
优化 | 为什么凸优化这么重要?
原文链接:https://www.zhihu.com/question/24641575
以下整理按照知乎全部回答的默认排序
No.1
作者:覃含章
1.为什么凸优化重要?
凸优化性质好,许多日常生活中的非凸优化问题,目前最有效的办法也只能是利用凸优化的思路去近似求解。
例如:
● 带整数变量的优化问题,松弛之后变成凸优化问题(所以原问题其实是凸优化问题+整数变量);
● 任意带约束的非凸连续优化问题,其对偶问题作为原问题解的一个lower bound,一定是凸的!
● 针对带有hidden variable的近似求解maximum likelihood estimate的EM算法,或者贝叶斯版本里头所谓的variational Bayes(VB) inference。而原本的MLE其实是非凸优化问题,所以EM和VB算法都是找到了一个比较好优化的concave lower bound对这个lower bound进行优化。
这是什么意思呢?
也就是说到今天2019年为止,我们还是只对凸优化问题比较有把握。
当然有人可能要说了,现在各种深度强化学习、深度学习的优化问题都是极其复杂的非凸优化问题,不是大家也能解的挺好?
这个问题的回答就更难一些,我个人观点,简单来说是这样,目前对于这些非凸优化问题取得的算法理论方面的突破大体其实归结于找到这些非凸优化问题中“凸”的结构。这也是为什么我们看到一阶算法(SGD, ADAM等)仍然大行其道,而分析这些非凸优化算法的时候其实很多的lemma(引理)仍然是凸优化(凸分析)里的引理或者引申。
举个例子:
我们大家都知道凸函数的各种等价定义。而在Zeyuan Allen-Zhu的一系列非凸优化算法的文章中所谓的非凸性的刻画仍然是基于此衍生出来的:
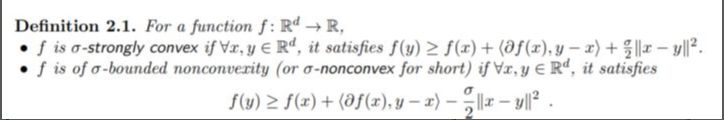
来源:Allen-Zhu, Zeyuan. Natasha: Faster Non-Convex Stochastic Optimization via Strongly Non-Convex Parameter. International Conference on Machine Learning. 2017.
我们知道它里面这个刻画非凸性的参数 ,如果取成0,那就等价于凸函数的定义,如果取成负的,那么实际上就是所谓strongly convex,而如果是正的,就变成它这里的non-convexity了。实际上,现在非凸优化里面很多的非凸性刻画都是脱胎于凸优化,比如prox regularity之类的,或者一些更弱的convexity定义(这在经典凸分析里就已经有不少研究了,quasi-convex,psuedo-convex等等),这里不再赘述。
个人认为,我们能真正一般化地解决非凸优化问题,那肯定是要对一般的混合整数(线性)规划(MILP, mixed integer linear programming)要有好的办法求解才算。因为任意一个非凸优化问题,都可以用很多的分段线性函数逼近,最后变成一个MILP。当然,因为P!=NP这个猜想的存在,这件事情在理论上肯定是hopeless,但是在实际当中,基于硬件能力的提升,还有比如量子计算机一类的新技术,我个人对人类未来能够在实际中求解MILP还是持一个比较乐观的态度。到那个时候,我觉得我们才能说传统的凸优化理论才是真正过时了。
2. 现有的优化方法不是都能解决(凸优化)吗?那凸优化又有什么用呢?
