
Spark 实践 | Spark SQL 在雪球的实践
背景
因为业务需要,雪球数据团队基于HDP 3.1.5(Hadoop 3.1.1+Hive 3.1.0+Tez 0.9.1)搭建了一个新的集群,HDP 3.1.5默认使用Hive3 on Tez作为ETL计算引擎,但是在使用Hive3 on Tez中,我们遇到很多问题:
- 部分SQL执行失败,需要关闭掉容器复用或者向量化执行。
- 部分SQL开启CBO优化之后的执行计划错误,导致结果出错,需要关闭CBO优化。
- 还有一些时区不准、GroupBy with Limit不准确等已经在新版本fix的bug。
- 极其个别复杂多级关联的SQL,计算结果不准确,很难发现,需要通过修改SQL来解决。
这些问题对数仓开发来说非常致命。从业界来看,各公司生产上大部分还是使用Hive2,而Hive和Tez的社区活跃程度低,更新迭代慢(Hive3.x最新一次release已经将近3年了),修复相关问题的代价比较大。
在分别比较了Hive3 on Tez、Hive3 on MR、Hive3 on Spark2 、Spark SQL等各种引擎之后,从准确性和稳定性以及计算效率各方面综合考虑,数据团队决定采用Spark SQL在作为数仓的ETL引擎。经过一段时间推广和使用,目前在交互查询和离线ETL很多场景和计算都已经支持了Spark SQL:
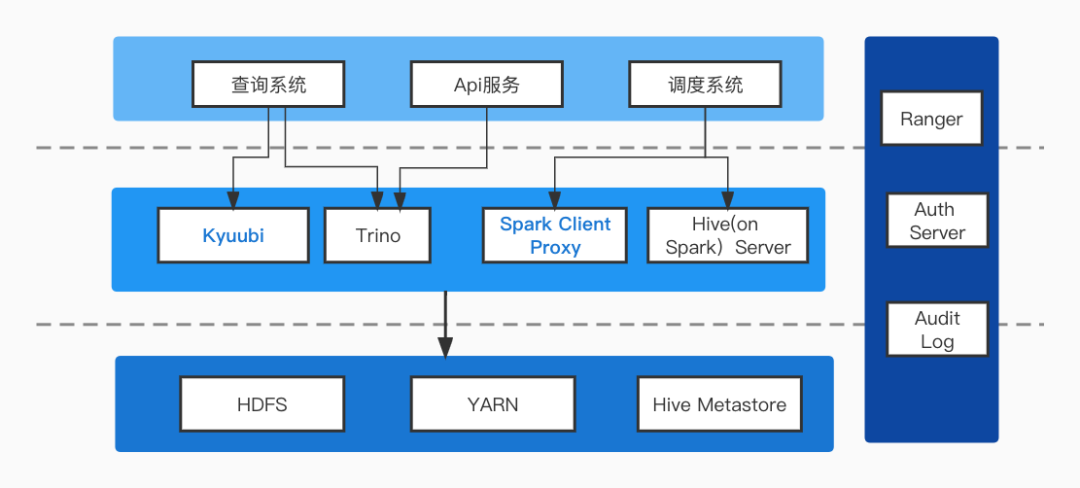
本文主要分享了从Hive3 SQL切换成Spark3 SQL的实践。
切换过程
Facebook在从Hive切换到Spark SQL的时候,重写了Spark SQL的执行计划,增加了一个Shadow过程:基于Hive SQL的执行日志,执行一个Spark SQL,将数据双写到Shadow表中,然后再通过工具对比实际表和Shadow表的执行效率和正确性。
雪球数据团队也开发了类似的工具分别做了测试和对比。公司自研的调度系统本身自带执行时长和资源消耗工具(基于yarn的application资源使用统计),可以用来对比执行效率。同时特意开发了一个基于Trino的正确率对比工具来对比正确率。
测试分两个阶段:
- 对于复杂场景SQL,主要做了正确率的对比:Hive3 on Tez的正确率约为50%,Hive3 on MR的正确率约为70%,Hive3 on Spark2的正确率为100%(需要关闭CBO),Spark SQL的正确率为100%。
数据准确性 | 平均执行时间(秒) | |||||
Hive3 on MR | Hive3 on Tez | Hive3 on Spark2(关闭优化) | Spark SQL | Hive on Spark2 | Spark SQL | 降低 |
70% | 50% | 100% | 100% | 1957 | 423 | 88% |
- 对线上实际运行的SQL,通过收集和重放了大量的线上实际SQL,用不同的引擎写入不同的目标表,然后用工具对比执行结果和执行效率。从执行时长来看,Spark SQL执行时长和Hive3 on Tez在一个数据量级,但Spark SQL资源消耗大概在Hive3 on Tez(限制了并行度)的1/3。而Hive3 on Spark2经常会出现数据倾斜。Spark SQL的表现最佳。
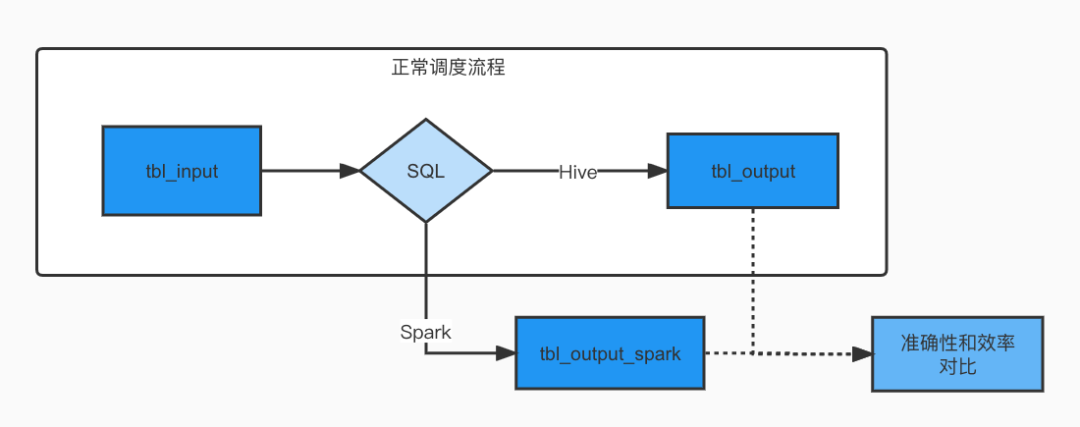
在谨慎评估正确率和执行效率后,大数据团队决定首先使用Hive3 on Spark2作为紧急替换Tez的计算引擎,随后选用 Spark 3.2.1 作为长期支持的计算引擎,逐步将Hive SQL切换成 Spark SQL。
遇到问题
得益于Spark3性能的提升和AQE机制,性能上很少遇到问题。不过,雪球数据团队在测试和切换过程中,遇到一些问题,其中大部分都是兼容性问题,下面进行逐一介绍:
1. Spark SQL无法递归子目录以及无法读写自己的问题
当Hive表数据存放在多级子目录时,Tez、MR、Spark默认均不能识别和读取到数据。针对这种情况,Apache Hive提供了两项项参数:
set hive.mapred.supports.subdirectories=true;
set mapreduce.input.fileinputformat.input.dir.recursive=true;
但Spark SQL并不支持类似参数。Spark SQL在执行ORC和Parquet格式的文件解析时,默认使用Spark内置的解析器(Spark内置解析器效率更高),这些内置解析器不支持递归子目录的两项参数,并且也没有其它参数支持这一效果。可以通过设置 spark.sql.hive.convertMetastoreOrc=false 来指定Spark使用Hive的解析器,使递归子目录参数正确生效。Spark的内置解析器也将于未来版本中支持递归子目录。
此外,当用户在使用Spark读写同一张Hive表时,经常会遇到 "Cannot overwrite a path that is also being read from "的报错,而同样的语句在Hive中可以进行。这是由于Spark对数仓常用的数据类型做了自己的实现方式,在他自己的实现方式下,目标路径会先被清空,随后才执行写入,而Hive是先写入到临时目录,任务完成后再讲结果数据替换目标路径。使用Hive解析器也可以解决这个问题。
2. Hive ORC解析的一些问题
在1 问题的解决方案中,我们选择统一使用Hive的ORC解析器,这将带来以下问题:
Hive的ORC在读取某些Hive表时,会出现数组越界异常或空指针异常。
其原因是某些目录下存在空的ORC文件,可通过设置hive.exec.orc.split.strategy=BI 规避空指针问题,
设置hive.vectorized.execution.enabled=false 规避数组越界问题。此外使用Spark 3.x时,还需要设置 hive.metastore.dml.events=false 避免写入数据时报错。
3. Spark.sql.sources.schema问题
