
即插即用 | CFNet提出全新多尺度融合方法!显著提升检测和分割精度!
点击下方卡片,关注「集智书童」公众号

Paper: https://arxiv.org/pdf/2302.06052.pdf
Code: https://github.com/zhanggang001/CFNet
摘要
多尺度特征对于密集预测任务来说是必不可少的,包括目标检测、实例分割和语义分割。现有的SOTA方法通常先通过主干网络提取多尺度特征,然后通过轻量级模块(如 FPN)融合这些特征。然而,我们认为通过这样的范例来融合多尺度特征可能是不够充分,因为与重量级主干网络相比,分配给特征融合的参数是有限的。
为此,我们提出了一种名为级联融合网络(CFNet)的新架构用于提升密集预测性能。除了用于提取初始高分辨率特征的主干和几个模块外,我们还引入了几个级联stage,使得CFNet能够生成更丰富的多尺度特征。每个stage都包括一个用于特征提取的子主干和一个用于特征集成的轻量级的转换模块。这种设计使得可以更深入有效地融合特征与整个主干的大部分参数。 最后,我们在目标检测、实例分割和语义分割等任务中验证了CFNet 的有效性。
导读
近几年,CNN和Transformer在许多计算机视觉任务中取得了令人满意的成果,包括图像分类、目标检测、语义分割等任务。对于图像分类任务,CNN和transformer网络在架构设计中均遵循逐渐减小特征图的空间大小的方式,来获取最高级语义特征进行预测。然而,对于许多密集预测任务,例如检测和分割,则需要多尺度特征来处理不同尺度的目标。
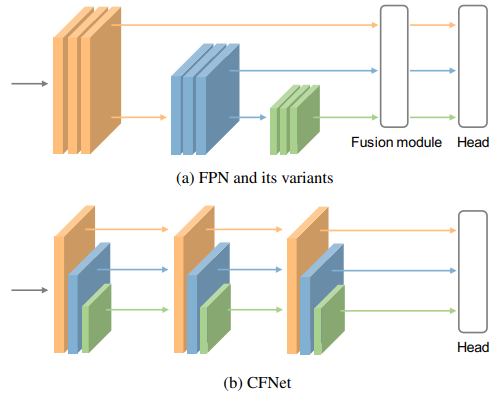
众所周知,特征金字塔网络 (FPN) 被广泛用于多尺度特征提取和融合,如上图(a)所示。然而,我们认为使用这样的范例可能不足以融合多尺度特征,因为与重量级主干网络相比,分配给特征融合的参数是有限的。例如,考虑基于主干 ConvNeXt-S 构建的 FPN,融合模块与主干的参数比例小于 10%。
那么,在计算资源不变的情况下,如果我们想为特征融合分配更多的参数,一个直观的方法是使用更小的主干并扩大融合模块。然而,使用较小的主干意味着整个模型从大规模预训练(例如 ImageNet 分类预训练)中获益较少,这对于训练数据有限的下游任务至关重要。那么我们如何分配更多的参数来实现特征融合,同时保持一个简单的模型架构,使得模型仍然可以最大程度地受益于大规模的预训练权重呢?
先回顾一下FPN的融合模块。为了融合多尺度特征,来自相邻层的特征首先通过逐元素相加进行整合,然后使用单个 3×3 卷积对求和特征进行变换。我们将这两个步骤命名为特征集成和特征转换。很明显,我们可以堆叠更多的卷积来转换集成特征,但它同时也引入了更多的参数,为主干留下的参数更少。从另一个角度思考,我们是否可以将特征整合操作插入主干,以便利用它之后的所有参数来转换整合后的特征。
基于对上述问题的思考,我们提出了一种用于密集预测,名为级联融合网络 (CFNet) 的新架构。CFNet主要思想是将特征集成操作插入至骨干网络中,使得更多参数能够用于特征融合,极大地增加了特征融合的丰富度。 本文提出的CFNet方法的主要贡献如下:
本文提出的CFNet能够有效改善密集任务(检测、分割)性能; 由于CFNet架构的简易性,能够轻松从大规模预训练权重中获益; 在目标检测和实例分割任务上超越ConvNeXt以及Swin Transformer 1~2%精度。
欢迎大家关注我们的公众号CVHub,每日都给大家带来原创、多领域、有深度的前沿AI论文解读与工业成熟解决方案!
