
手把手带你入门前端工程化——超详细教程
授权自@谭光志 链接:https://segmentfault.com/a/1190000037752931,也可点击阅读原文
本文将分成以下 7 个小节:
技术选型 统一规范 测试 部署 监控 性能优化 重构
部分小节提供了非常详细的实战教程,让大家动手实践。
另外我还写了一个前端工程化 demo 放在github上。这个 demo 包含了 js、css、git 验证,其中 js、css 验证需要安装 VSCode,具体教程在下文中会有提及。
技术选型
对于前端来说,技术选型挺简单的。就是做选择题,三大框架中选一个。个人认为可以依据以下两个特点来选:
选你或团队最熟的,保证在遇到棘手的问题时有人能填坑。 选市场占有率高的。换句话说,就是选好招人的。
第二点对于小公司来说,特别重要。本来小公司就不好招人,要是还选一个市场占有率不高的框架(例如 Angular),简历你都看不到几个...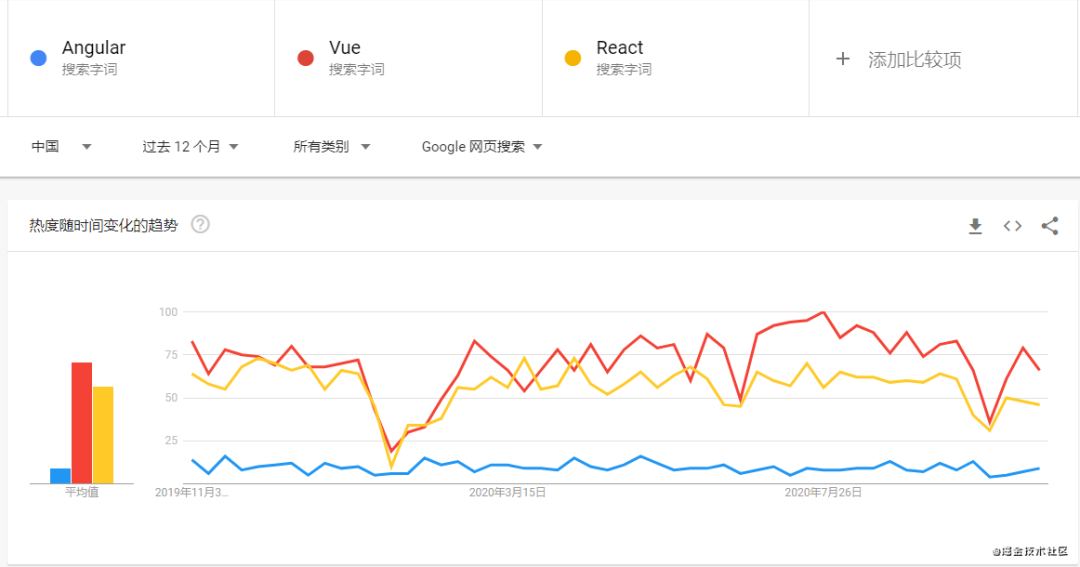
 UI 组件库更简单,github 上哪个 star 多就用哪个。star 多,说明用的人就多,很多坑别人都替你踩过了,省事。
UI 组件库更简单,github 上哪个 star 多就用哪个。star 多,说明用的人就多,很多坑别人都替你踩过了,省事。
统一规范
代码规范
先来看看统一代码规范的好处:
规范的代码可以促进团队合作 规范的代码可以降低维护成本 规范的代码有助于 code review(代码审查) 养成代码规范的习惯,有助于程序员自身的成长
当团队的成员都严格按照代码规范来写代码时,可以保证每个人的代码看起来都像是一个人写的,看别人的代码就像是在看自己的代码。更重要的是我们能够认识到规范的重要性,并坚持规范的开发习惯。
如何制订代码规范
建议找一份好的代码规范,在此基础上结合团队的需求作个性化修改。下面列举一些 star 较多的 js 代码规范:
airbnb (101k star 英文版),airbnb-中文版 standard (24.5k star) 中文版 百度前端编码规范 3.9k
css 代码规范也有不少,例如:
styleguide 2.3k spec 3.9k
如何检查代码规范
使用 eslint 可以检查代码符不符合团队制订的规范,下面来看一下如何配置 eslint 来检查代码。
下载依赖
// eslint-config-airbnb-base 使用 airbnb 代码规范
npm i -D babel-eslint eslint eslint-config-airbnb-base eslint-plugin-import
在 package.json的scripts加上这行代码"lint": "eslint --ext .js test/ src/ bin/"。然后执行npm run lint即可开始验证代码。
不过这样检查代码效率太低,每次都得手动检查。并且报错了还得手动修改代码。
为了改善以上缺点,我们可以使用 VSCode。使用它并加上适当的配置可以在每次保存代码的时候,自动验证代码并进行格式化,省去了动手的麻烦。
css 检查代码规范则使用stylelint插件。
由于篇幅有限,具体如何配置请看我的另一篇文章ESlint + stylelint + VSCode自动格式化代码(2020)。

git 规范
git 规范包括两点:分支管理规范、git commit 规范。
分支管理规范
一般项目分主分支(master)和其他分支。
