
Hinton发布44页最新论文「独角戏」GLOM,表达神经网络中部分-整体层次结构

新智元报道
新智元报道
来源:twitter
编辑:小匀、LRS
【新智元导读】不同图像有不同的结构,而传统的神经网络无法把固定输入的图像转换为动态的层次结构(解析树)。Hinton的最新论文中,他提出GLOM,通过提出island的概念来表示解析树的节点,可以显著提升transformer类模型的可解释性。
2017年,深度学习三巨头之一的Geoffrey Hinton,发表了两篇论文解释「胶囊网络(Capsule Networks)」。
在当时,这是一种全新的神经网络,它基于一种新的结构——胶囊,在图像分类上取得了更优越的性能,解决了CNN的某些缺陷,例如无法理解图片和语义关系、没有空间分层和空间推理的能力等。
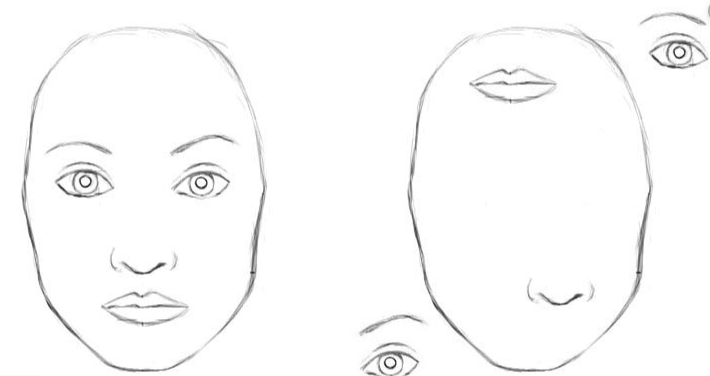
在CNN中,左右两幅图都可被网络识别为人脸
甚至,Hinton自己也公开表示过,他要证明为何卷积神经网络完全是「垃圾」,应该以自己的胶囊网络代替。
过去三年中,他每年都会推出一个新版本的胶囊网络。
本月,Hinton兴奋地说道,自己发表了一篇新论文,名为如何在神经网络中表示部分-整体层次结构?(How to represent part-whole hierarchies in a neural network)

本论文中,他提出了一个叫做GLOM的架构,可以在神经网络中使用胶囊来表示视觉的层次结构,即部分-整体的关系。
署名只有Hinton一人。

GLOM通过提出island的概念来表示解析树的节点。GLOM可以显著提升transformer类的模型的可解释性。可以显著提升transformer类的模型的可解释性。
提出island,GLOM表示解析树的节点
有强有力的心理学证据表明,人们将视觉场景解析成部分-整体的层次结构,并将部分和整体之间相对不变的视觉关系,建模为部分和整体之间的坐标变换。
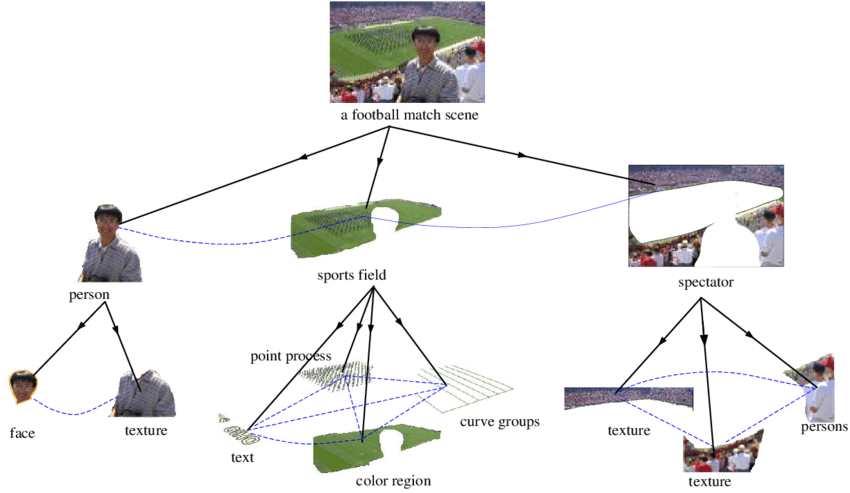
如果做出能和人们一样理解图像的神经网络,我们就需要弄清楚,神经网络如何才能表示部分-整体的层次结构?
