
【深度学习】PyTorch:Bi-LSTM的文本生成
编译 | VK
来源 | Towards Data Science
❝“写作没有规定。有时它来得容易而且完美;有时就像在岩石上钻孔,然后用炸药把它炸开一样。”—欧内斯特·海明威
❞
本文的目的是解释如何通过实现基于LSTMs的强大体系结构来构建文本生成的端到端模型。
博客分为以下几个部分:
介绍
文本预处理
序列生成
模型体系结构
训练阶段
文本生成
完整代码请访问:https://github.com/FernandoLpz/Text-Generation-BiLSTM-PyTorch
介绍
多年来,人们提出了各种各样的建议来建模自然语言,但这是怎么回事呢?“建模自然语言”指的是什么?我们可以认为“建模自然语言”是指对构成语言的语义和语法进行推理,本质上是这样,但它更进一步。
目前,自然语言处理(NLP)领域通过不同的方法和技术处理不同的任务,即对语言进行推理、理解和建模。
自然语言处理(NLP)领域在过去的十年里发展非常迅速。许多模型都从不同的角度提出了解决不同NLP任务的方法。同样,最受欢迎的模型中的共同点是实施基于深度学习的模型。
如前所述,NLP领域解决了大量的问题,特别是在本博客中,我们将通过使用基于深度学习的模型来解决文本生成问题,例如循环神经网络LSTM和Bi-LSTM。同样,我们将使用当今最复杂的框架之一来开发深度学习模型,特别是我们将使用PyTorch的LSTMCell类来开发。
问题陈述
给定一个文本,神经网络将通过字符序列来学习给定文本的语义和句法。随后,将随机抽取一系列字符,并预测下一个字符。
文本预处理
首先,我们需要一个我们要处理的文本。有不同的资源可以在纯文本中找到不同的文本,我建议你看看Gutenberg项目(https://www.gutenberg.org/).。
在这个例子中,我将使用George Bird Grinnell的《Jack Among the Indians》这本书,你可以在这里找到:https://www.gutenberg.org/cache/epub/46205/pg46205.txt。所以,第一章的第一行是:
The train rushed down the hill, with a long shrieking whistle, and then began to go more and more slowly. Thomas had brushed Jack off and thanked him for the coin that he put in his hand, and with the bag in one hand and the stool in the other now went out onto the platform and down the steps, Jack closely following.
如你所见,文本包含大写、小写、换行符、标点符号等。建议你将文本调整为一种形式,使我们能够以更好的方式处理它,这主要降低我们将要开发的模型的复杂性。
我们要把每个字符转换成它的小写形式。另外,建议将文本作为一个字符列表来处理,也就是说,我们将使用一个字符列表,而不是使用“字符串”。将文本作为字符序列的目的是为了更好地处理生成的序列,这些序列将提供给模型(我们将在下一节中详细介绍)。
代码段1-预处理
def read_dataset(file):
letters = ['a','b','c','d','e','f','g','h','i','j','k','l','m',
'n','o','p','q','r','s','t','u','v','w','x','y','z',' ']
# 打开原始文件
with open(file, 'r') as f:
raw_text = f.readlines()
# 将每一行转换为小写
raw_text = [line.lower() for line in raw_text]
# 创建一个包含整个文本的字符串
text_string = ''
for line in raw_text:
text_string += line.strip()
# 。创建一个字符数组
text = list()
for char in text_string:
text.append(char)
# 去掉所有的符号,只保留字母
text = [char for char in text if char in letters]
return text
如我们所见,在第2行我们定义了要使用的字符,所有其他符号都将被丢弃,我们只保留“空白”符号。
在第6行和第10行中,我们读取原始文件并将其转换为小写形式。
在第14行和第19行的循环中,我们创建了一个代表整本书的字符串,并生成了一个字符列表。在第23行中,我们通过只保留第2行定义的字母来过滤文本列表。
因此,一旦文本被加载和预处理,例如:
text = "The train rushed down the hill."
