
贝壳基于Spark的HiveToHBase实践
导读:本文详细介绍了如何将Hive里的数据快速稳定的写进HBase中。由于数据量比较大,我们采取的是HBase官方提供的bulkload方式来避免HBase put api写入压力大的缺陷。团队早期采用的是MapReduce进行计算生成HFile,然后使用bulkload进行数据导入的工作。
因为结构性的因素,整体的性能不是很理想,对于部分业务方来说不能接受。其中最重要的因素就是建HBase表时预分区的规划不合理,导致了后面很多任务运行时间太过漫长,很多都达到了4~5个小时才能成功。
在重新审视和规划时,自然的想到了从计算层面性能表现更佳的Spark。由它来接替MapReduce完成数据格式转换,并生成HFile的核心工作。
实际生产工作中因为工作涉及到了两个数据端的交互,为了更好的理解整体的流程以及如何优化,知道ETL流程中为什么需要一些看上去并不需要的步骤,我们首先需要简单的了解HBase的架构。
1. HBase结构简单介绍
Apache HBase是一个开源的非关系型分布式数据库,运行于HDFS之上。它能够基于HDFS提供实时计算服务主要是架构与底层数据结构决定的,即由 LSM-Tree (Log-Structured Merge-Tree) + HTable (Region分区) + Cache决定的:
LSM树是目前最流行的不可变磁盘存储结构之一,仅使用缓存和append file方式来实现顺序写操作。其中关键的点是:排序字符串表 Sorted-String-Table,这里我们不深入细节,这种底层结构对于bulkload的要求很重要一点就是数据需要排序。而以HBase的存储形式来看,就是KeyValue需要进行排序!
HTable的数据需要均匀的分散在各个Region中,访问HBase时先去HBase系统表查找定位这条记录属于哪个Region ,然后定位到这个Region属于哪个RegionServer,然后就到对应服务器里面查找对应Region中的数据。
最后的bulkload过程都是相同的,差别只是在生成HFile的步骤。这也是下文重点描述的部分。
2. 数据流转通路
数据从Hive到HBase的流程大致如下图:
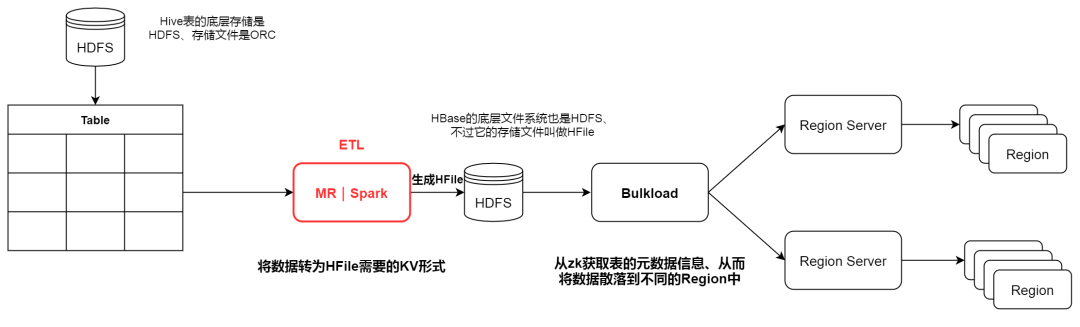
整个流程真正需要我们cover的就是ETL ( Extract Transfer Load ) 部分,HBase底层文件HFile属于列存文件,每一列都是以KeyValue的数据格式进行存储。
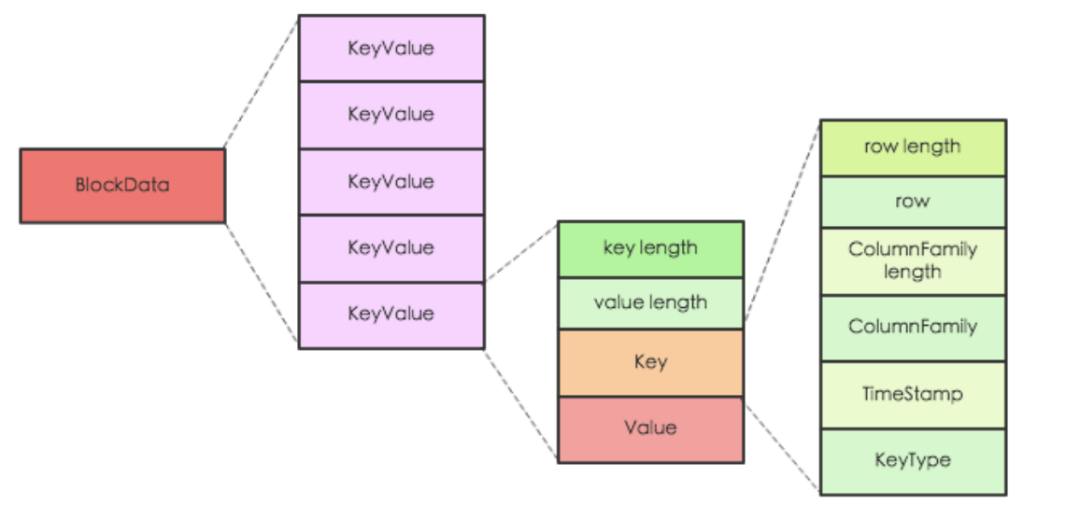
逻辑上真正需要我们做的工作很简单:( 为了简便、省去了timestamp 版本列 )、HBase一条数据在逻辑上的概念简化如下:
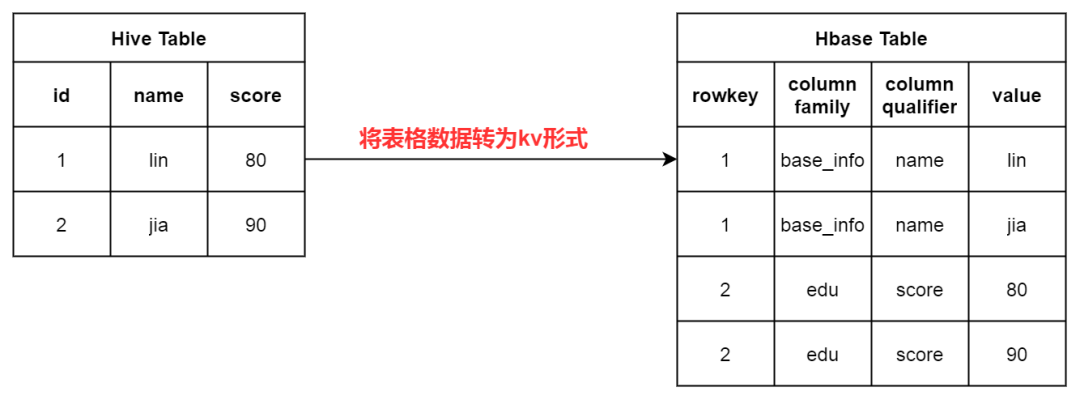
如果看到了这里,恭喜你已经基本明白本文的行文逻辑了。接下来就是代码原理时间:
Map/Reduce框架运转在
1. mapper:数据格式转换
mapper的目的就是将一行数据,转为rowkey:column family:qualifer:value的形式。关键的ETL代码就是将map取得的value,转成< ImmutableBytesWritable,Put>输出、进而交给reducer进行处理。
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ImmutableBytesWritable, Put>.Context context)throws IOException, InterruptedException {//由字符串切割成每一列的value数组String[] values = value.toString().split("\\x01", -1);String rowKeyStr = generateRowKey();ImmutableBytesWritable hKey = new ImmutableBytesWritable(Bytes.toBytes(rowKeyStr));Put hPut = new Put(Bytes.toBytes(rowKeyStr));for (int i = 0; i < columns.length; i++) {String columnStr = columns[i];String cfNameStr = "cf1";String cellValueStr = values[i].trim();byte[] columbByte = Bytes.toBytes(columnStr);byte[] cfNameByte = Bytes.toBytes(cfNameStr);byte[] cellValueByte = Bytes.toBytes(cellValueStr);hPut.addColumn(cfNameByte, columbByte, cellValueByte);}context.write(hKey, hPut);}
mapper写完了,好像已经把数据格式转完了,还需要reducer吗?参考官方的资料里也没有找到关于reducer的消息,我转念一想 事情没有这么简单!研读了提交Job的主流程代码后发现除了输出文件的格式设置与其他mr程序不一样:
job.setOutputFormatClass(HFileOutputFormat2.class);还有一个其他程序没有的部分,那就是:
HFileOutputFormat2.configureIncrementalLoad(job,htable)故名思义就是对job进行HFile相关配置。HFileOutputFormat2 是
2. job的配置
挑选出比较相关核心的配置:
根据mapper的输出格式来自动设置reducer,意味着我们这个mr程序可以只写mapper,不需要写reducer了。
获取对应HBase表各个region的startKey,根据region的数量来设置reduce的数量,同时配置partitioner让上一步mapper产生的数据,分散到对应的partition ( reduce ) 中。
reducer的自动设置
// Based on the configured map output class, set the correct reducer to properly// sort the incoming values.// TODO it would be nice to pick one or the other of these formats.if (KeyValue.class.equals(job.getMapOutputValueClass())) {job.setReducerClass(KeyValueSortReducer.class);} else if (Put.class.equals(job.getMapOutputValueClass())) {job.setReducerClass(PutSortReducer.class);} else if (Text.class.equals(job.getMapOutputValueClass())) {job.setReducerClass(TextSortReducer.class);} else {LOG.warn("Unknown map output value type:" + job.getMapOutputValueClass());}
实际上上面三种reducer底层都是会将数据转为KeyValue形式,然后进行排序。需要注意的是KeyValue 的排序是全排序,并不是以单个rowkey进行排序就行的。所谓全排序,就是将整个对象进行比较!
查看KeyValueSortRducer后会发现底层是一个叫做KeyValue.COMPARATOR的比较器,它是由Bytes.compareTo(byte[] buffer1, int offset1, int length1, byte[] buffer2, int offset2, int length2)将两个KeyValue对象的每一个字节从头开始比较,这是上面说到的全排序形式。
我们输出的文件格式是HFileOutputFormat2,它在我们写入数据的时候也会进行校验check每次写入的数据是否是按照KeyValue.COMPARATOR 定义的顺序,要是没有排序就会报错退出!Added a key not lexically larger than previous。
reduce数量以及partitioner设置
为什么要根据HBase的region的情况来设置我们reduce的分区器以及数量呢?在上面的小节中有提到,region是HBase查询的一个关键点。每个htable的region会有自己的【startKey、endKey】,分布在不同的region server中。
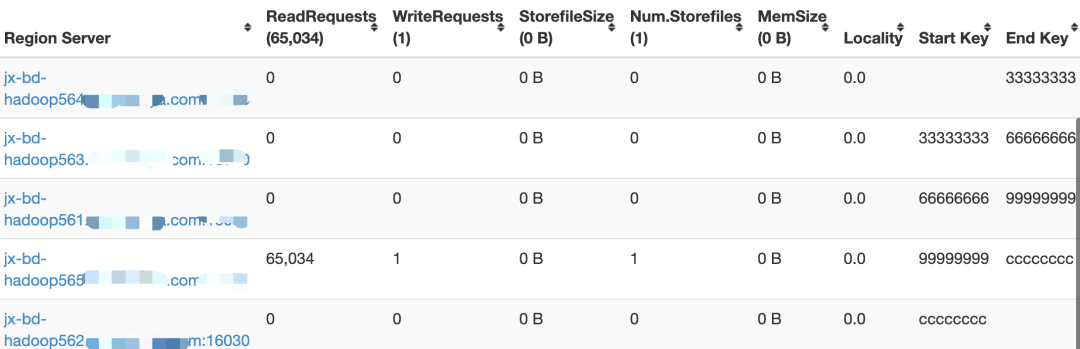
这个key的范围是与rowkey匹配的,以上面这张表为例,数据进入region时的逻辑场景如下:
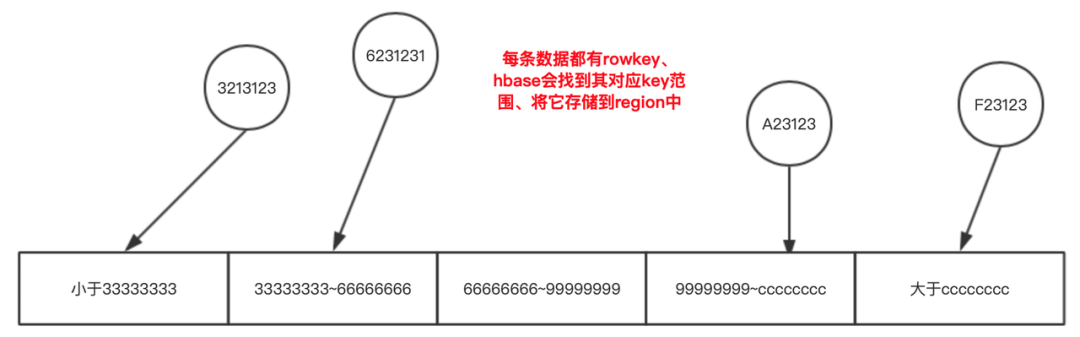
也正是因为这种管理结构,让HBase的表的rowkey设计与region预分区 ( 其实就是region数量与其 [starkey,endkey]的设置 ) 在日常的生产过程当中相当的重要。在大批量数据导入的场景当然也是需要考虑的!
HBase的文件在hdfs的路径是:
/HBase/data/<namespace>/<tbl_name>/<region_id>/<cf>/<hfile_id>通过并行处理Region来加快查询的响应速度,所以会要求每个Region的数据量尽量均衡,否则大量的请求就会堆积在某个Region上,造成热点问题、对于Region Server的压力也会比较大。
如何避免热点问题以及良好的预分区以及rowkey设计并不是我们的重点,但这能够解释为什么在ETL的过程中需要根据region的startkey进行reduce的分区。都是为了贴合HBase原本的设计,让后续的bulkload能够简单便捷,快速的将之前生成HFile直接导入到region中!
这点是后续进行优化的部分,让HiveToHBase能够尽量摆脱其他前置流程 ( 建htable ) 的干扰、更加的专注于ETL部分。其实bulkload并没有强制的要求一个HFile中都是相同region的记录!
3. 执行bulkload、完成的仪式感
讲到这里我们开头讲的需要cover的重点部分就已经完成并解析了底层原理,加上最后的job提交以及bulkload,给整个流程加上结尾。
Job job = Job.getInstance(conf, "HFile Generator ... ");job.setJarByClass(MRMain.class);job.setMapperClass(MRMapper.class);job.setMapOutputKeyClass(ImmutableBytesWritable.class);job.setMapOutputValueClass(Put.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(HFileOutputFormat2.class);HFileOutputFormat2.configureIncrementalLoad(job, htable);//等待mr运行完成job.waitForCompletion(true);LoadIncrementalHFiles loader = new LoadIncrementalHFiles(loadHBaseConf);loader.doBulkLoad(new Path(targetHtablePath), htable);
4. 现状分析
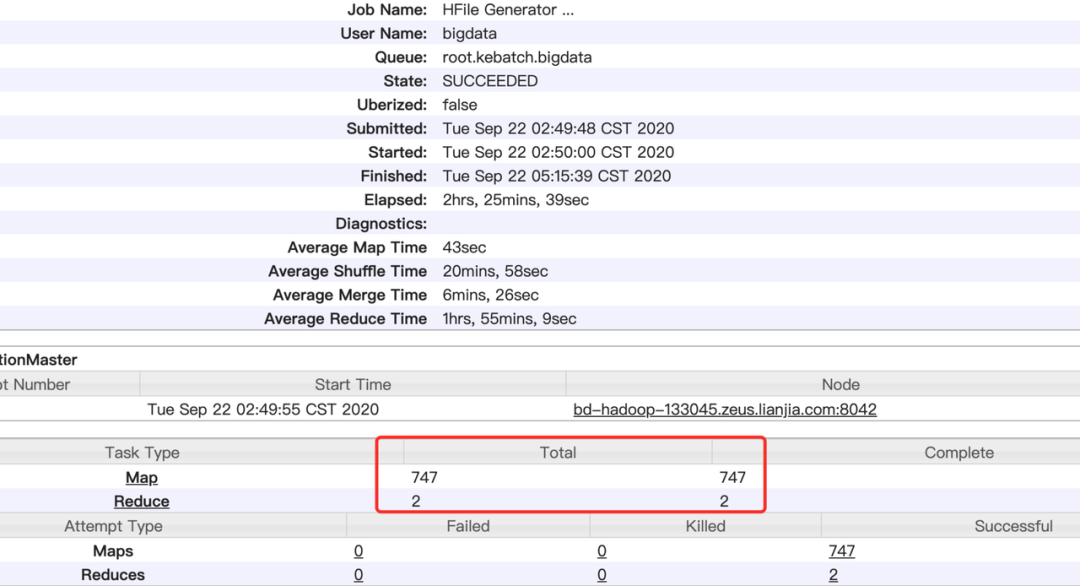
讲到这里HiveToHBase的MapReduce工作细节和流程都已经解析完成了,来看一下实际运行中的任务例子,总数据248903451条,60GB经过压缩的ORC文件。
痛点
因为历史的任务HBase建表时预分区没有设置或者设置不合理,导致很多任务的region数量只有几个。所以历史的任务性能卡点基本都是在进行reduce生成HFile的时候,经查验发现747个Map执行了大约4分钟,剩下两个Reduce执行了2小时22分钟。
而平台整体HiveToHBase的HBase表region数量分布如下:
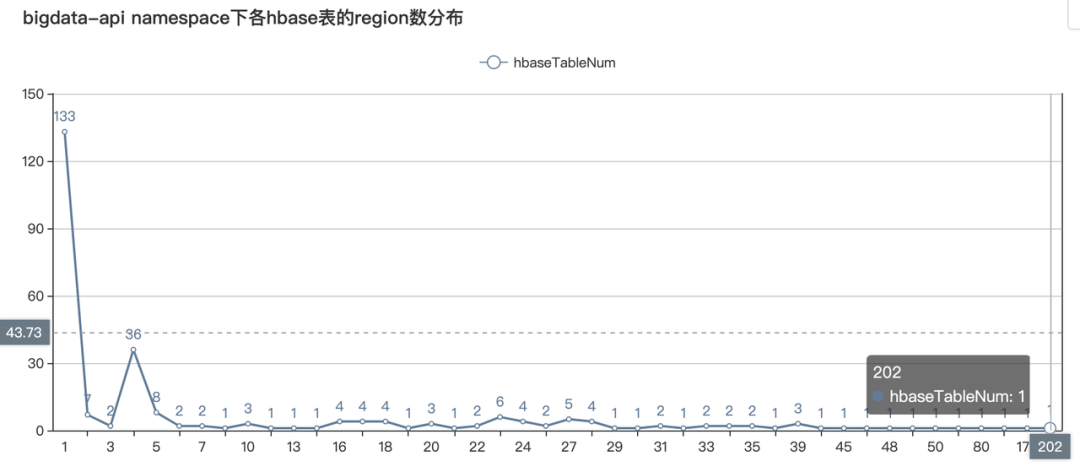
可以看到大部分的HBase表 region数量都只有几个,在这种情况下如果沿用之前的体系进行分区。那么整体的性能改变可以预想的不会太高!
