
Zeppelin 实践 | 如何在 Zeppelin 里定制 Python环境
对于Python开发人员来说,定制Python环境是一个必不可少的步骤。特别是对于多租户来说,大家在同一个集群里,但对Python环境有不同的需求:可能大家要用的Python版本不一样,也有可能大家要用的第三方库不一样。今天就给大家介绍下如何在Zeppelin里定制Python环境。这篇文章讲的是在hadoop yarn集群里实现Python的多租户开发,每个人如何定制自己的Python 环境。本文的例子都可以在下面这个链接找到,你可以把note下载到本地重现本文讲的内容。
http://zeppelin-notebook.com/#/notebook/2G7RDR415
另外本文的所讲的这个特性还没有正式发布,如果想尝试,请扫描加入Zeppelin钉钉群(34038239)或者扫描加入这个Flink on Zeppelin钉钉群,下载最新版的Zeppelin。
Step 1. 用Conda 定制Python环境
Zeppelin本身集成了Shell Interpreter,所以你可以用Shell Interpreter 来创建Conda环境,不过首先你需要安装以下工具
miniconda https://docs.conda.io/en/latest/miniconda.html
conda-pack https://conda.github.io/conda-pack/
mamba https://github.com/mamba-org/mamba



Step 2. 配置 Python Interpreter
