
Facebook AI PyTorch数据并行训练秘籍大揭秘

极市导读
本文介绍了PyTorch最新版本下分布式数据并行包的系统设计、具体实现和结果评估等方面的内容。>>加入极市CV技术交流群,走在计算机视觉的最前沿
在芯片性能提升有限的今天,分布式训练成为了应对超大规模数据集和模型的主要方法。本文将向你介绍流行深度学习框架 PyTorch 最新版本( v1.5)的分布式数据并行包的设计、实现和评估。

系统设计
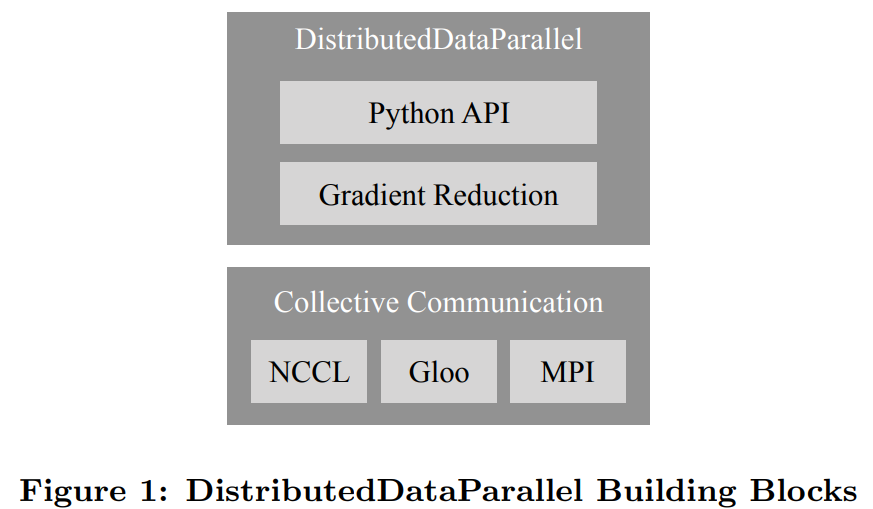
从相同的模型状态开始;
每次迭代花费同样多的梯度。
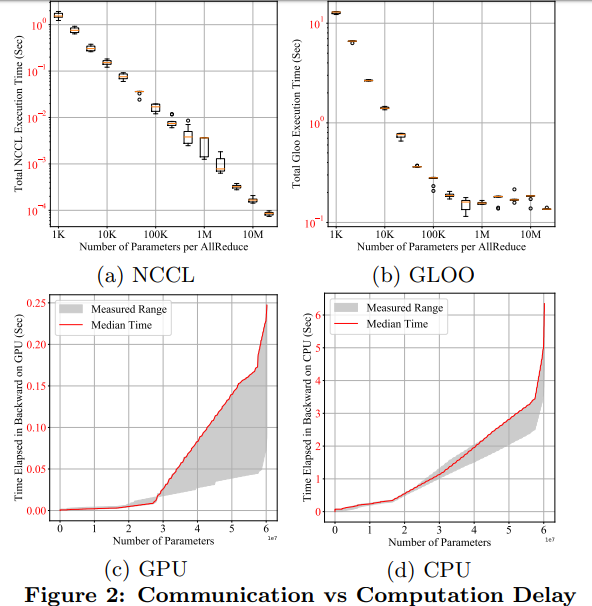
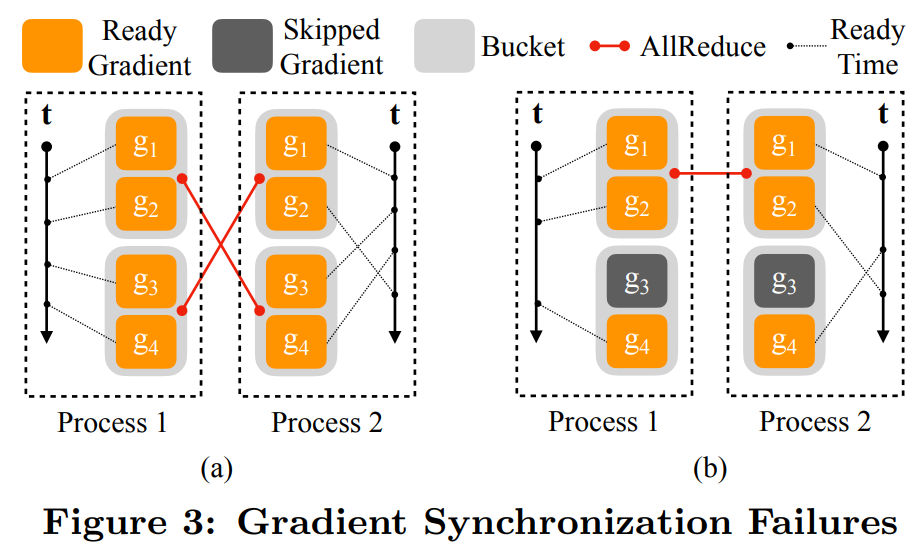

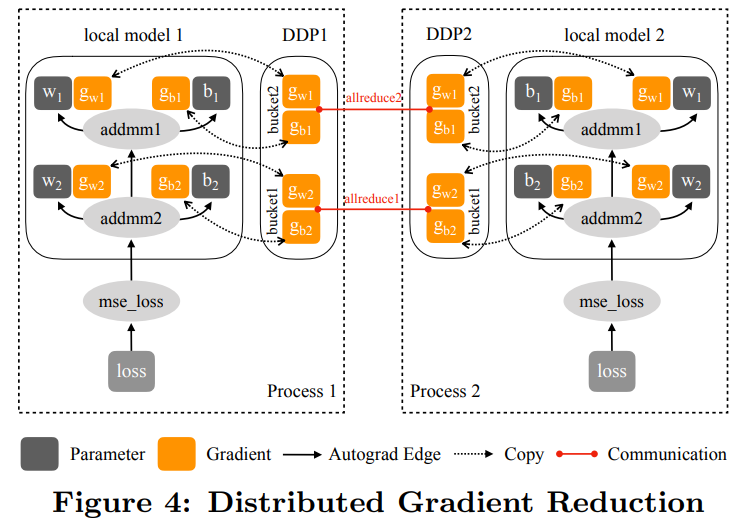

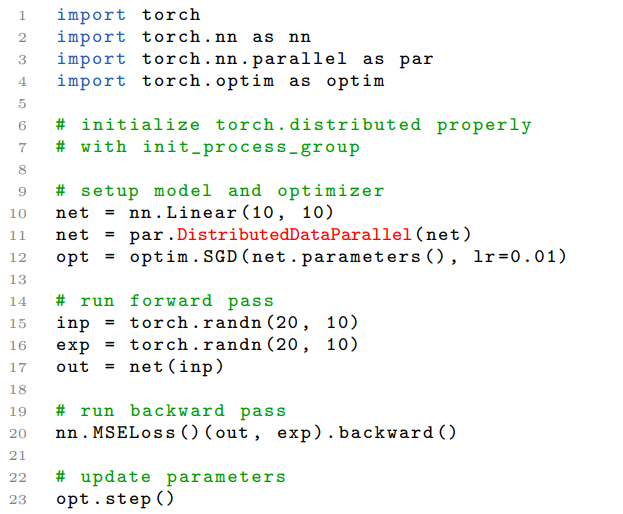
具体实现
