
实践|手写逻辑回归算法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
尽管对于机器学习来说,理论是非常重要的内容,但是持续的理论学习多少会有些审美疲劳。今天,我们就试着用代码来简单实现一下逻辑回归,也方便大家更好地理解逻辑回归的原理,以及机器学习模型在实践中是怎么运作的。
一、逻辑回归算法步骤简述
构建一个逻辑回归模型有以下几步:
收集数据:采用任意方法收集数据
准备数据:由于需要进行距离计算,因此我们要求数据类型为数值型。若是结构化数据格式更佳
分析数据:采用任意方法对数据进行分析
训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数
测试算法:训练步骤完成后将对算法进行测试
使用算法:首先我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归运算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其它的分析工作。
并且,因为逻辑回归适用于二元分类,因此,我们这次的这组数据的预测值仅有0和1(其它类型的数值也没关系,但都以0,1表示会比较方便)分别代表二元分类中的negative class 和 possitive class。
二、选择输入函数:sigmoid函数
因为我们已经确定是逻辑回归模型(若是未知模型的数据我们还需要从头推导模型),所以作为分类器的输出函数我们选择逻辑函数,又称sigmoid函数:
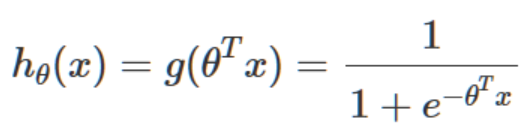
我们将sigmoid函数的输入θTx记为z,z由下面这个公式导出:

显然,x便是我们的输入变量。
三、选择优化算法:梯度上升法
作为第一次训练,我们选择比较简单的参数更新方法:梯度上升法,它细分为两种,一种是精度比较高但消耗比较大的批梯度上升法:

另一种是精度较低但速度较快的随机梯度上升法:
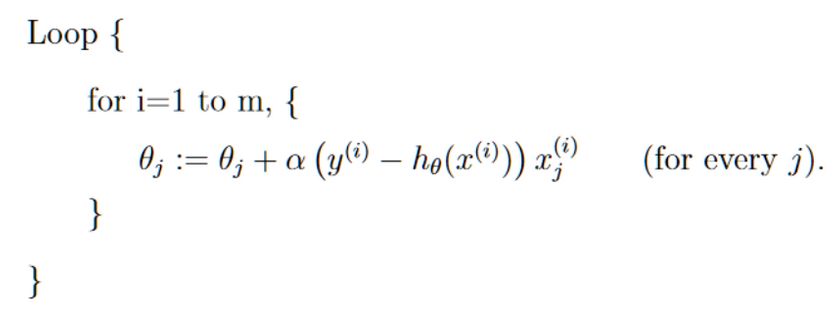
四、观察数据集
在数据集的样本特征还处在比较的低维的空间(方便我们观察的空间,像是二维(两个特征)或者三维(三个特征))的时候,我们可以为数据集绘制坐标图形从而对坐标进行简单地观察。尽管在现实任务中基本上不可能出现特征空间是二维或者三维的数据集,但在用代码实现理论模型的时候,这些简单的数据集能够让我们非常直观的看到实现的模型的效果而不需要去借助比较复杂的模型评估方法,换句话说,它们能够很好的辅助我们实现模型。
在现实任务中我们往往也有在处理数据前对数据集进行观察的必要,不论是制定数据预处理的策略还是选择模型的策略,观察并且了解自己将要处理的数据集都是非常非常重要的一项工作。
这里我用的数据集是来自Peter Harrington《机器学习实战》第五章上的数据集,github链接(https://github.com/pbharrin/machinelearninginaction)
这个数据集的样本特征空间只有两维,分别为x1和x2,标签仅有正类(1)和负类(0),我们用matplotlib模块来绘制它在平面直角坐标系上的数据分布图像:

数据集导入和输出代码:


函数loadDataSet将数据集从testSet.txt逐行读取并存入两个矩阵中。testSet中每一行的数据有三个值,分别是X1,X2和数据对应的类别标签。并且,注意到我们在dataMat中的第一个值设置为1,那其实是X0的值,这在这里单纯的数据集输出中没有太大的作用,但是会方便之后我们导入模型时的计算。shape函数读取矩阵的行数m和列数n。
figure建立绘图平面,addsubplot表示我们要在平面上建立绘制几个图表,111说明我们希望绘制一个占整个平面1∗1大小的图表,然后选取第一个图表。
scatter表示散点图,参数marker='s'表示点的形状为方形,它还可以接收一个参数s=<NUMBER>来调整点的大小。
五、批梯度上升训练
得知数据集的输出型状后,我们可以着手构建模型了,这一次我们先使用梯度上升模型。
我们先来构筑sigmoid函数:

表示接收一个输入inX可以认为是我们在sigmoid函数中所说的’z’,用sigmoid函数输出。
然后构建梯度上升函数:

