
手把手教你使用Python网络爬虫获取搜狗壁纸
回复“书籍”即可获赠Python从入门到进阶共10本电子书
/1 前言/
搜狗壁纸是一款高清电脑壁纸下载,集成万款美女、宠物、风景、电影、节日、日历、简约壁纸,一键更换壁纸,多分辨率自适应,支持分组播放。
搜狗壁纸,素材丰富,种类齐全,集美女、风景、萌宠等13个分类。让你的桌面充满爱。
/2 项目目标/
教会大家如何去获取搜狗壁纸,下载你喜欢的分类。
/3 项目准备/
软件:PyCharm
需要的库:requests、fake_useragent、json
网站如下:
https://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15/4 项目分析/
一、如何找到 json真正访问地址?
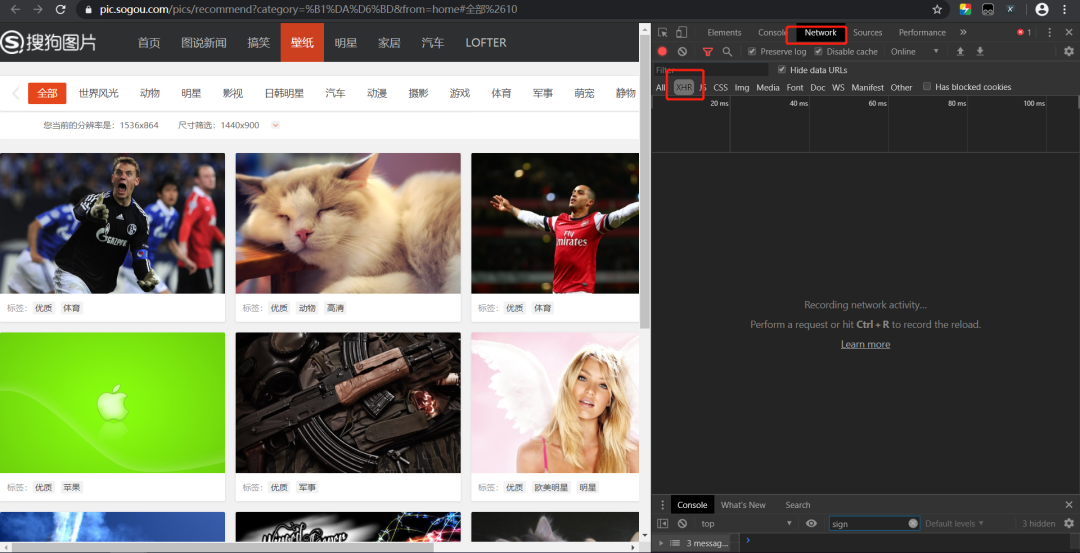
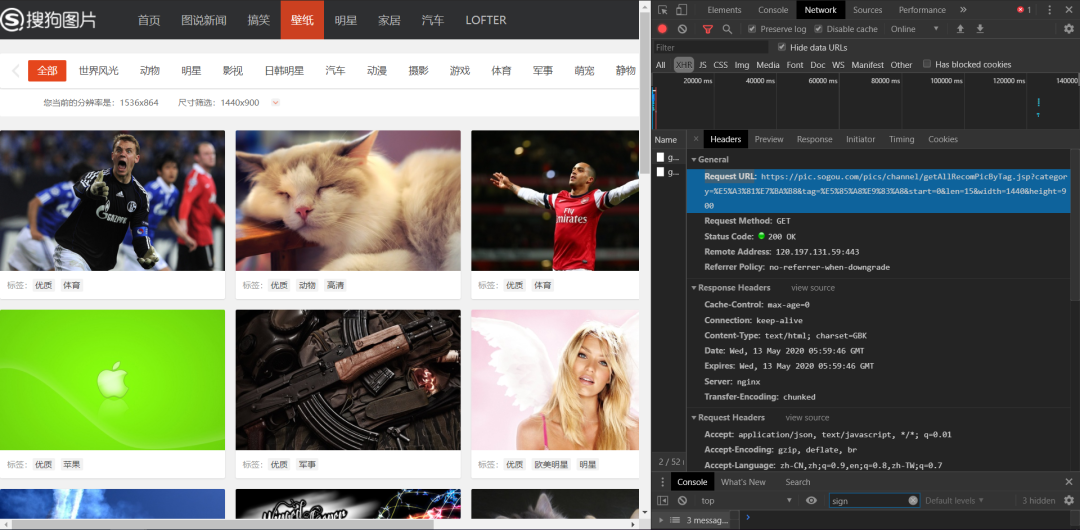
1、以壁纸这个分类来看,双击打开网站,右键F12>>找到下面的Network>>XHR>>(点击XHR下的文件)。刷新页面。找到Headers,里面的Request URL。
Request URL如下:
http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15&width=1536&height=8642、试着去掉一些不必要的部分,技巧就是,删掉可能的部分之后,访问不受影响。经筛选。最后得到的url如下:
http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=0&len=15 字面意思,知道category后面可能为分类。start为开始下标,len为长度,也即图片的数量。
二、如何获取里面的图片的地址?
