深度学习推动了 AI 领域成为目前最热门的学科,但引领这一风潮的先驱者,如 Geoffrey Hinton,正期待对神经网络进行大刀阔斧的修改,让 AI 能力实现新的真正突破。
「如果我们想让神经网络像人类一样理解图像,我们需要找出神经网络是如何表示部分 - 整体层次结构的。」谷歌副总裁、工程研究专家、Vector Institute 首席科学顾问、多伦多大学 Emeritus 荣誉教授 Geoffrey Hinton。
2 月 25 日,一篇署名只有图灵奖得主 Hinton 一人的 44 页论文被上传到了预印版论文平台 arXiv,引发了人工智能社区的震动。

论文链接:https://arxiv.org/abs/2102.12627这是在 2017 年,Hinton 及其合作者的胶囊网络 CapsNet 公开之后,他又一次对于深度学习模型架构的尝试。有趣的是,人们拜读后发现,这一文章虽然篇幅很长,但主要叙述的是一种思想,Hinton 期待其他研究者们能够从中获得启发,顺着这样的思路开展后续研究。
Hinton 在论文的摘要中写道:「这篇论文并没有描述一个已经在运行的系统。它只描述了一个有关表示的单一想法, 允许将几个不同的小组所取得的进步组合到一个称为 GLOM 的假想系统中。这些进步包含 Transformer、神经场(neural field)、对比表示学习、模型蒸馏和胶囊网络(capsule)。GLOM 回答了一个问题:具有固定架构的神经网络如何将图像解析为部分 - 整体的层次结构,而每个图像的层次结构又都不同?
这一想法简单地使用相同向量的孤岛来表示解析树中的节点。如果 GLOM 最终被证明可行,则其被应用于视觉或语言任务中时,可以大大改善 transformer 类系统产生表示的可解释性。

Hinton 是否已经对这个想法进行了具体编写代码程度的尝试?对此,作者本人表示:他正在和 Laura Culp、Sara Sabour 一同研究这样的想法。我们知道,Hinton 提及的谷歌研究科学家 Sara Sabour 此前也是胶囊网络论文的第一作者,在 NIPS 2017 论文《Dynamic Routing Between Capsules》出炉之后,Sara 也开源了一份 Capsule 代码。有强有力的心理学证据表明,人类会将视觉场景解析为部分与整体的层次结构,并将部分与整体之间视角不变的空间关系建模为他们为整体和部分分配的内在坐标系之间的坐标变换。如果想让神经网络像人类一样理解图像,我们就要弄清楚神经网络如何表征部分 - 整体这一层次结构。