
训练/测试集分布不一致解法总结
训练集高分,测试集预测提交后发现分数很低,为什么?有可能是训练集和测试集分布不一致,导致模型过拟合训练集,个人很不喜欢碰到这种线下不错但线上抖动过大的比赛,有种让你感觉好像在“碰运气”,看谁“碰”对了测试集的分布。但实际是有方法可循的,而不是说纯碰运气。本文我将从“训练/测试集分布不一致问题”的发生原因讲起,然后罗列判断该问题的方法和可能的解决手段。
一、发生原因
训练集和测试集分布不一致也被称作数据集偏移(Dataset Shift)。西班牙格拉纳达大学Francisco Herrera教授在他PPT
[1]
里提到数据集偏移有三种类型:
协变量偏移(Covariate Shift)
: 独立变量的偏移,指训练集和测试集的输入服从不同分布,但背后是服从同一个函数关系,如图1所示。
先验概率偏移(Prior Probability Shift)
: 目标变量的偏移。
概念偏移(Concept Shift)
: 独立变量和目标变量之间关系的偏移。
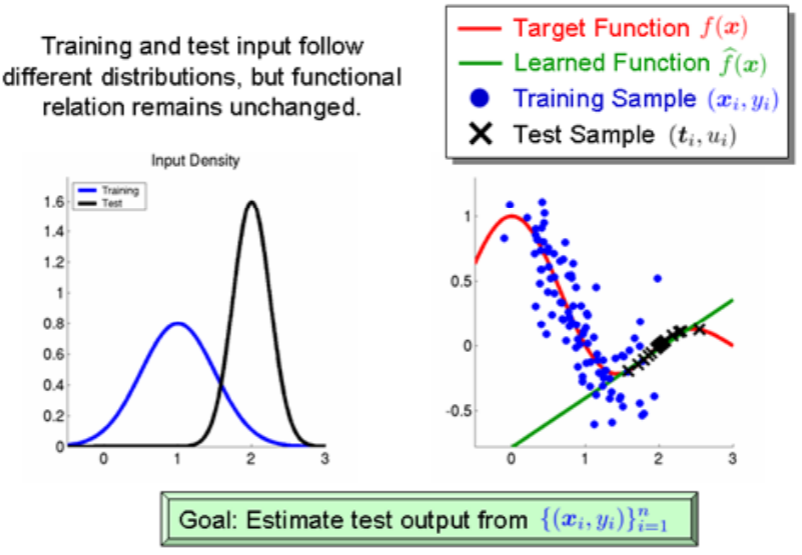
图1:协变量偏移
最常见的有两种原因
[1]
:
样本选择偏差(Sample Selection Bias)
: 训练集是通过有偏方法得到的,例如非均匀选择(Non-uniform Selection),导致训练集无法很好表征的真实样本空间。
环境不平稳(Non-stationary Environments)
: 当训练集数据的采集环境跟测试集不一致时会出现该问题,一般是由于时间或空间的改变引起的。
在分类任务上,有时候官方随机划分数据集,没有考虑类别平衡问题,例如: 训练集类别A数据量远多于类别B,而测试集相反,这类样本选择偏差问题会导致训练好的模型在测试集上鲁棒性很差,因为训练集没有很好覆盖整个样本空间。此外,除了目标变量,输入特征也可能出现样本选择偏差问题,比如要预测泰坦尼克号乘客存活率,而训练集输入特征里“性别”下更多是男性,而测试集里“性别”更多是女性,这样也会导致模型在测试集上表现差。
样本选择偏差也有些特殊的例子,之前我参加阿里天池2021“AI Earth”人工智能创新挑战赛
[2]
