
分布式训练 | Pytorch的主流做法详解

来源 | 九点澡堂子
编辑 | 极市平台
极市导读
前段时间工作涉及到修改分布式训练代码,在自研的工具库里直接调用简单的几行代码就可以,很多复杂的东西都封装起来了,但总感觉还是尽可能多了解下背后的东西比较好,原理和Pytorch的类似,就直接以torch来分析记录了。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
Pytorch 分布式训练主要有两种方式:
torch.nn.DataParallel ==> 简称 DP
torch.nn.parallel.DistributedDataParallel ==> 简称DDP
本文结合源码了解下Pytorch的这两个方法,本文主要记录DP和DDP的使用方式。
DP 只用于单机多卡,DDP 可以用于单机多卡也可用于多机多卡,后者现在是Pytorch分布式训练的主流用法。
DP写法比较简单,但即使在单机多卡情况下也比 DDP 慢。具体可参考:
https://pytorch.org/docs/stable/nn.html#dataparallel-layers-multi-gpu-distributed 。
DP
在DP中,只有一个主进程完成整体操作,大致用法:
import torchimport torch.nn as nn
# 1. 构造模型
net = model(imput_size, output_size)
# 2. 模型、数据放在GPU上
net = net.cuda()
inputs, labels = inputs.cuda(), labels.cuda()
# 3. 调用DP
net=nn.DataParallel(net)
# 4. 前向计算
result = net(inputs)
# 5. 其他和正常模型训练无差别
关于DataParallel的使用, 摘取主要源码:
class DataParallel(Module):
def __init__(self, module, device_ids=None, output_device=None, dim=0):
super(DataParallel, self).__init__()
# 如果没有GPU可用,直接返回
if not torch.cuda.is_available():
self.module = module
self.device_ids = []
return
# 如果有GPU,但没有指定的话,device_ids为所有可用GPU
if device_ids is None:
device_ids = list(range(torch.cuda.device_count()))
# 默认输出在0号卡上
if output_device is None:
output_device = device_ids[0]
由代码可知,如果不设定好要使用的device_ids的话, 程序会自动找到这个机器上面可以用的所有的显卡用于训练。
如果想要限制使用的显卡数,怎么办呢?
那就在代码最前面使用:
# 限制代码能看到的GPU个数,这里表示指定只使用实际的0号和5号卡
# 注意:这里的赋值必须是字符串,list会报错
os.environ['CUDA_VISIBLE_DEVICES'] == '0,5'
# 这时候device_count = 2
device_ids = range(torch.cuda.device_count())
# device_ids = [0,1] 这里的0就是上述指定的'0'号卡,1对应'5'号卡。
net = nn.DataParallel(net,device_ids)
# !!!模型和数据都由主gpu(0号卡)分发。
值得注意的是,在使用
os.environ['CUDA_VISIBLE_DEVICES']
对可以使用的显卡进行限定之后, 显卡的实际编号和程序看到的编号应该是不一样的。
例如上面我们设定的是:
os.environ['CUDA_VISIBLE_DEVICES']='0,5'
但是程序看到的显卡编号应该被改成了'0,1'。
也就是说程序所使用的显卡编号实际上是经过了一次映射之后才会映射到真正的显卡编号上面的, 例如这里的程序看到的'1'对应实际的'5'。
但是Dataparallel会带来显存的使用不平衡,具体分析见参考链接[2],而且碰到大的任务,时间和能力上都很受限。
DDP
为了弥补Dataparallel的不足,有了torch.nn.parallel.DistributedDataParallel,这也是现在Pytorch分布式训练主推的。
DDP支持单机多卡和多机多卡,和DP只有一个主进程不一样,DDP每张卡都有一个进程,这就涉及到进程通信,多进程通信初始化,是使用DDP最繁琐的地方。
主要涉及下面这个方法:
#详见:https://pytorch.org/docs/stable/distributed.html
torch.distributed.init_process_group( )
常用参数:
backend: 后端, 实际上是多个机器之间交换数据的协议,官方和很多用户都强烈推荐'nccl'作为backend。但是nccl的接口只有5个,如果有其他诉求nccl比较受限,mpi也可考虑。 init_method: 机器之间交换数据需要指定一个主节点, 这个参数用来指定主节点的。 world_size: 参与job的进程数, 实际就是GPU的个数; rank: 进程组中每个进程的唯一标识符。比如一个节点8张卡,world_size为8,每张卡的rank是对应的0-7的连续整数。 顺便解释下local_rank: 假设有两个节点/机器,每个节点有8张卡,总共16张卡,对应16个进程。global_rank是指0-15,对于节点1,local_rank为0-7,对于节点2,local_rank也是0-7。
初始化init_method的方法有两种:
使用TCP进行初始化; 使用共享文件系统进行初始化。
Pytorch作者推荐TCP,说是最简单的方式:
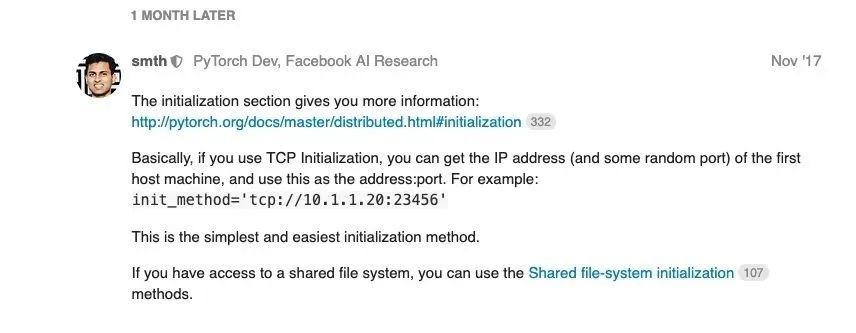
我们平常在集群上操作,可以通过os.environ获取每个进程的节点ip信息,全局rank以及local rank。
关于获取节点信息的详细代码:
import os
# 可用作world size
os.environ['SLURM_NTASKS']
# node id
os.environ['SLURM_NODEID']
# 可用作全局rank
os.environ['SLURM_PROCID']
# local_rank
os.environ['SLURM_LOCALID']
#从中取得一个ip作为通讯ip
os.environ['SLURM_NODELIST']
因此,torch中DDP的使用如下方式:
import os
import re
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.nn.parallel
import DistributedDataParallel as DDP
#1. 获取环境信息
rank = int(os.environ['SLURM_PROCID'])
world_size = int(os.environ['SLURM_NTASKS'])
local_rank = int(os.environ['SLURM_LOCALID'])
node_list = str(os.environ['SLURM_NODELIST'])
#2. 对ip进行操作
node_parts = re.findall('[0-9]+', node_list)
host_ip = '{}.{}.{}.{}'.format(node_parts[1], node_parts[2], node_parts[3], node_parts[4])
#3. 设置端口号,注意端口一定要没有被使用
port = "23456"
#4. 使用TCP初始化方法
init_method = 'tcp://{}:{}'.format(host_ip, port)
#5. 多进程初始化通信环境
dist.init_process_group("nccl", init_method=init_method,
world_size=world_size, rank=rank)
#6. 指定当前device
# 作用类似于os.environ['CUDA_VISIBLE_DEVICES']
# 官方推荐用CUDA_VISIBLE_DEVICES
# https://pytorch.org/docs/stable/cuda.html
torch.cuda.set_device(local_rank)
#7. 模型数据放到GPU上
model = model.cuda()
input = input.cuda()
#8. 指定模型所在local_rank
model = DDP(model, device_ids=[local_rank])
#9.前向计算
output = model(input)
#10. 此后训练流程与普通模型无异
最近官方表述中加了一个store参数,更新了下使用方法,大差不差。具体参考:
https://pytorch.org/docs/stable/distributed.html
使用TCP进行初始化,需要读取ip,我们在集群上通过os.environ可以很方便完成初始化。平常在集群提交任务的srun指令这样写:
# 单机多卡# 8个任务对应8个进程,每个节点上跑8个任务
srun -n8 --gres=gpu:8 --ntasks-per-node=8 python train.py
#多机多卡
#16个任务对应16个进程,每个节点最多跑8个任务/进程,每张卡占满8个GPU
#因此这里是申请了16/8=2个节点,即在两个机器上跑。
srun -n16 --gres=gpu:8 --ntasks-per-node=8 python train.py
参考链接
[1]https://blog.csdn.net/weixin_40087578/article/details/87186613
[2]https://zhuanlan.zhihu.com/p/86441879
[3]https://zhuanlan.zhihu.com/p/68717029
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
