
史上最全推荐系统传统算法合集
基于邻域的算法
隐语义模型
决策树模型
逻辑回归

1.1 基于邻域的算法(协调过滤)
1.1.1 UserCF
找到和目标用户兴趣相似的用户集合; 将集合中用户喜欢的未出现在目标用户的兴趣列表中的 item 以一定的权值排序后推荐给用户
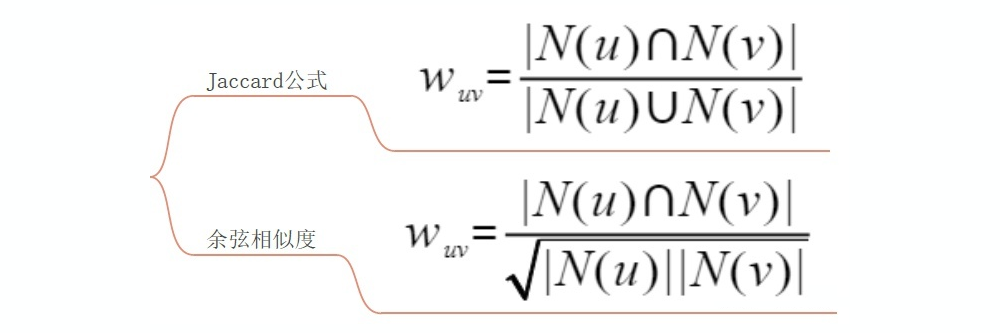
由于很多用户两两之间并没有对同样的物品产生过行为,用用户-物品表计算用户相似度很多时候计算都是浪费的,可以利用物品-用户倒排表简化计算。 加入热门商品惩罚,用户对冷门物品采取相同行为更能说明两者的相似性
1.1.2 ItemCF
计算物品之间的相似性
根据物品的相似度和用户的历史行为给用户生成推荐列表
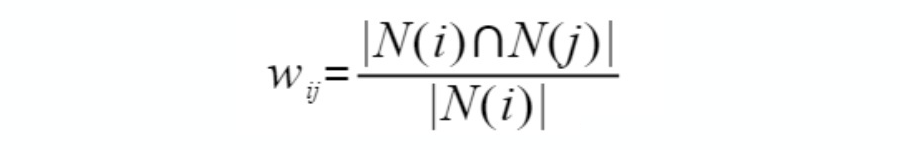
余弦相似度
加入热门用户惩罚,或者直接忽略过分活跃用户
利用用户-物品倒排表
同类物品相似度归一化
加大对热门物品的惩罚 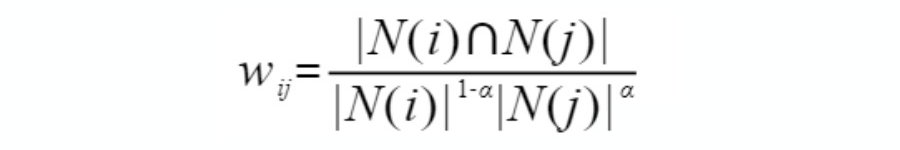
两个不同领域的热门商品有很高的相似度
1.1.3 UserCF与ItemCF比较

代码链接:github.com/mercurialgh/
1.2 UserCF 实验
不加入热门商品惩罚:
K=8
1.nitems=5

1.nitems=10

1.nitems=20

1.nitems=40

1.nitems=160

nitems=10
1.k=4

1.k=8
1.k=16

1.k=32

1.k=160

加入热门商品惩罚:
1.k=8,n=10,不热门商品惩罚:
1.k=8,n=10,热门商品惩罚

1.3 ItemCF实验
不加入活跃用户惩罚:
K=8
1.n=5

1.n=10

1.n=20

1.n=40

nitems=10

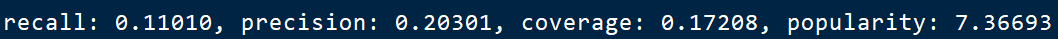

加入活跃用户惩罚:

同类物品相似度归一化


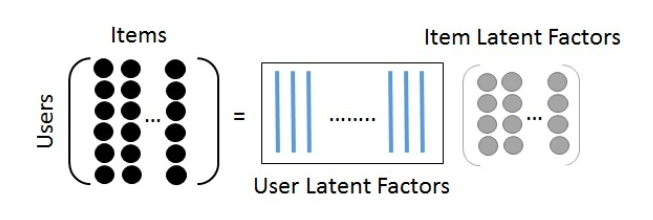
在隐语义模型中,我们使用同样的维度来表征(Embedding)item 和用户。对于 item,这个表征就是 item 表现出的对应维度的特征强度;对于用户,就是用户表现出的对对应维度特征的偏好强度。用用户的表征向量点乘 item 的表征向量,就可以得到用户对该条目的偏好描述。
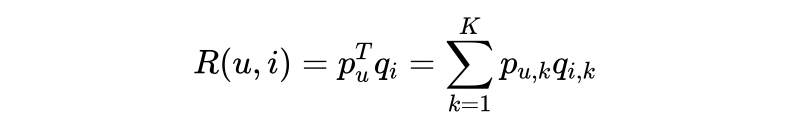
表示用户 u 对 item i 的喜好程度,其中关于用户和条目的描述维度有 k 个,这个参数是自定义的。
我们对模型的优化目标:
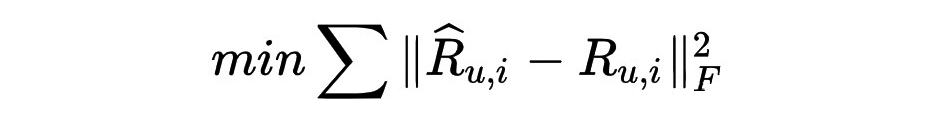
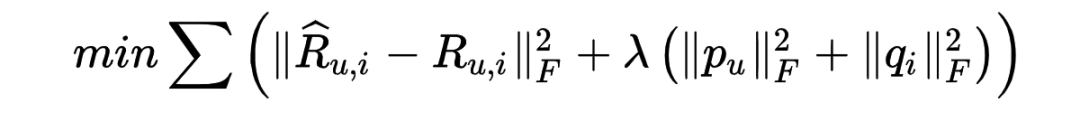
负样本构造应该遵循的原则:
对每个用户,要保证正负样本均衡
对每个用户采样负样本时,要选取那些热门,而用户没有行为的物品
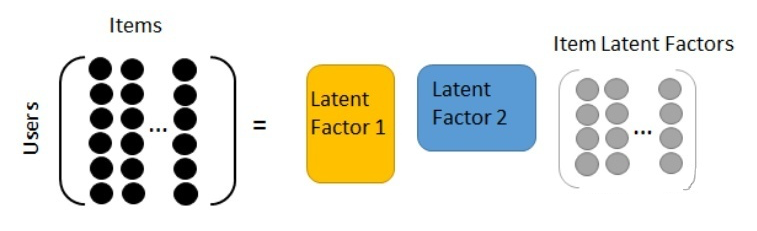
针对的问题:
类别特征经过 one-hot 编码后数据稀疏性 一些特征两两组合之后往往与 label 有更强的关联性
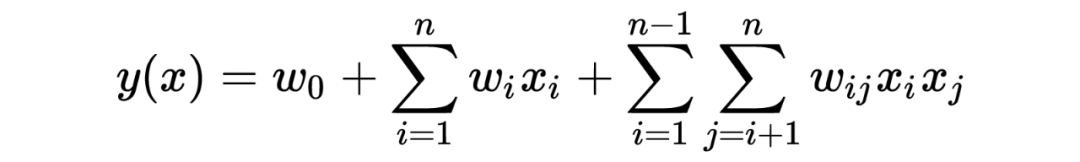
特征数量为 N,二次项系数为 N(N-1)/2,复杂度太高 one-hot 特征太稀疏,特征组合之后更加稀疏