,官方提供两类数据集作为训练集,分别是CMIP模拟数据和SODA真实数据,然后测试集又是SODA真实数据,CMIP模拟数据是通过系列气象模型仿真模拟得到的,即有偏方法,但选手都会选择将模拟数据加入训练,因为训练集真实数据太少了,可模拟数据的加入也无可避免的引入了样本选择偏差。
聊完样本选择偏移,我们聊下环境不平稳带来的数据偏移,我想最常见是在时序比赛里了吧,用历史时序数据预测未来时序,未来突发事件很可能带来时序的不稳定表现,这便带来了分布差异。环境因素不仅限于时间和空间,还有数据采集设备、标注人员等。
二、判断方法
1. KDE (核密度估计)分布图
当我们一想到要对比训练集和测试集的分布,便是画概率密度函数直方图,但直方图看分布有两点缺陷: 受bin宽度影响大和不平滑,因此多数人会偏向于使用核密度估计图(Kernel Density Estimation, KDE),KDE是非参数检验,用于估计分布未知的密度函数,相比于直方图,它受bin影响更小,绘图呈现更平滑,易于对比数据分布。我研究生的有一门课的小作业有要去对比直方图和KDE图,相信这个能帮助大家更直观了解到它们的差异:
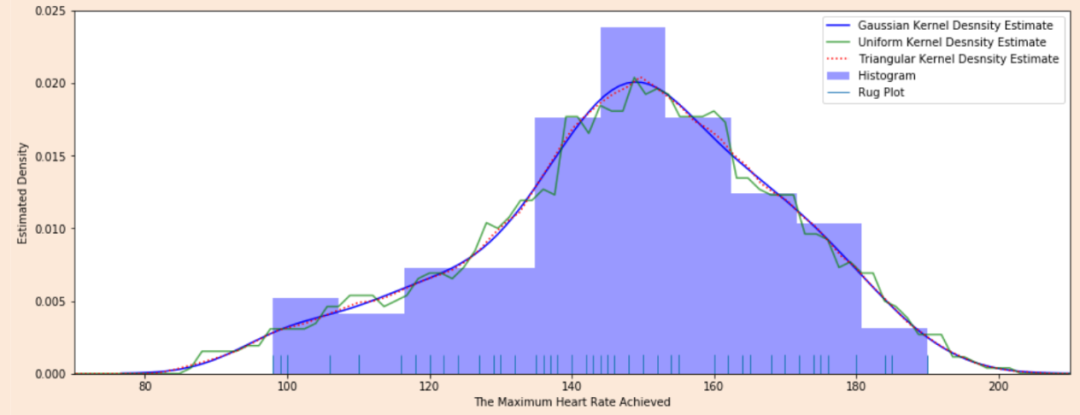
图2:心脏疾病患者最大心率的概率密度函数分布图,数据源自UCI ML开放数据集
这里在略微细讲下KDE,我们先看KDE函数:
是来自未知分布的样本, 是样本总数, 是核函数,h是带宽(Bandwidth)。
核函数定义一个用于生成PDF(概率分布函数Probability Distribution Function)的曲线,不同于将值放入离散bins内,核函数对每个样本值都创建一个独立的概率密度曲线,然后加总这些平滑曲线,最终得到一个平滑连续的概率分布曲线,如下图所示:
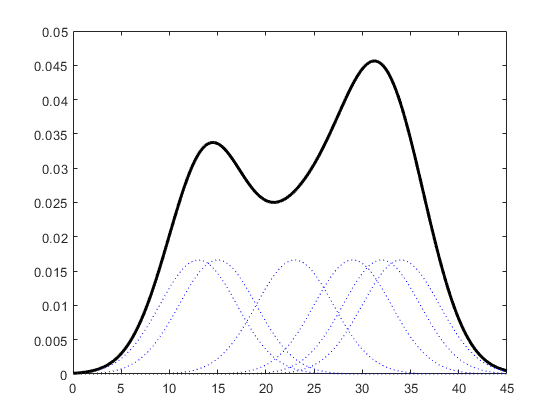
图3:生成KDE的过程呈现[3]
言归正传,对比训练集和测试集特征分布时,我们可以用seaborn.kdeplot()
[4]
进行绘图可视化,样例图和代码如下:
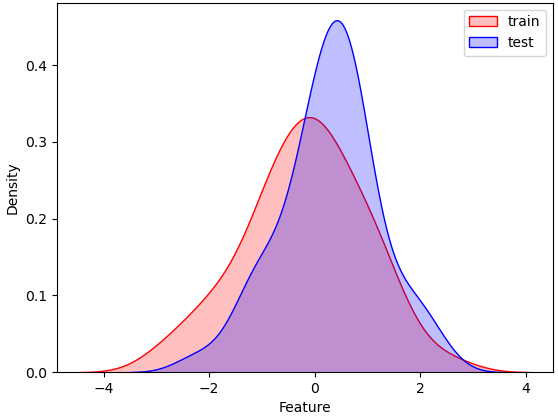
图4:不同数据集下的KDE对比
