
实战项目:基于机器学习的 Python 信用卡欺诈检测!
当我们在网上购买产品时,很多人喜欢使用信用卡,但信用卡欺诈常常会在身边发生,网络安全正成为我们生活中至关重要的一部分。
为了解决这个问题,我们需要利用机器学习算法构建一个异常行为的识别系统,如果发现可疑,中止操作。
在本文中,我将分享一个端到端模型训练方法,从数据获取方向到最后模型筛选对比,喜欢的小伙伴欢迎关注、点赞支持我。
关于数据
本文使用的为 kaggle 数据:https://www.kaggle.com/mlg-ulb/creditcardfraud,该数据集为 2013 年欧洲持卡人的真实银行交易。出于安全考虑,该数据已转换为 PCA 版本,有 29 个特征列和 1 个类列。
导入必要的库
在这里我将导入所有必要的库。由于信用卡数据特征是 PCA 的转换版本,因此我们不需要再次执行特征选择。否则,建议使用 RFE、RFECV、SelectKBest 和 VIF score 来查找适合模型的特征。
#Packages related to general operating system & warnings
import os
import warnings
warnings.filterwarnings('ignore')
#Packages related to data importing, manipulation, exploratory data #analysis, data understanding
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
from termcolor import colored as cl # text customization
#Packages related to data visualizaiton
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
#Setting plot sizes and type of plot
plt.rc("font", size=14)
plt.rcParams['axes.grid'] = True
plt.figure(figsize=(6,3))
plt.gray()
from matplotlib.backends.backend_pdf import PdfPages
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn import metrics
from sklearn.impute import MissingIndicator, SimpleImputer
from sklearn.preprocessing import PolynomialFeatures, KBinsDiscretizer, FunctionTransformer
from sklearn.preprocessing import StandardScaler, MinMaxScaler, MaxAbsScaler
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, LabelBinarizer, OrdinalEncoder
import statsmodels.formula.api as smf
import statsmodels.tsa as tsa
from sklearn.linear_model import LogisticRegression, LinearRegression, ElasticNet, Lasso, Ridge
from sklearn.neighbors import KNeighborsClassifier, KNeighborsRegressor
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, export_graphviz, export
from sklearn.ensemble import BaggingClassifier, BaggingRegressor,RandomForestClassifier,RandomForestRegressor
from sklearn.ensemble import GradientBoostingClassifier,GradientBoostingRegressor, AdaBoostClassifier, AdaBoostRegressor
from sklearn.svm import LinearSVC, LinearSVR, SVC, SVR
from xgboost import XGBClassifier
from sklearn.metrics import f1_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
导入数据集
导入数据集非常简单。你只需使用 python 中的 pandas 模块导入它,运行如下命令,「数据集可文末下载」。
data=pd.read_csv("creditcard.csv")
数据处理与理解
关于这些数据,你可能会注意到一个问题,数据集是不平衡的,因为数据集中正常交易占绝大多数,只有少数百分比的交易是欺诈的。
让我们检查一下数据分布。
Total_transactions = len(data)
normal = len(data[data.Class == 0])
fraudulent = len(data[data.Class == 1])
fraud_percentage = round(fraudulent/normal*100, 2)
print(cl('Total number of Trnsactions are {}'.format(Total_transactions), attrs = ['bold']))
print(cl('Number of Normal Transactions are {}'.format(normal), attrs = ['bold']))
print(cl('Number of fraudulent Transactions are {}'.format(fraudulent), attrs = ['bold']))
print(cl('Percentage of fraud Transactions is {}'.format(fraud_percentage), attrs = ['bold']))

