
项目实践|如何在较暗环境进行人脸检测?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|Datawhale
计算机视觉在人脸检测领域的应用已经较为成熟,但依然存在较多难点。其中一大难点是光照问题,由于人脸的3D结构,光照投射出的阴影,会加强或减弱原有的人脸特征。如何解决光照问题对人脸检测带来的影响呢?

本文目录:
1. 基本LBP
1.1 概念理解
1.2 主要步骤
2. 圆形领域的LBP算子
2.1 概念理解
2.2 计算方法
3. 旋转不变的LBP算子
4. 统一化的LBP算子
4.1 理论基础
4.2 统一化的意义
4.3 收集箱个数计算
5. 案例实战
5.1 读取图片
5.2 加载级联文件
5.3 人脸检测
5.4 处理脏数据
邻域的类型可分为四邻域、D邻域、八邻域。
四邻域:该像素点的上下左右四个位置;
D领域:该像素点斜对角线上的四个相邻位置。
八邻域:四邻域与D邻域的并集。
基本的LBP算子考虑的是像素的八邻域。
例如,在某些情况下,阳光照射强度更低,导致拍摄图像的整体亮度降低,但是实际上每个像素之间的差值仍然是固定的。那么在这种情况下,在图片亮度对LBP特征编码无影响。
使用一个3*3的矩形,处理待判断像素点及其邻域之间的关系。
如果A的像素值大于其邻近点的像素值,则得到0。 如果A的像素值小于其邻近点的像素值,则得到1。
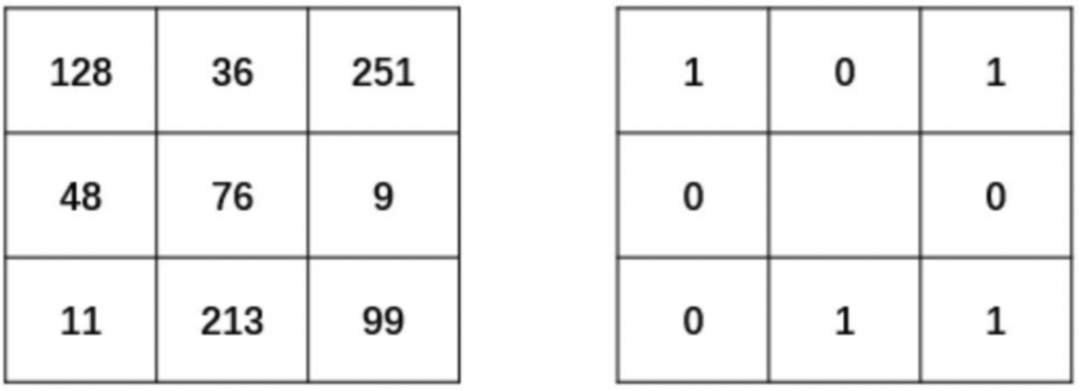
如下图LBP原理示意图所示,在左侧的区域中,中心点的像素为76,并设置它为此次的阈值。然后现在我们对该中心点的8邻域做进一步的处理。
将中心点周围的8个位置中灰度值大于76的像素点处理为1。例如,其邻域中像素值为128、251、99、213的点,都被处理为1,填入对应的像素点位置上。
将中心点周围的8个位置中灰度值值小于76的像素点处理为0。例如,其邻域中像素值为36、9、11、48的点,都被处理为0,填入对应的像素点位置上。
最后得到的二值结果如右图所示。
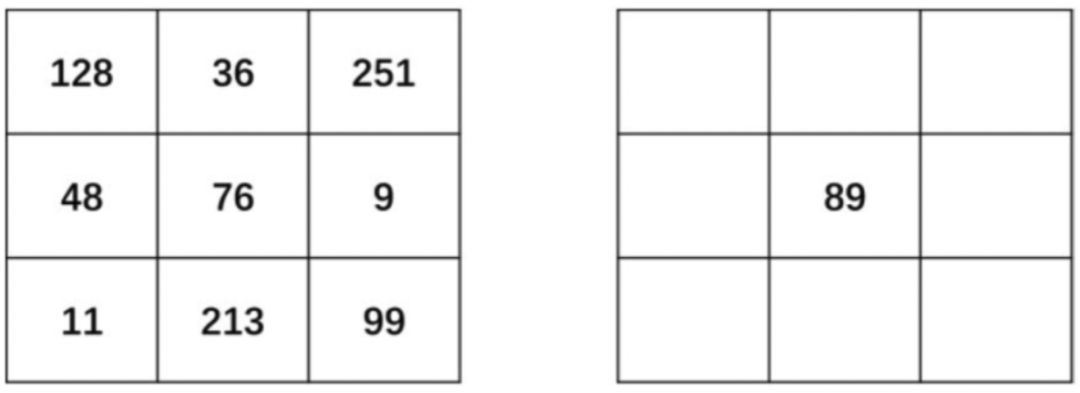
步骤2:中心点处理
假设此时有一幅100*100大小的图像。
在初始化时,将该图划分为10*10个Block,其中每个Block的大小为10*10。 对每个Block的像素点提取其LBP特征,并建立一个计算某个“数字”出现的频率统计直方图。 结束时,将生成10*10个统计直方图,选择性地对直方图进行规范化处理。 连接所有小块的(规范化的)直方图,整合后构成了整个窗口的特征向量,用来描述这幅图片。 得到特征向量之后,就可以使用各类算法对该图像进行特定的处理了。
基本LBP算子可以被进一步推广到使用不同大小和形状的邻域。采用圆形的邻域并结合双线性插值运算使得我们可以获得任意半径和任意数目的邻域像素点。该圆形邻域可以用表示,其中P表示圆形邻域内参与运算的像素点个数,R表示邻域的半径。
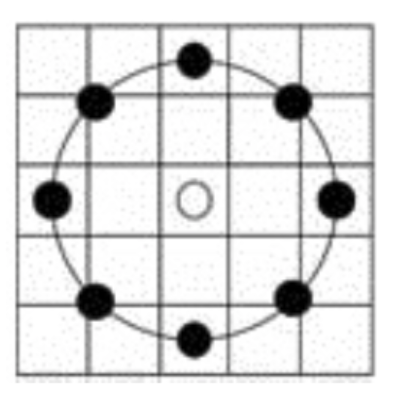
假设此时给出了一个半径为2的8邻域像素的圆形邻域,图中每个方格对应一个像素。
处在方格中心的邻域点(左、上、右、下4个黑点):以该点所在方格的像素值作为它的值 不在方格中心的邻域点(斜45°方向的4个黑点):线性插值法确定其值。
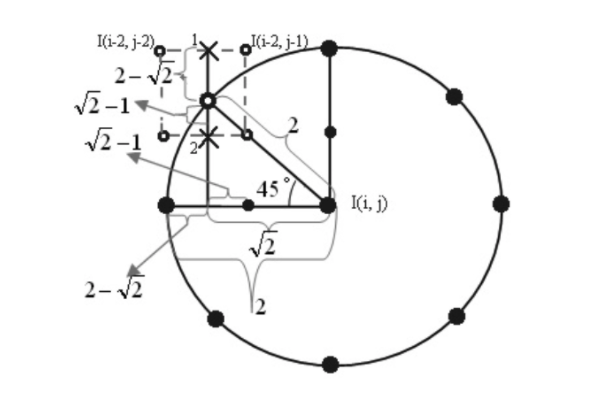
同理计算出点2的值如下:
再计算出点1和点2竖直的线性插值。
如下图所示,黑点代表0,白点代表1,假设初始的灰度值为255。经过7次旋转,得到7个不同的二进制序列,并分别转换为相应的十进制数,最后取到最小值“15”为最终中心点的LBP值,且序列为“00001111”。

二进制序列中存在从1到0或者0到1的转变,可以称作是一次跳变。下面我们将举例说明跳变次数的计算:

对于一个局部二进制模型而言,在将其二进制位串视为循环的情况下,如果其中包含的从0到1或者从1到0的转变不多于2个,则称为统一化模式。所以上例中的模式“01010000”就不属于统一化模式。
序列中包含的跳变为2次以上的,可以称为混合模式。
4.2 统一化的意义
假设图像分块区域大小为,则像素的总数为360个。如果采用8邻域像素的标准LBP算子,收集箱(特征)数目为个,平均到每个收集箱的像素数目还不到2个。但是在统一化LBP算子的收集箱数目为59个(58个统一化模式收集箱加上1个非统一化模式收集箱),平均每个收集箱中将含有6个左右的像素点,因此更具有统计意义。
0个转变(2个):
1个转变(7 x 2 = 14):01111111,00111111,00011111,00001111,00000111,00000011,00000001。 2个转变(42):
1 x 2:01111110
总结一下,经过上面的计算知道,这种统一化后的编码个数可以用公式(4)表示。
这次仍然是把待读取的照片放入img包中,图片名为cv_3.jpeg。
import cv2import matplotlib.pyplot as pltfilepath = "../img/cv_3.jpeg"# 读取图片,路径不能含有中文名,否则图片读取不出来image = cv2.imread(filepath)# 显示图片plt.imshow('image', image)plt.show()
这次的待检测图片:

# 需要是Anaconda虚拟环境下的绝对路径cascade_path = "/Users/sonata/opt/anaconda3/share/opencv4/lbpcascades/lbpcascade_frontalface_improved.xml"# 下载到了本地使用# 加载人脸级联文件faceCascade = cv2.CascadeClassifier(cascade_path)
OpenCV给我们使用特征数据的方法:
def detectMultiScale(self, image, scaleFactor=None, minNeighbors=None, flags=None, minSize=None, maxSize=None)params:
1. scaleFactor: 指定每个图像比例缩小多少图像
2. minNeighbors: 指定每个候选矩形必须保留多少个邻居,值越大说明精度要求越高
3. minSize:检测到的最小矩形大小
4. maxSize: 检测到的最大矩形大小
所以我们使用此方法检测图片中的人脸
# 灰度转换gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 人脸检测faces = faceCascade.detectMultiScale(gray, 1.1, 2, minSize=(100, 100))print(faces) # 识别的人脸信息# 循环处理每一张脸for x, y, w, h in faces:cv2.rectangle(img, pt1=(x, y), pt2=(x+w, y+h), color=[0, 0, 255], thickness=2)img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)plt.imshow(img)plt.show()
得到检测结果如下:

我们发现除了检测到人脸数据,还有一些其他的脏数据,这个时候可以打印检测出的人脸数据位置和大小结果如下:
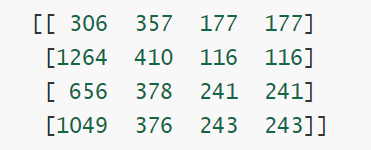
从大小中我们看到最大的两个矩形,刚好是人脸数据,其余都是脏数据,那么继续修改函数参数
faces = faceCascade.detectMultiScale(gray, 1.1, 2, minSize=(150, 150))# 把最小矩形大小改成150
这样我们就可以把脏数据给除去了:
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~