要做到这一点并不容易,因为一个真实的神经网络无法动态地分配一组神经元来表示解析树中的一个节点。神经网络无法动态分配神经元是一系列使用「胶囊」的模型的动机。这些模型假设:一组名为「胶囊」的神经元将永远专注于一个特定类型的一部分,这一类型出现在图像的一个特定区域。然后,可以通过激活这些预先存在的、特定类型的胶囊的子集以及它们之间的适当连接来创建解析树。但是,本论文描述了一种非常不同的方法,使用胶囊来表示神经网络中的部分 - 整体层次结构。尽管本文主要关注单个静态图像的感知,但将 GLOM 看作一个处理帧序列的 pipeline 是最容易理解的,因此一张静态图像将被视为一些相同帧组成的序列。 GLOM 架构是由大量使用相同权重的列组成的。每一列都是空间局部自编码器的堆栈,这些编码器学习在一个小图像 patch 中出现的多级表示。每个自动编码器使用多层自底向上编码器和多层自顶向下解码器将某一层级上的嵌入转换为相邻层级上的嵌入。这些层级与部分 - 整体层次结构中的层级相对应。例如,当显示一张脸的图像时,单个列可能会收敛到表示鼻孔、鼻子、脸和人的嵌入向量上。图 1 显示了不同层级的嵌入如何在单个列中交互。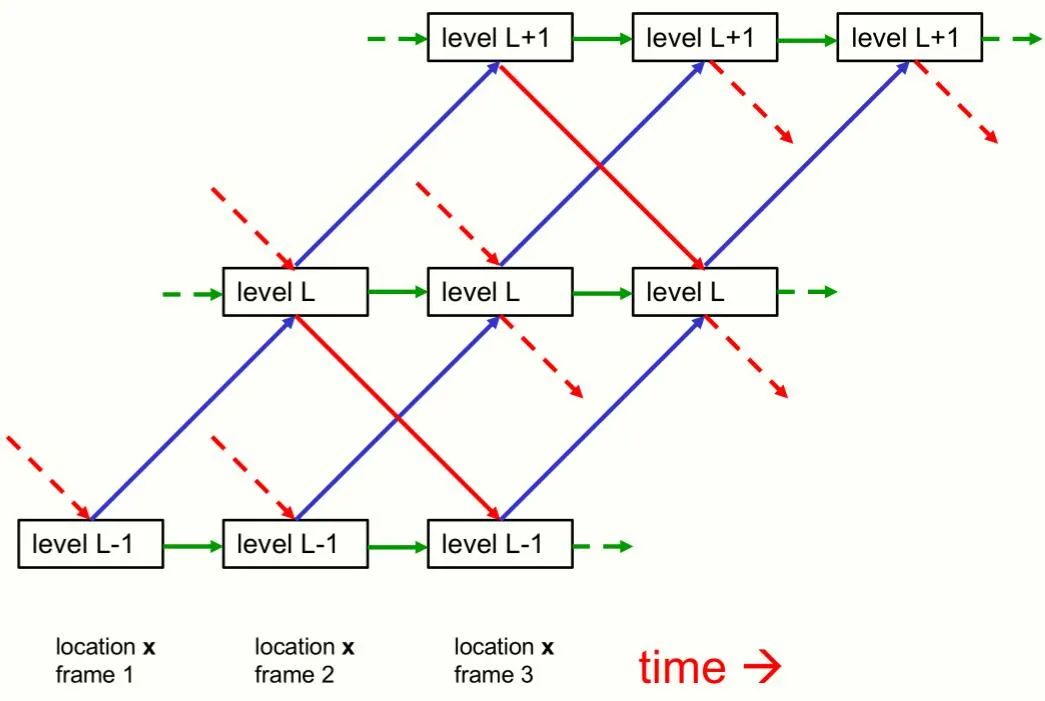

图 1 并没有显示不同列中相同层级的嵌入之间的交互。这些交互比列内的交互简单得多,因为它们不需要实现部分 - 整体坐标转换。它们就像多头 transformer 中表示不同词碎片(word fragment)的列之间的注意力加权交互,但它们更简单,因为查询、键和值向量都与嵌入向量相同。列间交互的作用是在一个层级上产生相同嵌入的 island,方法是让该层级上的每个嵌入向量回归到临近位置上的其他相似向量。这就产生了多个局部「回音室(echo chamber)」,在这些回音室中,某个层级上的嵌入主要关注其他志同道合的嵌入。在每个离散时间和每一列中,将某个层级的嵌入更新为以下 4 个内容的加权平均值:由自底向上的神经网络产生的预测,该网络之前作用于下一个层级的嵌入;
由自顶向下的神经网络产生的预测,该网络之前作用于上一个层级的嵌入;
前一个时间步的嵌入向量;
之前相邻列中相同层级的嵌入的注意力加权平均值。
对于静态图像,某一层级上的嵌入应随时间的流逝而稳定下来,以生成几乎相同向量的不同 island。层级越高,这些 island 应该越大,如图 2 所示。