首先先明确一点,凸优化难吗?嗯相比非凸优化,各种NP-complete问题,凸优化里各种P问题,那肯定是简单的。然而,在实际当中,我们完全不可能满足于有一个“多项式时间算法”就好了。
我们知道,运筹学,优化问题,反映到现实世界里面就是各种数学建模问题。这些问题,普遍地出现在航空业、金融业、广告业、电商零售业、能源业、医疗业、交通业等各个领域。我们必须要明确一点,计算复杂性理论(P,NP这套东西)在实际当中其实是没什么用处的。嗯,NP hard, NP complete问题很难,没有多项式时间算法,但如果你实际的问题规模不太大,比如几十个城市的旅行商问题(TSP, travelling salesman problem),几十x几十的图上的NP-complete问题,是不是很难?然而现在2019年,你在iphone上下个app,一部小小的手机不要几秒钟就能给你算出最优解。(实际上,他们这个app,1000个左右城市的TSP, iphone也顶多要算个几小时就能找到全局最优解,无近似)
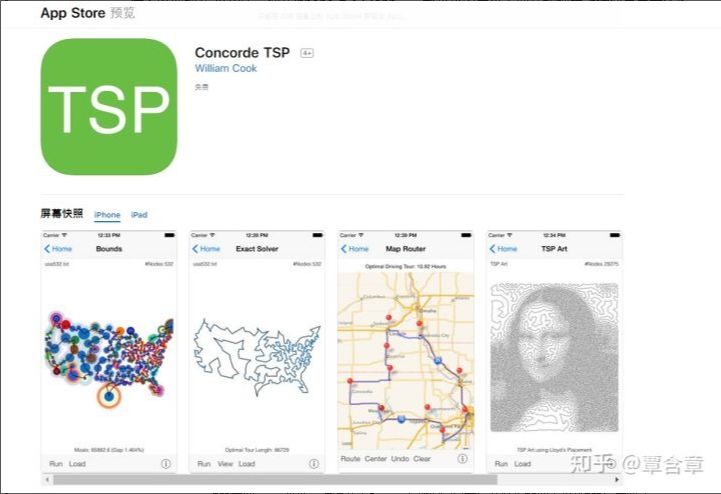
TSP求解app,当然,这得益于Concorde他们家目前行业领先的解大规模TSP底层算法...
与此相对应的,即使是一个P问题,但是如果实际当中你的问题规模超级大呢?实际上反而这个问题会让你更头疼的。
举个例子,比如现在优酷、天猫、京东、亚马逊这些个平台,每天你登陆网站,它在推荐栏都需要根据你的历史活动记录决定推荐哪些产品给你。这个在线推荐算法,本质上只是需要求解一个线性规划问题(LP, linear programming, 比一般的凸优化还简单),甚至还不是一个一般的线性规划,有个专门的名字叫做packing LP,这类packing LP理论上可以有跟问题规模呈线性的复杂度的算法(忽略log项,跟排个序差不多...)。听起来是不是很简单?然而,实际这些问题的规模无比巨大,每天这些平台上线人次数以亿记,这些平台可以推荐的商品也是至少百万千万规模的。。而且实际问题还有各种各样的现实约束,比如我们希望我们的算法可以完全在线更新(online,甚至是streaming algorithm),我们的算法需要灵活运用存储数据的数据结构,需要利用计算集群的并行能力,分布式能力,这也是需要非常非常专门的(一阶)优化算法设计的。。这边就不再多说了,因为我个人确实在之前公司实习的时候,发现中国最好的IT公司面对这类海量规模的“简单”LP,实际上远没有能力去完美地求解。
因此你说现有的方法能解决所有的凸优化问题,但从实际的角度其实还差的远。事实上,目前的大公司面对如此规模的优化问题,也就LP还可以勉强接受,像是什么second-order cone prorgamming (SOCP), semidefinite programming (SDP)根本目前实际中都不可能大规模求解。而这两类问题在理论上还仍然都是“线性”的,因为可以写成linear conic programming,所以就更不要说一般的带约束的凸优化问题了。
实际上,在这个方面,无论是求解器(solver)还是更好的理论算法的开发都还有大量的研究空间。比如,SDP实际当中的大规模算法设计目前来看还基本一片空白,有很多很基本的问题都还没有在理论上得到满意的解答(像SDP其实和另一类凸优化问题只有一丝之隔,copositive programming,而这类凸优化问题的计算复杂度却是NP complete的,所以即使是凸优化也未必复杂度就容易!实际上,所有mixed 0/1 nonconvex quadratic program都可以写成copositive program这个凸优化的形式。两者的算法设计也因此都很蛋疼)。。还有这么多没有解决的问题,又如何能说凸优化的问题都已经被“解决”了呢?
至于具体如何把mixed 0/1 nonconvex quadratic program写成凸优化形式,这是个很cute的结果,有兴趣的同学可见我这篇专栏文章的第二部分。

https://zhuanlan.zhihu.com/p/34772469
随手写写没想到也吐了不少嘈,我这边最后就再总结个几点吧:
● 做研究过程中,切忌轻易下结论。
实际上,对很多看似已经“解决”的问题,你如果肯花点功夫研究研究,会发现总有很多细节是值得深思的。更不要说直接说一个大的研究领域就已经被“解决”了。我记得前不久还看到NeurlIPs文章的方向汇总,凸优化仍然是优化方向文章里数量最多(还是第二多,具体记不清了)的。因为实际上我前面还有很多没提,比如像现在很火的强化学习(或者说多阶段的随机动态规划)里面还有大量的凸优化问题没搞定。。
● 基础永远是重要的。
而凸优化就是你做非凸优化研究的基础。这么些年来,我自己也逐渐体会,研究当中最常用的,真的还就是那些最基础的微积分,线性代数,概率统计的基本功。很多问题,如果你有基础,就都直接不是问题了;反过来,如果当初在学习过程中冒进,去追求最前沿,最时髦,最fancy的topic,却没好好打基础,你可能就会发现很多基本的知识本来都不应该成为障碍,最后却各种让你磕磕绊绊。
● 作为优化研究者,埋头研究的同时,一定要睁开眼睛看看业界的实际情况。
当然,总有一部分优化大师是不在乎实际应用的(然而Nesterov, Nemirovski这样的人也是有应用文章的),有志做令人高山仰止的大师的就可以忽略我这条了。我只是想说,对于大多数做优化的人,我们实际上应该都是希望自己做的东西可以用在业界的实际问题当中。那么这个时候除了学理论知识,真的我们应该多hands on,get your hands dirty。我自己的体会是,往往都是在实际写代码求解问题的时候才会对很多知识有更深刻的理解,并且能找到真正值得研究的有意思的问题。
convexity is sexy~
No.2
作者: 留德华叫兽
前言:运筹学在国内,远没有统计和人工智能来的普及。
相信很多人不知道,运筹学正是研究优化理论的学科(包括凸优化),而人工智能模型最后几乎都能化简成求解一个能量/损失函数的优化问题。因此,我把它称为人工智能、大数据的“引擎”。(本文的详细版本已发表在@运筹OR帷幄专栏:离散/整数/组合/非凸优化概述及其在AI的应用 - 知乎专栏)
言归正传,为什么凸优化这么重要?
1. 首先大家需要知道Convex VS Non-Convex的概念吧?