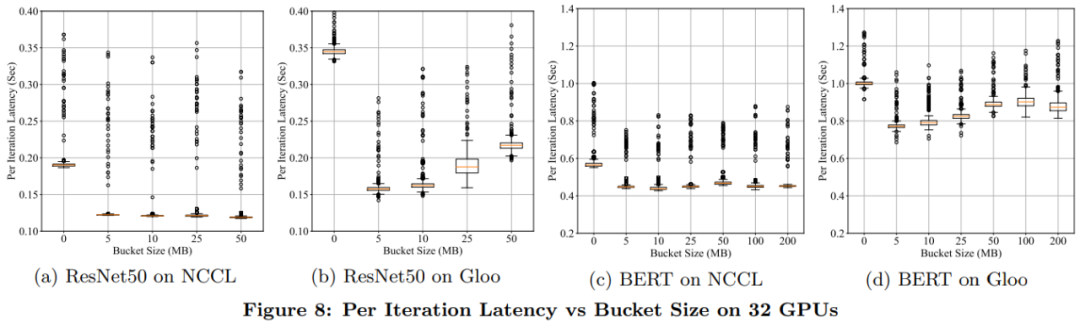
分组处理以找出 DDP 中运行 AllReduce 的进程组实例,它能够帮助避免与默认进程组混淆; bucket_cap_mb 控制 AllReduce 的 bucket 大小,其中的应用应调整 knob 来优化训练速度; 找出没有用到的参数以验证 DDP 是否应该通过遍历 autograd 图来检测未用到的参数。
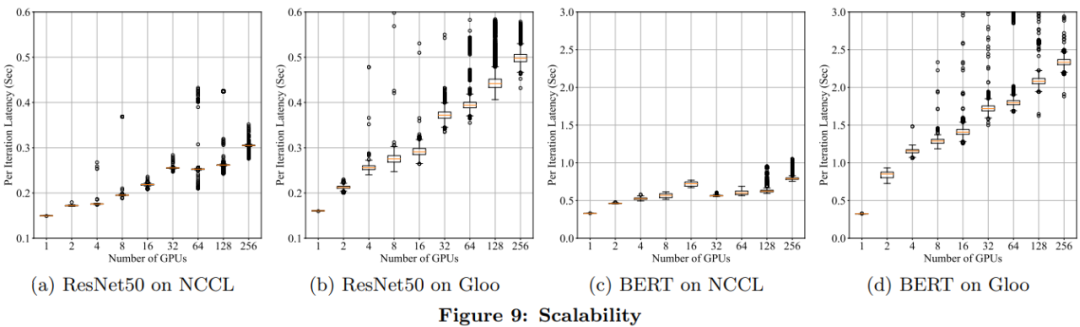