可以得到这样的字符列表:
text = ['t','h','e',' ','t','r','a','i','n',' ','r','u','s','h','e','d',' ','d','o','w','n',
' ','t','h','e',' ','h','i','l','l']
我们已经有了全文作为字符列表。众所周知,我们不能将原始字符直接引入神经网络,我们需要一个数值表示,因此,我们需要将每个字符转换成一个数值表示。为此,我们将创建一个字典来帮助我们保存等价的“字符索引”和“索引字符”。
代码段2-字典创建
def create_dictionary(text):
char_to_idx = dict()
idx_to_char = dict()
idx = 0
for char in text:
if char not in char_to_idx.keys():
# 构建字典
char_to_idx[char] = idx
idx_to_char[idx] = char
idx += 1
return char_to_idx, idx_to_char
我们可以注意到,在第11行和第12行创建了“char-index”和index-char”字典。
到目前为止,我们已经演示了如何加载文本并以字符列表的形式保存它,我们还创建了两个字典来帮助我们对每个字符进行编码和解码。
序列生成
序列生成的方式完全取决于我们要实现的模型类型。如前所述,我们将使用LSTM类型的循环神经网络,它按顺序接收数据(时间步长)。
对于我们的模型,我们需要形成一个给定长度的序列,我们称之为“窗口”,其中要预测的字符(目标)将是窗口旁边的字符。每个序列将由窗口中包含的字符组成。要形成一个序列,窗口一次向右得到一个字符。要预测的字符始终是窗口后面的字符。我们可以在图中清楚地看到这个过程。
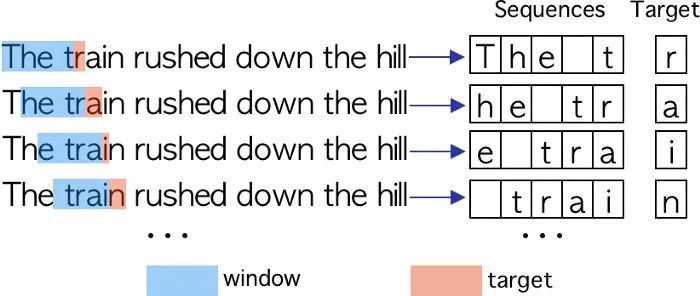
在本例中,窗口的大小为4,这意味着它将包含4个字符。目标是作者在窗口图像右边的第一个字符
到目前为止,我们已经看到了如何以一种简单的方式生成字符序列。现在我们需要将每个字符转换为其各自的数字格式,为此,我们将使用预处理阶段生成的字典。这个过程可以在下图可视化。
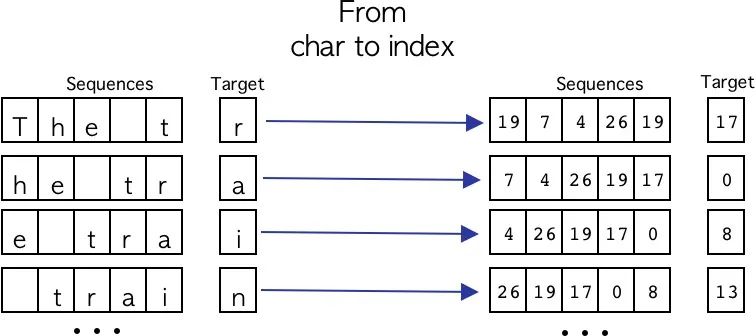
很好,现在我们知道了如何使用一个一次滑动一个字符的窗口来生成字符序列,以及如何将字符转换为数字格式,下面的代码片段显示了所描述的过程。
代码段3-序列生成
def build_sequences(text, char_to_idx, window):