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 创建样例特征
train_mean, train_cov = [0, 2], [(1, .5), (.5, 1)]
test_mean, test_cov = [0, .5], [(1, 1), (.6, 1)]
train_feat, _ = np.random.multivariate_normal(train_mean, train_cov, size=50).T
test_feat, _ = np.random.multivariate_normal(test_mean, test_cov, size=50).T
# 绘KDE对比分布
sns.kdeplot(train_feat, shade = True, color='r', label = 'train')
sns.kdeplot(test_feat, shade = True, color='b', label = 'test')
plt.xlabel('Feature')
plt.legend()
plt.show()
2.KS检验
KDE是PDF来对比,而KS检验是基于CDF(累计分布函数Cumulative Distribution Function)来检验两个数据分布是否一致,它也是非参数检验方法(即不知道数据分布情况)。两条不同数据集下的CDF曲线,它们最大垂直差值可用作描述分布差异(见下图5中的D)。
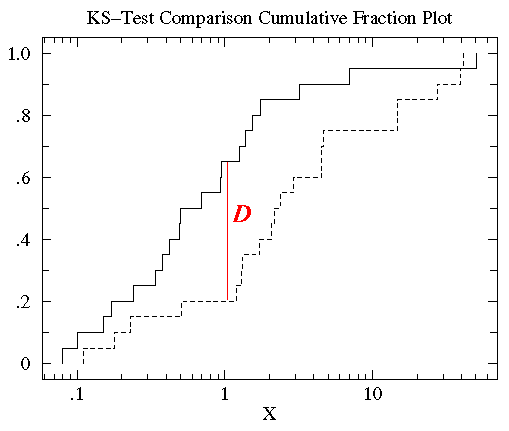
图5:不同数据集下的CDF对比[5]
调用scipy.stats.ks_2samp()
[6]
可轻松得到KS的统计值(最大垂直差)和假设检验下的p值:
from scipy import stats
stats.ks_2samp(train_feat, test_feat)
输出:KstestResult(statistic=0.2, pvalue=0.2719135601522248)
若KS统计值小且p值大,则我们可以接受KS检验的原假设H0,即两个数据分布一致。上面样例数据的统计值较低,p值大于10%但不是很高,因此反映分布略微不一致。注意: p值<0.01,强烈建议拒绝原假设H0,p值越大,越倾向于原假设H0成立。