第一个参数是全部输入样本组成的二维数组,每一个样本包含3个特征分别是X0,X1,X2,因此,用mat函数转换后的dataMat是一个3 x 100的输入矩阵。第二个参数是每一个样本的标签组成的矩阵,为了方便计算,我们在转化它为1 x 100的矩阵后还要用transpose()将其转置。
变量alpha表示梯度上升中的步长,maxCycles表示我们将要进行的步数,一般来说我们也可以通过设定条件让程序判断收敛情况来自行决定合适的步长,但这一步我们暂且先简化为这样。weights便是我们希望求得的参数,可以看作是上面给出的梯度上升的数学模型中的θ,这里我们先将其初始化为一个 3 x 1的矩阵分别对应数据的3个特征。
然后我们循环更新weights值,以找到最合适的weights。更新方式便是梯度上升更新:
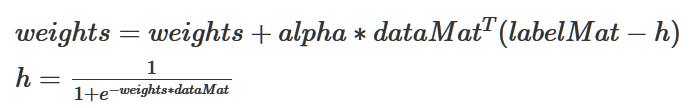
我们可以把它与上面的梯度更新公式对比一下。然后通过500步更新得到目标参数weights。
我们可以用print输出看看我们得到的参数:

然后将其绘制到我们一开始做的数据集表示图上。


发现效果不错。其中,函数getA()表示将矩阵weights转换成数组,如果我们不这么做的话,输出一下x和y就会发现这一步的必要性:

我们会发现y的值是被包裹在两个[]里面的,实际上可以认为y是一个嵌套了两层的一维矩阵,这也是为什么,我们要用getA来将weights从矩阵转换回数组。
y的计算方式或许也会给人带来疑问:实际上,我们知道,我们希望得到的是一条将两个数据集分开的直线。因此,我们在给出一串连续的横坐标(代码中就是从-3到3每隔0.1取一个横坐标)组成的向量后,就可以根据直线的方程y=kx+b(转换成−w2X2=w1X1+w0)
计算这一连串横坐标对应的y轴坐标,然后将其绘制到散点图上。
六、随机梯度上升训练
因为我们这里的样本比较小,所以我们的批梯度上升可以很快的就得到我们想要的结果,但实际上,很多数据集包含的内容都非常巨大,因此,为了能够快速执行分类任务,我们有时候会牺牲一些精度来换取运算的速度。这便是我们的随机梯度上升法,它的原理我在机器学习理论中的笔记有讲,这里就不再赘述:



可以得到我们随机梯度下降的结果:

发现结果没有之前的准确,这是当然的,因为我们牺牲了精度,随机梯度上升对参数weights的每一次更新都只用了一个样本,因此速度上相较批梯度上升会大幅提升。
下面这张图表示每一次更新回归参数X0,X1,X2的值,根据样本次数,我们总共更新了100次:
绘图代码:

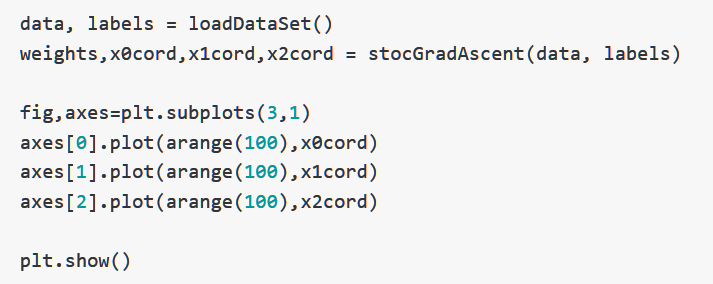
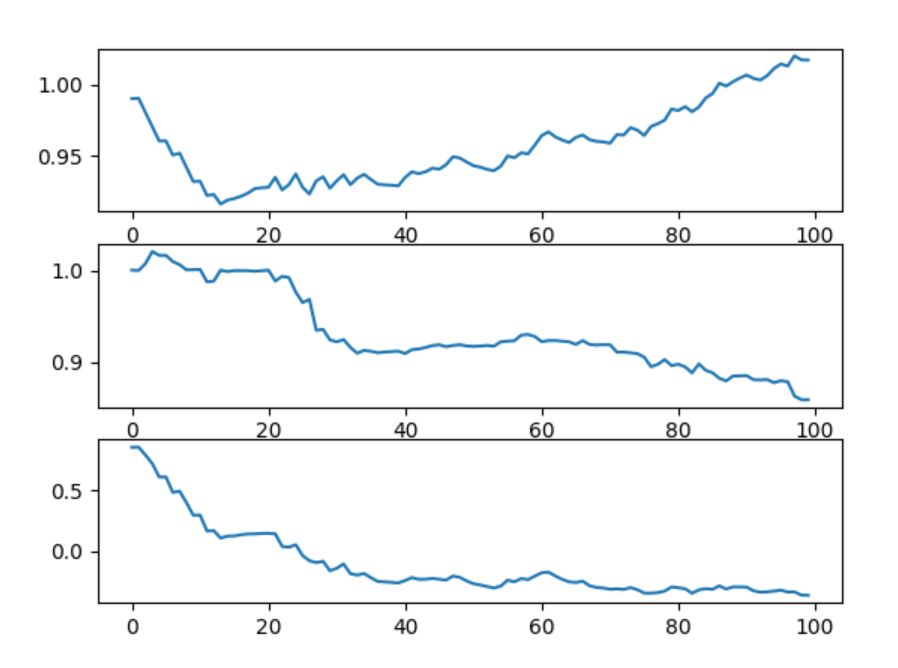
可以看出来,回归参数的上下波动非常巨大,并且时常会往与梯度不同的方向更新,X2在开始的几次更新之后很快达到了稳定,但是X0和X1则没有。
并且,我们可以发现,参数在趋于稳定之后依然会有局部波动,这是因为数据集中并非所有的数据都可以确保正确分类(因为数据集并非线性可分)。
资料来源参考:
Peter Harrington.《机器学习实战》,人民邮电出版社
数据集来源 Github:Peter Harrington(https://github.com/pbharrin/machinelearninginaction)
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~