这是很困难的,不同图像有不同的结构,而传统的神经网络无法把固定输入的图像转换为动态的层次结构(解析树)。
而这,也是「胶囊模型」被提出的动机。
这些模型做出了这样的假设:一个胶囊就是一组神经元,每个胶囊对应表示图片特定位置的一个目标。
然后可以通过激活这些预先存在的、特定类型的胶囊,并在他们之间建立适当连接来创建一棵解析树。
本文介绍了一种非常不同的方式,即在神经网络中使用胶囊来表示部分-整体的层次结构。
需要注意的是,论文没有描述一个工作系统。
相反,它提出了一个关于表征的单一想法,将几个不同小组取得的进展合并到一个名为GLOM的假想系统中。
尽管本文主要关注对单一静态图像的感知,但GLOM很容易被理解为一个处理帧序列的流水线。静态图像可以被认为是多个相同帧组成的序列。
GLOM架构,显著提升transformer类的模型的可解释性
GLOM架构由大量的列组成,这些列都使用完全相同的权重。
每一列都是一个空间局部自动编码器的堆栈,可以学习小图像补丁中发生的多层次的表示。每个自动编码器,使用多层自下而上的编码器和解码器,将一级的嵌入转化为相邻一级的嵌入。这些层次对应于部分-整体层次结构中的层次。
例如,当显示一个人脸的图像时,一个列可能会聚集为一个向量,用来表示鼻孔、鼻子、脸和人。
下图显示了不同层次的嵌入如何在单列中相互作用。
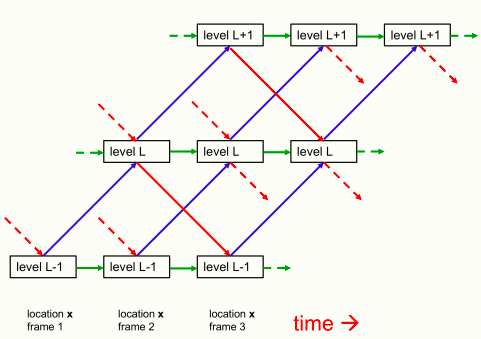
单列GLOM架构中相邻三层之间自下而上、自上而下、同层交互的情况
其中,蓝色箭头和红色箭头分别代表自下而上和自上而下的交互方式,由两个不同的神经网络实现的,并且网络中可以存在隐藏层。
对于一张静态图片来说,绿色箭头可以简化为残差链接用来实现时序的平滑效果。对于视频这种包含多帧序列的情况,绿色箭头的连接转为一个神经网络用来学习时序过程中的胶囊状态的变化。
不同列中同一层次的嵌入向量之间的交互作用,由一个非自适应的、注意力加权的局部平滑器来实现,这一点没有在图片中画出来。这比列内的交互要简单得多,因为它们不需要实现部分整体坐标变换。它们就像多头Transformer中代表不同单词片段的列之间的注意力加权交互,但它们更简单,因为query、key和value都与嵌入向量相同。
列间相互作用通过使某一层次的每个嵌入向量向附近位置的其他类似向量回归,在某一层次产生相同嵌入的岛。这就形成了多个局部的「回声室」,在这个「回声室」中,一个层次的嵌入物主要关注其他相似的嵌入物。
在每一个离散的时间点和每个列中,一个层次的embedding更新为下列四方面的加权平均:
1 由自下而上的神经网作用于下层的embedding在上一时间步产生的预测
2 由自上而下的神经网在上一级的embedding上作用于上一时间步产生的预测
3 前一个时间步长的embedding向量
4 前一时间步相邻列中同层次的embedding的注意力加权平均值