x = list()
y = list()
for i in range(len(text)):
try:
# 从文本中获取字符窗口
# 将其转换为其idx表示
sequence = text[i:i+window]
sequence = [char_to_idx[char] for char in sequence]
#得到target
# 转换到它的idx表示
target = text[i+window]
target = char_to_idx[target]
# 保存sequence和target
x.append(sequence)
y.append(target)
except:
pass
x = np.array(x)
y = np.array(y)
return x, y
太棒了,现在我们知道如何预处理原始文本,如何将其转换为字符列表,以及如何以数字格式生成序列。现在我们来看看最有趣的部分,模型架构。
模型架构
正如你已经在这篇博客的标题中读到的,我们将使用Bi-LSTM循环神经网络和标准LSTM。本质上,我们使用这种类型的神经网络,因为它在处理顺序数据时具有巨大的潜力,例如文本类型的数据。同样,也有大量的文章提到使用基于循环神经网络的体系结构(例如RNN、LSTM、GRU、Bi-LSTM等)进行文本建模,特别是文本生成[1,2]。
❝所提出的神经网络结构由一个嵌入层、一个双LSTM层和一个LSTM层组成。紧接着,后一个LSTM连接到一个线性层。
❞
方法
该方法包括将每个字符序列传递到嵌入层,这将为构成序列的每个元素生成向量形式的表示,因此我们将形成一个嵌入字符序列。随后,嵌入字符序列的每个元素将被传递到Bi-LSTM层。随后,将生成构成双LSTM(前向LSTM和后向LSTM)的LSTM的每个输出的串联。紧接着,每个前向+后向串联的向量将被传递到LSTM层,最后一个隐藏状态将从该层传递给线性层。最后一个线性层将有一个Softmax函数作为激活函数,以表示每个字符的概率。下图显示了所描述的方法。
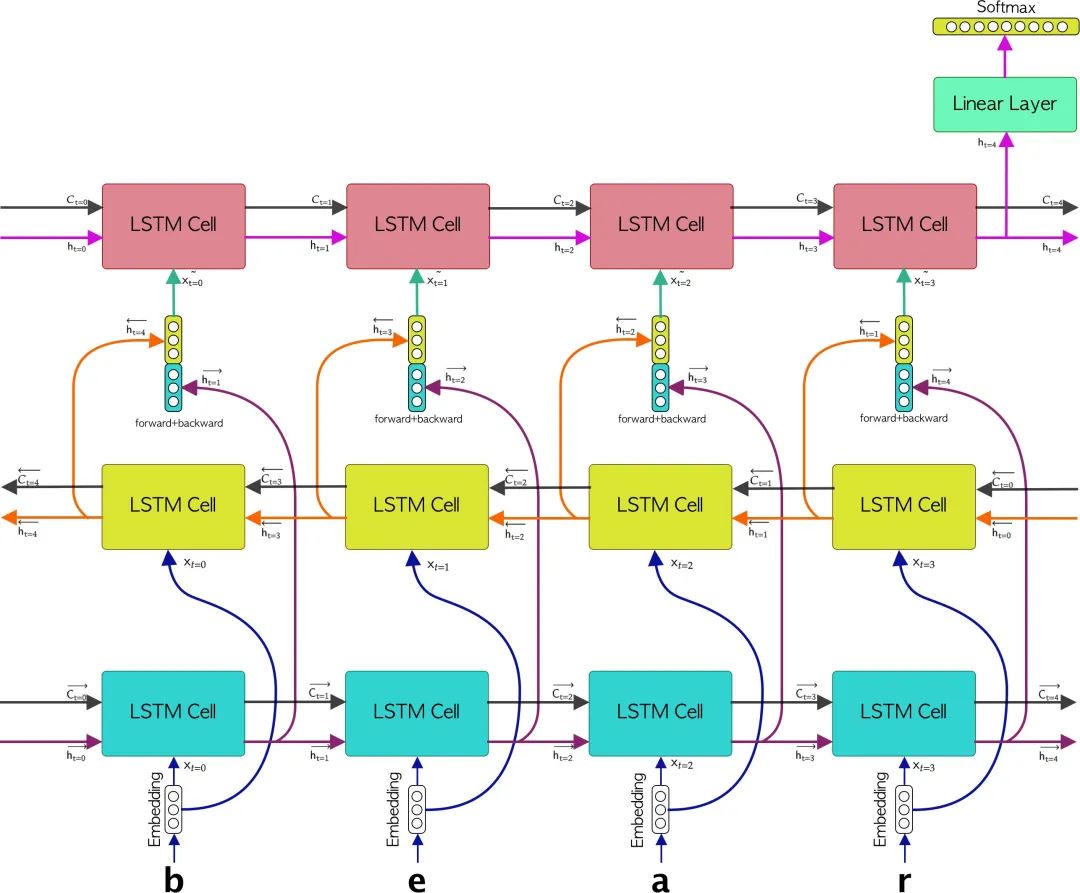
到目前为止,我们已经解释了文本生成模型的体系结构以及实现的方法。现在我们需要知道如何使用PyTorch框架来实现所有这些,但是首先,我想简单地解释一下bilstm和LSTM是如何协同工作的,以便稍后了解如何在代码中实现这一点,那么让我们看看bilstm网络是如何工作的。
Bi-LSTM和LSTM
