AMD于昨晚正式发布了首款基于全新CDNA架构的Instinct MI100 GPU以及配套的ROCm 4.0生态系统,而英伟达也不甘示弱,于今日发布了 A100 80GB GPU,将支持NVIDIA HGX AI 超级计算平台,内存比上一代提升一倍,能够为研究人员和工程师们提供空前的速度和性能,助力实现新一轮AI和科学技术突破。>>加入极市CV技术交流群,走在计算机视觉的最前沿
AMD (超微半导体公司)昨夜正式推出其 AMD Instinct MI100 加速GPU芯片,这是一款新的图形处理器处理器(GPU) ,在科学研究计算方面起着专门的加速器作用。这种 7nm GPU 加速器使用 AMD 的 CDNA 结构来处理高性能计算(HPC)和人工智能任务,这样科学家们就可以从事重负荷的计算任务,比如冠状病毒研究。AMD 推出 Instinct MI100芯片,AI性能暴涨7倍
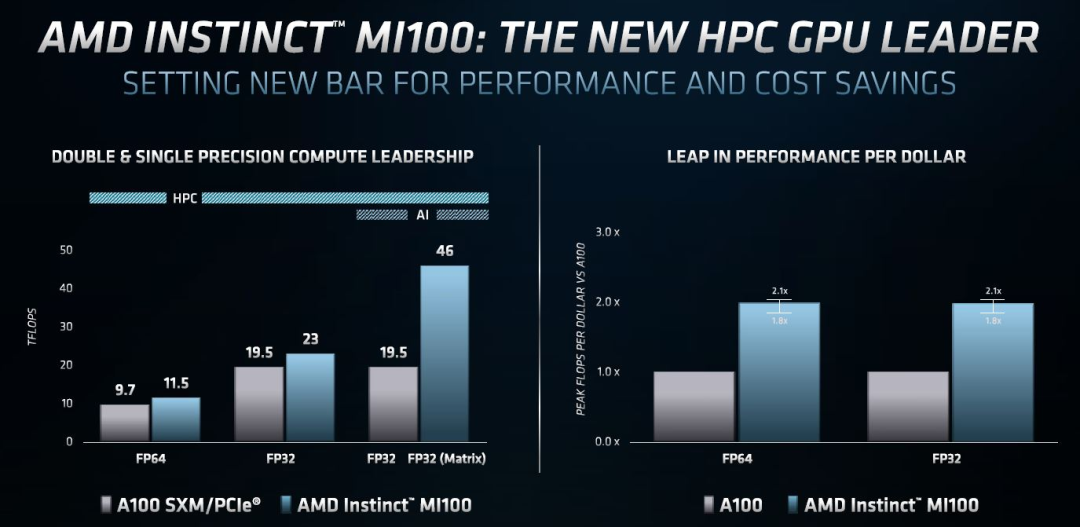
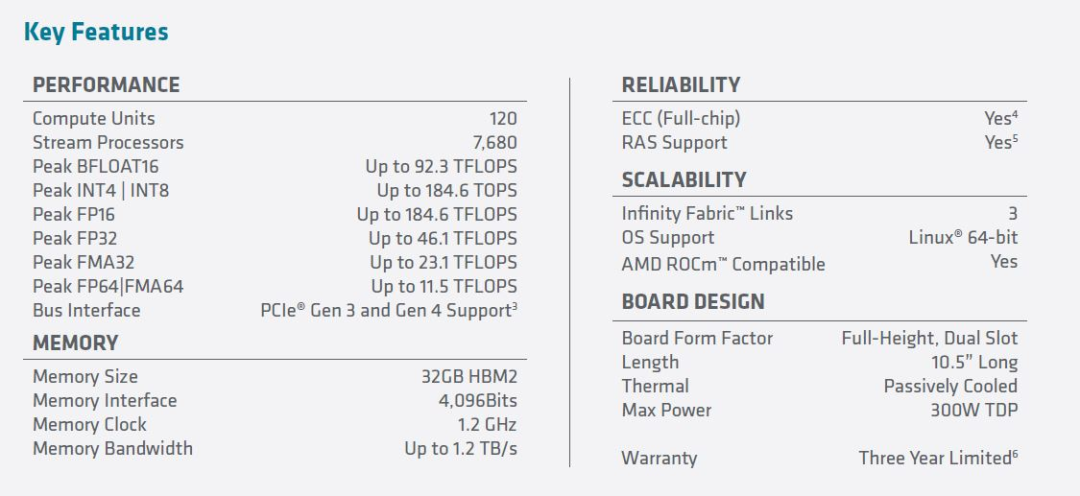
AMD 公司表示,MI100芯片是世界上最快的高性能计算处理器 GPU,也是第一个性能超过10万亿次浮点运算的 x86 服务器 GPU。该设备支持新的加速计算包括 AMD 的客户:戴尔,技嘉,惠普和超微。AMD高级副总裁丹 · 麦克纳马拉在新闻发布会上说: 「高性能计算机在分析感染冠状病毒、开发疫苗以及各种生命科学应用的可能性方面确实发挥了非常重要的作用」。MI100与第二代 AMD Epyc 处理器和 ROCm 4.0开放软件相结合,旨在帮助科学家取得科学突破。今年3月,AMD发布了其首个专门针对数据中心高性能计算而设计的CDNA架构,与其Radeon的 RDNA 游戏架构分道扬镳。二者虽然还有一些共通点,但在设计、优化上已经在各自的领域里有了不同的特色。Brad McCredie 在新闻发布会上说,有充足的证据显示数据中心应用程序的 CPU 进度相对于 GPU 的进度已经放慢,而最近,通用的 GPU 也开始放慢它们的进度。这就是为什么 AMD 将其设计工作分为消费者图形处理器和企业/服务器图形处理器,因为图形处理和人工智能处理的需求可能非常不同。这种独立的架构方法与英伟达仅使用一种架构的方法形成了鲜明的对比。AMD的内部人士也称,不同的任务处理实际上并不需要共存,没有必要用一个芯片去玩steam游戏的同时也可以进行高级分子模拟、抗震分析或天体物理模拟。在命名方面,AMD也放弃了Radeon字样,不再叫做Radeon Instinct,而是简单改成 Instinct。Instinct MI100 是 AMD 史上性能最高的HPC GPU,FP64 双精度浮点性能达到了 11.5 TFlops(也就是每秒1.15亿亿次),并在架构设计上专门加入了 Matrix Core(矩阵核心),用于加速HPC、AI运算。AMD称其在混合精度和FP16半精度的AI负载上,性能提升接近7倍,为 AI 和机器学习工作负载提供 FP32 Matrix 单精度矩阵计算为 46.1TFlops(每秒4.61亿亿次),FP16 Matrix 半精度矩阵计算为 184.6TFlops(每秒18.46亿亿次),Bfloat16 浮点为92.3TFlops(每秒9.23亿亿次)的性能。AMD的 ROCm 开发者软件为百万兆等级的运算提供了基础,ROCm 4.0已经进行了优化,以便为基于 MI100的系统提供大规模的性能。2018年AMD发布了 ROCm 的2.0版本,到2019年又发布了专注于机器学习和深度学习的3.0版本,再到昨晚最新发布的4.0版本,ROCm 已经打造成了完整的针对机器学习和高性能计算的开发方案,渐渐形成了一个完整的生态,用于各个领域的高性能计算。既然AMD发布了MI100,那老对手自然也不会缺席。AMD这款芯片的竞争对手是80GB 版本的 Nvidia A100 GPU,该GPU也于今天发布。
英伟达 A100 80GB新卡,与AMD新品正面刚
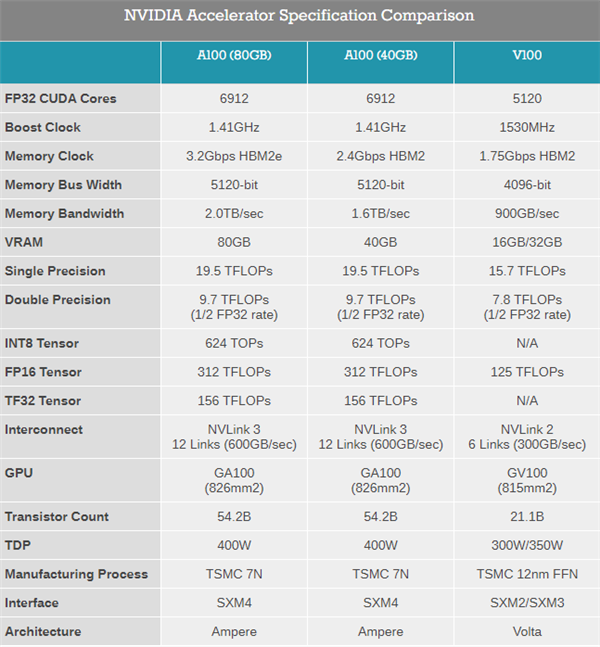
该芯片基于英伟达的 Ampere 图形架构,旨在通过实现更好的实时数据分析,帮助企业和政府实验室更快地做出关键决策。A100 80GB 版本的内存是六个月前推出的上一代的两倍。Nvidia 高管帕雷什•卡亚(Paresh Kharya)在新闻发布会上表示: 英伟达已经将这个系统的所有功能加倍,以便更有效地为客户服务。同时他还说道,世界上90% 的数据是在过去两年中创建的。
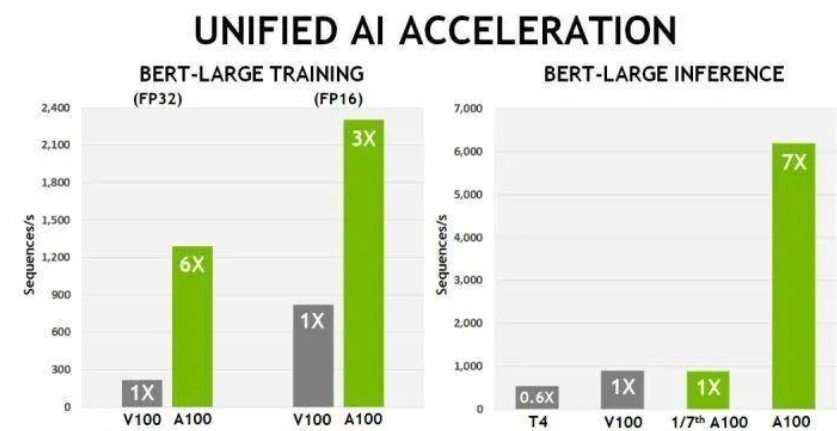
A100 芯片为研究人员和工程师提供了更快的速度和更高的性能,用于人工智能和科学应用。它提供超过每秒2 terabytes的内存带宽,这使得系统能够更快地将数据提供给 GPU。「超级计算已经发生了深刻的变化,从专注于模拟扩展到人工智能超级计算,数据驱动的方法现在正在补充传统的模拟,」 Kharya 说,他还补充说道,「Nvidia 的端到端的超级计算方法,从模拟的工作流到人工智能,是必要的保持进步」。Nvidia A100 80GB GPU 可在 Nvidia DGX A100和 Nvidia DGX Station 系统上使用,预计将在本季度出货。Nvidia今天还宣布,新芯片将与 AMD 新推出的 Instinct MI100 GPU 竞争。与 AMD 相比,Nvidia 有一个单一的 GPU 架构,既可用于人工智能,又可用于图形处理。有国外的分析师认为,AMD GPU 的性能比 Nvidia 最初的40GB A100提高了18% 。但他说真正的应用程序可能会受益于80GB 的 Nvidia 版本。