数学定义就不写了,介绍个直观判断一个集合是否为Convex的方法,如下图:
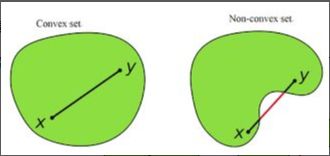
简单的测试一个集合是不是凸的,只要任意取集合中的俩个点并连线,如果说连线段完全被包含在此集合中,那么这个集合就是凸集,例如左图所示。
2. 凸优化-相对简单
凸优化有个非常重要的定理,即任何局部最优解即为全局最优解。由于这个性质,只要设计一个较为简单的局部算法,例如贪婪算法(Greedy Algorithm)或梯度下降法(Gradient Decent),收敛求得的局部最优解即为全局最优。因此求解凸优化问题相对来说是比较高效的。
另一个侧面,可微分的凸优化问题满足KKT条件,因此容易求解:
【学界】关于KKT条件的深入探讨
这也是为什么机器学习中凸优化的模型非常多,毕竟机器学习处理海量的数据,需要非常高效的算法。
3,非凸优化-非常困难
而非凸优化问题被认为是非常难求解的,因为可行域集合可能存在无数个局部最优点,通常求解全局最优的算法复杂度是指数级的(NP难)。如下图:

最经典的算法要算蒙特卡罗投点法了,大概思想便是随便投个点,然后在附近区域(可以假设convex)用2中方法的进行搜索,得到局部最优值。然后随机再投个点,再找到局部最优点--如此反复,直到满足终止条件。
假设有1w个局部最优点,你至少要投点1w次吧?并且你还要假设每次投点都投到了不同的区域,不然你只会搜索到以前搜索过的局部最优点。
4. 为何要学习非凸优化呢?
因为现实生活中,几乎所有问题的本质都是非凸的。
把3中的图看作山川盆地,你在现实中有见过左图这么“光滑”的地形么?右图才是Reality!
5. 凸优化为何这么重要呢?
科学的本质便是由简到难,先把简单问题研究透彻,然后把复杂问题简化为求解一个个的简单问题。
例如3中经典的蒙特卡罗投点法,就是在求解一个个的凸优化问题。
假设需要求解1w个凸优化问题可以找到非凸优化的全局最优点,那么凸优化被研究透彻了,会加速凸优化问题的求解时间,例如0.001秒。这样求解非凸优化问题=求解1w个凸优化问题=10秒,还是可以接受的嘛!【学界】非凸转成凸、约束转无约-运筹学和支持向量机中的拉格朗日松弛法
6. 运筹学中线性规划与凸优化的关系
线性规划是运筹学最基础的课程,其可行域(可行解的集合)是多面体(polyhedron),具有着比普通的凸集更好的性质。
因此是比较容易求解的(多项式时间可解)。
如有兴趣,且听我唠叨一下关于运筹学的四个知乎 Live
7. 运筹学中(混合)整数规划与非凸优化的关系
大家或许不知道,(混合)整数规划被称为极度非凸问题(highly nonconvex problem),如下图:
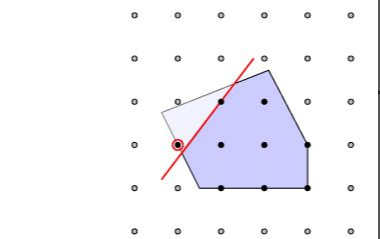
实心黑点组成的集合,是一个离散集,按照1中判断一个集合是否为凸集的技巧,我们很容易验证这个离散集是非凸的。
因此整数规划问题也是一个非凸优化问题,并且它也是NP难的。
那么整数规划的求解思路呢,也遵循了科学研究的本质,即被分解为求解一个个的线性规划(凸优化)问题。
感兴趣的朋友可以搜索参考下文:
【学界】混合整数规划/离散优化的精确算法--分支定界法及优化求解器
8.(混合)整数规划为何重要?
虽然时间是连续的,但是社会时间却是离散的。例如时刻表,通常都是几时几分,即使精确到几秒,它还是离散的(整数)。没见过小数计数的时刻表吧?
同样,对现实社会各行各业问题数学建模的时候,整数变量有时是不可避免的。例如:x辆车,y个人。x,y这里便是整数变量,小数是没有意义的。
9. 深度学习为何非凸?
深度学习里的损失函数,是一个高度复合的函数。什么叫复合函数?好吧,例如h(x)=f(g(x))就是一个f和g复合函数。
当f,g都是线性的时候,h是线性的。但在深度学习里用到的函数,Logistic, ReLU等等,都是非线性 ,并且非常多。把他们复合起来形成的函数h,便是非凸的。
求解这个非凸函数的最优解,类似于求凸优化中某点的gradient,然后按照梯度最陡的方向搜索。不同的是,复合函数无法求gradient,于是这里使用Back Propagation求解一个类似梯度的东西,反馈能量,然后更新。
10. 深度学习的优化问题在运筹学看来是“小儿科”
这句话可能会打脸大部分观众。
深度学习中的优化问题,虽然目标函数非常复杂,但是它没有约束阿,是一个无约束优化问题!