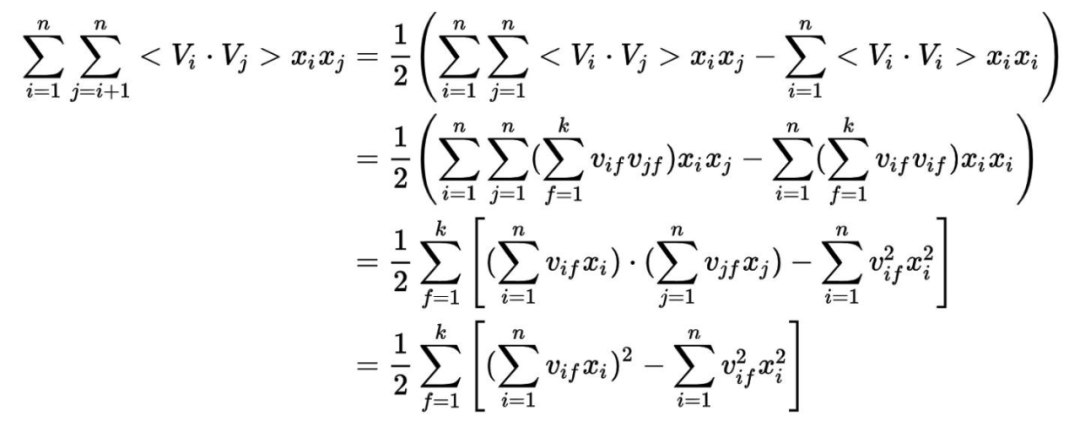
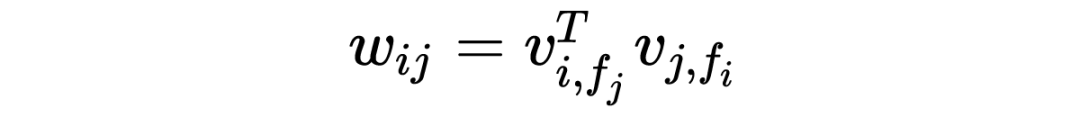
LFM 具有比较好的理论基础,它是一种学习方法,通过优化一个设定的指标建立最优的模型。基于邻域的方法更多的是一种基于统计的方法,并没有学习过程。
LFM 在生成一个用户推荐列表时速度太慢,因此不能在线实时计算。 ItemCF 算法支持很好的推荐解释,它可以利用用户的历史行为解释推荐结果。但 LFM 无法提供这样的解释。

3.1 GBDT
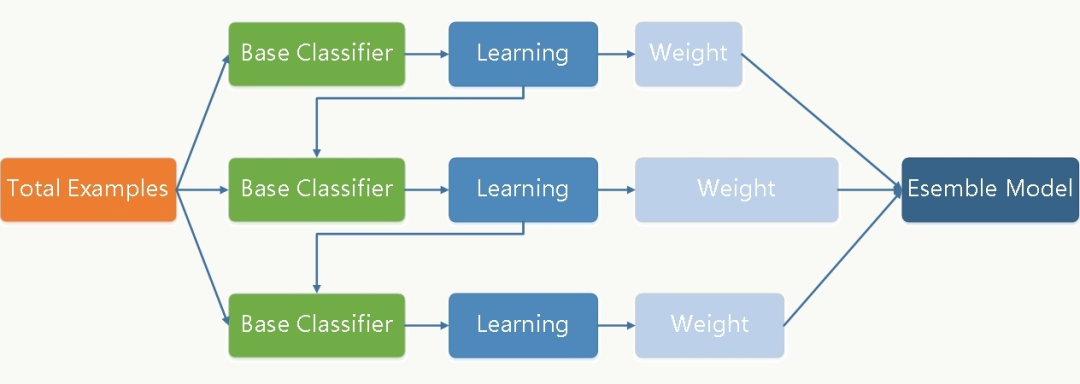
算法流程如下:
计算残差 拟合残差学习得到弱分类器 得到新的强学习器
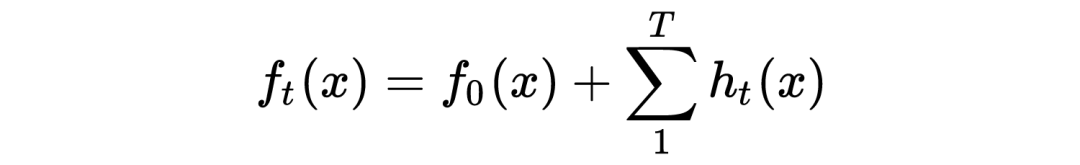
3.1.1 GBDT回归算法
假设训练集样本 ,最大迭代次数 T,损失函数 L,输出的强学习器 ,回归算法的流程如下:
2. 对迭代次数 t=1,...T;
对样本 i=1,...m;计算梯度 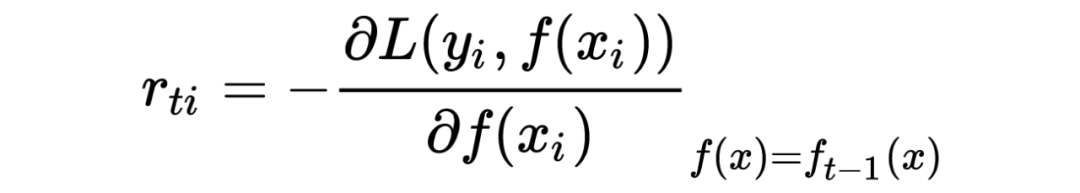
利用 ,拟合一颗 CART 树,得到第 t 棵回归树,其对应的叶子节点区域为 ,j=1,2,..J。其中 J 为回归树 t 的叶子节点个数。 对叶子区域 j=1,2,3,…,J,计算最佳拟合值:
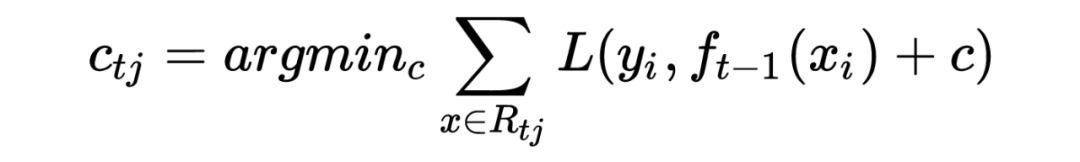
更新强学习器