同时他还表示,虽然价格敏感的客户可能青睐 AMD,但他认为 AMD 在人工智能性能方面无法与 Nvidia 抗衡。在人工智能领域,英伟达再次提高了门槛,几乎没有任何竞争对手能够跨越这一障碍。对于AI 训练,像 DLRM 这样的推荐系统模型拥有代表数十亿用户和数十亿产品的大型表格。A100 80gb 提供了高达3倍的加速,因此企业可以迅速重新训练这些模型,以提供高度准确的建议。A100 80GB 还可以在单个 HGX 驱动的服务器上训练最大的模型,比如 GPT-2等。Nvidia 说,A100 80GB 消除了对数据或模型并行体系结构的需求,这些体系结构实现起来很费时间,跨多个节点运行起来很慢。通过其多实例 GPU (MIG)技术,A100可以被划分为多达7个 GPU 实例,每个实例拥有10GB 的内存。这提供了安全的硬件隔离,并最大限度地利用 GPU 的各种较小的工作负载。而A100 80GB 与AMD的芯片一样,同样可以为科学应用提供加速,比如天气预报和量子化学。Nvidia 还发布了第二代人工智能计算系统,命名为 Nvidia DGX Station A100,该公司称其为「盒子中的数据中心」。DGX 提供了2.5千兆次的AI性能,有4个A100的张量核心GPU。总而言之,它有高达320GB的GPU内存。Nvidia 副总裁 Charlie Boyle 在一次新闻发布会上说,该系统提供了多达28个不同的 GPU 实例来运行并行作业。使用 DGX Station 平台的客户遍及教育、金融服务、政府、医疗保健和零售业。其中包括宝马集团、德国 DFKI 人工智能研究中心、洛克希德 · 马丁公司、 NTT Docomo 和太平洋西北国家实验室。本季度将提供 Nvidia DGX Station A100和 Nvidia DGX A100 640GB 系统。最后,Nvidia 发布了 Mellanox 400G Infiniband 网络,用于 exascale AI 超级计算机。2019年,Nvidia 以68亿美元收购了 Mellanox。这已经是第七代 Mellanox InfiniBand 技术,数据传输速度为每秒400千兆比特,而第一代技术为每秒10千兆比特。InfiniBand 技术提供的网络吞吐量为每秒1.64 petabits,是上一代的5倍。Nvidia 高级副总裁 Gilad Shainer 在新闻发布会上说,Mellanox 的技术将使从超级计算机到自动驾驶汽车的所有东西都能更快地联网。比尔盖茨在微软创立之初曾说希望每个家庭都能有一台PC,或许通过AMD和英伟达不断推进的研发,未来的每个家庭都能有自己的一个「超算中心」。
推荐阅读
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~