标准LSTM和Bi-LSTM的关键区别在于Bi-LSTM由2个LSTM组成,通常称为“正向LSTM”和“反向LSTM”。基本上,正向LSTM以原始顺序接收序列,而反向LSTM接收序列。随后,根据要执行的操作,两个LSTMs的每个时间步的每个隐藏状态都可以连接起来,或者只对两个LSTMs的最后一个状态进行操作。在所提出的模型中,我们建议在每个时间步加入两个隐藏状态。
很好,现在我们了解了Bi-LSTM和LSTM之间的关键区别。回到我们正在开发的示例中,下图表示每个字符序列在通过模型时的演变。
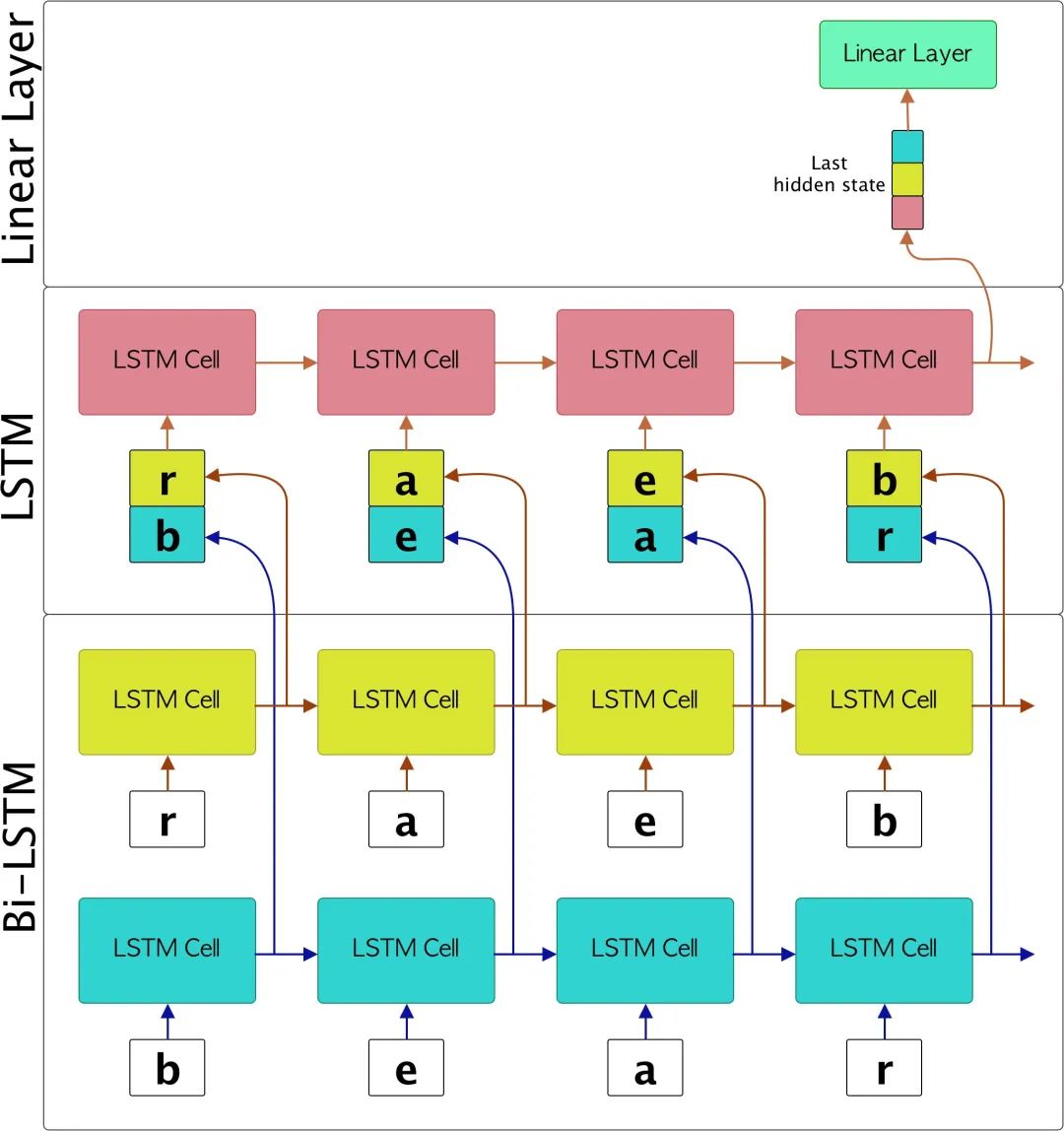
太好了,一旦Bi-LSTM和LSTM之间的交互都很清楚,让我们看看我们是如何在代码中仅使用PyTorch框架中的LSTMcell来实现的。
那么,首先让我们了解一下如何构造TextGenerator类的构造函数,让我们看看下面的代码片段:
代码段4-文本生成器类的构造函数
class TextGenerator(nn.ModuleList):
def __init__(self, args, vocab_size):
super(TextGenerator, self).__init__()
self.batch_size = args.batch_size
self.hidden_dim = args.hidden_dim
self.input_size = vocab_size
self.num_classes = vocab_size
self.sequence_len = args.window
# Dropout
self.dropout = nn.Dropout(0.25)
# Embedding 层
self.embedding = nn.Embedding(self.input_size, self.hidden_dim, padding_idx=0)
# Bi-LSTM
# 正向和反向
self.lstm_cell_forward = nn.LSTMCell(self.hidden_dim, self.hidden_dim)
self.lstm_cell_backward = nn.LSTMCell(self.hidden_dim, self.hidden_dim)
# LSTM 层
self.lstm_cell = nn.LSTMCell(self.hidden_dim * 2, self.hidden_dim * 2)
# Linear 层
self.linear = nn.Linear(self.hidden_dim * 2, self.num_classes)
