
Transformer大升级!谷歌、OpenAI联合推出分层模型,刷榜ImageNet32刷新SOTA
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
来自谷歌、OpenAI和华沙大学的一个团队提出了一种新的用于语言建模的高效Transformer架构Hourglass,在ImageNet32上达到新的SOTA,证明拥有一个明确的分层结构是Transformer能有效处理长序列的关键。Hourglass在给定相同计算量和存储量的情况下,可以产生比Transformer更好的结果。
Transformer模型在很多不同的领域都取得了SOTA,包括自然语言,对话,图像,甚至音乐。每个Transformer体系结构的核心模块是注意力模块,它为一个输入序列中的所有位置对计算相似度score。
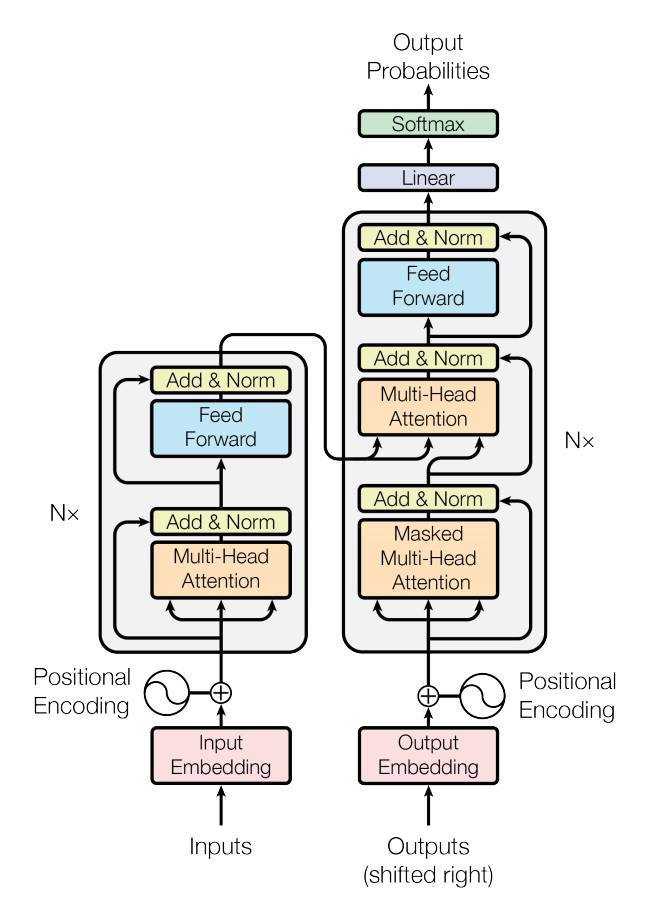
Transformer示意图
然而,Transformer在输入序列的长度较长时效果不佳,因为它需要计算时间呈平方增长来产生所有相似性得分,以及存储空间的平方增长来构造一个矩阵存储这些score,因此将它们扩展到长序列(如长文档或高分辨率图像)是非常费时费内存的。
对于需要长距离注意力的应用,目前已经提出了几种快速且更节省空间的方法,如常见的稀疏注意力。
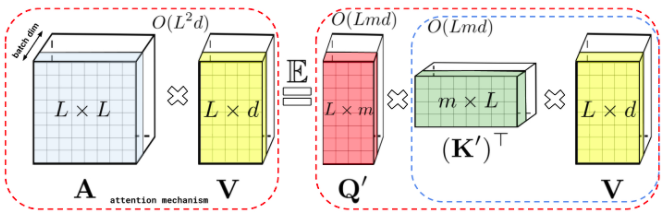