3. 对抗验证
对抗验证是个很有趣的方法,它的思路是:我们构建一个分类器去分类训练集和测试集,如果模型能清楚分类,说明训练集和测试集存在明显区别(即分布不一致),否则反之。具体步骤如下:
训练集和测试集合并,同时新增标签‘Is_Test’去标记训练集样本为0,测试集样本为1。
构建分类器(例如LGB, XGB等)去训练混合后的数据集(可采用交叉验证的方式),拟合目标标签‘Is_Test’。
输出交叉验证中最优的AUC分数。AUC越大(越接近1),越说明训练集和测试集分布不一致。
相关代码可参考Qiuyan918在Kaggle的Microsoft Malware Prediction比赛中使用实例代码
[7]
。
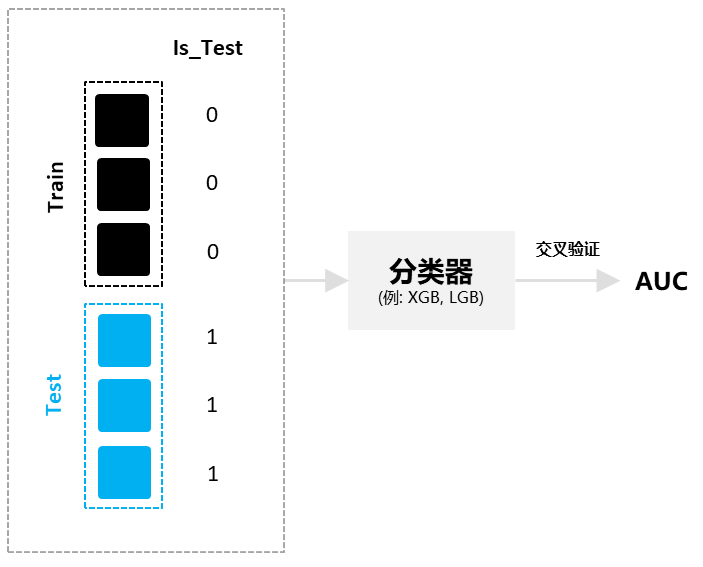
图6:对抗验证示意图
三、解决方法
1. 构造合适的验证集
当出现训练集和测试集分布不一致的,我们可以试图去构建跟测试集分布近似相同的验证集,保证线下验证跟线上测试分数不会抖动,这样我们就能得到稳定的benchmark。Qiuyan918在基于对抗验证的基础上,提出了三种构造合适的验证集的办法:
人工划分验证集
选择和测试集最相似的样本作为验证集
有权重的交叉验证
接下来,我将依次细讲上述方法。
(1) 人工划分验证集
以时间序列举例,因为一般测试集也会是未来数据,所以我们也要保证训练集是历史数据,而划分出的验证集是未来数据,不然会发生“时间穿越”的数据泄露问题,导致模型过拟合(例如用未来预测历史数据),这个时候就有两种验证划分方式可参考使用:
TimeSeriesSplit
:Sklearn提供的TimeSeriesSplit。
固定窗口滑动划分法
:固定时间窗口,不断在数据集上滑动,获得训练集和验证集。(个人推荐这种)
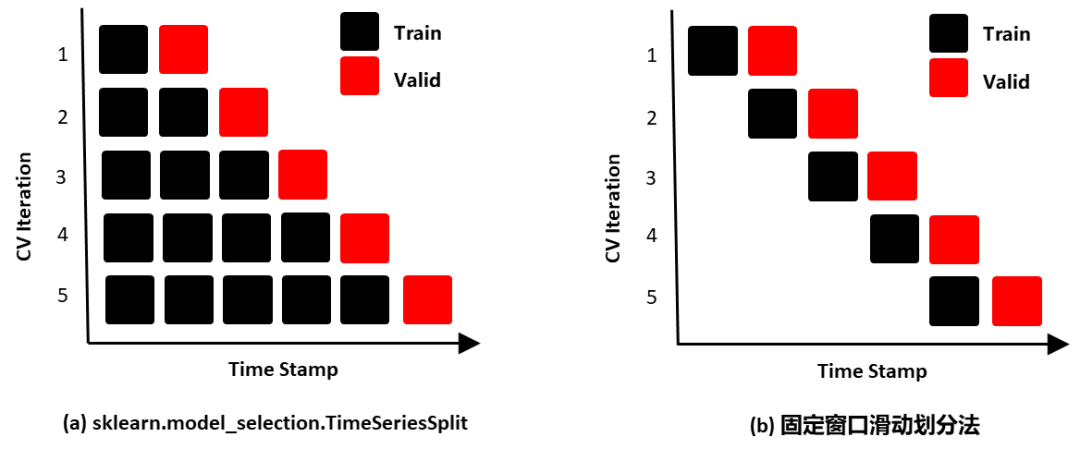
图7:划分时序数据的两种方法
除了时间序列数据,其它数据集的验证集划分都要遵循一个原则,即尽可能符合测试集的数据模式。像前面提到的2021“AI Earth”人工智能创新挑战赛中气象数据,由于测试集是真实气象数据,那么我们划分验证集时,更倾向于使用真实气象数据去评估线下模型的表现,而不是使用模拟气象数据作为验证集。