如我们所见,从第6行到第10行,我们定义了用于初始化神经网络每一层的参数。需要指出的是,input_size等于词汇表的大小(也就是说,我们的字典在预处理过程中生成的元素的数量)。同样,要预测的类的数量也与词汇表的大小相同,序列长度表示窗口的大小。
另一方面,在第20行和第21行中,我们定义了组成Bi-LSTM的两个「LSTMCells」 (向前和向后)。在第24行中,我们定义了LSTMCell,它将与「Bi-LSTM」的输出一起馈送。值得一提的是,隐藏状态的大小是Bi-LSTM的两倍,这是因为Bi-LSTM的输出是串联的。稍后在第27行定义线性层,稍后将由softmax函数过滤。
一旦定义了构造函数,我们需要为每个LSTM创建包含单元状态和隐藏状态的张量。因此,我们按如下方式进行:
代码片段5-权重初始化
# Bi-LSTM
# hs = [batch_size x hidden_size]
# cs = [batch_size x hidden_size]
hs_forward = torch.zeros(x.size(0), self.hidden_dim)
cs_forward = torch.zeros(x.size(0), self.hidden_dim)
hs_backward = torch.zeros(x.size(0), self.hidden_dim)
cs_backward = torch.zeros(x.size(0), self.hidden_dim)
# LSTM
# hs = [batch_size x (hidden_size * 2)]
# cs = [batch_size x (hidden_size * 2)]
hs_lstm = torch.zeros(x.size(0), self.hidden_dim * 2)
cs_lstm = torch.zeros(x.size(0), self.hidden_dim * 2)
# 权重初始化
torch.nn.init.kaiming_normal_(hs_forward)
torch.nn.init.kaiming_normal_(cs_forward)
torch.nn.init.kaiming_normal_(hs_backward)
torch.nn.init.kaiming_normal_(cs_backward)
torch.nn.init.kaiming_normal_(hs_lstm)
torch.nn.init.kaiming_normal_(cs_lstm)
一旦定义了包含隐藏状态和单元状态的张量,是时候展示整个体系结构的组装是如何完成的.
