
Petastorm深度学习分布式训练库
Petastorm 是由 Uber ATG(Advanced Technologies Group) 开发的开源数据访问库。这个库可以直接基于数 TB Parquet 格式的数据集进行单机或分布式训练和深度学习模型评估。Petastorm 支持基于 Python 的机器学习框架,如 Tensorflow、Pytorch 和 PySpark,也可以直接用在 Python 代码中。
Petastorm 的特性
Petastorm 提供了各种特性来支持自动驾驶算法的训练,包括行过滤、数据分片、shuffle、对字段子集的访问,以及对时间序列数据(n-gram)的支持。
典型数据集的结构包括:
在自动驾驶汽车测试运行期间收集的传感器数据的多个列,包括摄像头、激光定位器和雷达。
手动生成的标签,作为行的字段进行存储。
行数据按照时间顺序排序,并按照汽车的测试运行进行分组,行组大小通常在 30 到 100 范围内。
Petastorm 架构
Petastorm 的设计目标包括:
通过单数据模式定义进行数据的编码和解码。
为 ML 框架和纯 Python 代码提供可用的高数据加载带宽。
将 Apache Spark 作为分布式集群计算框架来生成数据集。
与 Python、ML 平台无关的 Petastorm 核心组件的实现。
呈现给 Tensorflow 和 PyTorch 框架的原生接口。
etl 包实现了生成数据集的功能。
Reader 是训练和计算代码使用的主要数据加载引擎。Reader 使用 Python 实现,不依赖任何 ML 框架(Tensorflow、Pytorch),并且可以通过 Python 代来实例化和使用。
为 Tensorflow 和 PyTorch 提供适配器。
Unischema 可以被数据集生成和数据加载代码引用。
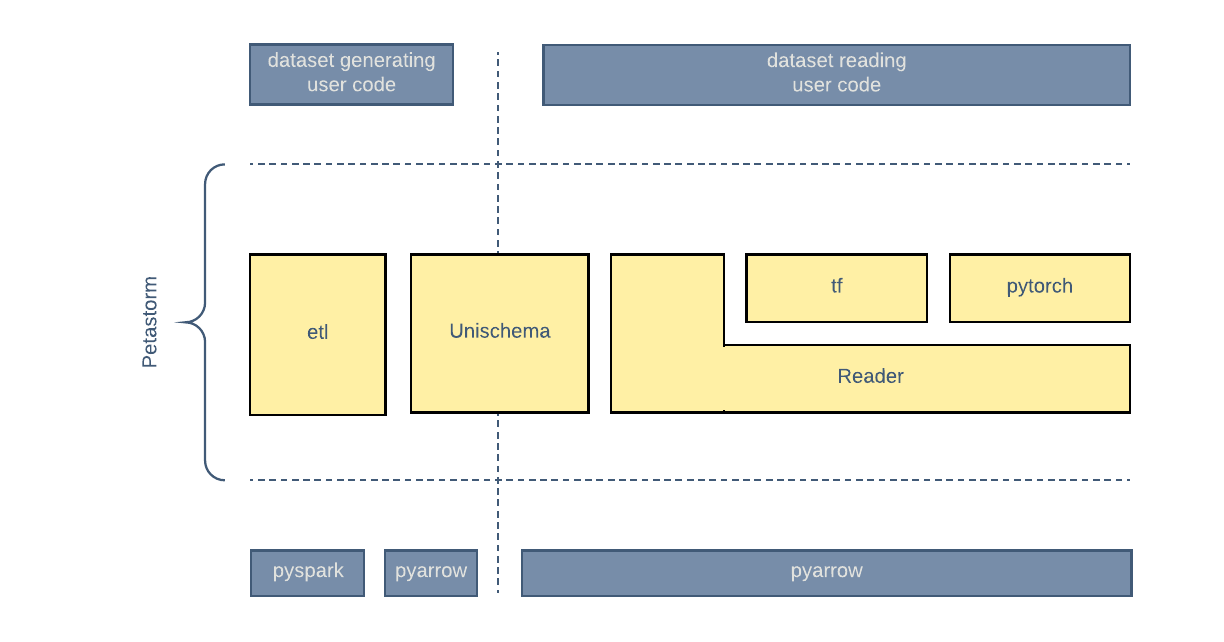
Petastorm 提供了支持数据集生成和读取的组件。Unischema 定义了可供两者使用的公共数据模式。
内容摘自AI前线