(2) 选择和测试集最相似的样本作为验证集
前面在讲对抗验证时,我们有训练出一个分类器去分类训练集和测试集,那么自然我们也能预测出训练集属于测试集的概率(即训练集在‘Is_Test’标签下预测概率),我们对训练集的预测概率进行降序排列,选择概率最大的前20%样本划分作为验证集,这样我们就能从原始数据集中,得到分布跟测试集接近的一个验证集了,具体样例代码详见
[7]
。之后,我们还可以评估划分好的验证集跟测试集的分布状况,评估方法:将验证集和测试集做对抗验证,若AUC越小,说明划分出的验证集和测试集分布越接近(即分类器越分不清验证集和测试集)。
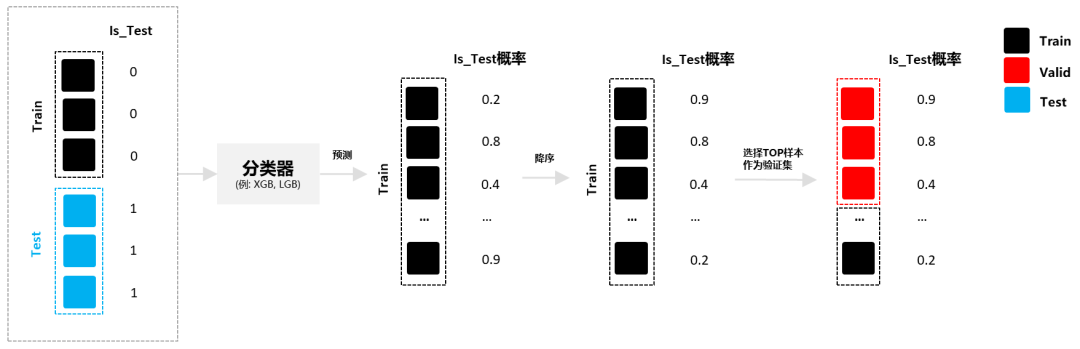
图8:选择和测试集最相似的样本作为验证集
(3) 有权重的交叉验证
如果我们对训练集里分布更偏向于测试集分布的样本更大的样本权重,给与测试集分布不太一致的训练集样本更小权重,也能一定程度上,帮助我们线下得到不易抖动的评估分数。在lightgbm库的Dataset初始化参数中,便提供了样本加权的参数weight,详见文档
[8]
。图7中,对抗验证的分类器预测训练集的Is_Test概率作为权重即可。
2. 删除分布不一致特征
如果我们遇到分布不一致且不太重要的特征,我们可以选择直接删去这种特征。该方法在各大比赛中十分常见。例如: 在2018年蚂蚁金服风险大脑-支付风险识别比赛中,亚军团队根据特征在训练集和测试集上的表现,去除分布差异较大的特征,如图9
[9]
。

图9:蚂蚁金服支付风险识别比赛中删除分布不一致特征[9]
虽然个人建议的是删除分布不一致但不太重要的特征,但有时避免不了碰到分布不一致但又很重要的特征,这时候其实就需要自行trade off特征分布和特征重要性的关系了,比如在第四届工业大数据创新竞赛-注塑成型工艺的虚拟量测中,第5名团队保留了sensor1_mean特征而删除了pack_press_2特征,尽管他们发现pack_press_2从实际生产角度和相关性角度都非常重要,可为了提升模型在测试集的泛化能力和分数,他们没用pack_press_2特征,如图10
[10]
。
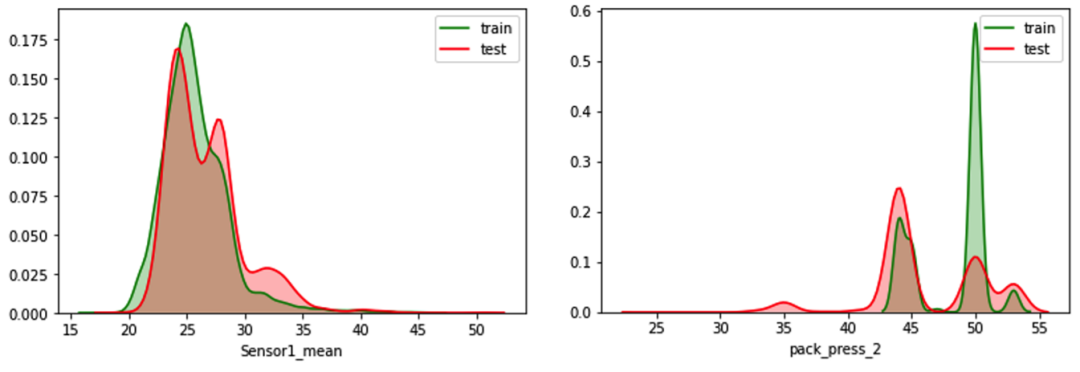
图10:注塑成型工艺的虚拟量测比赛中删除分布不一致特征[10]
3. 修正分布不一致的特征输入
当我们对比观察训练集和测试集的KDE时,若发现对数据做数学运算(例如加减乘除)或对增删样本就能修正分布,使得分布接近一致,那么我们可以试试。比如,蚂蚁金服比赛里,亚军团队发现"用户交易请求"特征在训练集中包含0、1和-1,而测试集只有1和0样本,因此他们对训练集删去了特征值为-1的样本,减少该特征在训练集和测试集的差异
[9]
。
4. 修正分布不一致的预测输出
除了对输入特征进行分布检查,我们也可以检查目标特征的分布,看是否存在可修正的空间。这种案例很少见,因为正常情况下,你看不到测试集的目标特征值。在“AI Earth”人工智能创新挑战赛里,我们有提到官方提供两类数据集作为训练集,分别是CMIP模拟数据和SODA真实数据,然后测试集又是SODA真实数据,其中前排参赛者YueTan就将CMIP和SODA的目标特征分布画在一起,然后发现SODA的值更集中,且整体分布偏右一些,所以对用CMIP训练得到的预测值加了一个小的常数,修正CMIP下模型的预测输出,使得它分布更偏向于SODA分布
[11]
。
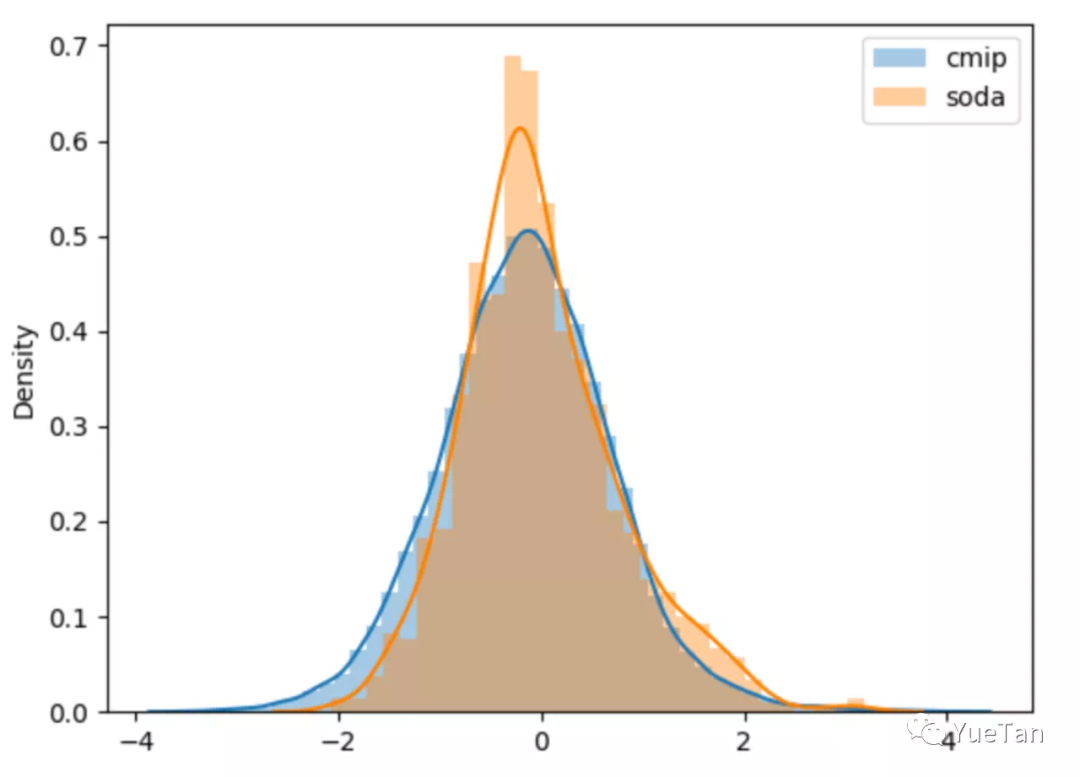
图11:气象数据SODA真实值和CMIP模拟值分布对比[11]
5. 伪标签
伪标签是半监督方法,利用未标注数据加入训练,我们先看看伪标签的思路,再讨论为什么它可能在一定程度上对分布不一致的数据集有帮助。伪标签最常见的方法是:
使用有标注的训练集训练模型M;
然后用模型M预测未标注的测试集;
选取测试集中预测置信度高的样本加入训练集中;
使用标注样本和高置信度的预测样本训练模型M';
预测测试集,输出预测结果。
TripleLift知乎主提供的入门版伪标签思路图如下所示,建议有兴趣的朋友阅读他原文
[12]
,他还提供了进阶版和创新版的伪标签技术,值得借鉴学习。
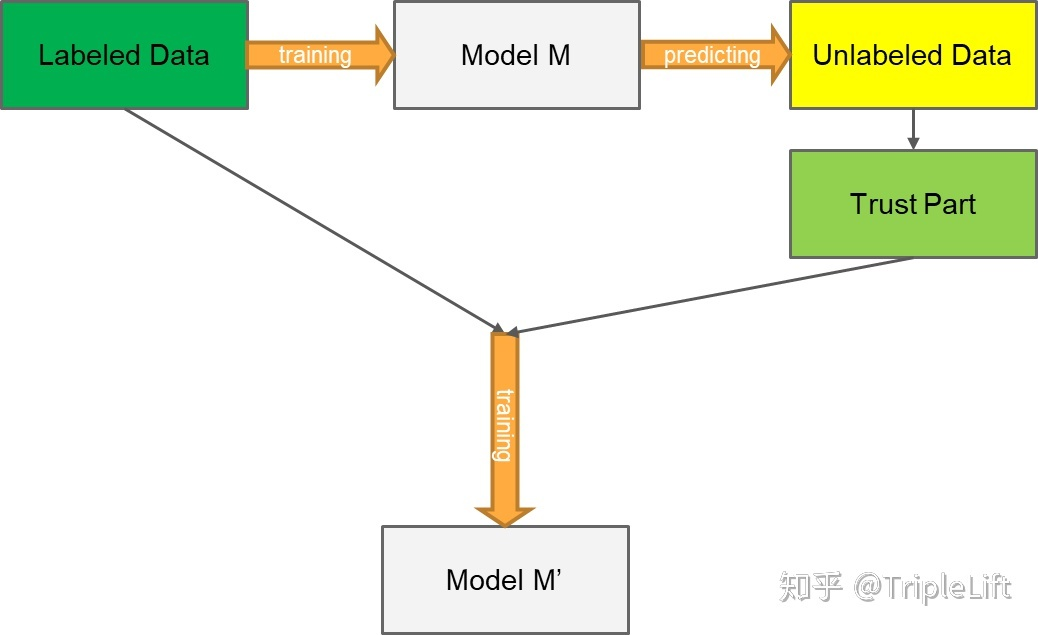
图12:入门版伪标签思路图