首先,让我们看一下下面的代码片段:
代码片段6-BiLSTM+LSTM+线性层
# 从 idx 到 embedding
out = self.embedding(x)
# 为LSTM准备shape
out = out.view(self.sequence_len, x.size(0), -1)
forward = []
backward = []
# 解开Bi-LSTM
# 正向
for i in range(self.sequence_len):
hs_forward, cs_forward = self.lstm_cell_forward(out[i], (hs_forward, cs_forward))
hs_forward = self.dropout(hs_forward)
cs_forward = self.dropout(cs_forward)
forward.append(hs_forward)
# 反向
for i in reversed(range(self.sequence_len)):
hs_backward, cs_backward = self.lstm_cell_backward(out[i], (hs_backward, cs_backward))
hs_backward = self.dropout(hs_backward)
cs_backward = self.dropout(cs_backward)
backward.append(hs_backward)
# LSTM
for fwd, bwd in zip(forward, backward):
input_tensor = torch.cat((fwd, bwd), 1)
hs_lstm, cs_lstm = self.lstm_cell(input_tensor, (hs_lstm, cs_lstm))
# 最后一个隐藏状态通过线性层
out = self.linear(hs_lstm)
为了更好地理解,我们将用一些定义的值来解释程序,这样我们就可以理解每个张量是如何从一个层传递到另一个层的。所以假设我们有:
batch_size = 64
hidden_size = 128
sequence_len = 100
num_classes = 27
所以x输入张量将有一个形状:
# torch.Size([batch_size, sequence_len])
x : torch.Size([64, 100])
然后,在第2行中,x张量通过嵌入层传递,因此输出将具有一个大小:
# torch.Size([batch_size, sequence_len, hidden_size])
x_embedded : torch.Size([64, 100, 128])
需要注意的是,在第5行中,我们正在reshape x_embedded 张量。这是因为我们需要将序列长度作为第一维,本质上是因为在Bi-LSTM中,我们将迭代每个序列,因此重塑后的张量将具有一个形状:
# torch.Size([sequence_len, batch_size, hidden_size])
x_embedded_reshaped : torch.Size([100, 64, 128])
紧接着,在第7行和第8行定义了forward 和backward 列表。在那里我们将存储Bi-LSTM的隐藏状态。
所以是时候给Bi-LSTM输入数据了。首先,在第12行中,我们在向前LSTM上迭代,我们还保存每个时间步的隐藏状态(hs_forward)。在第19行中,我们迭代向后的LSTM,同时保存每个时间步的隐藏状态(hs_backward)。你可以注意到循环是以相同的顺序执行的,不同之处在于它是以相反的形式读取的。每个隐藏状态将具有以下形状:
# hs_forward : torch.Size([batch_size, hidden_size])
hs_forward : torch.Size([64, 128])
# hs_backward : torch.Size([batch_size, hidden_size])
hs_backward: torch.Size([64, 128])
很好,现在让我们看看如何为最新的LSTM层提供数据。为此,我们使用forward 和backward 列表。在第26行中,我们遍历与第27行级联的forward 和backward 对应的每个隐藏状态。需要注意的是,通过连接两个隐藏状态,张量的维数将增加2倍,即张量将具有以下形状:
# input_tesor : torch.Size([bathc_size, hidden_size * 2])
input_tensor : torch.Size([64, 256])
最后,LSTM将返回大小为的隐藏状态:
# last_hidden_state: torch.Size([batch_size, num_classes])
last_hidden_state: torch.Size([64, 27])
最后,LSTM的最后一个隐藏状态将通过一个线性层,如第31行所示。因此,完整的forward函数显示在下面的代码片段中:
代码片段7-正向函数
def forward(self, x):
# Bi-LSTM
# hs = [batch_size x hidden_size]
# cs = [batch_size x hidden_size]
hs_forward = torch.zeros(x.size(0), self.hidden_dim)
cs_forward = torch.zeros(x.size(0), self.hidden_dim)
hs_backward = torch.zeros(x.size(0), self.hidden_dim)
cs_backward = torch.zeros(x.size(0), self.hidden_dim)