当有团队成员要开发新功能或改 BUG 时,就从 master 分支开一个新的分支。例如项目要从客户端渲染改成服务端渲染,就开一个分支叫 ssr,开发完了再合并回 master 分支。
如果改一个 BUG,也可以从 master 分支开一个新分支,并用 BUG 号命名(不过我们小团队嫌麻烦,没这样做,除非有特别大的 BUG)。
git commit 规范
<type>():
大致分为三个部分(使用空行分割):
标题行: 必填, 描述主要修改类型和内容 主题内容: 描述为什么修改, 做了什么样的修改, 以及开发的思路等等 页脚注释: 可以写注释,BUG 号链接
type: commit 的类型
feat: 新功能、新特性 fix: 修改 bug perf: 更改代码,以提高性能 refactor: 代码重构(重构,在不影响代码内部行为、功能下的代码修改) docs: 文档修改 style: 代码格式修改, 注意不是 css 修改(例如分号修改) test: 测试用例新增、修改 build: 影响项目构建或依赖项修改 revert: 恢复上一次提交 ci: 持续集成相关文件修改 chore: 其他修改(不在上述类型中的修改) release: 发布新版本 workflow: 工作流相关文件修改
scope: commit 影响的范围, 比如: route, component, utils, build... subject: commit 的概述 body: commit 具体修改内容, 可以分为多行. footer: 一些备注, 通常是 BREAKING CHANGE 或修复的 bug 的链接.
示例
fix(修复BUG)
如果修复的这个BUG只影响当前修改的文件,可不加范围。如果影响的范围比较大,要加上范围描述。
例如这次 BUG 修复影响到全局,可以加个 global。如果影响的是某个目录或某个功能,可以加上该目录的路径,或者对应的功能名称。
// 示例1
fix(global):修复checkbox不能复选的问题
// 示例2 下面圆括号里的 common 为通用管理的名称
fix(common): 修复字体过小的BUG,将通用管理下所有页面的默认字体大小修改为 14px
// 示例3
fix: value.length -> values.length
feat(添加新功能或新页面)
feat: 添加网站主页静态页面
这是一个示例,假设对点检任务静态页面进行了一些描述。
这里是备注,可以是放BUG链接或者一些重要性的东西。
chore(其他修改)
chore 的中文翻译为日常事务、例行工作,顾名思义,即不在其他 commit 类型中的修改,都可以用 chore 表示。
chore: 将表格中的查看详情改为详情
其他类型的 commit 和上面三个示例差不多,就不说了。
验证 git commit 规范
验证 git commit 规范,主要通过 git 的pre-commit钩子函数来进行。当然,你还需要下载一个辅助工具来帮助你进行验证。
下载辅助工具
npm i -D husky
在package.json加上下面的代码
"husky": {
"hooks": {
"pre-commit": "npm run lint",
"commit-msg": "node script/verify-commit.js",
"pre-push": "npm test"
}
}
然后在你项目根目录下新建一个文件夹script,并在下面新建一个文件verify-commit.js,输入以下代码:
const msgPath = process.env.HUSKY_GIT_PARAMS
const msg = require('fs')
.readFileSync(msgPath, 'utf-8')
.trim()
const commitRE = /^(feat|fix|docs|style|refactor|perf|test|workflow|build|ci|chore|release|workflow)(\(.+\))?: .{1,50}/
if (!commitRE.test(msg)) {
console.log()
console.error(`
不合法的 commit 消息格式。
请查看 git commit 提交规范:https://github.com/woai3c/Front-end-articles/blob/master/git%20commit%20style.md
`)
process.exit(1)
}
现在来解释下各个钩子的含义:
"pre-commit": "npm run lint",在git commit前执行npm run lint检查代码格式。"commit-msg": "node script/verify-commit.js",在git commit时执行脚本verify-commit.js验证 commit 消息。如果不符合脚本中定义的格式,将会报错。"pre-push": "npm test",在你执行git push将代码推送到远程仓库前,执行npm test进行测试。如果测试失败,将不会执行这次推送。
项目规范
主要是项目文件的组织方式和命名方式。
用我们的 Vue 项目举个例子。
├─public
├─src
├─test
一个项目包含 public(公共资源,不会被 webpack 处理)、src(源码)、test(测试代码),其中 src 目录,又可以细分。
├─api (接口)
├─assets (静态资源)
├─components (公共组件)
├─styles (公共样式)
├─router (路由)
├─store (vuex 全局数据)
├─utils (工具函数)
└─views (页面)
文件名称如果过长则用 - 隔开。
UI 规范
UI 规范需要前端、UI、产品沟通,互相商量,最后制定下来,建议使用统一的 UI 组件库。
制定 UI 规范的好处:
统一页面 UI 标准,节省 UI 设计时间 提高前端开发效率
测试
测试是前端工程化建设必不可少的一部分,它的作用就是找出 bug,越早发现 bug,所需要付出的成本就越低。并且,它更重要的作用是在将来,而不是当下。
设想一下半年后,你的项目要加一个新功能。在加完新功能后,你不确定有没有影响到原有的功能,需要测试一下。由于时间过去太久,你对项目的代码已经不了解了。在这种情况下,如果没有写测试,你就得手动一遍一遍的去试。而如果写了测试,你只需要跑一遍测试代码就 OK 了,省时省力。
写测试还可以让你修改代码时没有心理负担,不用一直想着改这里有没有问题?会不会引起 BUG?而写了测试就没有这种担心了。
在前端用得最多的就是单元测试(主要是端到端测试我用得很少,不熟),这里着重讲解一下。
单元测试
单元测试就是对一个函数、一个组件、一个类做的测试,它针对的粒度比较小。它应该怎么写呢?
根据正确性写测试,即正确的输入应该有正常的结果。 根据异常写测试,即错误的输入应该是错误的结果。
对一个函数做测试
例如一个取绝对值的函数abs(),输入1,2,结果应该与输入相同;输入-1,-2,结果应该与输入相反。如果输入非数字,例如"abc",应该抛出一个类型错误。
对一个类做测试
假设有这样一个类:
class Math {
abs() {
}
sqrt() {
}
pow() {
}
...