稀疏注意力机制通过从一个序列而不是所有可能的Pair中计算经过选择的相似性得分来减少注意机制的计算时间和内存需求,从而产生一个稀疏矩阵而不是一个完整的矩阵。
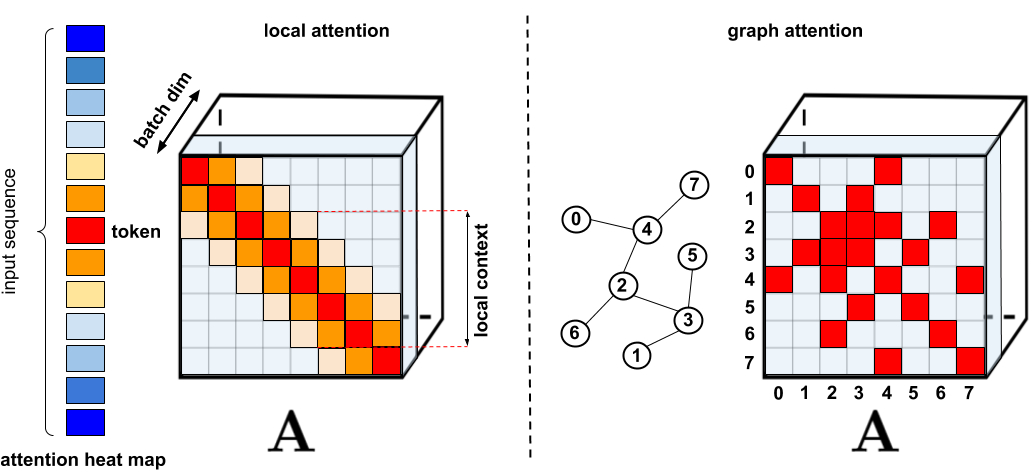
这些稀疏条目可以通过优化的方法找到、学习,甚至随机化,如Performer、Sparse Transformers、Longformers、RoutingTransformers、Reformers和BigBird。
Performer示意图
虽然,稀疏注意力引入了许多技术来修改注意机制,但是,整体Transformer的架构并没有改变。这些稀疏注意机制降低了自我注意的复杂性,但仍然迫使模型要处理与输入相同长度的序列。
为了缓解这些问题,来自谷歌、OpenAI和华沙大学的团队提出了一种新的用于语言建模的高效Transformer架构,称之为Hourglass。

论文地址:https://arxiv.org/pdf/2110.13711v1.pdf
Hourglass假设,拥有一个明确的层次结构是Transformer有效处理长序列的关键,
所以,Hourglass中对激活进行下采样和上采样的不同方法,以便使tokens分层。

Hourglass算法伪代码
Hourglass使用缩短操作将tokens合并,因此减少了总的序列长度,然后结合来自早期层的序列再次对它们进行上采样。
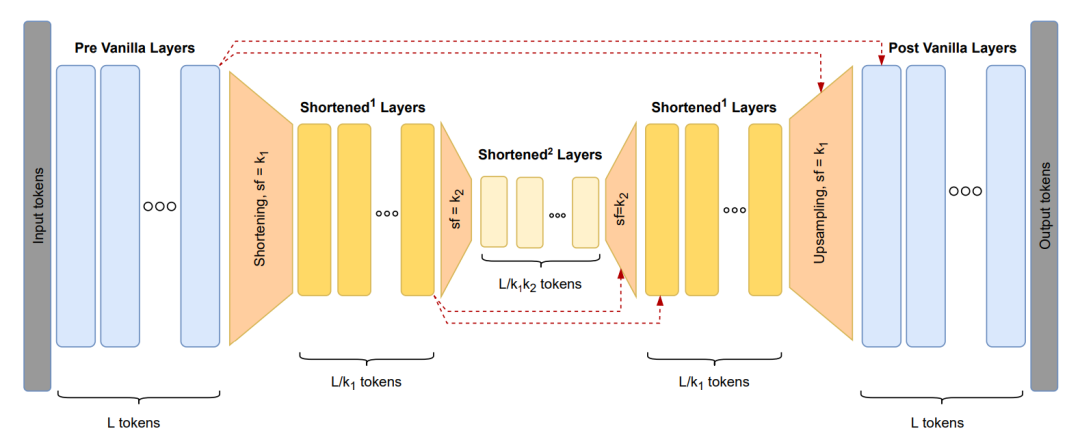
Hourglass架构概述