我们还可以使用以下代码检查空值。
data.info()
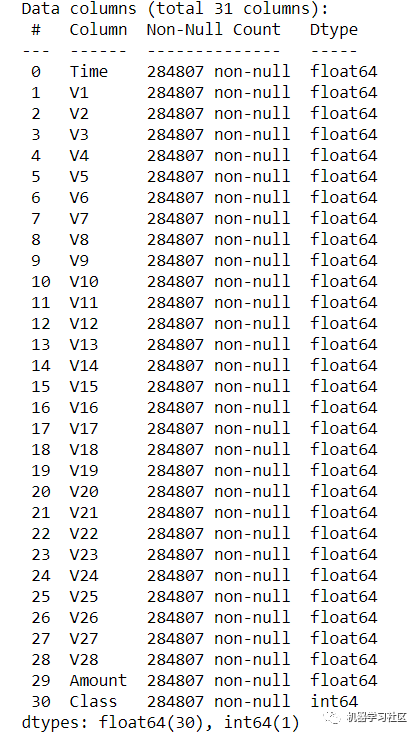
根据每列的计数,我们没有空值。此外,可以尝试应用特征选择方法来检查结果是否得到优化。
我在数据中观察到 28 个特征是 PCA 的转换版本,但字段"Amount "是原始的。在检查最小值和最大值时,我发现差异很大,可能会偏离我们的结果。 在这种情况下,我按照如下方法整理。
在这种情况下,我按照如下方法整理。
sc = StandardScaler()
amount = data['Amount'].values
data['Amount'] = sc.fit_transform(amount.reshape(-1, 1))
我们还有一个变量,即 time,它可能是一个外部决定因素,在我们的建模过程中,舍弃它。
我们还可以检查任何重复数据。在删除任何重复数据之前,数据集中有 284807 行。 去重
去重
data.drop_duplicates(inplace=True)

因此,我们有大约9000笔重复交易。
训练与测试分离
在拆分训练和测试之前,我们需要定义因变量和自变量。因变量也称为 X,自变量称为 y。
X = data.drop('Class', axis = 1).values
y = data['Class'].values
现在,让我们拆分训练和测试数据。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 1)
就这样,我们现在有两个不同的数据集。
构建模型
我们将尝试不同的机器学习模型。定义模型要容易得多。一行代码就可以定义我们的模型。同样,一行代码可以在我们的数据上拟合模型。我们也可以通过选择不同的优化参数来调整这些模型。
1)决策树
DT = DecisionTreeClassifier(max_depth = 4, criterion = 'entropy')
DT.fit(X_train, y_train)
dt_yhat = DT.predict(X_test)
让我们查看一下决策树模型的准确性。
print('Accuracy score of the Decision Tree model is {}'.format(accuracy_score(y_test, tree_yhat)))
Accuracy score of the Decision Tree model is 0.999288989494457
查看决策树模型的F1分数。
print('F1 score of the Decision Tree model is {}'.format(f1_score(y_test, tree_yhat)))
F1 score of the Decision Tree model is 0.776255707762557
查看混淆矩阵:
confusion_matrix(y_test, tree_yhat, labels = [0, 1])

2)随机森林
rf = RandomForestClassifier(max_depth = 4)
rf.fit(X_train, y_train)
rf_yhat = rf.predict(X_test)
让我们看一下随机森林模型的准确性。
print('Accuracy score of the Random Forest model is {}'.format(accuracy_score(y_test, rf_yhat)))
Accuracy score of the Random Forest model is 0.9993615415868594
查看随机森林模型的F1分数。
print('F1 score of the Random Forest model is {}'.format(f1_score(y_test, rf_yhat)))
F1 score of the Random Forest model is 0.7843137254901961
3)XGBoost
xgb = XGBClassifier(max_depth = 4)
xgb.fit(X_train, y_train)
xgb_yhat = xgb.predict(X_test)
让我们看一下 XGBoost 模型的准确性。
print('Accuracy score of the XGBoost model is {}'.format(accuracy_score(y_test, xgb_yhat)))
Accuracy score of the XGBoost model is 0.9995211561901445
查看 XGBoost 模型的F1分数。
print('F1 score of the XGBoost model is {}'.format(f1_score(y_test, xgb_yhat)))
F1 score of the XGBoost model is 0.8421052631578947
结论
我们刚刚获得了 99.95% 的信用卡欺诈检测准确率。这一数字并不令人惊讶,因为我们的数据是针对一个类别的。
根据我们的 F1-Score 得分,XGBoost 是我们案例的赢家。这里唯一需要注意的是我们用于模型训练的数据。数据特征是PCA的变换版本。
福利时间
近日吴恩达新书《Machine Learning Yearning》中文版开放下载!

《Machine Learning Yearning》是吴恩达历时两年,根据自己多年实践经验整理出来的一本机器学习、深度学习实践经验宝典。里面讲的机器学习课程非常棒,很适合数学基础不是很好的人自学,最近中文版也开放下载阅读了!
如何下载?
1. 识别并关注下方公众号;
2. 在下面公众号(非本号)后台回复关键字「吴恩达」。