
GPU多卡并行训练总结(以pytorch为例)
点击左上方蓝字关注我们

为什么要使用多GPU并行训练
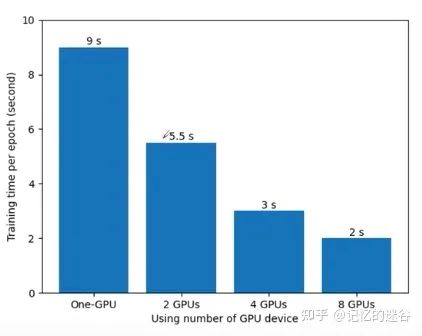
常见的多GPU训练方法
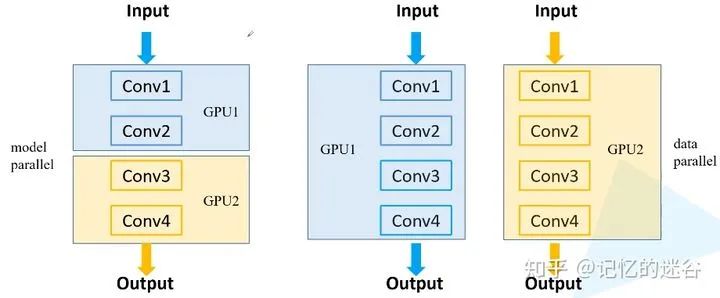
误差梯度如何在不同设备之间通信?
在每个GPU训练step结束后,将每块GPU的损失梯度求平均,而不是每块GPU各计算各的。
BN如何在不同设备之间同步?
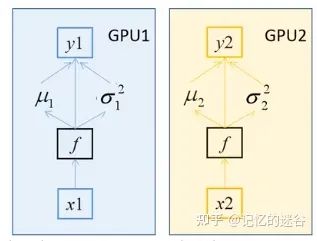
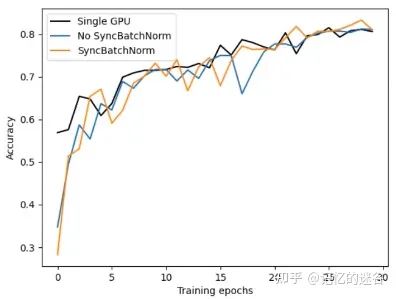
两种GPU训练方法
DataParallel 和 DistributedDataParallel
DataParallel是单进程多线程的,仅仅能工作在单机中。而DistributedDataParallel是多进程的,可以工作在单机或多机器中。
DataParallel通常会慢于DistributedDataParallel。所以目前主流的方法是DistributedDataParallel。
pytorch中常见的GPU启动方式

def init_distributed_mode(args):
# 如果是多机多卡的机器,WORLD_SIZE代表使用的机器数,RANK对应第几台机器
# 如果是单机多卡的机器,WORLD_SIZE代表有几块GPU,RANK和LOCAL_RANK代表第几块GPU
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
# LOCAL_RANK代表某个机器上第几块GPU
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu) # 对当前进程指定使用的GPU
args.dist_backend = 'nccl' # 通信后端,nvidia GPU推荐使用NCCL
dist.barrier() # 等待每个GPU都运行完这个地方以后再继续
def main(args):
if torch.cuda.is_available() is False:
raise EnvironmentError("not find GPU device for training.")