对于一个静态图像来说,随着时间的推移,一个层面的嵌入应该会稳定下来,产生几乎相同的向量的独特岛,如下图所示:
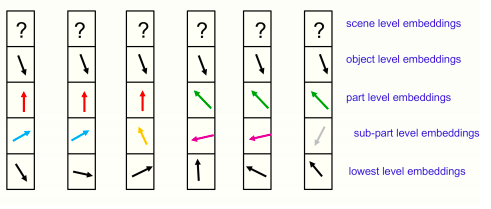
附近六列中某一特定时间的嵌入图片
所有显示的位置都属于同一个对象,场景层面还没有确定一个共享矢量。将每个位置的完整嵌入向量分为部分-整体层次结构中每个层次的独立部分,然后将一个层次的高维嵌入向量作为二维向量显示出来。
这样就可以说明,不同位置的嵌入向量的排列情况。图中所示的各级相同向量的岛代表一棵分析树。
GLOM没有分配神经硬件来表示解析树中的一个节点,也没有给节点指向其前面和后面的指针,而是分配一个合适的活动向量来表示该节点,并对属于该节点的所有位置使用相同的活动向量。访问节点的先后能力是由自下而上和自上而下的神经网络来实现的,而不是用RAM来做表查找。
像BERT一样,整个系统可以在最后一个时间步进行训练,从有缺失区域的输入图像中重建图像,但目标函数还包括两个正则化器,鼓励在每个层次上有接近相同向量的岛。
简单来说,正则器只是新的嵌入在一个层面上与自下而上和自上而下的预测之间的保持一致的一种方法,这有利于形成局部岛。
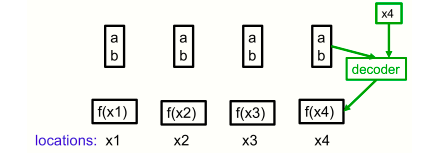
一个非常简单的神经场的例子,使用单个像素作为位置。四个像素的强度都可以用同一个代码(a,b)来表示,即使它们的强度根据函数f(x) = ax+b而变化。解码器有一个额外的输入,它指定了位置。
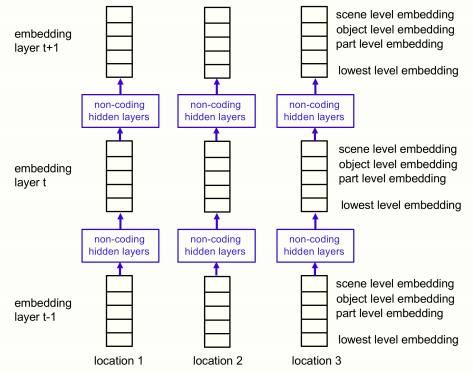
GLOM架构的另一种可视化方法
这是GLOM架构所示架构的另一种可视化方式,显示了用另一种方式看待GLOM架构的各个自下而上和自上而下的神经网。
在这里,该架构与Transformer的关系更加明显。文中第一个图代表时间的水平维度变成了本图中代表层次的垂直维度。
在每个位置,每个层现在都有部分-整体层次结构中所有层次的嵌入。这相当于在图1中垂直压缩了单个时间片内的层次描述。通过这个架构的一次正向传递就可以解释静态图像。这里将所有特定级别的自下而上和自上而下的神经网都显示为单个神经网。
在正向传递过程中,L层的嵌入向量通过多层自下而上的神经网接收来自上一层中L-1层嵌入向量的输入。
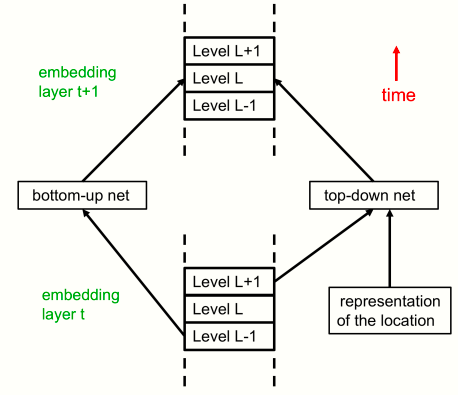
它还通过多层自上而下的神经网络接收来自上一层中L+1级嵌入的输入。在前向传递过程中,对前一层中L+1级的依赖性实现了自上而下的效果。层t+1中的L级嵌入也取决于层t中的L级嵌入和层t中其他附近位置的L级嵌入的注意力加权和,这些层内交互作用没有显示出来。
最后,研究人员还对GLOM与其他神经网络模型(例如胶囊模型,变压器模型,卷积神经网络等)相比,存在的优势作出了分析。
论文发表在https://arxiv.org/abs/2102.12627上。