由上图我们可以看到,模型的训练引入了部分测试集的样本,这样相当于引入了部分测试集的分布。但需要注意:
(1) 相比于前面的方法,伪标签通常没有表现的很好,因为它引入的是置信度高的测试集样本,这些样本很可能跟训练集分布接近一致,所以才会预测概率高。因此引入的测试集分布也没有很不同,所以使用时常发生过拟合的情况。
(2) 注意引入的是高置信度样本,如果引入低置信度样本,会带来很大的噪声。另外,高置信度样本也不建议选取过多加入训练集,这也是为了避免模型过拟合。
(3) 伪标签适用于图像领域更多些,表格型比赛建议最后没办法再考虑该方法,因为本人使用过该方法,涨分的可能性都不是很高(也可能是我没用好)。
6. 其它
在写文章的时候,我查知乎发现有个问答《训练集和测试集的分布差距太大有好的处理方法吗?》下,知乎主纳米酱提到:"特征数值差距不大,特征相关性差距也不大,但是目标数值差距过大,这个好办,改变任务设置共同的中间目标,比如你说的目标值是否可以采取相对值,增长率,夏普等,而非绝对值"[13]。这种更改预测目标的方法,可能是发现更改预测目标后,新的预测目标值分布会变得相对一致,所以才考虑该方法的。但实际中,我没碰过这种情境,但还是提出来让大家参考学习下。
四、总结
通过这次整理,我对“训练集和测试集分布不一致”问题有了一个大致的知识框架,也学到了不少,特别是对抗验证这块,希望大家也有所获,欢迎交流讨论。
参考资料
[1]
Dataset Shift in Classification: Approaches and Problems - Francisco Herrera, PPT: http://iwann.ugr.es/2011/pdf/InvitedTalk-FHerrera-IWANN11.pdf
[2] 2021“AI Earth”人工智能创新挑战赛 - 阿里天池, 比赛: https://tianchi.aliyun.com/competition/entrance/531871/introduction
[3] Kernel Distribution - MathWorks, 文档: https://www.mathworks.com/help/stats/kernel-distribution.html