# LSTM
# hs = [batch_size x (hidden_size * 2)]
# cs = [batch_size x (hidden_size * 2)]
hs_lstm = torch.zeros(x.size(0), self.hidden_dim * 2)
cs_lstm = torch.zeros(x.size(0), self.hidden_dim * 2)
# 权重初始化
torch.nn.init.kaiming_normal_(hs_forward)
torch.nn.init.kaiming_normal_(cs_forward)
torch.nn.init.kaiming_normal_(hs_backward)
torch.nn.init.kaiming_normal_(cs_backward)
torch.nn.init.kaiming_normal_(hs_lstm)
torch.nn.init.kaiming_normal_(cs_lstm)
# 从 idx 到 embedding
out = self.embedding(x)
# 为LSTM准备shape
out = out.view(self.sequence_len, x.size(0), -1)
forward = []
backward = []
# 解开Bi-LSTM
# 正向
for i in range(self.sequence_len):
hs_forward, cs_forward = self.lstm_cell_forward(out[i], (hs_forward, cs_forward))
hs_forward = self.dropout(hs_forward)
cs_forward = self.dropout(cs_forward)
forward.append(hs_forward)
# 反向
for i in reversed(range(self.sequence_len)):
hs_backward, cs_backward = self.lstm_cell_backward(out[i], (hs_backward, cs_backward))
hs_backward = self.dropout(hs_backward)
cs_backward = self.dropout(cs_backward)
backward.append(hs_backward)
# LSTM
for fwd, bwd in zip(forward, backward):
input_tensor = torch.cat((fwd, bwd), 1)
hs_lstm, cs_lstm = self.lstm_cell(input_tensor, (hs_lstm, cs_lstm))
# 最后一个隐藏状态通过线性层
out = self.linear(hs_lstm)
return out
到目前为止,我们已经知道如何使用PyTorch中的LSTMCell来组装神经网络。现在是时候看看我们如何进行训练阶段了,所以让我们继续下一节。
训练阶段
太好了,我们来训练了。为了执行训练,我们需要初始化模型和优化器,稍后我们需要为每个epoch 和每个mini-batch,所以让我们开始吧!
代码片段8-训练阶段
def train(self, args):
# 模型初始化
model = TextGenerator(args, self.vocab_size)
# 优化器初始化
optimizer = optim.RMSprop(model.parameters(), lr=self.learning_rate)
# 定义batch数
num_batches = int(len(self.sequences) / self.batch_size)
# 训练模型
model.train()
# 训练阶段
for epoch in range(self.num_epochs):
# Mini batches
for i in range(num_batches):
# Batch 定义
try:
x_batch = self.sequences[i * self.batch_size : (i + 1) * self.batch_size]
y_batch = self.targets[i * self.batch_size : (i + 1) * self.batch_size]
except:
x_batch = self.sequences[i * self.batch_size :]
y_batch = self.targets[i * self.batch_size :]
# 转换 numpy array 为 torch tensors
x = torch.from_numpy(x_batch).type(torch.LongTensor)
y = torch.from_numpy(y_batch).type(torch.LongTensor)
# 输入数据
y_pred = model(x)
# loss计算
loss = F.cross_entropy(y_pred, y.squeeze())
# 清除梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
print("Epoch: %d , loss: %.5f " % (epoch, loss.item()))
一旦模型被训练,我们将需要保存神经网络的权重,以便以后使用它们来生成文本。为此我们有两种选择,第一种是定义一个固定的时间段,然后保存权重,第二个是确定一个停止函数,以获得模型的最佳版本。在这个特殊情况下,我们将选择第一个选项。在对模型进行一定次数的训练后,我们将权重保存如下:
代码段9-权重保存
# 保存权重
torch.save(model.state_dict(), 'weights/textGenerator_model.pt')
到目前为止,我们已经看到了如何训练文本生成器和如何保存权重,现在我们将进入这个博客的最后一部分,文本生成!