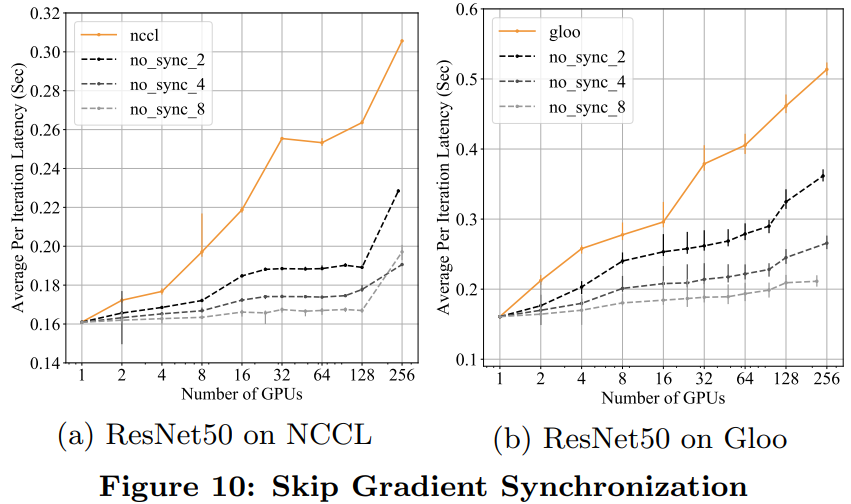
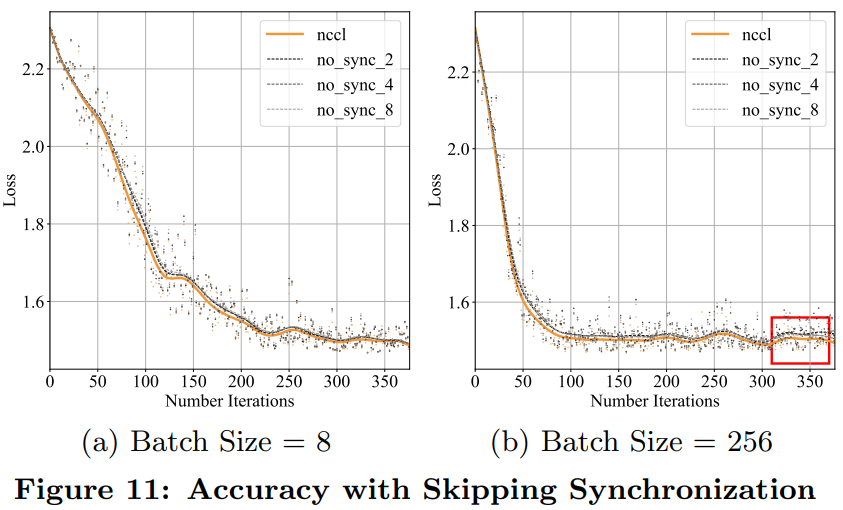
实验评估
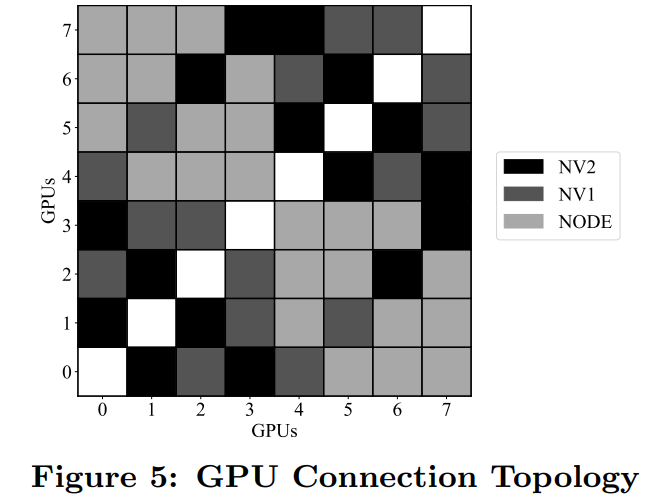
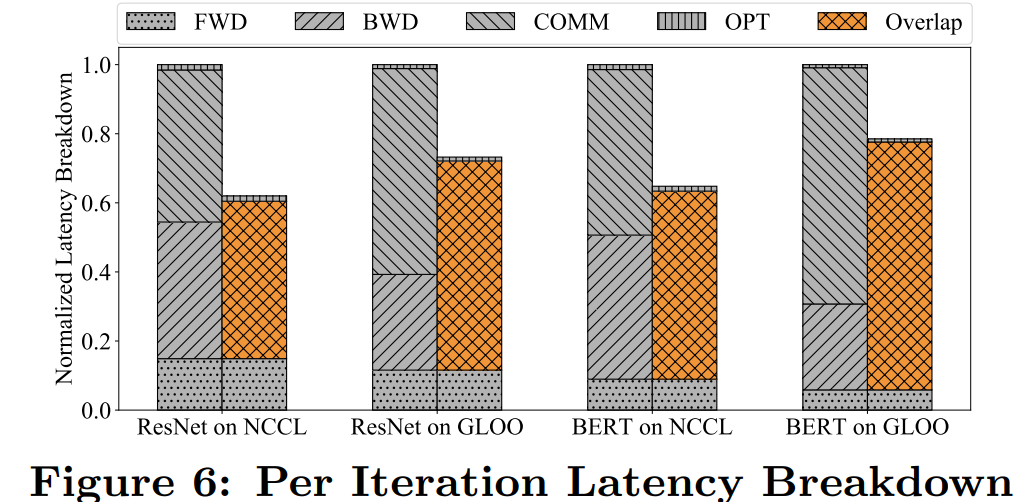
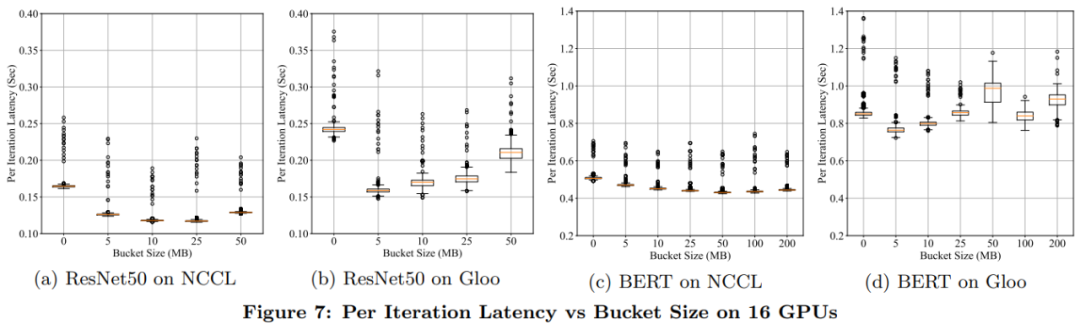
推荐阅读

评论