Zeppelin 的 Interpreter有不同的运行模式,比如Shared,Isolated (https://www.yuque.com/jeffzhangjianfeng/ggi5ys/uls6am),这里推荐大家用Per Note Isolated,这样每个Note 就有自己独立的Python Interpreter,你可以为每个Note配置不同的Python Interpreter.
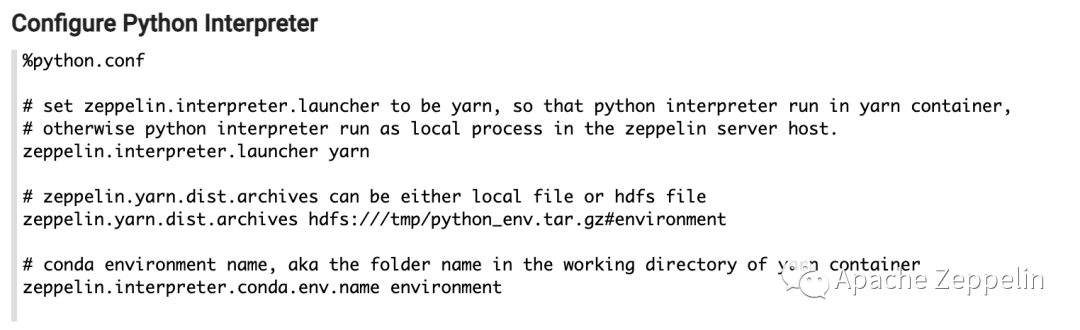
有3个配置选项需要配置:
zeppelin.interpreter.launcher 设为 yarn,这样你的Python Interpreter就会运行在Yarn container 里
zeppelin.yarn.dist.archives 设为 Step 1 上传到hdfs上的路径,注意后面有个#environment,这个是yarn的语法,yarn会在yarn container里把这个tar包解压到文件夹 environment
zeppelin.interpreter.conda.env.name 就是上面那个environment 文件夹,Zeppelin 会在这个文件夹里做一些初始化工作,否则这个conda env没法在yarn环境下正常工作
Step 3. 使用 Python Interpreter
接下来你就可以使用这个定制了上面这个Python环境的Python Interpreter,比如,下面2个例子里,一个用了Matplotlib,一个用了Plotnine
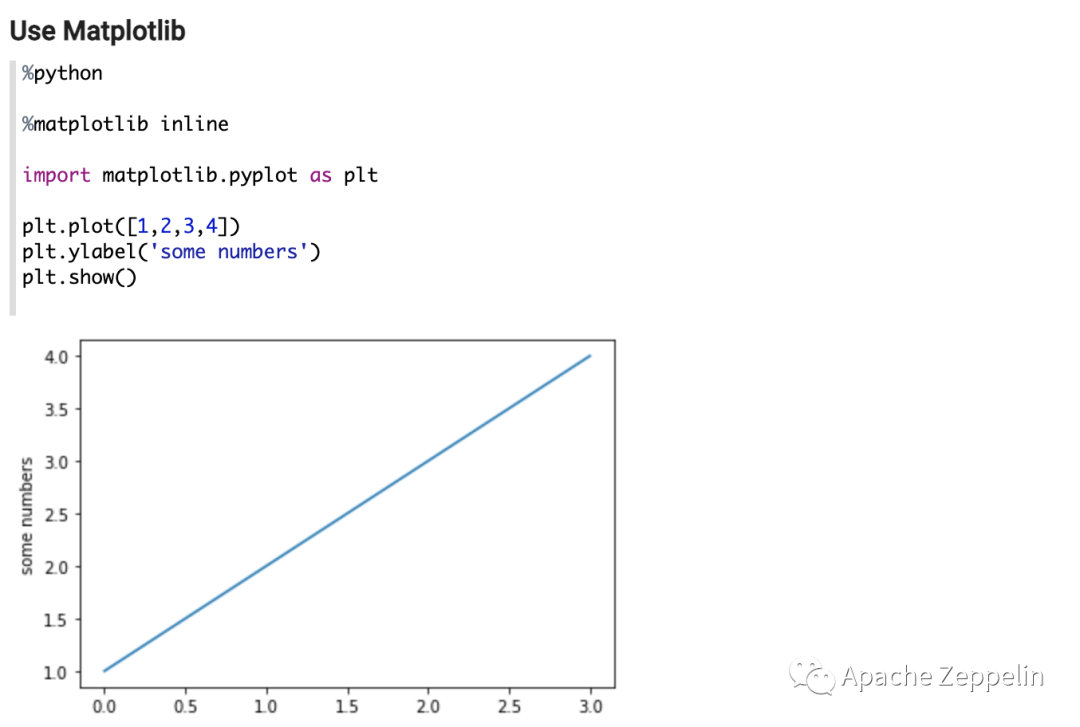
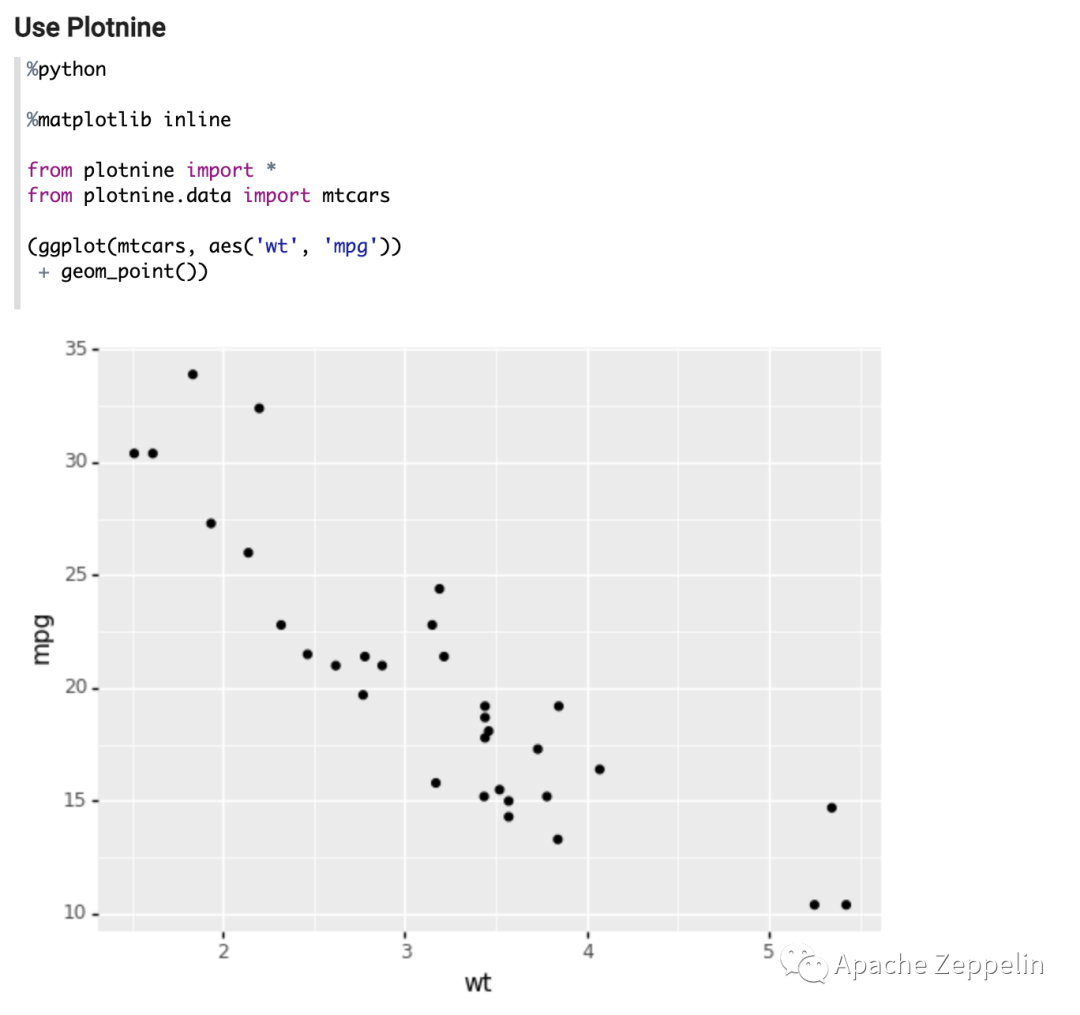
另外社区也实现了如何在PySpark里实现类似的功能,具体使用方法会发在另外一篇文章里,大家敬请期待。
----------------- 招聘-----------------