方法
架构概述
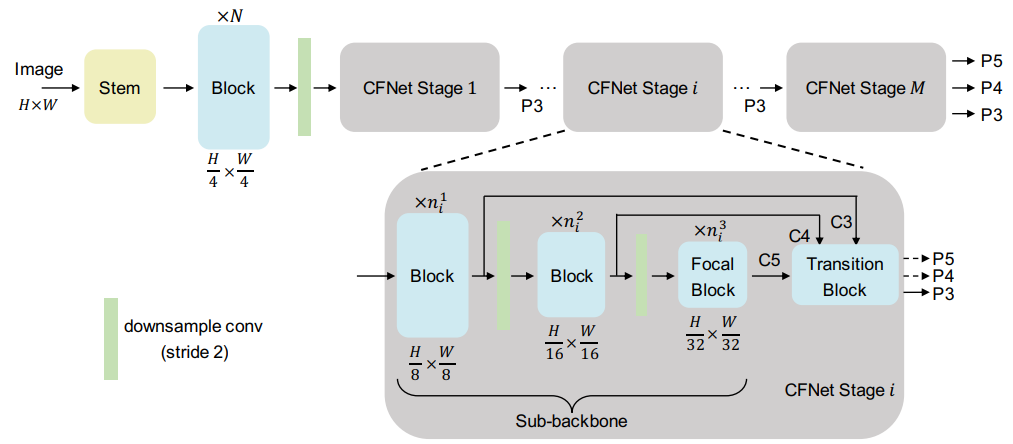
上图展示了CFNet网络架构。输入一张尺寸大小为 的 RGB 图像,经过一个 stem 和 N 个连续的块(block)处理,提取到的高分辨率特征。stem 由两个步幅(stride)为 2 的 卷积层组成,每个卷积层后面跟着一个 LayerNorm 层和一个 GELU 单元。CFNet 中的块(block)可以是之前的一些研究中提出的任何设计,例如 ResNet 瓶颈块、ConvNeXt 块、Swin Transformer 块等。
在CFNet 的多级结构中,高分辨率的特征经过一个步幅(stride)为 2 的 卷积层降采样后,被送入 个级联的stage中。所有的stage都共享相同的结构,但是它们可能具有不同数量的块(block)。在每个stage的最后一个块组中,应用了关注块(focal block)。值得注意的是,每个阶段输出带有步幅为 8、16、32 的特征 P3、P4、P5,但只有 P3 特征被送入后续stage。最后,由最后一个阶段输出的融合特征 P3、P4 和 P5 用于密集预测任务。
转换块(Transition block)
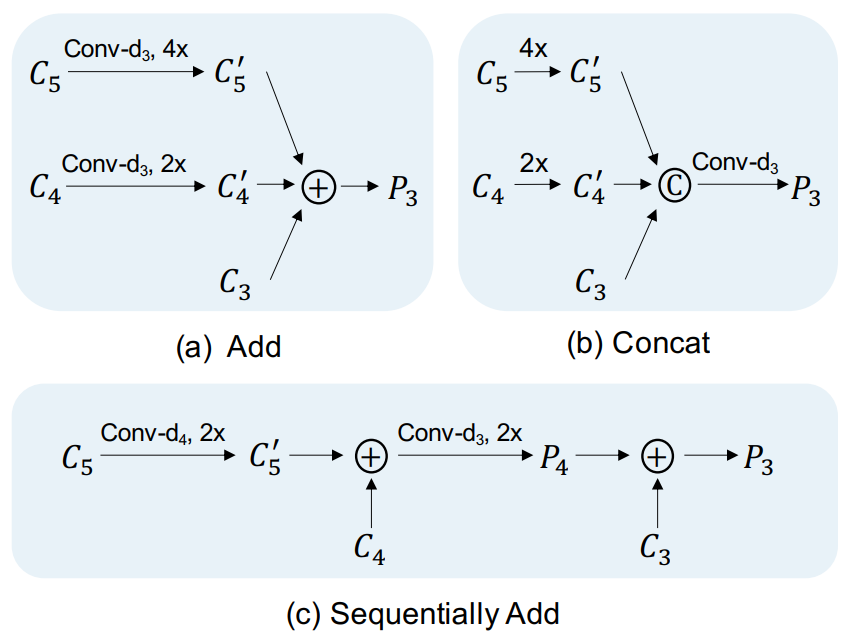
转换块用于整合每个stage中不同尺度的特征。如上图所示,我们提出了三种简单的转换块。
Add: 首先使用1×1卷积将C4和C5的通道数量降低以与C3对齐。在执行逐元素相加之前,使用双线性插值操作对齐特征的空间大小。
Concat: 直接上采样C4和C5的特征以与C3的空间大小对齐,然后拼接这些特征,接着使用1×1卷积来减少通道数。
Sequentially Add: 将不同尺度的特征逐步上采样和组合。这个设计类似于FPN中的融合模块,不同之处在于没有额外的卷积来转换相加的特征。
聚焦块(Focal block)
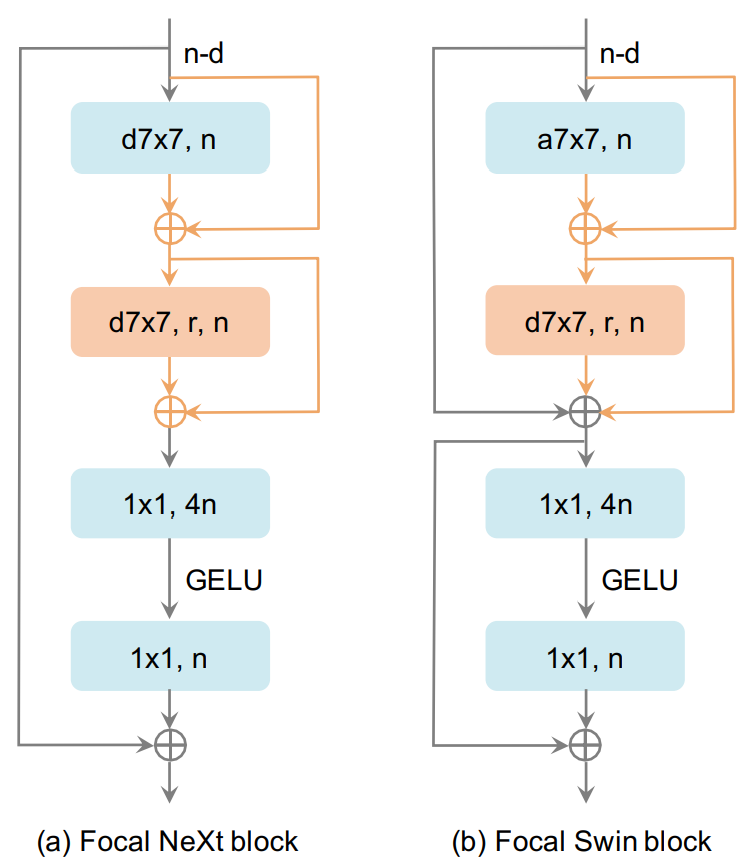
在密集预测任务中,处理各种尺度的目标一直是一个巨大的挑战。通常采用的解决方案是生成不同分辨率的特征。例如,使用步幅为8、16、32、64、128的特征来检测相应尺度的目标。用于生成步幅较大的特征的神经元通常具有较大的感受野。在CFNet的每个stage中,有三个块组用于提取步幅为8、16、32的特征。理想情况下,我们可以提取另外两个分辨率的特征以整合更多的特征尺度,就像和FPN一样。然而,这会引入更多的参数,因为随着特征的空间尺寸缩小,后面的组的通道数量逐渐增加。因此,我们提出了聚焦块,用于扩大每个stage的最后一个块组中神经元的感受野。
如上图所示,本文提出了两种聚焦块的设计,分别在ConvNeXt块和Swin Transformer块中引入了膨胀深度卷积和两个跳跃连接。聚焦块可以同时合并细粒度的局部特征和粗粒度的全局特征进行交互。最近,使用全局注意力或大卷积核来扩大感受野已经得到广泛研究。虽然取得了有竞争力的结果,但将这些操作应用于密集预测任务时,由于输入图像的尺寸过大,通常会引入大量的计算成本和内存开销。相比之下,本文提出的聚焦块仅引入了极少量的额外成本。
架构变体
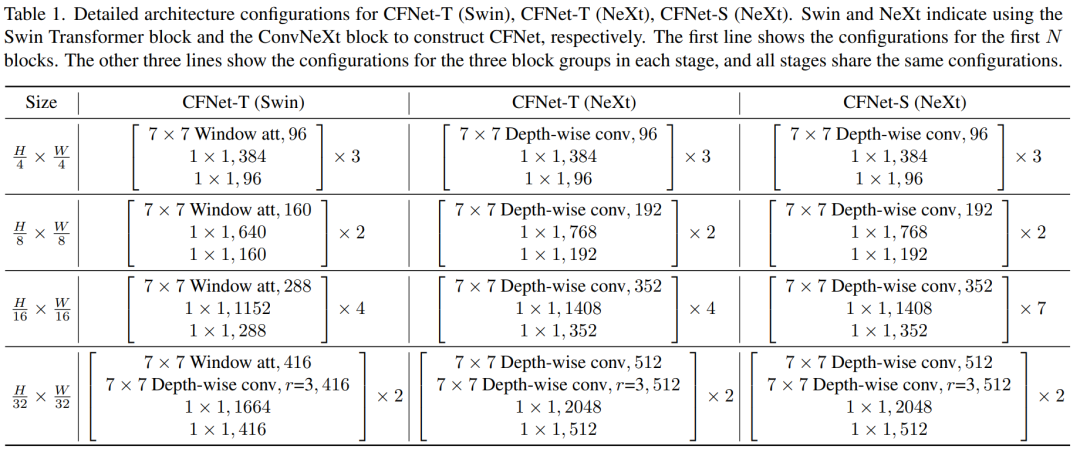
我们设计了三个CFNet变体,即CFNet-T(Swin)、CFNet-T(NeXt)和CFNet-S(NeXt)。T和S分别是tiny和small两个词的缩写,表示模型大小。第一个使用Swin Transformer块和focal Swin块,另外两个使用ConvNeXt块和focal NeXt块。
上表列出了每个CFNet变体的详细配置。CFNet-T和CFNet-S的阶段数分别设置为3和4。尽管不同配置的stage可能会取得更好的性能,但为了简单起见,我们为所有阶段设置了相同的配置。所有focal块中的扩张率r默认设置为3。
实验
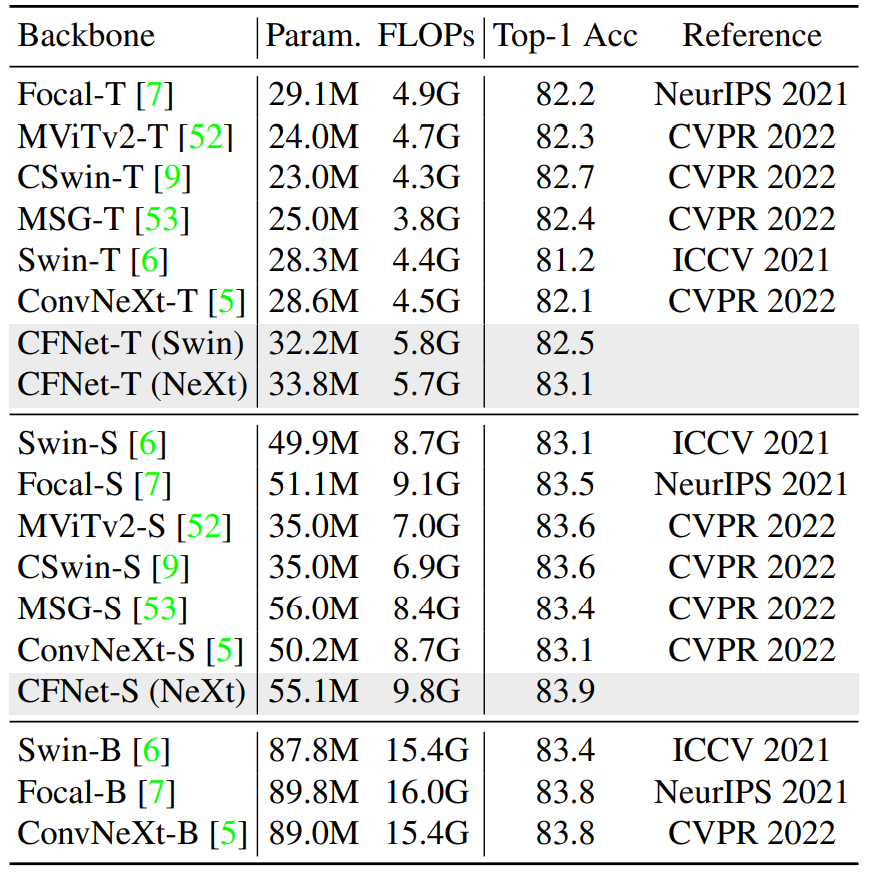
CFNet的参数量与计算量均比同量级模型稍大,同时精度也更高。但从整体上来看,CFNet在分类任务上没有显著优势。
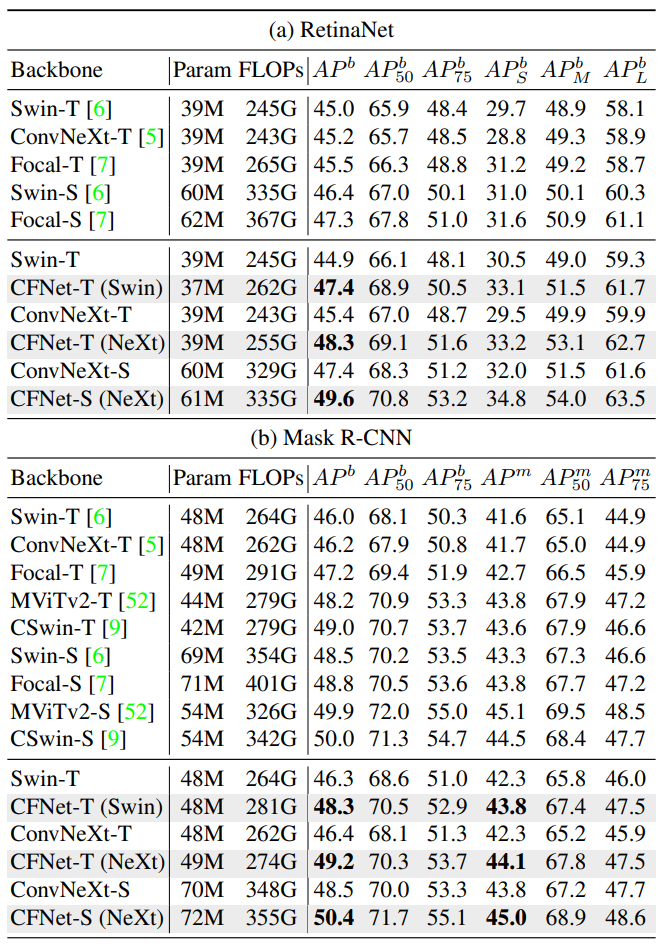
与同等量级的SOTA模型相比,CFNet精度有着显著的提升。
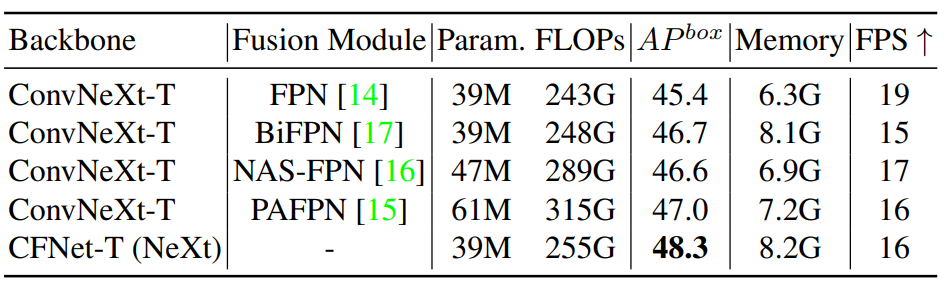
相比FPN及其变体结构,CFNet仅需较低的参数量和计算量便获得了更高的精度。虽然在FPS和Memory这两个指标上表现稍差,但并不影响CFNet变现出的更优综合能力。
与同等量级的SOTA模型相比,CFNet精度有着显著的提升。与检测任务的表现一致,这验证了CFNet拥有更强的多尺度融合能力,更适合用于处理检测和分割这类密集预测任务。

可以明显看出CFNet的检测框位置与类别置信度都更高更准确。
总结
本文提出了一种用于密集预测任务的新型体系结构CFNet。与广泛使用的FPN及其变体不同,它们使用轻量级融合模块来融合由主干网络提取的多尺度特征,CFNet则是引入了几个级联stage,基于提取的高分辨率特征来学习多尺度表示。 通过将特征集成操作插入到主干中,可以有效地利用大部分主干来有效地融合多尺度特征。本文在几个主流的密集预测任务上进行了大量实验来验证所提方法的有效性。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎扫码与我交流,一起探讨更多有趣的话题!

扫码加入👉「集智书童-目标检测」交流群
(备注:方向+学校/公司+昵称)




前沿AI视觉感知全栈知识👉「分类、检测、分割、关键点、车道线检测、3D视觉(分割、检测)、多模态、目标跟踪、NerF」
欢迎扫描上方二维码,加入「集智书童-知识星球」,日常分享论文、学习笔记、问题解决方案、部署方案以及全栈式答疑,期待交流!
点击上方卡片,关注「集智书童」公众号