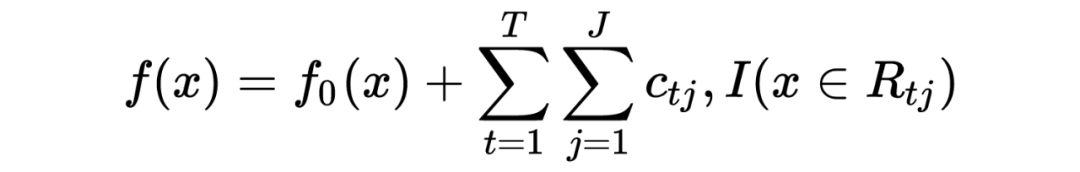
3.1.2 GBDT分类算法
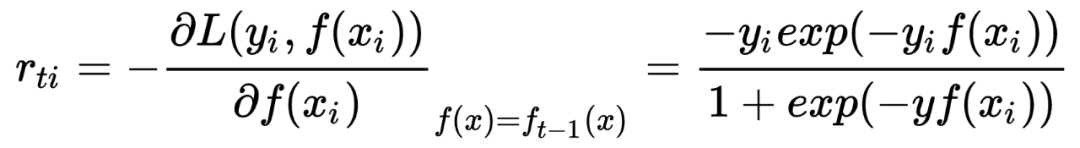
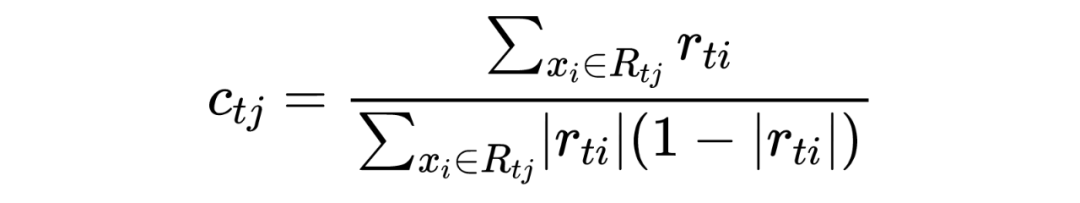
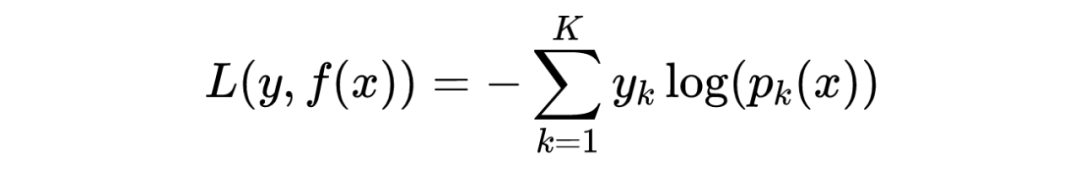
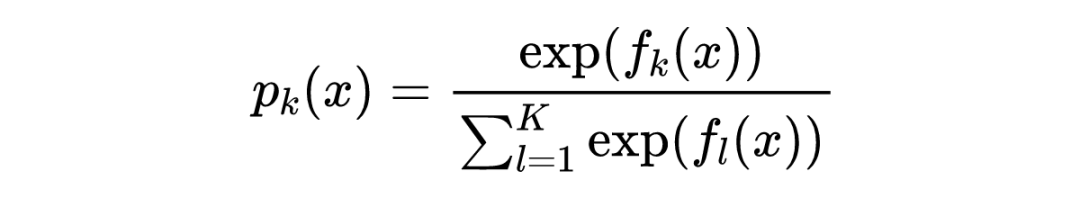
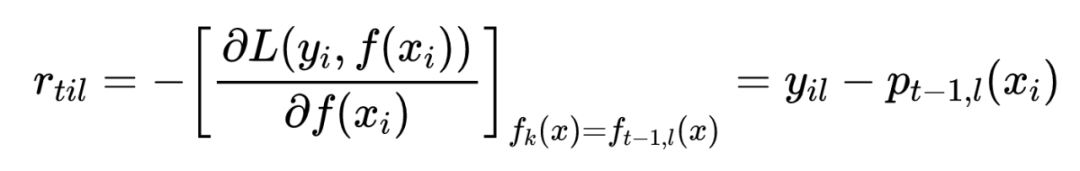
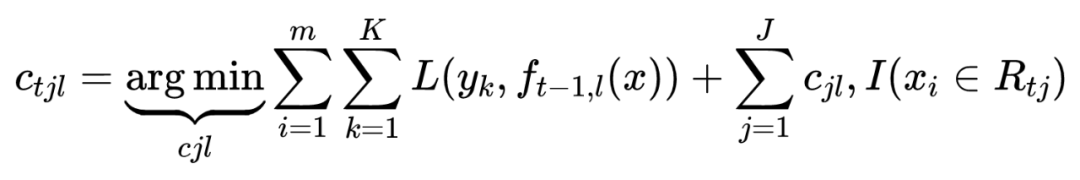
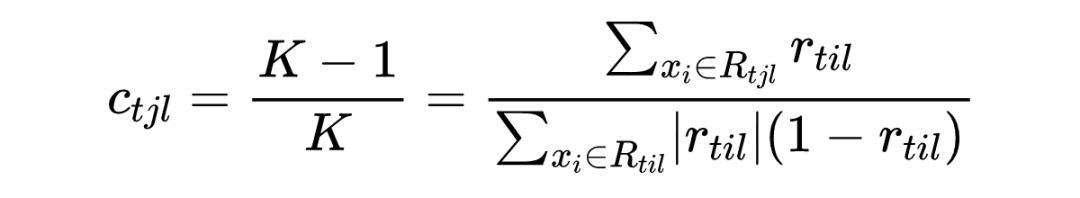
3.1.3 正则化
针对 GBDT 正则化,我们通过子采样比例方法和定义步长 v 方法来防止过拟合。
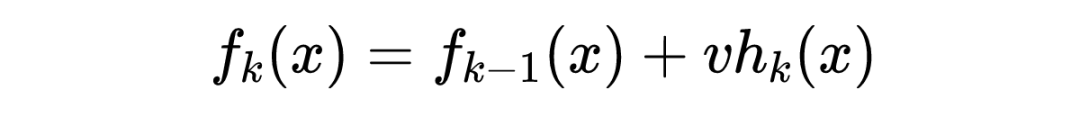
经验表明:一个小的学习率(v<0.1)可以显著提高模型的泛化能力(相比较于 v=1)。
如果学习率较大会导致预测性能出现较大波动。
3.2 XGB
3.2.1 算法原理
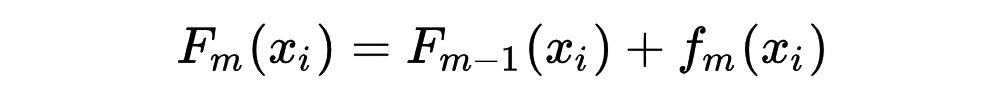
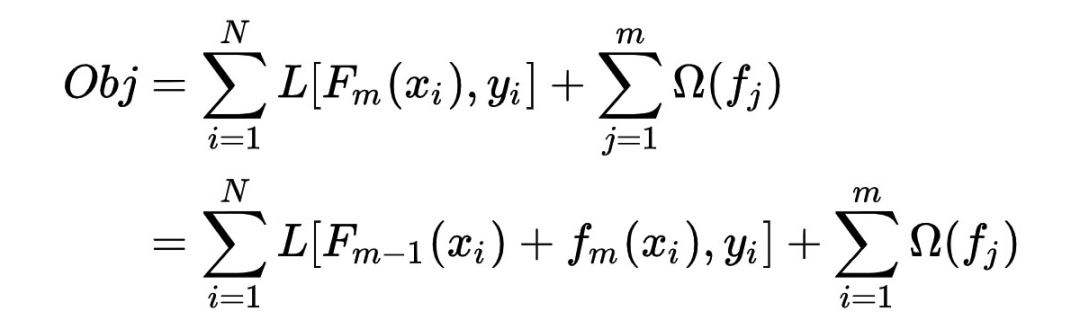
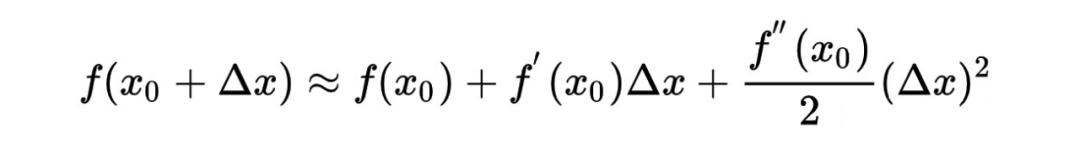
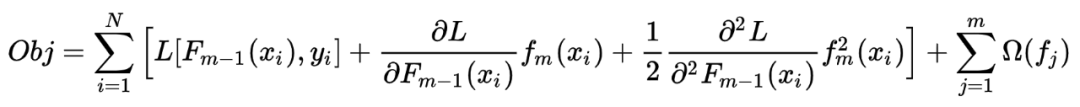
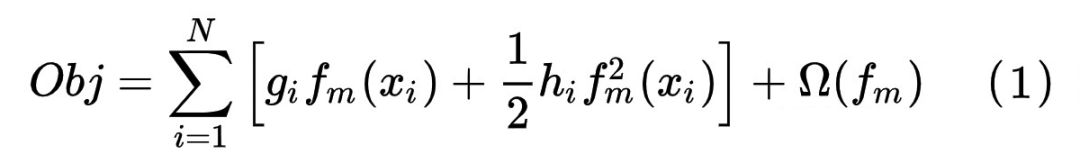
3.2.2 xgb的正则化
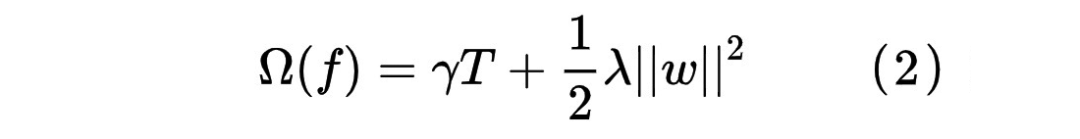
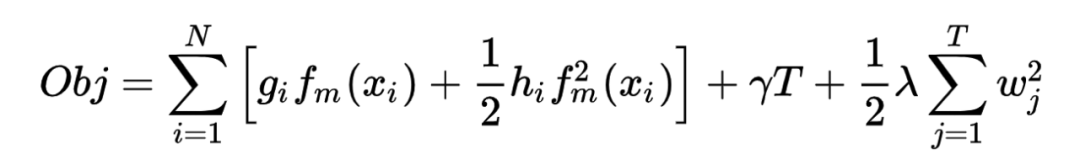
3.2.3 节点分裂准则