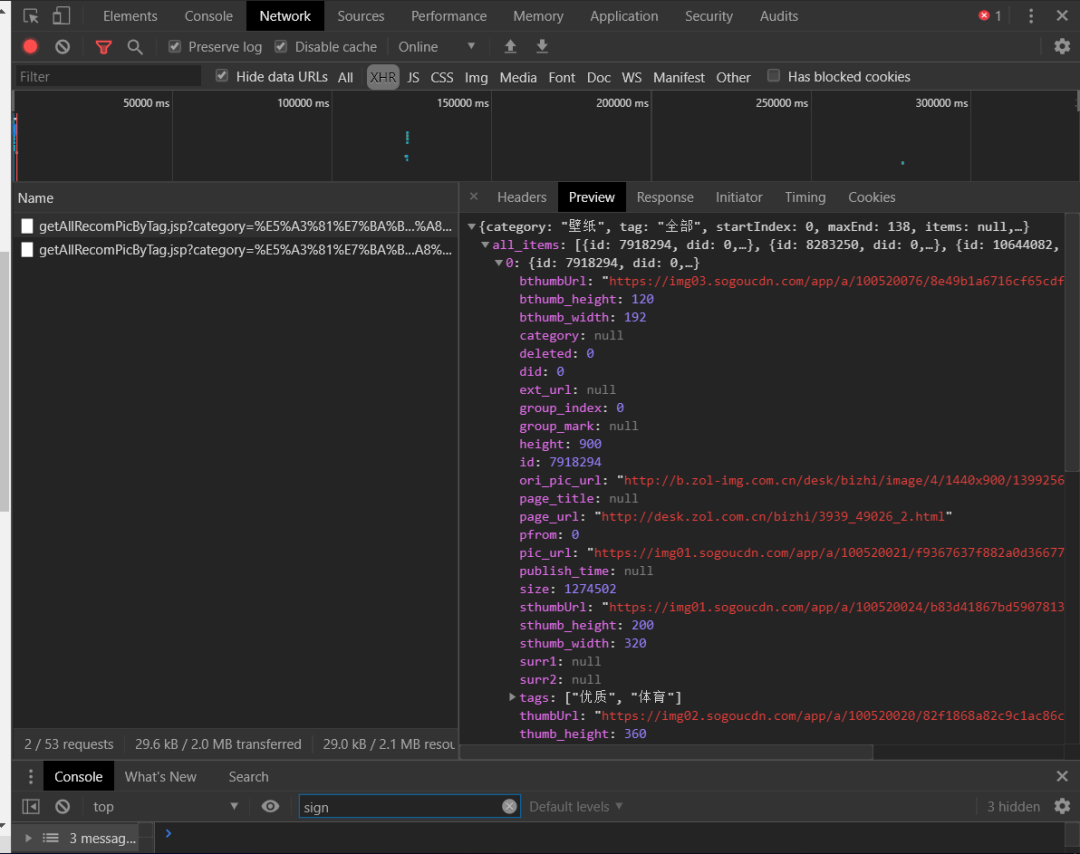
1、点击其中一个文件打开Preview,点开all_items 发现下面是0 1 2 3...一个一个的貌似是图片元素。试着打开一个url。pic_url就是图片的地址。如图:
/5 反爬措施/
1、获取正常的http请求头,并在requests请求时设置这些常规的http请求头。
2、使用 fake_useragent ,产生随机的UserAgent进行访问。
/6 项目实现/
1、定义一个class类继承object,定义init方法继承self,主函数main继承self。导入需要的库和网址,代码如下所示。
import requests, jsonfrom fake_useragent import UserAgentclass ShouGO(object):def __init__(self):passdef main(self):passif __name__ == '__main__':Siper = ShouGO()Siper.main()
2、随机生成UserAgent,防止反爬。
ua = UserAgent(verify_ssl=False)for i in range(1, 50):self.headers = {'User-Agent': ua.random,}
3、定义Shou方法传入三个参数category, length, path分别对应json地址参数值。实例化变量。
def Shou(self, category, length, path):n = lengthcate = category
4、json解析。
imgs = requests.get('http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category=' + cate + '&tag=%E5%85%A8%E9%83%A8&start=0&len=' + str(n))jd = json.loads(imgs.text)jd = jd['all_items']imgs_url = []
5、for循环遍历数组找到图片地址。
for j in jd:imgs_url.append(j['pic_url'])
6、for循环边框图片地址,定义一个变量m作为图片名称,拼接图片地址。
m = 0for img_url in imgs_url:# print(img_url)print('***** ' + cate + str(m) + '.jpg *****' + ' Downloading...')
7、 图片地址发生请求,获取响应。
img = requests.get(url=img_url, headers=self.headers).content8、保存图片
with open(path + cate + str(m) + '.jpg', 'wb') as f:f.write(img)# urllib.request.urlretrieve(img_url, path + str(m) + '.jpg')m = m + 1print('Download complete!')
9、mian里调用Shou方法传入参数。实现功能。
def main(self):self.Shou('汽车', 2000, './壁纸2/')
/7 效果展示/
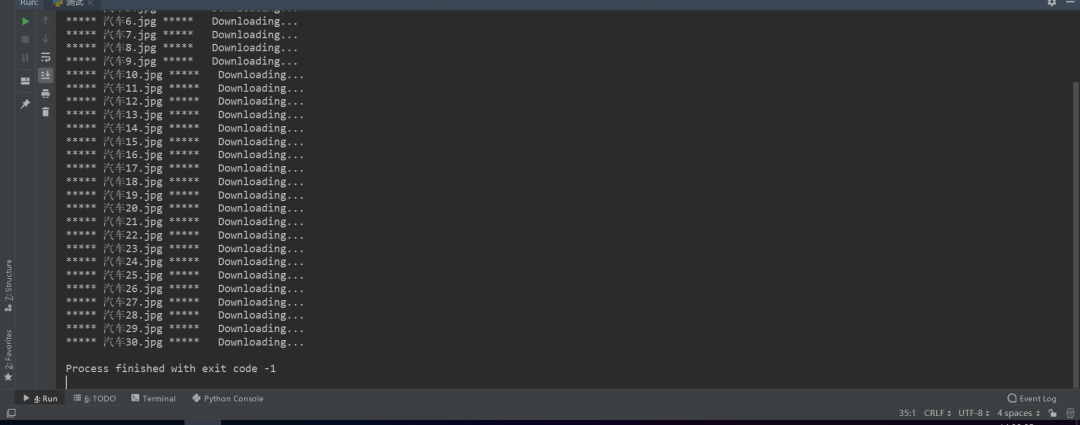
1、点击绿色小三角运行。以Shou('汽车', 2000, './壁纸2/'):(“分类”,长度。"保存的地址")为例。点击运行,结果显示在控制台,如下图所示。
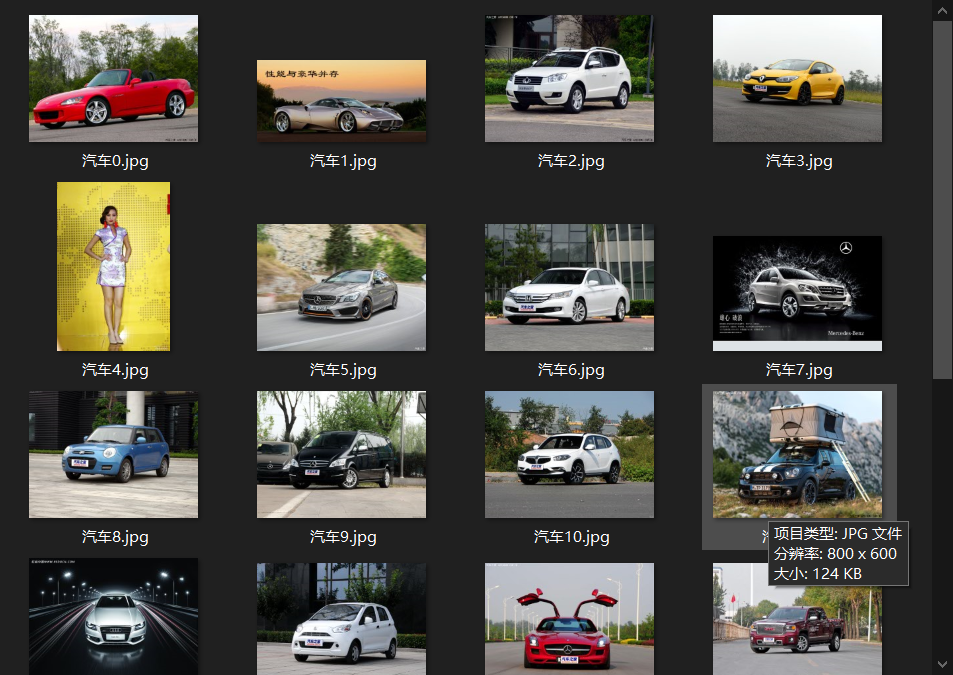
2、保存的图片,如下图所示。
/8 小结/
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~