
中文多模态CLIP,它终于有开源了
大家好,我是DASOU。
前段时间发现在Github上有位同学开源了中文的CLIP,包括权重和微调代码。但是可惜的是,这个仓库后续被关闭了,很奇怪~~

所以这个仓库就不能用了。
当时是分享到朋友圈了,所以看到就是赚到:
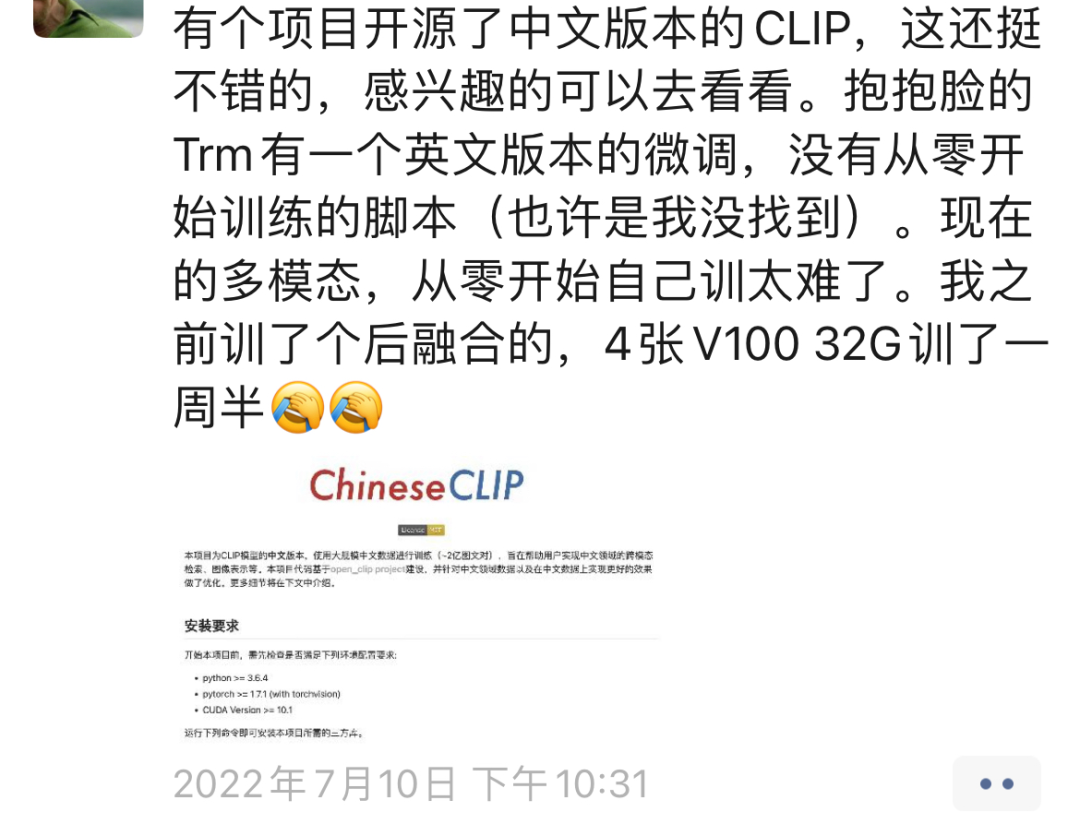
不过后来有朋友书说看到了另一个同学开源了同样的项目,我fork了一下,大家可以去我Github看下,应该也能用~~
然后,这两天在知乎看到又有位同学开源了CLIP的中文权重,比较方便的一点是在hugging face可以直接调用使用。
hugging face是有预留CLIPModel的接口的,所以开源的权重可以直接被使用。
我看作者的描述,「在预训练的时候,对于image encoder,直接加载openAI的权重,而且是冻住,并没有参与训练。对于text encoder, 则是加载中文robert预训练模型作为初始化权重进行训练。所以放出来的开源模型只有text encoder,image encoder直接用openAI的权重即可」
emm......好吧。
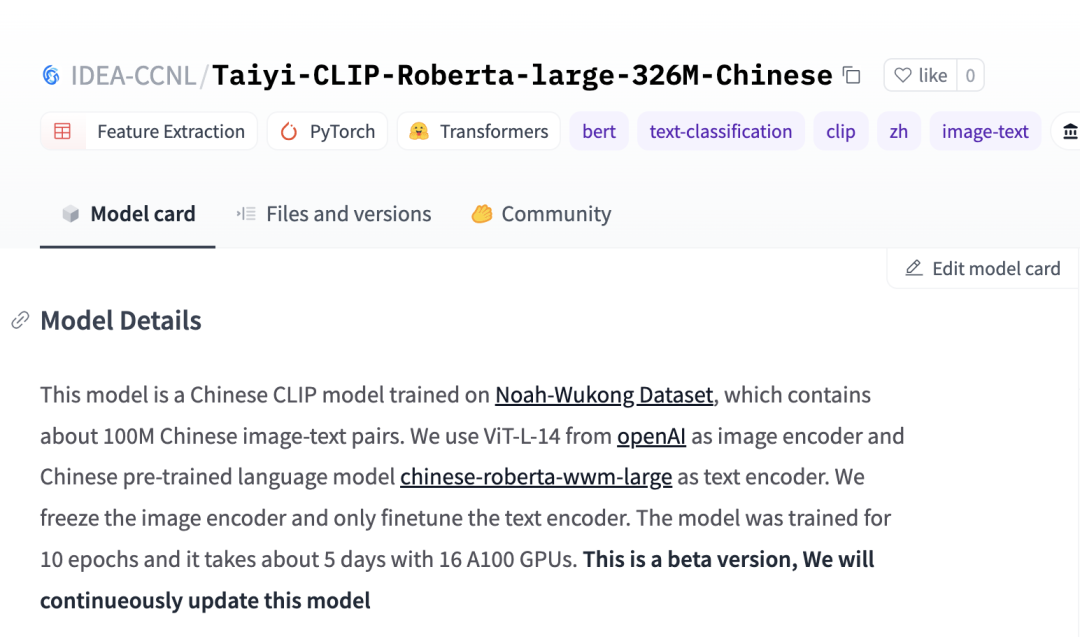
模式是基于wukong数据集训练的,这个数据集在刚出来的时候,我也公众号分享了一下,看这里 这个数据集,绝了。
总的来说,有大规模的多模态中文模型开源出来总归是好的。因为对于一些同学来说,从零训练一个多模态模型,实在是太耗资源了,也是一个小门槛。
我之前用训练一个后融合的多模态模,4张V100/32G显存,训练了快2周,还没训练好~~
辛苦求个三连
权重地址:https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese
如果想第一时间看到一些比较好的技术/论文的分享,可以加我微信围观朋友圈~~
评论