开宗明义,我们认为大数据上半场战斗已经结束,上半场战斗主要是底层引擎之争,目前已经趋于稳定。大数据的下半场战斗将发生在引擎之上的平台层。
如果你是有经验的大数据工程师,可能会有下面这3个痛点: 1. 缺少一个真正的可以提高工程师开发效率的平台。通常你需要在本地开发,然后打包上传代码,切换到集群环境里跑你的代码,如果出现错误,需要重新打包上传,整个过程效率低下,从开发到生产环境的过渡不够smooth。
2. 与上下游整合效率低下。大数据不是一个孤立的领域,通常需要结合上下游,上游是数据源,下游是BI,AI应用,现在大部分情况你需要在各种工具之间做切换以及数据交换才能完成整个端到端的解决方案。
3. 对接各种引擎成本太高。通常情况下,一个企业内有多种引擎来应对各种不同场景,你需要对接各种引擎,而每种引擎的对接方式又是千差万别,导致引擎对接成本太高。
我们是阿里云的大数据开放平台组,立志于打造一款革命性的大数据开发平台产品来解决上面的问题。如果你有志于为大数据领域做出一些小小的贡献,欢迎加入我们。
岗位要求
• 基本功扎实,有学习的热情和态度,有很强的解决问题能力。有快速学习新框架,看源码的能力。
• 熟悉Java,Python等开发语言,具备扎实的计算机理论基础,
• 具有良好的软件架构设计能力和写可读性高的代码能力
• 有大数据研发经验者。例如利用大数据框架(Hadoop,Spark,Flink 等等)工具构建过大数据产品或者ETL,大数据分析等,并且需要理解主流引擎的内部工作机制。
• 不仅有技术的深度,也有做产品的热情和sense。
• 有数据分析经验,机器学习经验者加分
• 有开源贡献经验者加分
这是一次难得的机会,希望我们有机会一起来做一个伟大的产品。
有意者请发送简历到 jeffzhang.zjf@alibaba-inc.com公司地址:浦东张江人工智能岛