文本生成
我们已经到了博客的最后一部分,文本生成。为此,我们需要做两件事:第一件事是加载训练好的权重,第二件事是从序列集合中随机抽取一个样本作为模式,开始生成下一个字符。下面我们来看看下面的代码片段:
代码片段10-文本生成器
def generator(model, sequences, idx_to_char, n_chars):
# 评估模式
model.eval()
# 定义softmax函数
softmax = nn.Softmax(dim=1)
# 从序列集合中随机选取索引
start = np.random.randint(0, len(sequences)-1)
# 给定随机的idx来定义模式
pattern = sequences[start]
# 利用字典,它输出了Pattern
print("\nPattern: \n")
print(''.join([idx_to_char[value] for value in pattern]), "\"")
# 在full_prediction中,我们将保存完整的预测
full_prediction = pattern.copy()
# 预测开始,它将被预测为一个给定的字符长度
for i in range(n_chars):
# 转换为tensor
pattern = torch.from_numpy(pattern).type(torch.LongTensor)
pattern = pattern.view(1,-1)
# 预测
prediction = model(pattern)
# 将softmax函数应用于预测张量
prediction = softmax(prediction)
# 预测张量被转换成一个numpy数组
prediction = prediction.squeeze().detach().numpy()
# 取概率最大的idx
arg_max = np.argmax(prediction)
# 将当前张量转换为numpy数组
pattern = pattern.squeeze().detach().numpy()
# 窗口向右1个字符
pattern = pattern[1:]
# 新pattern是由“旧”pattern+预测的字符组成的
pattern = np.append(pattern, arg_max)
# 保存完整的预测
full_prediction = np.append(full_prediction, arg_max)
print("Prediction: \n")
print(''.join([idx_to_char[value] for value in full_prediction]), "\"")
因此,通过在以下特征下训练模型:
window : 100
epochs : 50
hidden_dim : 128
batch_size : 128
learning_rate : 0.001
我们可以生成以下内容:
Seed:
one of the prairie swellswhich gave a little wider view than most of them jack saw quite close to the
Prediction:
one of the prairie swellswhich gave a little wider view than most of them jack saw quite close to the wnd banngessejang boffff we outheaedd we band r hes tller a reacarof t t alethe ngothered uhe th wengaco ack fof ace ca e s alee bin cacotee tharss th band fofoutod we we ins sange trre anca y w farer we sewigalfetwher d e we n s shed pack wngaingh tthe we the we javes t supun f the har man bllle s ng ou y anghe ond we nd ba a she t t anthendwe wn me anom ly tceaig t i isesw arawns t d ks wao thalac tharr jad d anongive where the awe w we he is ma mie cack seat sesant sns t imes hethof riges we he d ooushe he hang out f t thu inong bll llveco we see s the he haa is s igg merin ishe d t san wack owhe o or th we sbe se we we inange t ts wan br seyomanthe harntho thengn th me ny we ke in acor offff of wan s arghe we t angorro the wand be thing a sth t tha alelllll willllsse of s wed w brstougof bage orore he anthesww were ofawe ce qur the he sbaing tthe bytondece nd t llllifsffo acke o t in ir me hedlff scewant pi t bri pi owasem the awh thorathas th we hed ofainginictoplid we me
正如我们看到的,生成的文本可能没有任何意义,但是有一些单词和短语似乎形成了一个想法,例如:
we, band, pack, the, man, where, he, hang, out, be, thing, me, were
恭喜,我们已经到了博客的结尾!
结论
在本博客中,我们展示了如何使用PyTorch的LSTMCell建立一个用于文本生成的端到端模型,并实现了基于循环神经网络LSTM和Bi-LSTM的体系结构。
值得注意的是,建议的文本生成模型可以通过不同的方式进行改进。一些建议的想法是增加要训练的文本语料库的大小,增加epoch以及每个LSTM的隐藏层大小。另一方面,我们可以考虑一个基于卷积LSTM的有趣的架构。
参考引用
[1] LSTM vs. GRU vs. Bidirectional RNN for script generation(https://arxiv.org/pdf/1908.04332.pdf)
[2] The survey: Text generation models in deep learning(https://www.sciencedirect.com/science/article/pii/S1319157820303360)
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: