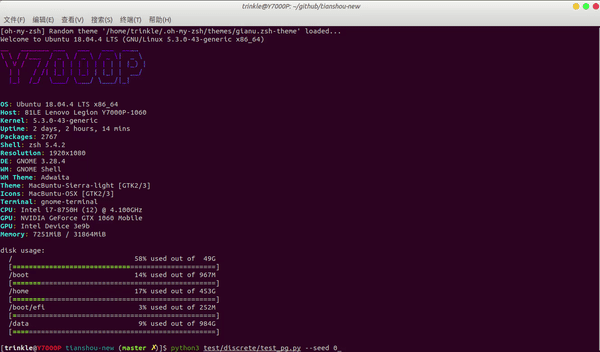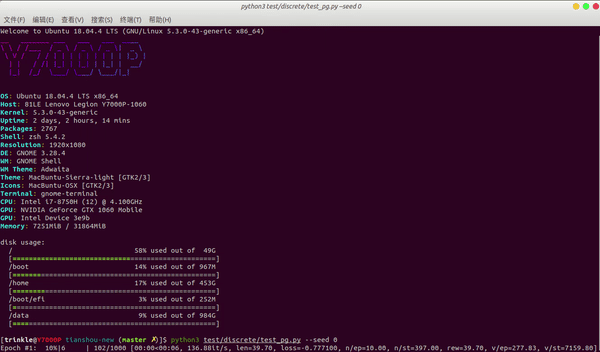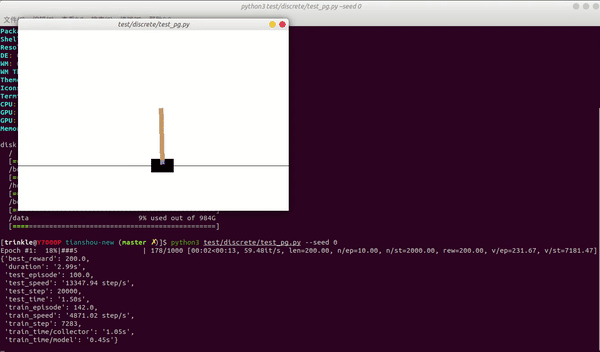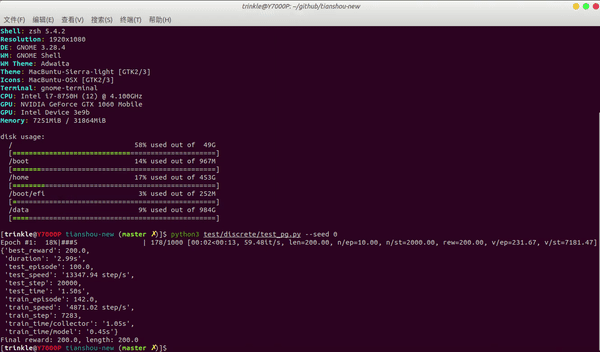
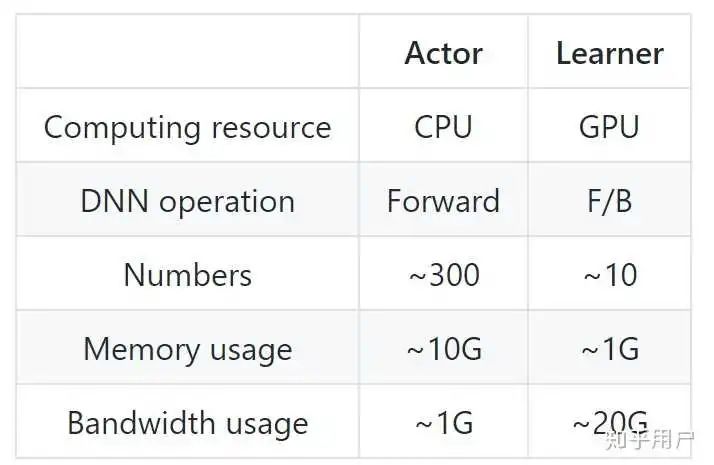
目前最好用的大规模强化学习算法训练库是什么?极市平台关注共 8818字,需浏览 18分钟 ·2020-08-12 16:49 点击蓝字 关注我们本文整理自知乎问答,仅用于学术分享,著作权归作者所有。如有侵权,请联系后台作删文处理。本文精选知乎问题“目前最好用的大规模强化学习算法训练库是什么?”评论区的热门回答,对比并总结了不同系统的特点。其中,上半年由清华大学人工智能研究院发布并开源的深度强化学习框架“天授”,具有代码简洁、模块化、可复现性、接口灵活及训练速度快等五大技术优势。亦有答主指出,“最好用”的系统是不存在的,应当根据需求来判断并选择最适合自身的训练库。回答一作者丨Trinkle本科毕设中期之前摸鱼凑数的成果,自卖自夸一波:https://github.com/thu-ml/tianshou这个小轮子代码少(目前除去atari和mujoco的wrapper之后,7个算法加上replay buffer在符合pep8规范下一共1100行),实现简单,速度还挺快,平均10秒内一个PG/DQN/A2C在CartPole,反观某些平台代码又臭又长100万step花一个小时还train不出来(狗头保命)下图是一个三秒在我自己笔记本上用PG train出来的CartPole,其实还有更快的(有1.6s一个DQN的)但就这样吧,再录一次屏幕有些麻烦:(正式训练之前等待大概三秒我测了测是net.to('cuda')要申请一堆内存所花的时间)说一下其他框架我认为的不足之处:(反正我今后再也不发RL的paper,直接在这里开始喷了)1、OpenAI Baselines: 代码写的和*一样早有听人耳闻,各种不遵守规范乱来,函数调来调去也就算了,我train一个DQN都很难train上去……大概是我太菜了82、rllib:不得不说是一个很好的框架,但是包的也太heavy了,class一层包一层,果然是Google的风格和TensorFlow有的一拼,想要更改某一个算法的某一个地方要读一圈代码+费好大劲才能改……大概还是我太菜了8这两个应该是RL平台star最多的两个了,其他比如Spinning up支持的算法有限(只有Policy-based一块的),Dopamine 好像只有DQN那一个family的。只针对PyTorch的:PyTorch目前的RL实现还没做到像rllib那么成熟,有几个分散的实现但我觉得不是太好,而且没有做到真正模块化。其实用PyTorch写RL代码真的要比Tensorflow少太太太太太太太多了!1、PyTorch DRL 是GitHub我找了一圈之后PyTorch RL平台Star最多的,侧重于实现hierarchical RL的算法,但是代码emmm和baseline好像几乎是同一个风格……还难改!(2.3K star我真的不知道怎么来的,可能就是时间早?2、rlpyt是PyTorch RL star第二多的,目前(15000行)实现的功能和我没到1500行代码实现的功能几乎一样,代码也是一层包一层,继承了一堆theano的历史代码,文档不全,我想改example跑gym的cartpole都跑不起来……用户体验不太行,但也至少比上面那个好一些。剩下的就没对比了,结果在这里:Tianshou的优势:1、实现简洁,不拖泥带水,是一看就懂的那种轻量级框架,方便修改来实现idea水paper和Berkeley争抢一席之地(x2、速度快,在已有的toy scenarios上面完胜所有其他平台,夸张到比如3秒一个Policy Gradient连我自己第一次跑出来都不敢相信。3、模块化,把所有policy都拆成4个模块,只要完善了这些给定的接口就能在100行之内完整实现一个强化学习算法。4、可复现性:我把GitHub Actions给用起来了,每一次单元测试除了基本功能的测试之外,还包括针对所有算法的完整训练过程,也就是说一旦有一个算法没办法train出来,单元测试不给过。据我所知,目前RL平台应该没一个敢这么干的(因为都太慢了5、接口灵活:用户可以定制各种各样的training方法,而且没几行就能实现,可以参考这里:https://tianshou.readthedocs.io/en/latest/tutorials/dqn.html#train-a-policy-with-customized-codes来源:https://www.zhihu.com/question/377263715/answer/1113283781回答二作者丨fmxFranky以下回答纯属个人认知,欢迎交流讨论~paper方面我调研过Scalable/Distributed RL的相关的算法(Ape-X,R2D2,IMPALA,A3C,G-A3C,SEED_RL,Agent57等);框架库方面我因为项目需要也做过一定的调研,也基于很多轮子进行了一些使用。因此我觉得我应该可以给题主分享一些经验。我觉得一开始题主要明确两个问题:“大规模/分布式”对与你来说具体指哪方面?你需要的大规模/分布式到什么程度?”然后需要基于上面的结论根据你做的research或者项目来思考:“我需要做到什么程度的框架?”我们来依次讨论这两方面的问题。我了解的大规模/分布式目前主要有三方面:1、环境的并行:这里我特指单机条件下使用wrapper对环境进行封装,使得可以同时运行很多环境,打batch使用网络进行inference。当然这个其实不怎么算大规模,不过一般的Research我觉得可能环境并行就差不多了,上升不到真正的大规模。2、Actor的并行:这里主要是值Ape-X、A3C等Scalable RL算法中的Actor,其作用主要是在每个机器/线程上运行一个Actor同若干数量的envs进行交互来收集数据。3、Learner并行:这里主要是类似分布式深度学习,基于单机多卡或者多机多卡进行大batch的训练。大规模强化学习我觉得本质上首先需要在工程上解决“高效快速收集大规模数据”的问题,然后才是从算法角度解决“基于大规模数据进行高效神经网络训练”。下面说一下支持上面三种层面我推荐的相关库。1、环境并行环境的并行一般来说取决于你做的问题:假如你做的是Atari、Mujoco这种,其实绝大多数库都提供了相关的wrapper,一般是基于多进程/线程来同时跑若干个环境,最后提供一个vector_envs;如果你只是觉得DQN类算法基于一个环境交互训练太慢需要多几个环境同时交互那我觉得大多数框架基本上都可以满足需求。也就说如果你就是要在在单机多核单卡的机器上跑rl算法,更加需要关注的反而是这个框架有没有实现你想看想改的算法,复现了之后能不能打平paper里面的benchmark。这里我推荐几个repo,基本上复现的算法不少,效果有一定保证。1)openai的baselines,还有第三方复现的stable baselines:优点是经典RL算法均有复现,是很多Research跑benchmark都使用的repo;缺点是太工程化,套娃严重,想读懂需要话很长时间,修改的话也比较费事,而且据我周围的人说貌似openai复现的dqn效果不是特别好。2)openai的spinningup:里面提供了经典Policy-based算法的复现,优点是写的通俗易懂上手简单,并且效果有保障,而且同时tf和Pytorch的支持;缺点是没有value-based的算法,做DQN系列的就没办法了。3)Intel AI LAB的Coach:这是一个基于tf1.14的rl库,实现了经典RL算法,甚至有一些上面两个没实现的算法它也实现了。优点我觉得是他对RL Framework的设计很模块化,比如整体流程,算法模块定义,网络定义,探索策略定义等等,把常见的算法全部分成相互独立的模块拼接到一起,让研究人员可以高效的focus到要修改的地方而不需要考虑其他部分。建议题主可以看一下他的design doc看看适不适合你的需求,同时也支持分布式和AWS训练等,支持绝大多数游戏环境;缺点的话可能是模块化的有点死,看代码学习结构的时候有点不太友好。4)Google的dopamine,实现了Distributional DQN的一系列算法,其他算法没有。5)UCB两个大佬开源的rlpyt:专门基于pytorch实现的rl框架,有单机/多机分配资源的黑科技,挂arxiv的paper里面介绍的也效果也不错。contributor以前也写过如何加速DQN训练的调参方法。6)Kei Ohta开源tf2rl:感觉和上面这个差不太多,基于的是tf2.0。我只看过里面实现的Ape-x,所以不过多介绍。2、Actor并行和Learner并行如果你要做的算法就是类似Scalable RL topic的新算法,或者你使用的环境有运行限制(比如一台机器只能运行一个环境,我真的遇到过这种……),或者你的机器是单机多卡核数不多导致并行效率很慢但是你有其他的多CPU机器可以单独进行数据收集,那这种情况下你需要考虑的就是怎么在多机多核环境下并行运行很多环境,然后把分布式的数据收集起来。这个领域目前通用性高一些的据我了解主要是ray还有这两年在NIPS仿生骨骼人挑战上蝉联冠军的PARL。这些环境都可以单机多核和多机多核方便的拓展。1)Ray(含RLlib,tune)是UCB基于通用RL框架设计的框架,优点是涵盖了你能想到的一切有关RL可能用到的东西,包括使用redis进行Remote Procedure Call,distributed tf/pytorch,超参搜索调优,自定义trainer/environment/optimizer/policy。里面复现了Ape-X,D4PG,A3C,IMPALA,APPO,MADDPG,ES等算法(Scalable RL+Multi-Agent),效果也有保障,你只要学会了其实现思路分布式算法它都能搞定;缺点就是因为太大太general导致上手很困难,我看了rllib部分的源码。2)PARL:百度出品,基于PaddlePaddle的RL框架,其核心卖点一是使用了黑科技可以消除python多线程GIL锁的限制,使得可以高效利用多核CPU来环境并行。本质是还是基于RPC那一套让环境和agent step可以在远程集群上运行从而不使用本地资源。经过测试PARL的吞吐效率是比Ray高一些的,可能得益于其黑科技外加简易RPC流程(PARL使用的是zmq+pyarrow序列化简单object,ray可以序列化更加复杂的object),另外PARL里面也定义了Agent、Model、Algorithm类让研究人员高效修改算法。核心卖点二是PARL里面复现的算法是100%保证和paper里面的数值差不多的,这点其实我觉得大多数repo并不能做到这一点,恰恰对修改经典算法做Research来说这点反而额外重要;至于缺点可能就是要学PaddlePaddle,虽然目前里面增加了pytorch但是复现的算法还很少。在一些项目里面其实可能需要的是ray/PARL里面提供的远程通讯轮子而非全部,大规模并行的收集数据可能算法研发更加重要(纯属个人观点)。3、其他大规模分布式repo按照我调研过的Scalable RL算法来看,目前业界主流使用的基本都是基于Apex-X、R2D2的Actor-Learner-Buffer框架或者是类似IMPALA的框架,因此其实有很多repo都基于这两个两个算法进行复现,也就是说是没有其他算法就只有R2D2或者IMPALA,我也给题主推荐几个我调研过的repo,首先声明这两个我没有具体跑过,只是看了一下arxiv挂的paper,感觉还不错^_^,至少大厂出品品质有保证。1)Google Research的SEED_RL:ICLR2020 google的提出的分布式框架,在repo中基于Atari,google-football,DM Lab环境复现了R2D2和IMPALA,而且耗时更短,主要原因是他们让环境集中step,基于gRPC每次返回很大batch的state,然后把inference和training都放在TPU上面(详情可以去读他们的paper)2)Facebok AI Research的TorchBeast:也挂了arxiv,主要是基于python pytorch复现了IMPALA,支持单机和多机,通信部分和batch 打包部分是基于C++写的,他们的目标是让研究者只需要关注python算法部分。3)Facebook AI Research的ELF(pytorch官方也实现了一个简易版只针对围棋的ELF):田渊栋大神的代表作之一,适用于RTS的分布式训练框架。具体可以看repo里面的tutorial。另外额外提一个repo,NVIDIA Lab的CuLE:把Atari全部放到了GPU上面,一块卡可以跑上千个环境,官方提供了一些examples,其中基于CuLE的A2C+VTrace,一块卡,在Pong游戏上3min跑到19分。如果是做Atari的话可以考虑一下这个(详情见repo中提到的paper)。总结一下,没有所谓的“最好的大规模强化学习框架”,只能说基于题主你的需求来选框架,你需要什么程度的并行,然后希望框架做到什么程度,甚至可能出现市面上开源框架都不符合你要求的情况,这种情况可能就只能基于RPC通讯的轮子自己造框架的了。比如近几年几家大厂(OpenAI,DeepMind,腾讯等)在现实游戏(Dota2,SC2,王者荣耀等)上面的进展,都是肯定要自研框架的。题主如果是偏Research的话可能要根据研究的topic,使用的环境等方面来选择框架;如果是有很多机器来完成一些项目的话可能需要根据项目的实际情况来确定并行程度再来看市面上的框架有没有适合的。当然我上面提到的RL框架一定是不全的,只是基于我的调研给题主进行的推荐,而且其实还有很多个人实现的repo但是我发现都没有什么可复现性保证和比较广的算法覆盖范围所以就没推荐了,可能会有更好的框架,如果题主发现了记得告诉我一下~来源:https://www.zhihu.com/question/377263715/answer/1120555103回答三作者丨李英儒Distributed Accelerated Reinforcement Learning on memoireNeurIPS19的Divergence-Augmented Policy Optimization 和NeurIPS18的Exponentially Weighted Imitation Learning for Batched Historical Data 的实现是基于本框架。李英儒的专栏文章《从Mirror Descent的视角统一强化学习中的策略优化》讲了讲我们在这个框架上做的策略优化算法Divergence-Augmented Policy Optimization。(https://zhuanlan.zhihu.com/p/122663529)我们知道深度强化学习的训练速度一大瓶颈主要在数据生成采集,如何高效利用异构计算架构(多CPU+多GPU)来加速深度强化学习是一个重要的问题。我们通过针对策略优化算法设计异构分布式采样和计算来解决数据生成采集速率和优化计算速度较慢这一问题。我们的解决方案是memoire框架,其特色是将Replay memory模块和神经网络训练模块解耦,这样不论你在训练端是用什么DRL框架,基于tensorflow的也好,基于pytorch的也好,都可以轻松的用到分布式数据采样,更好的利用异构计算资源,加速训练。如图所示,多个Actor进程在多个CPU上并行运行,Actor负责根据本地网络参数对应的策略与环境交互和探索,并生成轨迹数据供Learner训练。Learner进程运行在GPU[1]上,负责通过Actor产生的数据更新深度神经网络的模型参数。具体而言,Actor在主循环中使用来自当前本地节点的策略与本地节点的环境交互生成动作,并将生成的观察和动作数据缓存在本地内存中。本地节点Actor上正在运行的策略会定期更新为Learner的最新策略;本地节点Actor同时将生成的数据异步发送到学习者。Learner 向 Actor 传递神经网络模型参数采用 Pub/Sub Messaging 模式在Learner节点,Learner以先进先出FIFO的方式保留每个执行者Actor分别产生的最多20个最近的episode。Learner从这些轨迹中有放回地随机抽取批量数据用于神经网络训练。Actors1、从Learner处“获取(Subscribe)”已发布的最新策略神经网络模型参数;2、根据当前获取的策略模型在环境中进行交互;3、将与环境交互产生的轨迹数据存在经验回放记忆存储(Replay memory)的客户端;4、Replay memory客户端将采样数据push到Replay memory服务器端。Learners1、从Replay memory 服务器端取得批量轨迹样本;2、根据不同的策略优化算法用批量样本更新模型;3、一定更新步骤后,将最新的策略神经网络模型参数“发布(Publish)”。框架部分设计细节Replay memory的客户端存储由本地Actor生成的最近轨迹。Local replay memory的存储大小受总步数/状态转移数和总episode数目的限制。我们提供3种方法来为新的episode创建空间,向当前episode添加状态转移轨迹以及关闭终止的episode。当episode结束时,将自动计算每个步骤的返回值,并更新其采样优先级。我们还提供了一种对当前正在运行的未完成轨迹进行采样以形成缓存并将其推送到Learner的方法。服务器端会自动从客户端接收push的缓存。当Learner需要一批样本进行训练时,Learner可以从这些从客户端push的缓存中获取一批次样本,并在这些样本中进行第二阶段的采样。在客户端和服务器端分别进行两阶段采样,最终大致等价于从Actor生成的所有轨迹样本中进行采样。注意到在此框架中,客户端只有采样过的状态转移轨迹而不是所有生成的轨迹会被push到Learner。在我们有大量Actors的情况下,这种设计可以减少Leaner的带宽负担和内存使用量。同时,Learner仍然可以通过优先采样的方式获得具有较高优先级的样本,以至于更高效地更新神经网络模型。实验结果我们在小型集群上部署异步并行分布式训练框架。Learner在GPU机器上使用M40卡运行,而执行者Actor在2.5GHz Xeon Gold 6133 CPU上以16个并行进程运行。最后我们展示在Atari game 58个环境下和STOA算法的相对优势。我们可以从实验结果看到,通过增加实际KL散度的返回值(即我们提出的Divergence-augmented Policy Optimization),我们算法的性能要比基准算法PPO更好。Divergence-augmented Policy Optimization 在可能具有局部最优值且需要更深入探索的游戏中性能提高更为明显。更多的详细实验结果感兴趣的读者可以参考原论文的第五章和附录。上图为在58个Atari 实验环境下,我们提出的Divergence-augmented Policy Optimization 对于 PPO 的相对提高值。Atari环境分类为易探索的环境和难探索的环境。同时Memorie架构已经支持以下features:Prioritized SamplingFrame StackingN-Step LearningMultidimensional RewardTD-lambda return computingSampling from unfinished episodememorie的资源消耗与带宽使用情况https://github.com/lns/dapogithub.comhttps://github.com/lns/memoiregithub.com参考资料:可以运行多个Learner进程进行分布式训练来源:https://www.zhihu.com/question/377263715/answer/1081446215推荐阅读解读!清华、谷歌等10篇强化学习论文总结ICLR 2020 高质量强化学习论文汇总基于模型的强化学习论文合集添加极市小助手微信(ID : cv-mart),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR等技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~△长按添加极市小助手△长按关注极市平台,获取最新CV干货觉得有用麻烦给个在看啦~ 浏览 50点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 RL4JJVM 的深度强化学习库RL4J 是一个与 Deeplearning4j 集成的强化学习框架。DQN(深度 DQ 学习与双 RL4JJVM 的深度强化学习库RL4J是一个与Deeplearning4j集成的强化学习框架。DQN(深度DQ学习与双DQN)AsyncRL(A3C,AsyncNStepQlearning)两者都用于低维(数组)和高维(像素)输入【强化学习】通俗易懂谈强化学习之Q-Learning算法实战机器学习初学者0综述:基于深度强化学习的自动驾驶算法新机器视觉0OpenAI Gym强化学习算法工具包OpenAI Gym 是一个用于开发和比较强化学习算法的工具包。gym 不对代理的结构做任何假设,并TextWorld基于 Python 的强化学习代理训练环境TextWorld是微软开源的一个可扩展的引擎,可用于生成和模拟文本游戏。你可以使用它来训练强化学习(RL)代理,以学习语言理解、记忆、规划和探索等。 TextWorld采用Python编写,可视为用【系统回顾】深度强化学习预训练机器学习算法与Python实战0OpenAI Gym强化学习算法工具包OpenAIGym是一个用于开发和比较强化学习算法的工具包。gym不对代理的结构做任何假设,并且与任何数值计算库兼容,例如TensorFlow或Theano。有关OpenAIGym的白皮书,请访问ht基于DQN强化学习训练一个超级玛丽机器学习实验室0基于DQN强化学习训练一个超级玛丽小白学视觉0点赞 评论 收藏 分享 手机扫一扫分享分享 举报





 返回值,并更新其采样优先级。
返回值,并更新其采样优先级。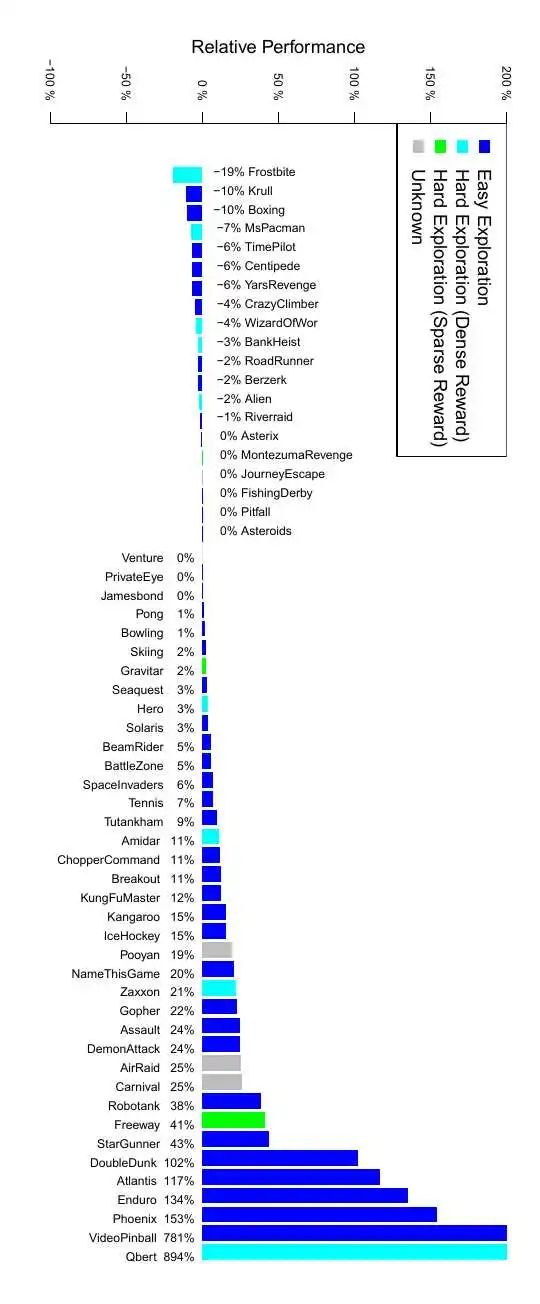

 下载APP返回值,并更新其采样优先级。
下载APP返回值,并更新其采样优先级。