[4] seaborn.kdeplot(), 文档: http://seaborn.pydata.org/generated/seaborn.kdeplot.html
[5] KS-检验(Kolmogorov-Smirnov test)-- 检验数据是否符合某种分布 - Arkenstone, 博客: https://www.cnblogs.com/arkenstone/p/5496761.html
[6] scipy.stats.ks_2samp(), 文档: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ks_2samp.html
[7] Adversarial_Validation - Qiuyuan918, 代码: https://github.com/Qiuyan918/Adversarial_Validation_Case_Study/blob/master/Adversarial_Validation.ipynb
[8] lightgbm.Dataset(), 文档: https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Dataset.html#lightgbm.Dataset
[9] 蚂蚁金服ATEC风险大脑-支付风险识别--TOP2方案 - 吊车尾学院-E哥, 文章: https://zhuanlan.zhihu.com/p/57347243?from_voters_page=true
[10] 工业大数据之注塑成型虚拟量测Top5分享 - 公众号: Coggle数据科学
[11] 数据敏感度:以AI earth为栗子 - 公众号: YueTan
[12] 伪标签(Pseudo-Labelling)——锋利的匕首 - TripleLift, 文章: https://zhuanlan.zhihu.com/p/157325083
[13] 训练集和测试集的分布差距太大有好的处理方法吗?- 知乎, 文章: https://www.zhihu.com/question/265829982/answer/1770310534
干货学习,
点
赞
三连
↓