大家如果学过运筹学,就知道它由目标函数和约束条件组成,而约束条件,是使得运筹学的优化问题难以求解的重要因素(需要搜寻可行解)。
关于运筹学与人工智能更多的交叉与应用(自动驾驶),
参见知乎Live:理工科的你想要转AI?快上车!
总结:
机器学习、数据科学因为处理数据量庞大,因此研究问题主要的方法还是凸优化模型,原因正是求解高效,问题可以scale。
虽然目前还很小众,但是随着计算机硬件能力的提高,GPU并行计算的流行,以及(非)凸优化算法、模型的进化,想必非凸优化,甚至(混合)整数规划会是未来的研究热点。
这不,最近就有研究智能算法求解深度学习损失函数的paper:遗传算法,模拟退火算法,粒子群算法,神经网络等智能算法的作用?
No.3
作者:王源(运筹优化博士,机器学习半吊子)
之前看过Nesterov的 Introductory Lectures on Convex Programming 颇有一些收获,再这里就把Nesterov 关于凸函数的观点简单的解读一下。

这个条件被称为一阶必要条件,什么是必要条件呢,就是满足这个条件的不一定是最优解,而不满足的一定不是最优解。如果把在茫茫人海中寻找到你的最佳伴侣比喻成找到优化问题的最优解,那么这个一阶必要条件就相当于一个筛选条件,例如有房有车的。没房没车的人肯定不是最佳伴侣,下面仅仅在有房有车的人当中找最佳伴侣,这样事情会变得简单一些了。
一阶必要条件可以帮我们筛选掉一些肯定不是局部最优解的,让问题变得简单,但是这个一阶必要条件有两个致命伤:一是它是一个必要条件啊,必要条件多多少少看着就让人有点不爽。我们辛辛苦苦用梯度法,拟牛顿法或者共轭梯度法找到了一个满足必要条件的点,然后一阶必要条件告诉我们,这个点可能是最优解,也可能不是。二是该条件是针对局部最优解的,根本没谈全局最优的事情,能不能找到全局最优只能看运气喽,梯度法的初始点选得好兴许能找到,也兴许没找到。概括以上两点就是“局部最优不一定,全局最优全靠碰。”
那么到这里肯定就想问一下,有没有办法让这个一阶必要条件变成充要条件,同时让局部最优变成全局最优的情况呢?
答案是有的,对一些特殊一点的而言,一阶必要条件会变成充要条件。那这类性质非常好的函数长什么样呢?
答案是 凸函数。
也就是说对于是可微的凸函数而言,一阶必要条件就变成了充要条件,同时局部最优也升格为全局最优。如果各位想看该命题的严谨证明的话 参考Introductory Lectures on Convex Programming 的chapter2即可。
到此为止,我们可以自信满满的说若是可微还是凸函数的话,满足的点,一定是全局最优解。哈哈,梯度法,拟牛顿法或者共轭梯度法等基于梯度的算法都可以完完全全保证能收敛到全局最优解上去。
所以说对优化问题而已 凸函数的性质简直好到爆炸啊。个人感觉这就是凸优化为何那么重要的原因之一吧。套用一句经典话语:优化问题的分水岭不是线性和非线性,而是凸和非凸。
参考文献
Nesterov, Yurii. "Introductory lectures on convex programming volume i: Basic course." Lecture notes (1998).
Allen-Zhu, Zeyuan. Natasha: Faster Non-Convex Stochastic Optimization via Strongly Non-Convex Parameter. International Conference on Machine Learning. 2017.
✄------------------------------------------------
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