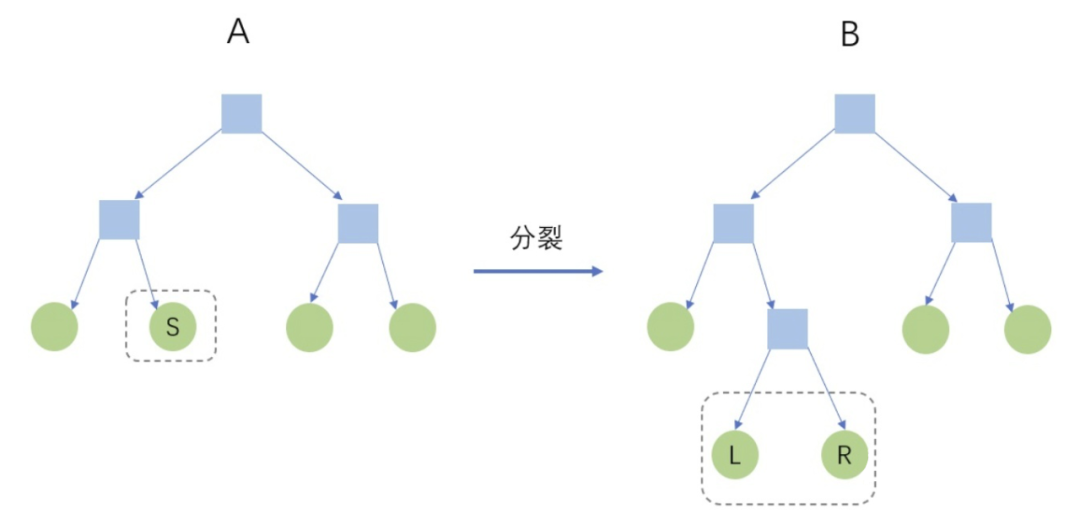
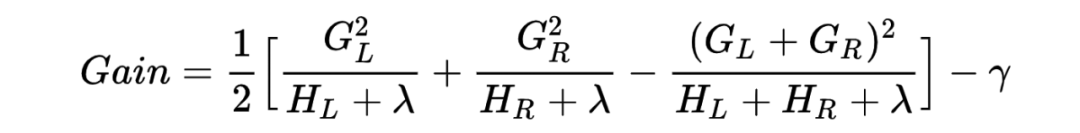
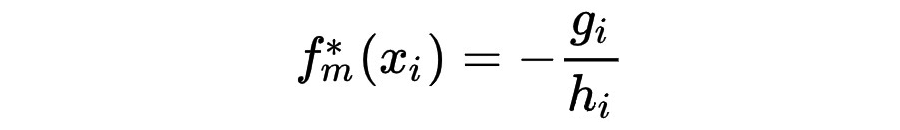
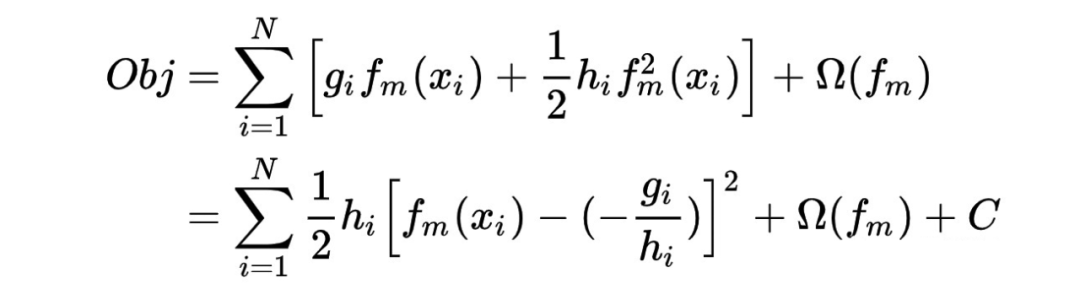
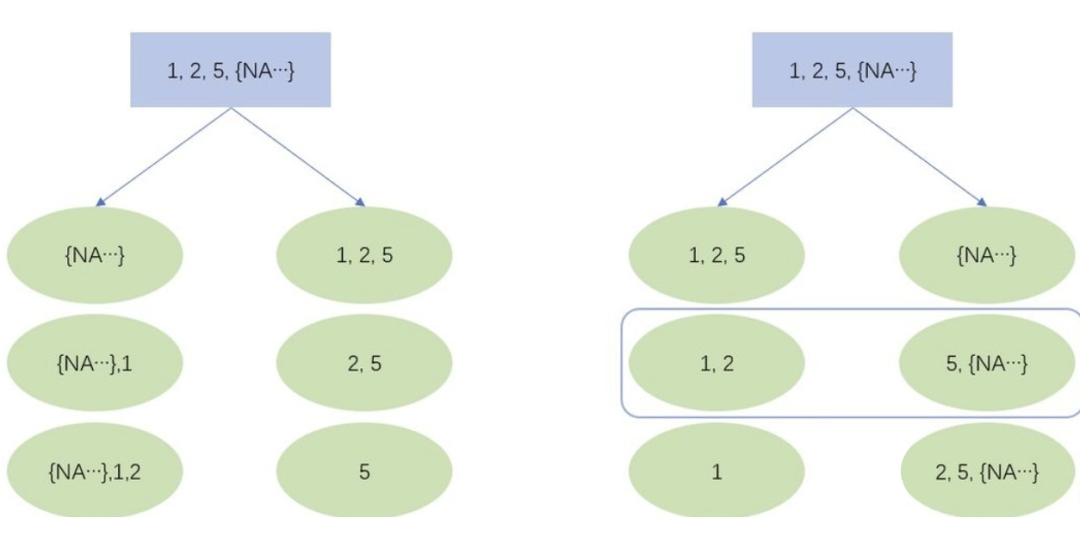
如上图所示,若某个特征值取值为 1,2,5 和大量的 NA,XGBoost 会遍历以上 6 种情况(3 个非缺失值的切分点 × 缺失值的两个方向),最大的分裂收益就是本特征上的分裂收益,同时,NA 将被分到右节点。
3.2.4 工程优化
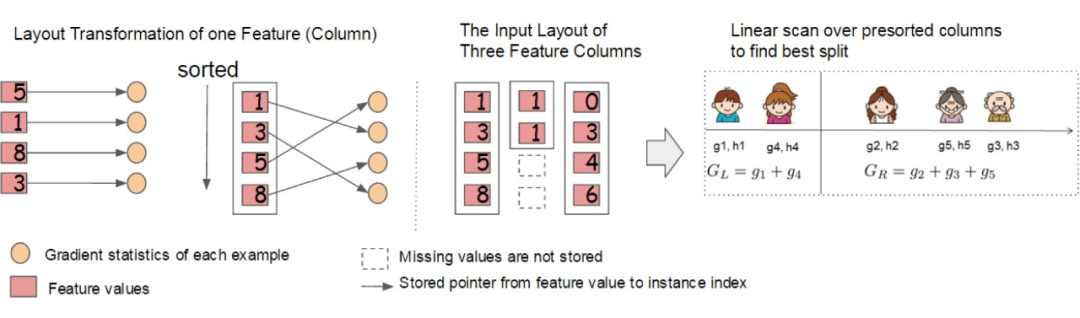
3. 核外块计算
数据量过大时,不能同时全部载入内存。XGBoost 将数据分为多个 blocks 并储存在硬盘中,使用一个独立的线程专门从磁盘中读取数据到内存中,实现计算和读取数据的同时进行。为了进一步提高磁盘读取数据性能,XGBoost 还使用了两种方法:一是通过压缩 block,用解压缩的开销换取磁盘读取的开销;二是将 block 分散储存在多个磁盘中,有助于提高磁盘吞吐量。
3.2.5 与GBDT比较
性质:GBDT 是机器学习算法,XGBoost 除了算法内容还包括一些工程实现方面的优化。
基于二阶导:GBDT 使用的是损失函数一阶导数,相当于函数空间中的梯度下降;而 XGBoost 还使用了损失函数二阶导数,相当于函数空间中的牛顿法。
正则化:XGBoost 显式地加入了正则项来控制模型的复杂度,能有效防止过拟合。
列采样:XGBoost 采用了随机森林中的做法,每次节点分裂前进行列随机采样。
缺失值处理:XGBoost 运用稀疏感知策略处理缺失值,而 GBDT 没有设计缺失策略。
并行高效:XGBoost 的列块设计能有效支持并行运算,提高效率。