使用相似性的 island 表征图像的解析,避免了需要分配神经元组来动态地表示解析树的节点,或预先为所有可能的节点预留神经元组的需求。GLOM 没有分配神经硬件来表示解析树中的节点,也没有为节点提供指向其祖先和后代的指针,而是分配了一个适当的活动向量来表征该节点,并为属于该节点的所有位置使用了相同的活动向量。访问节点祖先和后代的能力是通过自底向上和自顶向下的神经网络实现的。而不是通过使用 RAM 进行表查找实现的。和 BERT 一样,整个系统可以进行端到端训练,以便在最后的时间步从存在缺失区域的输入图像中重建图像,而目标函数还包括两个正则化程序,它们促使在每一层上的 island 几乎向量相同。正则化程序只是某层的新嵌入与自下而上和自上而下的预测之间的协议,增加该协议将有助于生成局部 island。与胶囊网络相比,GLOM 的主要优势在于它无需在每个层级将神经元预先分配给一组可能的离散部分,这允许在类似组件(如手臂和腿)之间进行更多的知识共享,并且在属于特定类型对象的部分的数量 / 类型上具有更大的灵活性。同时,GLOM 也不需要动态路径,而且其形成聚类的过程要比胶囊网络好得多。而与最近大热的 Transformer 模型相比,GLOM 的重新布置等效于 transformer 的标准版本,但具有一些不同之处:每层的权重都相同;极大简化的注意力机制;在大多数 transformer 模型中用于提供更多表现力的 multiple head 被重新设计成用于实现部分 - 整体层次结构的多个层级。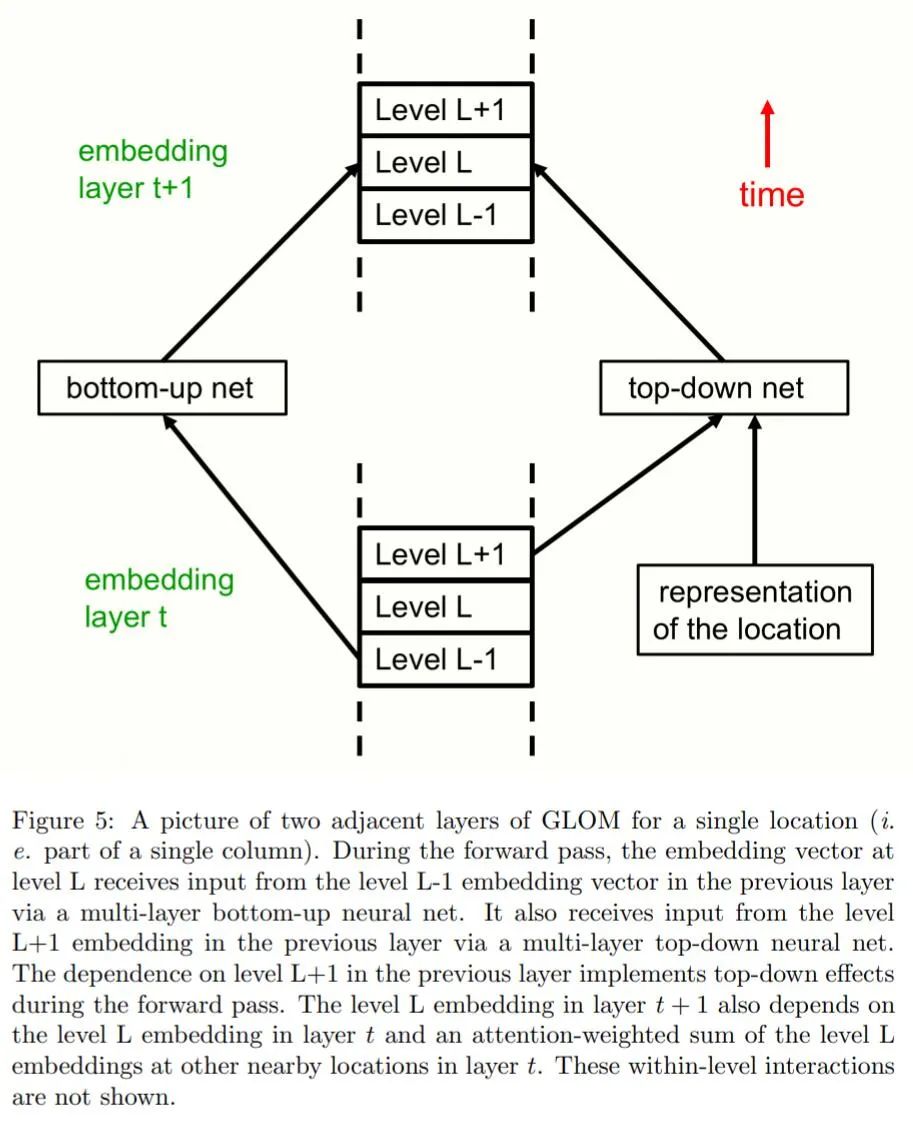
在该研究中,Hinton 表示,当初提出胶囊网络,是因为卷积神经网络 CNN 存在三个可感知的缺陷。如果你熟悉 CNN,那么也可以将 GLOM 视为一种特殊的 CNN,它在以下方面不同于标准 CNN:• 位置之间的交互是通过无参数平均来实现的,该平均实现了符合过滤器,后者允许自己使用霍夫变换(Hough transform)来激活单元,而不仅使用匹配的过滤器。• 迭代不使用单个前馈遍历表示层级,而是允许神经场实现自上而下的影响。• 它包括对比性自监督学习,并执行分层分割,这是识别的一部分,而不再是单独的任务。这解决了不透明的问题。正如网友们的评论所言:不论 Geoffrey Hinton 所提出的是否是一个好主意,人们可以发现他的写作风格非常令人愉快。这位 2018 图灵奖得主在篇幅不小的论文中很好地构建了自己的想法,并通过各种不同视角将其具体化。即使这种模型最终在技术上被证明不是很可行,人们也可以从他推理的过程中获得不小的启发。
