
逻辑回归(Logistic Regression)是一种统计机器学习方法,简单易用,却涉及很多知识点。正所谓麻雀虽小,五脏俱全。大多数教程都是从定义和原理出发,来讲解逻辑回归,容易显得晦涩难懂。本文将结合实例和图示,帮助读者在7分钟内搞懂逻辑回归算法。
功能
逻辑回归一般用于二分类任务,并能给出两个类的相应概率。
常见的应用包括垃圾邮件判别、银行判断是否给用户贷款等等。当然,二分类问题可以扩展到多分类问题。
做二分类任务,最简单的判别函数是阶跃函数,如下图红线所示。当 时判断为正类(1),反之为负类(0)。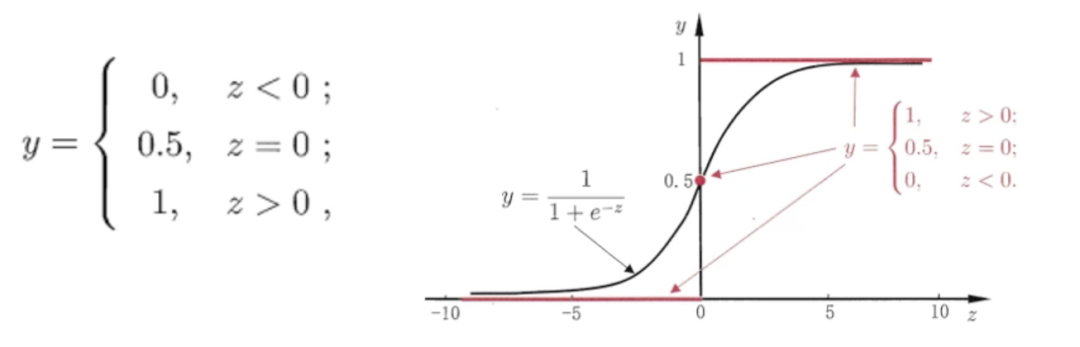
但阶跃函数不连续,过于“死板”,不便于后续求导优化。因此用logistic function(上图黑线)代替,因为呈现“S”形,也称为 sigmoid function,对应公式:
定义域为整个实数集合,值域为0~1,相当于概率值。
为何不叫逻辑分类?
首先,“逻辑”指的是“logistic”(音译),“回归”来源于线性回归的 ,使用线性回归去拟合逼近一个决策边界,使得按照这个边界进行数据分类后的总损失最小。以概率0.5作为界线,将数据分为正例和反例。当 ,对应正例(趋近于概率1);当 ,对应负例(趋近于概率0)。这是在使用回归的思想去解决分类问题,所以称为逻辑回归。等价于在线性回归外包裹了一层sigmoid函数,将离散值映射为0和1之间的概率,以0.5为界。核心问题
理解逻辑回归的一个核心问题是,如何求解决策边界 ?求最优决策边界,等价于求 的值。当样本的真实标签 是1和0时,我们分别定义一个损失函数:
以 为例,当模型的预测值 趋向1时,损失函数取值也应该越来越小;反之,当 趋向0时,损失函数值越来越大,可以通过函数 体现。模型的训练目的是尽可能减小损失,所以会让输出值朝着1的方向学习。是否可以将两类的cost函数合并到一块,方便计算总损失呢?
对于下图的样本点,绿线是决策边界。绿线上部 ,距离绿线越远 越大,预测值 越接近1。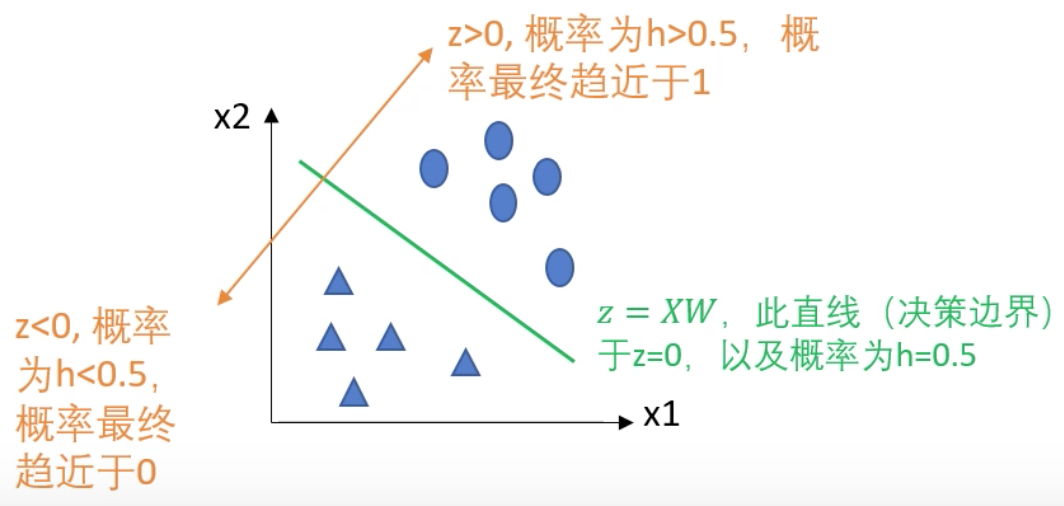
求解边界
明确了损失函数后,我们来计算模型参数的最优值。首先需要计算cost对参数 的导数,再借助梯度下降等算法微调参数值,不断逼近最优解。假设我们有10个样本点,每个样本包含3个特征,则 维度为[10, 3], 维度为[3, 1], 和 的维度为[10, 1]。cost的维度也是[10, 1]。cost和H相关,H和Z相关,Z和WX相关,存在关系映射:cost~H~Z~X。根据链式求导法则,整个计算过程如下: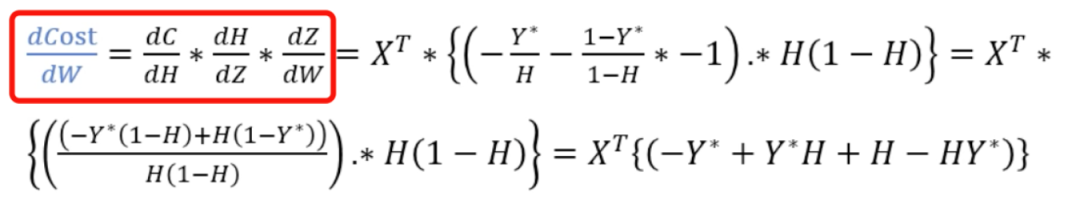
梯度下降法
刚刚我们使用了梯度下降法迭代求解最优的 ,一共分为3步:当cost函数是凸函数时,可以保证cost降到全局最小,否则可能只走到局部最小。

使用逻辑回归,我们可以使用python、C++等语言自己实现,或借助机器学习工具包Sklearn中的接口 LogisticRegression [2]。现在,大家是不是理解了逻辑回归的思想呢?如有疑问,欢迎交流(vx:cs-yechen)
在NLP情报局公众号后台回复“三件套”,即可获取深度学习三件套:《PyTorch深度学习》,《Hands-on Machine Learning》,《Python深度学习》参 考 文 献
[1] 文小刀机器学习|逻辑回归:https://www.bilibili.com/video/BV1As411j7zw[2] LogisticRegression: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html欢 迎 关 注 👇
原创不易,有收获的话请帮忙点击分享、点赞、在看吧🙏

 下载APP
下载APP