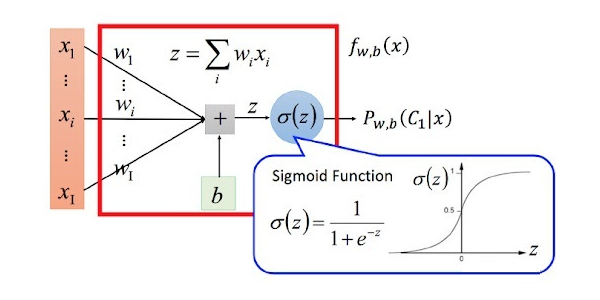
在推荐系统中,可以将是否点击一个商品看成一个概率事件,被推荐的商品无非两种可能性:1.被点击;2.不被点击。那么就可以将这个推荐问题转换成一个分类问题。逻辑回归是监督学习中的分类算法,所以可以使用逻辑回归来进行一个分类预测。
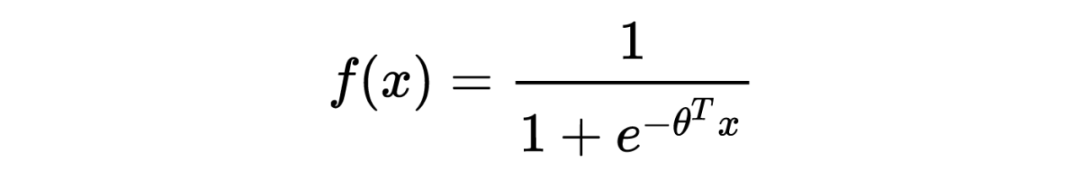
推荐阅读:
推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)