Hourglass的结构从基本层开始,基本层是在完全tokens序列上运行的一堆Transformer块。
在此之后,插入缩短层,其中k1是缩短因子参数。在缩短之前,序列被向右移动,以防止信息泄露。
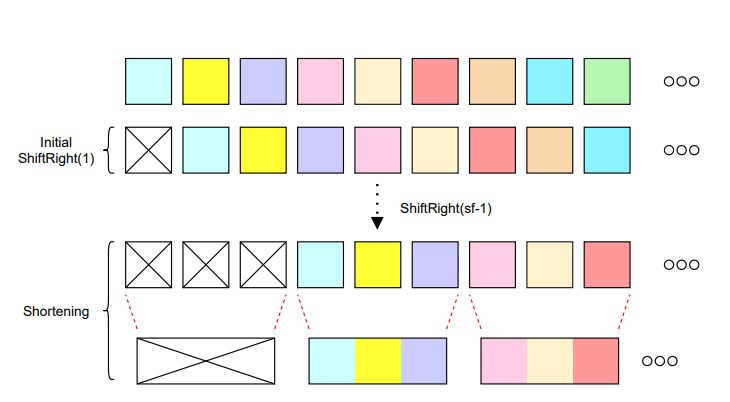
缩短方法示意图
然后递归地插入另一个缩短块,以缩小k1k2倍的最小规模运行。
之后就要对经过处理的tokens进行上采样,上采样层将生成的激活信息恢复到原始tokens的分辨率。
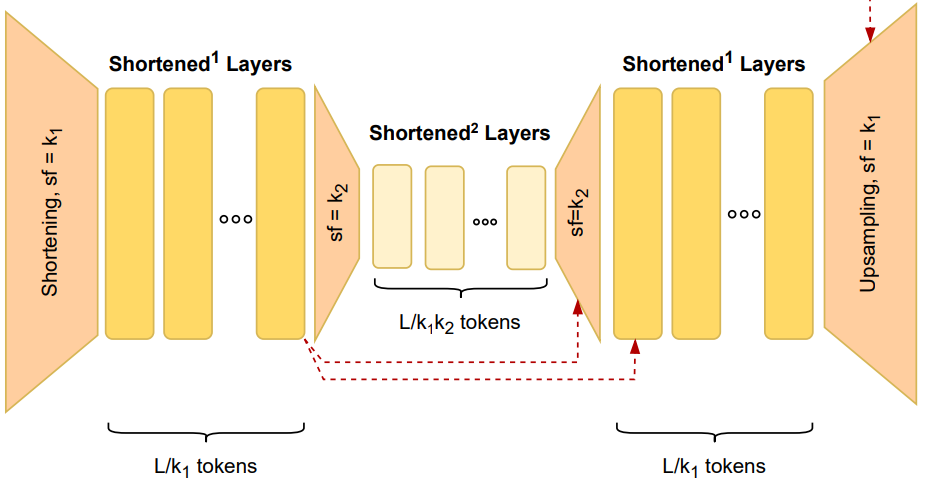
上采样示意图
在上采样和残差连接后,生成的激活信息会由token级别的Transformer普通层处理。
研究人员将Hourglass应用于三个语言建模任务。为了展示Hourglass跨领域泛化能力,他们在一个与自然语言处理相关的数据集和两个来自计算机视觉领域的数据集上训练Hourglass模型。
结果表明,Hourglass在给定相同计算量和存储量的情况下,对Transformer基线进行了改进,可以产生比Transformer更好的结果。
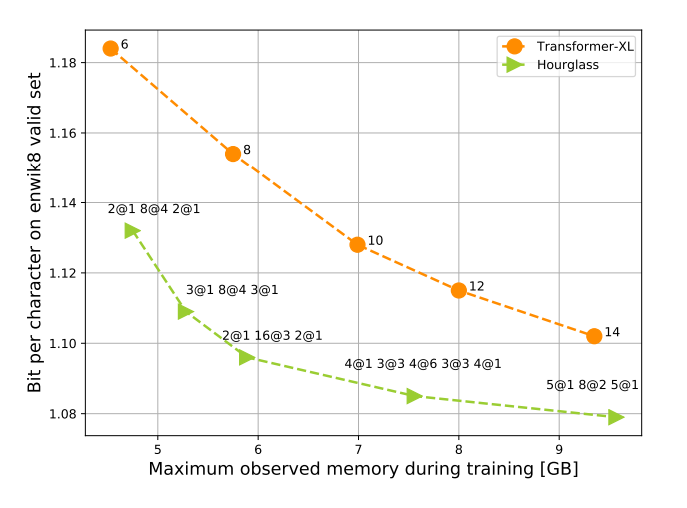
Transformer-XL与Hourglass的训练所用存储的比较
特别是,Hourglass在广泛研究的enwik8基准上也提高了语言建模效率。
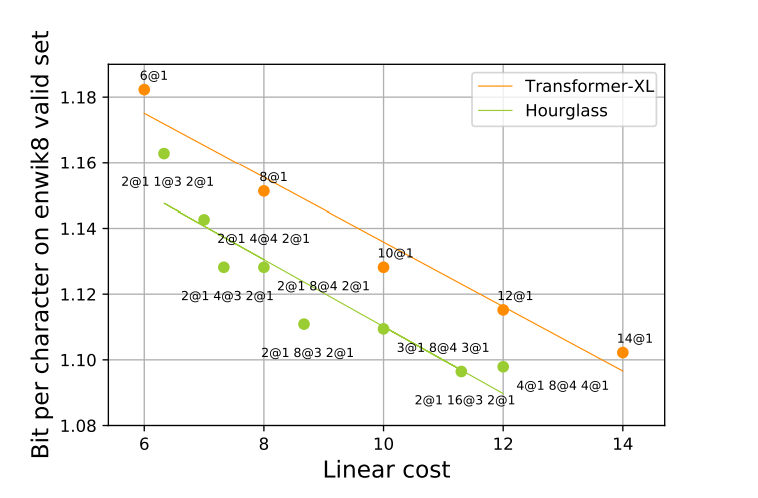
基线(红色)和分层Transformer(绿色)的每字符位数与计算成本的关系
Enwik8是一个字节级语言建模基准,包含1亿字节未处理的英文维基百科文本。
在测试集上评估Hourglass模型,将其拆分为序列长为6912,步长为128的重叠序列,并仅计算最后128个token的测试损失。使用(5@1,24@3,5@1)层次结构,最终得到0.997BPC。

Enwik8结果
Hourglass还在ImageNet32生成任务上实现自回归Transformer模型新的SOTA。
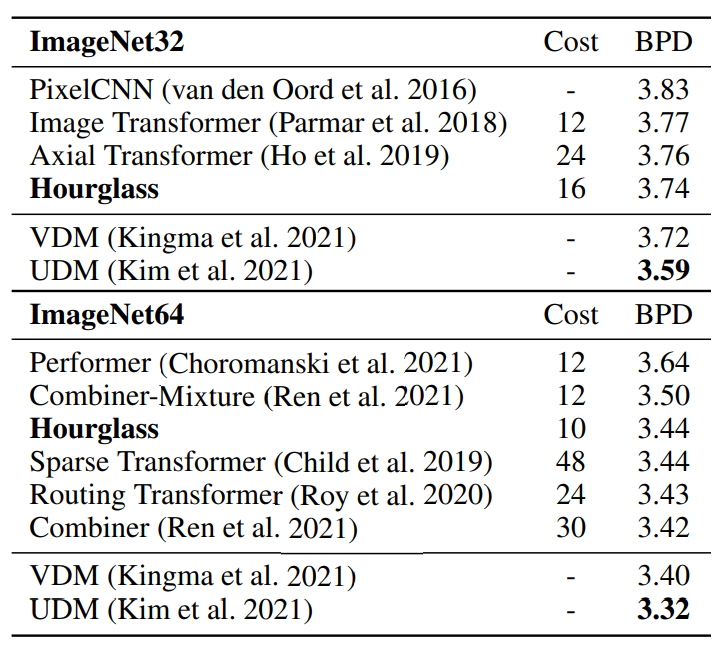
下采样图像的每维位数(BPD),自回归模型和非自回归模型用一条水平线分开

模型生成的例子,其中每个图像的下半部分由我们的模型生成,由上半部分提示
Hourglass在ImageNet32生成任务的自回归模型中获得最佳结果,在其他图像生成和语言建模任务中也获得极具竞争力的结果。
特别值得说明的是,Hourglass可以用于任何注意力类型,这为未来处理更长序列的Transformer的相关研究开辟了许多方向,提高了效率和准确性之间的权衡。
参考资料:
https://arxiv.org/pdf/2110.13711.pdf https://www.reddit.com/r/MachineLearning/comments/qmm9z7/r_hierarchical_transformers_are_more_efficient/
如果觉得有用,就请分享到朋友圈吧!

点个在看 paper不断!