本论文最初是一个用于实现的设计文档,但很快就因为需要证明一些设计决策而放慢脚步。Hinton 使用假想的 GLOM 架构作为工具,来传达一系列彼此之间相关联的想法,这些想法旨在揭示神经网络视觉系统的内部构造。由于没有介绍可行的实现,Hinton 更容易专注于将想法表达清楚,避免人们忙于将「idea 质量」与「实现质量」放在一起谈论。「科学和哲学的区别就在于,实验可以证明极其合理的想法是错误的,而极其不合理的想法也可以是正确的。」目前,Hinton 正在参与一个合作项目,以检验 GLOM 架构的能力。同时,他也希望其他研究小组能够参与到验证上述想法的行列。解析树中的节点由相似向量的 island 表示,这一观点统一了两种非常不同的理解感知的方法。第一种方法是经典的格式塔学派,主张人脑的运作原理属于整体论,整体不同于其部件的总和,还提出了「场(field)」的理论来建模感知。在 GLOM 中,一个 percept 就是一个场,表示整体的共享嵌入向量实际上与表示部分的共享嵌入向量非常不同。第二种方法是经典的人工智能派别,它依靠结构描述来建立感知模型。GLOM 也有结构描述,解析树中的每个节点都有自己的「地址(address)」,但地址位于可能嵌入的连续空间中,而不是硬件位置的离散空间中。一些深度学习的批评者认为,神经网络不能处理组合的层次体系,需要有一个「神经符号」接口,使神经网络的前端和后端能够将高级推理移交给一个更加 symbolic 的系统。而 Hinton 相信,人类的主要推理模式是使用类比(analogy),而这些类比之所以成为可能,是因为学到的高维向量之间存在相似性。他还给出了一个关于神经符号接口的类比,认为这一接口就像汽车制造商们花费 50 年的时间阐释电动机的缺点,但最终还是纷纷将电动设备加入汽油引擎(混动、电气化)。BERT 的巨大成功以及早期的研究成果(如果任务需要,神经网络可以输出解析树)清楚地表明,如果神经网络愿意,它们可以解析句子。通过构建 BERT 多头之间的交互,使它们对应于表示的级别,并通过添加一个对比学习的 regularizer,以促进在每个级别的多个词碎片上局部 island 的一致性,这可能表明 GLOMBERT 实际上在解析句子。参考内容:https://www.reddit.com/r/MachineLearning/comments/lszl9c/r_new_geoffrey_hinton_paper_on_how_to_represent/https://twitter.com/geoffreyhinton/status/1365311399287808002