而且由于历史原因HiveToHBase支持用户写sql完成Hive数据的处理,然后再导入HBase中。mr是不支持sql写法的,之前是先使用tez引擎以insert overwrite directory + sql的方式产生临时文件,然后将临时文件再进行上述的加工。
解决方案
经过综合的考量,决定采用Spark重写HiveToHBase的流程。现在官方已经有相应的工具包提供
但是这样解决不了我们的痛点,所以决定不借助
还记得上文中说过,其实bulkload并没有强制的要求一个HFile中都是相同region的记录 吗?所以我们是可以不按照region数量切分partition的,摆脱htable region的影响。HBase bulkload的时候会check之前生成的HFile,查看数据应该被划分到哪个Region中。
如果是之前的方式提前将相同的前缀rowkey的数据聚合那么bulkload的速度就会很快,而如果不按照这种方式,各个region的数据混杂在一个HFile中,那么就会对bulkload的性能和负载产生一定的影响!这点需要根据实际情况进行评估。
使用Spark的原因:
考虑它直接支持sql连接hive,能够优化掉上面提到的步骤,整体流程会更简便。
spark从架构上会比mr运行快得多。
最后的预期以上述例子为示意 如下图:
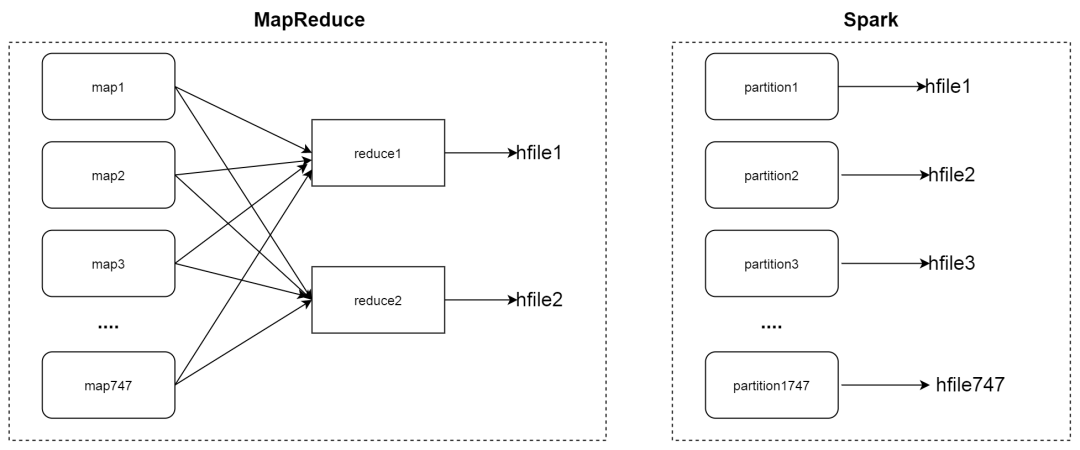
核心流程代码:与MR类似,不过它采用的是Spark 将RDD写成磁盘文件的api。需要我们自己对数据进行排序工作。
1. 排序
构造一个KeyFamilyQualifier类,然后继承Comparable进行类似完全排序的设计。实际验证过程只需要rowkey:family:qualifier进行排序即可。
public class KeyFamilyQualifier implements Comparable<KeyFamilyQualifier>, Serializable {private byte[] rowKey;private byte[] family;private byte[] qualifier;public KeyFamilyQualifier(byte[] rowKey, byte[] family, byte[] qualifier) {this.rowKey = rowKey;this.family = family;this.qualifier = qualifier;}public int compareTo(KeyFamilyQualifier o) {int result = Bytes.compareTo(rowKey, o.getRowKey());if (result == 0) {result = Bytes.compareTo(family, o.getFamily());if (result == 0) {result = Bytes.compareTo(qualifier, o.getQualifier());}}return result;}}
2. 核心处理流程
spark中由于没有可以自动配置的reducer,需要我们自己做更多的工作。下面是工作的流程:
将spark的dataset
转为
将
将排好序的数据转为
将构建完成的rdd数据集,转成hfile格式的文件。
SparkSession spark = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate();Dataset<Row> rows = spark.sql(hql);JavaPairRDD javaPairRDD = rows.javaRDD().flatMapToPair(row -> rowToKeyFamilyQualifierPairRdd(row).iterator()).sortByKey(true).mapToPair(combineKey -> {return new Tuple2(combineKey._1()._1(), combineKey._2());});Job job = Job.getInstance(conf, HBaseConf.getName());job.setMapOutputKeyClass(ImmutableBytesWritable.class);job.setMapOutputValueClass(KeyValue.class);HFileOutputFormat2.configureIncrementalLoad(job, table, regionLocator); //使用job的conf,而不使用job本身;完成后续 compression,bloomType,blockSize,DataBlockSize的配置javaPairRDD.saveAsNewAPIHadoopFile(outputPath, ImmutableBytesWritable.class, KeyValue.class, HFileOutputFormat2.class, job.getConfiguration());
3. Spark:数据格式转换
row -> rowToKeyFamilyQualifierPairRdd(row).iterator() 这一part其实就是将row数据转为< KeyFamilyQualifier, KeyValue>
//获取字段<value、type> 的tupleTuple2<String, String>[] dTypes = dataset.dtypes();return dataset.javaRDD().flatMapToPair(row -> {List<Tuple2<KeyFamilyQualifier, KeyValue>> kvs = new ArrayList<>();byte[] rowKey = generateRowKey();// 如果rowKey 为null, 跳过if (rowKey != null) {for (Tuple2<String, String> dType : dTypes) {Object obj = row.getAs(dType._1);if (obj != null) {kvs.add(new Tuple2<>(new KeyFamilyQualifier(rowkey,"cf1".getBytes(),Bytes.toBytes(dType._1)),getKV(param-x));}}} else {LOGGER.error("row key is null ,row = {}", row.toString());}return kvs.iterator();});
这样关于HiveToHBase的spark方式就完成了,关于partition的控制我们单独设置了参数维护便于调整:
// 如果任务的参数 传入了 预定的分区数量if (partitionNum > 0) {hiveData = hiveData.repartition(partitionNum);}
分离了partition与sort的过程,因为repartition也是需要shuffle 有性能损耗,所以默认不开启。就按照spark正常读取的策略 一个hdfs block对应一个partition即可。如果有需要特殊维护的任务,例如加大并行度等,也可以通过参数控制。
上述例子的任务换成了新的方式运行,运行33分钟完成。从146分钟到33分钟,性能整整提升了4倍有余。由于任务迁移和升级还需要很多前置性的工作,整体的数据未能在文章撰写时产出,所以暂时以单个任务为例子进行对比性实验。(因为任务的运行情况和集群的资源紧密挂钩,只作为对照参考作用)
可以看到策略变化对于bulkload的性能来说是几乎没有变化的,实际证明我们这种策略是行得通的:

还有个任务是原有mr运行方式需要5.29小时,迁移到spark的方式 经过调优 ( 提高partition数量 ) 只需要11分钟45秒。这种方式最重要的是可以手动进行调控,是可灵活维护的。本身离线任务的运行时长就是受到很多因素的制约,实验虽然缺乏很强的说服力,但是基本还是能够对比出提升的性能是非常多的。
限于篇幅,有很多未能细讲的点,例如加盐让数据均匀的分布在region中,partition的自动计算,spark生成hfile过程中导致的oom问题。文笔拙略,希望大家能有点收获。
最后感谢开发测试过程中给予笔者很多帮助的雨松和冯亮,还有同组同学的大力支持。