# 初始化各进程环境
init_distributed_mode(args=args)
rank = args.rank
device = torch.device(args.device)
batch_size = args.batch_size
num_classes = args.num_classes
weights_path = args.weights
args.lr *= args.world_size # 学习率要根据并行GPU的数倍增
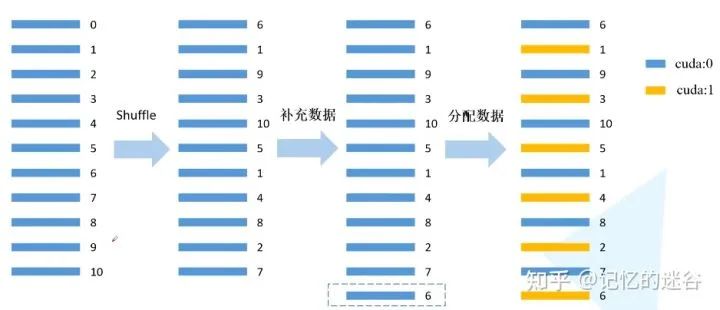
#给每个rank对应的进程分配训练的样本索引
train_sampler=torch.utils.data.distributed.DistributedSampler(train_data_set)
val_sampler=torch.utils.data.distributed.DistributedSampler(val_data_set)
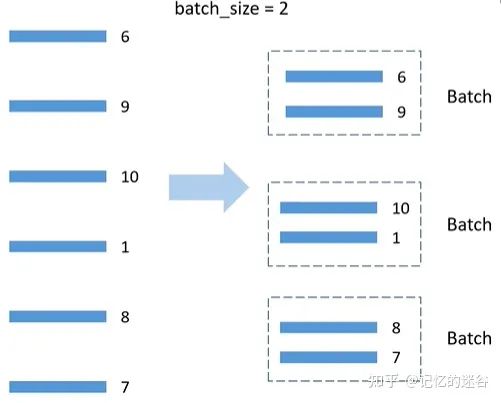
#将样本索引每batch_size个元素组成一个list
train_batch_sampler=torch.utils.data.BatchSampler(
train_sampler,batch_size,drop_last=True)
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_sampler=train_batch_sampler,
pin_memory=True, # 直接加载到显存中,达到加速效果
num_workers=nw,
collate_fn=train_data_set.collate_fn)
val_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
sampler=val_sampler,
pin_memory=True,
num_workers=nw,
collate_fn=val_data_set.collate_fn)
# 实例化模型
model = resnet34(num_classes=num_classes).to(device)
# 如果存在预训练权重则载入
if os.path.exists(weights_path):
weights_dict = torch.load(weights_path, map_location=device)
# 简单对比每层的权重参数个数是否一致
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(load_weights_dict, strict=False)
else:
checkpoint_path = os.path.join(tempfile.gettempdir(), "initial_weights.pt")
# 如果不存在预训练权重,需要将第一个进程中的权重保存,然后其他进程载入,保持初始化权重一致
if rank == 0:
torch.save(model.state_dict(), checkpoint_path)
dist.barrier()
# 这里注意,一定要指定map_location参数,否则会导致第一块GPU占用更多资源
model.load_state_dict(torch.load(checkpoint_path, map_location=device))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后的全连接层外,其他权重全部冻结
if "fc" not in name:
para.requires_grad_(False)
else:
# 只有训练带有BN结构的网络时使用SyncBatchNorm采用意义
if args.syncBN:
# 使用SyncBatchNorm后训练会更耗时
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
# 转为DDP模型
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
# optimizer使用SGD+余弦淬火策略
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005)
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
train_sampler.set_epoch(epoch)
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
sum_num = evaluate(model=model,
data_loader=val_loader,
device=device)
acc = sum_num / val_sampler.total_size
def train_one_epoch(model, optimizer, data_loader, device, epoch):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
mean_loss = torch.zeros(1).to(device)
optimizer.zero_grad()
# 在进程0中打印训练进度
if is_main_process():
data_loader = tqdm(data_loader)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
loss = loss_function(pred, labels.to(device))
loss.backward()
loss = reduce_value(loss, average=True) # 在单GPU中不起作用,多GPU时,获得所有GPU的loss的均值。
mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses
# 在进程0中打印平均loss
if is_main_process():
data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
return mean_loss.item()
def reduce_value(value, average=True):
world_size = get_world_size()
if world_size < 2: # 单GPU的情况
return value
with torch.no_grad():
dist.all_reduce(value) # 对不同设备之间的value求和
if average: # 如果需要求平均,获得多块GPU计算loss的均值
value /= world_size
return value
@torch.no_grad()
def evaluate(model, data_loader, device):
model.eval()
# 用于存储预测正确的样本个数,每块GPU都会计算自己正确样本的数量
sum_num = torch.zeros(1).to(device)
# 在进程0中打印验证进度
if is_main_process():
data_loader = tqdm(data_loader)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
sum_num = reduce_value(sum_num, average=False) # 预测正确样本个数
return sum_num.item()
if rank == 0:
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.module.state_dict(), "./weights/model-{}.pth".format(epoch))
if rank == 0:# 删除临时缓存文件
if os.path.exists(checkpoint_path) is True:
os.remove(checkpoint_path)
dist.destroy_process_group() # 撤销进程组,释放资源
END
整理不易,点赞支持一下吧↓
评论