在Spark和Hive同时使用的情况下,某些操作可能会导致Hive表元数据里面有spark.sql.sources.schema.part属性的存在,后续如果修改表结构会导致表元数据和数据不一致的情况。例如:新增字段A后并执行新的写入语句后,查询A字段值为NULL。
这是因为Spark在读写存在该属性的Hive表时,会优先使用该属性提供的映射值来生成表结构。而Hive原生修改表结构的语句不会更新该值,最终导致新字段在读写时不被Spark识别。
解决方案是重新建表,或者删除该表属性。在两个引擎同时存在时期,可以约定只使用Hive来执行DDL数据。
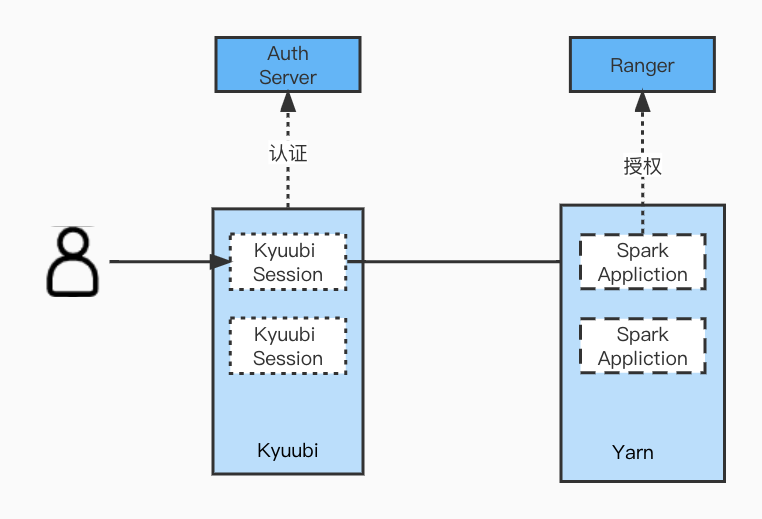
4. Spark权限和审计
在Hive里面,我们继承了PasswdAuthenticationProvider实现了自定义的用户认证,通过集成Ranger实现了权限管控,而Spark开源版并没有完整的解决方案。官方的Spark Thrift Server在资源隔离和权限管控上有很大的不足,我们引入了Apache Kyuubi。Kyuubi也有类似PasswdAuthenticationProvider的接口,可以来实现用户认证。对于权限管控,一般的方案是使用Submarine。但是Submarine最新版本已经将这一模块去掉,而最近一个支持Ranger的0.6.0版本只支持Spark 3.0。Spark集成Ranger的要先解析SQL取得相关的表和字段,以判断当前用户是否有权限读写,而Spark 3.0到Spark 3.2.1的解析SQL做了很多修改,所以我们修改了相关的代码来适配Spark 3.2.1。同时基于Apache Kyuubi的Event体系,完成了Spark的审计功能。
5. Hive SQL 迁移 Spark SQL 的一些较隐蔽的坑
- 日期类型比较,处理方式不同
低版本Hive会将Date类型转换为string,2.3.5以后的版本会将String转换为Date比较。
如: '2022-03-14 11:11:11' > date_sub('2022-03-15',1)
在低版本时,该不等式结果为true,高版本则为false。在 Spark SQL 3.2.1 中,结果同样为false。
- 类型严格程度不同
Hive 默认支持隐式转换,Spark需要设置 spark.sql.storeAssignmentPolicy=LEGACY 才支持有限度的隐式转换,否则执行会报错。
对语义的精准度要求更高,例如
关联语法不同:
select a from t1 join t2 group by t1.a
在Spark SQL中需要写成 select t1.a from t1 join t2 group by t1.a
grouping语法不同:Select a,b from t1 group by a,b grouping sets (a,b)
在Hive中除了聚合汇总a和b维度外,还会汇总整体维度,但是在SparkSQL中要求写成
Select a,b from t1 group by a,b grouping sets ((),(a),(b))
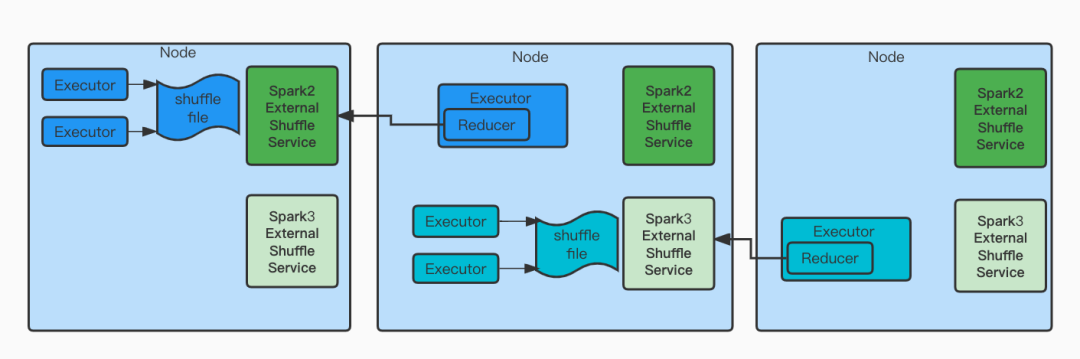
6. 动态资源,多版本兼容
Spark动态资源可以节省很多资源,但是要依赖shuffle service。因为集群在切换过程中需要同时支持Spark2(Hive on Spark2)和Spark3,所以需要保证集群能够同时支持两个版本的shuffle service。YARN在2.9.0之后支持了Classloader隔离的aux service。而Spark 3.1引入了可配置的方式去启动不同端口不同classpath包的shuffle service。但是在实践中发现,Yarn的这种机制并不能加载xml配置文件,需要将xml打成jar包才能识别。
7. 小文件问题
为了提升计算速度,大数据计算引擎在计算时候都会采取并行处理,而Spark SQL在写入数据的时候是并行写入,并没有一个合并的过程。小文件过多,会增大Namenode的压力,同时对查询性能也有很大影响。通常在Hive中可以引入 hive.spark.mergefiles=true 来为hive的执行计划增加一个合并Job,但Spark SQL不支持这个做法。
目前,我们开启AQE,通过设置目标大小和最大shuffle上限在一定程度上减少最后生成的文件数。例如:
--conf spark.sql.adaptive.enabled=true \
--conf spark.sql.adaptive.advisoryPartitionSizeInBytes=262144000 \
--conf spark.sql.adaptive.maxNumPostShufflePartitions=200 \
--conf spark.sql.adaptive.forceApply=true \
--conf spark.sql.adaptive.coalescePartitions.parallelismFirst=false \
--conf spark.sql.adaptive.coalescePartitions.minPartitionSize =52428800 \
注意:advisoryPartitionSizeInBytes这个参数指定的不是最终生成的文件大小,而是在最终输出文件阶段,每个partition read的字节大小,此处的256M对应到ORC Snappy的输出文件大小约为55M。
经实验,生成的文件数最大为200个,大小平均55M。总大小小于50M时,只会有一个文件。
未来规划
目前每天300+任务是基于Spark SQL,已经稳定运行较长时间,之前遇到的问题都已经基本解决,后续会将所有的ETL引擎统一到Spark SQL,用来提高计算效率。使用Spark SQL的主要场景还是在数仓离线的ETL,后续会在更多的场景尝试引入Spark SQL,比如交互式分析,会结合公司目前的Trino引擎做一些互补。另外,目前业务上有很多实时的数据需求,后续会基于Spark技术栈引入Hudi等数据湖技术来满足业务的需求。