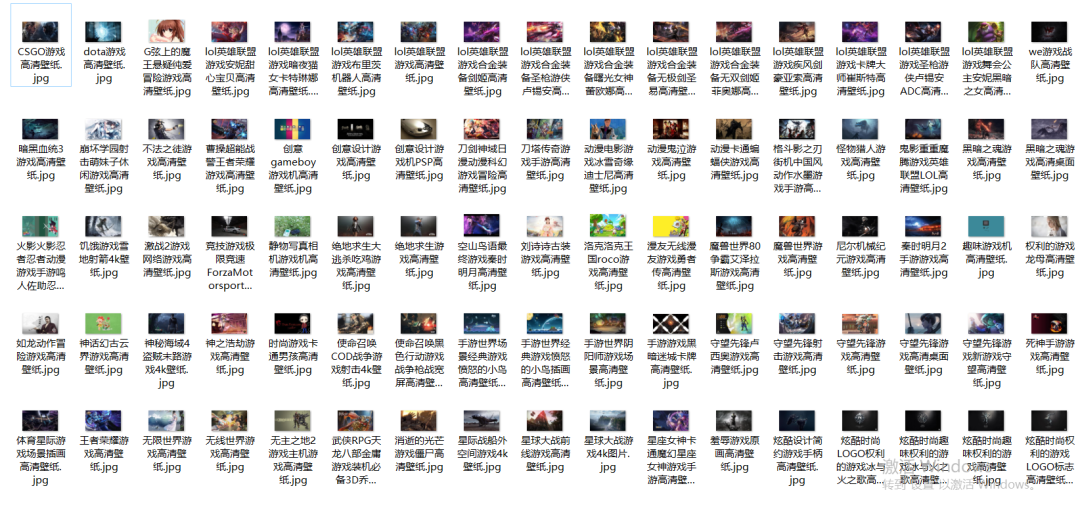
当然了这里只是截取了部分图像,总共爬取了,2000+张图片。
六、总结
本次我们使用了多线程爬取了某壁纸网站的高清图片,如果使用requests很明显同步请求并且下载数据是比较慢的,所以我们使用多线程的方式去下载图片,提高了爬取效率。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】
------------------- End -------------------
往期精彩文章推荐: