
Hudi 实践 | 快手基于 Apache Hudi 的实践
分享一篇Apache Hudi在快手的实践,如何使用Apache Hudi解决效率问题

分享者为靳国卫,快手大数据研发专家,负责用户增长数据团队

分为三部分介绍Hudi如何解决效率问题,首先是实际应用中遇到的痛点有哪些,业务诉求是什么,然后调研业界的解决方案,为什么选择Hudi来解决痛点问题,然后介绍在实践中如何使用Hud解决业务问题,并形成体系化的解决方案。

业务痛点包括数据调度、数据同步和修复回刷三大类痛点,包括数据全量回刷效率低。
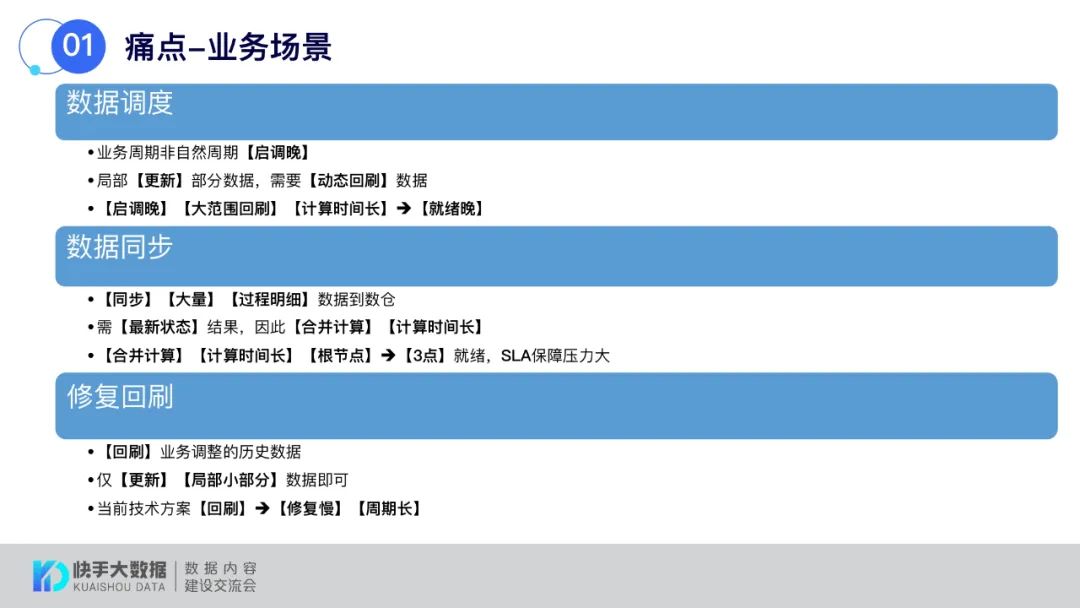
三个场景拉通来看,从业务诉求就是希望更快看到结果,像业务库那样数据准备好了就可以使用,由于业务库引擎限制,又希望使用大数据技术做分析,总的来看可以结合实时化和大数据的CRUD。

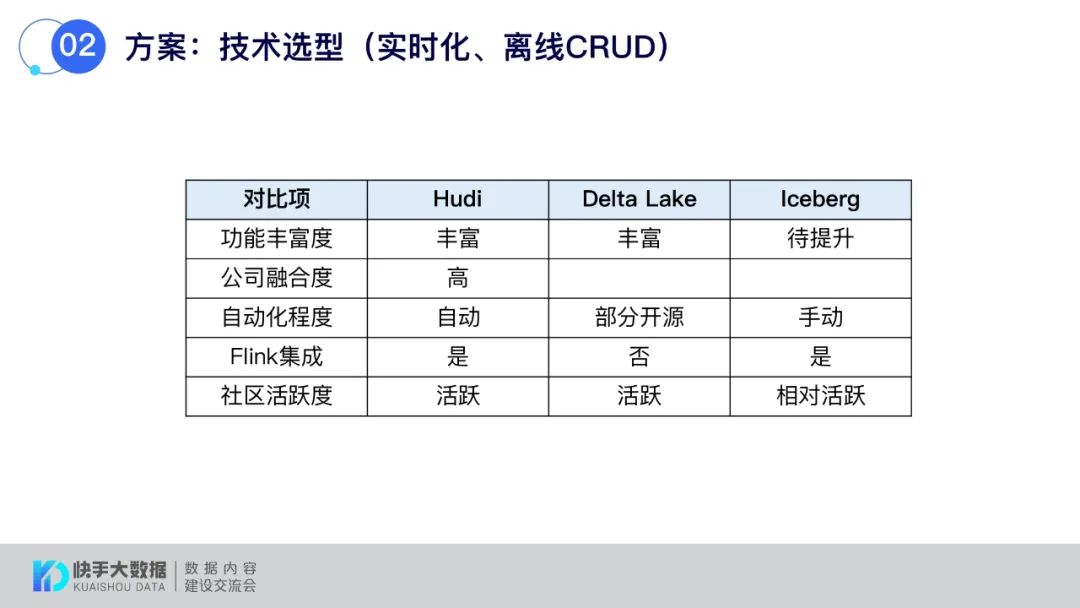
在业界进行调研后,发现有一些解决方案,但最后为什么选择了Hudi呢?

对比了现在业界通用的解决方案,并且从功能丰富度、与公司痛点匹配度、自动化程度、与Flink集成、社区活跃度等方面考虑,快手最后选择Hudi作为解决方案。
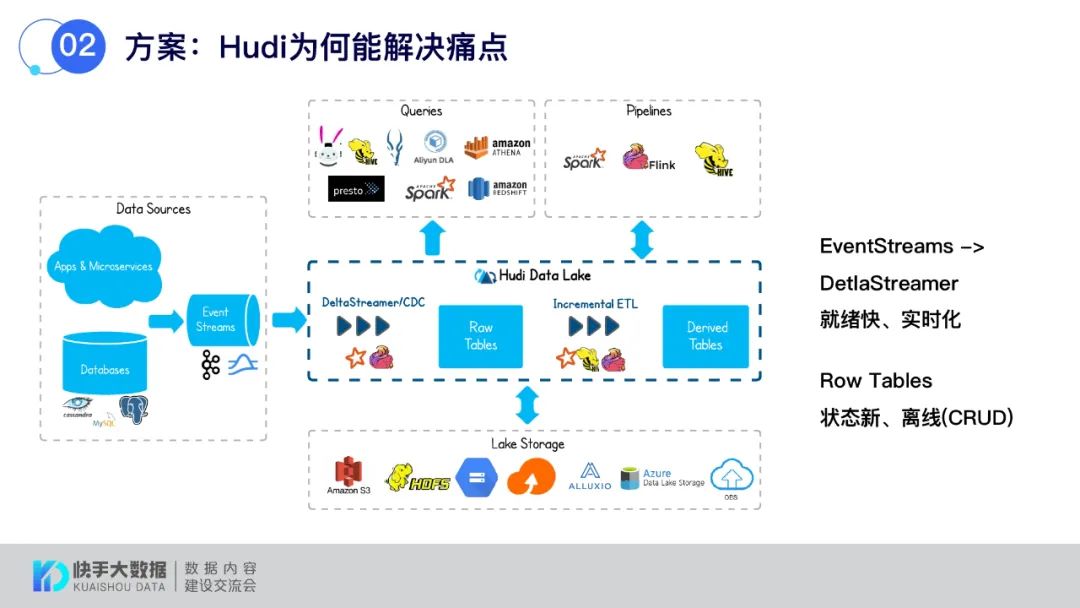
首先来看Hudi的架构体系,通过Spark/Flink将上游数据同步到数据湖的Raw Tables中,并可对Raw Tables进行增删改查,与快手内部需求及痛点匹配度非常高。
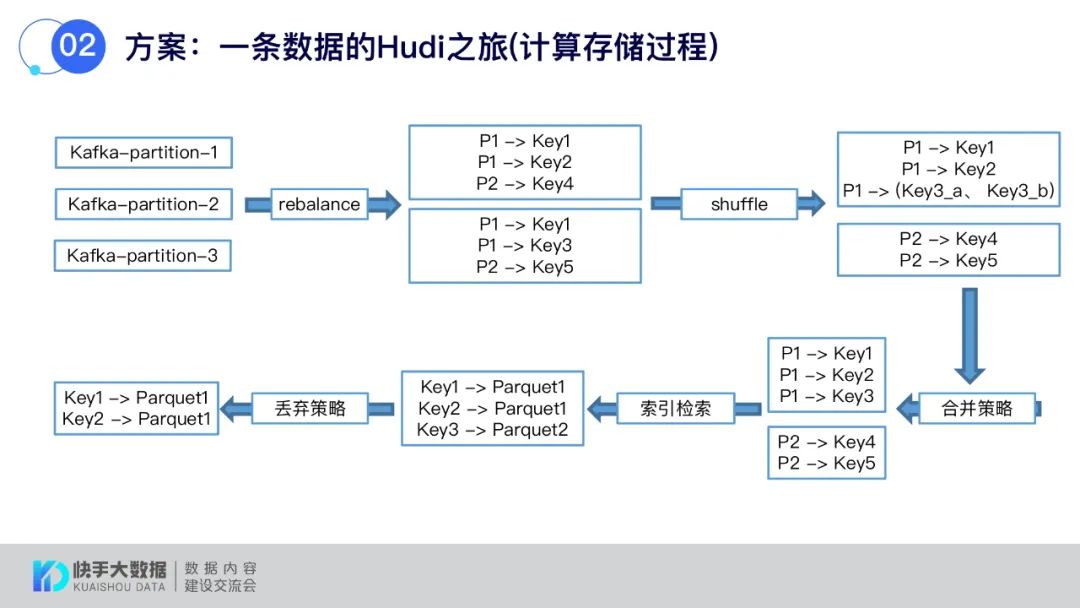
下面来看数据在Hudi的写入流程,从Kafka中取数据时会先进行一次rebalance来预防数据热点问题,然后对数据进行合并后进行检索,最后会丢弃一部分无用数据(重复或乱序到达的数据)。
经过数据写入后Parquet文件格式存在,其结构包括数据、Footter(包含一些元数据信息)等,Hudi是一个数据存储解决方案,可以解决离线数仓中的增删改问题。

接下来从实践的角度来看Hudi如何解决业务问题

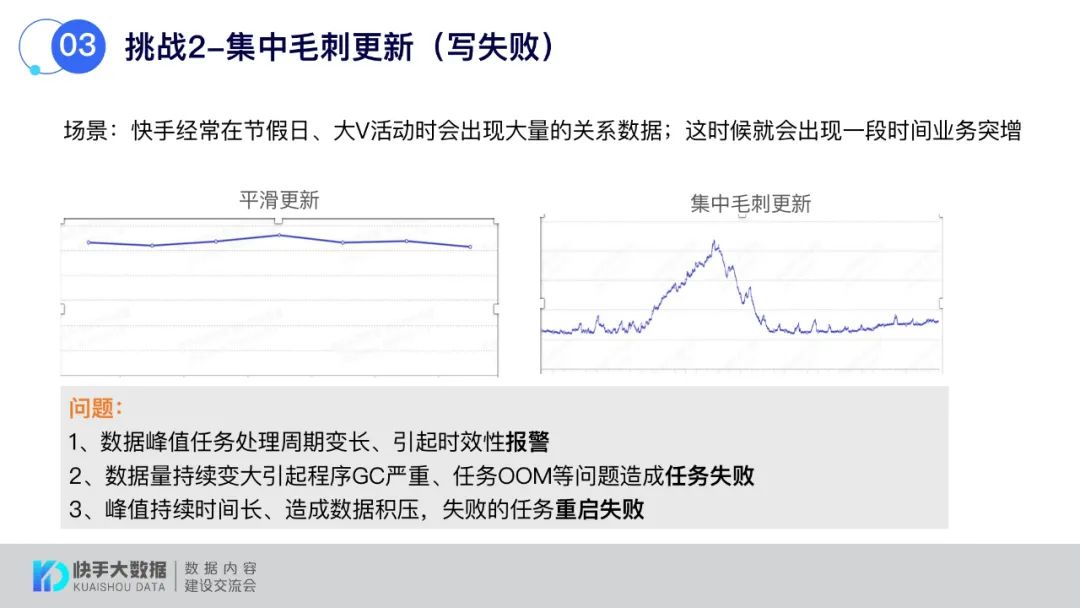
对大量数据进行大量更新时效性差,SLA压力大,另外就是数据局部更新资源浪费严重。

Hudi的模型设计与传统的离线数仓模型设计不相同,认知上有所不同。

另外一个挑战是Hudi的写模型设计,包括主键、分区设计以及一些策略的设计等。

基于Hudi的模型,对数据同步模型进行了设计,来解决千亿级数据量的亿级更新问题。

确定合适的分区和文件大小来解决数据更新中的毛刺问题
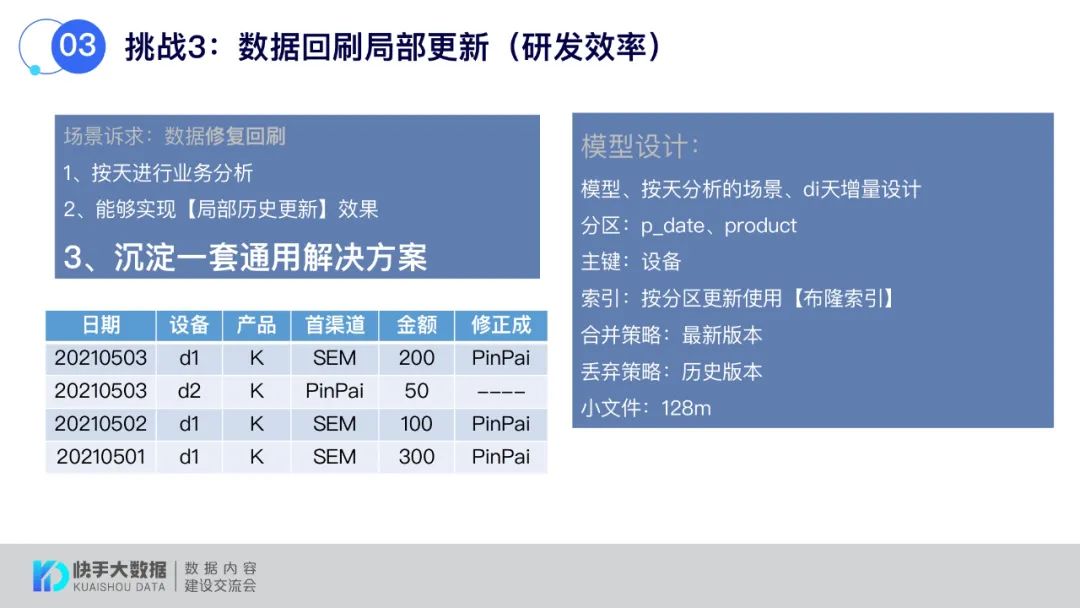
对于数据回刷场景下的局部更新也有了很好的解决,沉淀了一套通用解决方案。

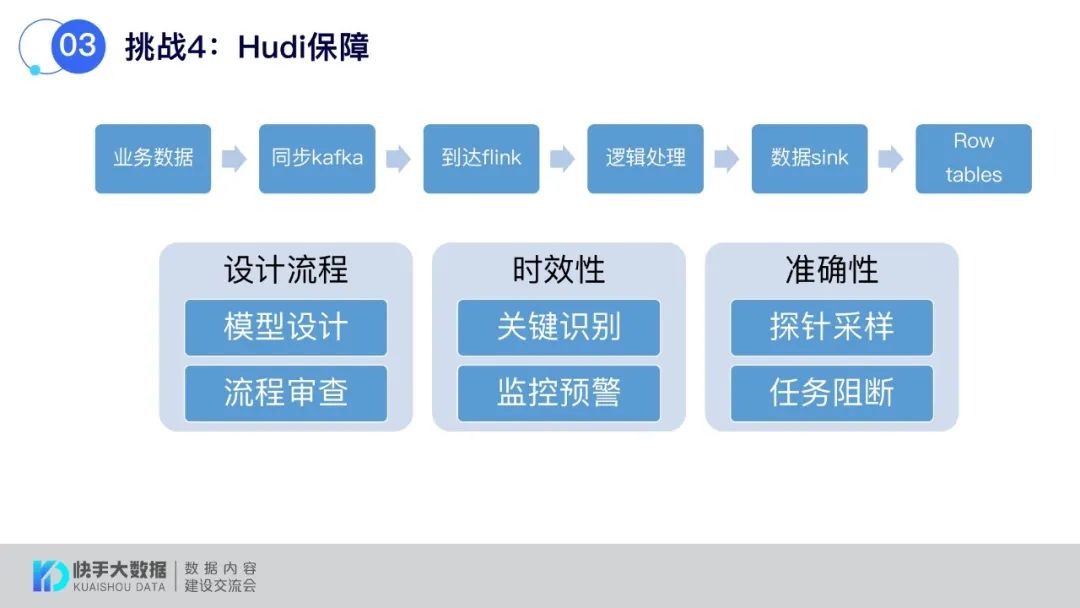
还有一个挑战是如何保障Hudi作业正常运行,包括设计流程、时效性和准确性几方面做了一些建设。
使用Hudi方案后取得了很好的效果,包括时效、资源、基于Hudi的通用解决方案等方面效果都非常不错。

推荐阅读