}
单元测试,必须把这个类的所有方法都测一遍。
对一个组件做测试
组件测试比较难,因为很多组件都涉及了 DOM 操作。
例如一个上传图片组件,它有一个将图片转成 base64 码的方法,那要怎么测试呢?一般测试都是跑在 node 环境下的,而 node 环境没有 DOM 对象。
我们先来回顾一下上传图片的过程:
点击 ,选择图片上传。触发 input的change事件,获取file对象。用 FileReader将图片转换成 base64 码。
这个过程和下面的代码是一样的:
document.querySelector('input').onchange = function fileChangeHandler(e) {
const file = e.target.files[0]
const reader = new FileReader()
reader.onload = (res) => {
const fileResult = res.target.result
console.log(fileResult) // 输出 base64 码
}
reader.readAsDataURL(file)
}
上面的代码只是模拟,真实情况下应该是这样使用
document.querySelector('input').onchange = function fileChangeHandler(e) {
const file = e.target.files[0]
tobase64(file)
}
function tobase64(file) {
return new Promise((resolve, reject) => {
const reader = new FileReader()
reader.onload = (res) => {
const fileResult = res.target.result
resolve(fileResult) // 输出 base64 码
}
reader.readAsDataURL(file)
})
}
可以看到,上面代码出现了 window 的事件对象event、FileReader。也就是说,只要我们能够提供这两个对象,就可以在任何环境下运行它。所以我们可以在测试环境下加上这两个对象:
// 重写 File
window.File = function () {}
// 重写 FileReader
window.FileReader = function () {
this.readAsDataURL = function () {
this.onload
&& this.onload({
target: {
result: fileData,
},
})
}
}
然后测试可以这样写:
// 提前写好文件内容
const fileData = 'data:image/test'
// 提供一个假的 file 对象给 tobase64() 函数
function test() {
const file = new File()
const event = { target: { files: [file] } }
file.type = 'image/png'
file.name = 'test.png'
file.size = 1024
it('file content', (done) => {
tobase64(file).then(base64 => {
expect(base64).toEqual(fileData) // 'data:image/test'
done()
})
})
}
// 执行测试
test()
通过这种 hack 的方式,我们就实现了对涉及 DOM 操作的组件的测试。我的vue-upload-imgs库就是通过这种方式写的单元测试,有兴趣可以了解一下。
TDD 测试驱动开发
TDD 就是根据需求提前把测试代码写好,然后根据测试代码实现功能。
TDD 的初衷是好的,但如果你的需求经常变(你懂的),那就不是一件好事了。很有可能你天天都在改测试代码,业务代码反而没怎么动。
所以到现在为止,三年多的程序员生涯,我还没尝试过 TDD 开发。
虽然环境如此艰难,但有条件的情况下还是应该试一下 TDD 的。例如在你自己负责一个项目又不忙的时候,可以采用此方法编写测试用例。
测试框架推荐
我常用的测试框架是jest,好处是有中文文档,API 清晰明了,一看就知道是干什么用的。
部署
在没有学会自动部署前,我是这样部署项目的:
执行测试 npm run test。推送代码 git push。构建项目 npm run build。将打包好的文件放到静态服务器。
一次两次还行,如果天天都这样,就会把很多时间浪费在重复的操作上。所以我们要学会自动部署,彻底解放双手。自动部署(又叫持续部署 Continuous Deployment,英文缩写 CD)一般有两种触发方式:
轮询。 监听 webhook事件。
轮询
轮询,就是构建软件每隔一段时间自动执行打包、部署操作。
这种方式不太好,很有可能软件刚部署完我就改代码了。为了看到新的页面效果,不得不等到下一次构建开始。
另外还有一个副作用,假如我一天都没更改代码,构建软件还是会不停的执行打包、部署操作,白白的浪费资源。
所以现在的构建软件基本采用监听webhook事件的方式来进行部署。
监听webhook事件
webhook 钩子函数,就是在你的构建软件上进行设置,监听某一个事件(一般是监听push事件),当事件触发时,自动执行定义好的脚本。
例如Github Actions,就有这个功能。 对于新人来说,仅看我这一段讲解是不可能学会自动部署的。为此我特地写了一篇自动化部署教程,不需要你提前学习自动化部署的知识,只要照着指引做,就能实现前端项目自动化部署。
对于新人来说,仅看我这一段讲解是不可能学会自动部署的。为此我特地写了一篇自动化部署教程,不需要你提前学习自动化部署的知识,只要照着指引做,就能实现前端项目自动化部署。
前端项目自动化部署——超详细教程(Jenkins、Github Actions),教程已经奉上,各位大佬看完后要是觉得有用,不要忘了点赞,感激不尽。
监控
监控,又分性能监控和错误监控,它的作用是预警和追踪定位问题。
性能监控
性能监控一般利用window.performance来进行数据采集。
Performance 接口可以获取到当前页面中与性能相关的信息,它是 High Resolution Time API 的一部分,同时也融合了 Performance Timeline API、Navigation Timing API、 User Timing API 和 Resource Timing API。
这个 API 的属性timing,包含了页面加载各个阶段的起始及结束时间。
 为了方便大家理解
为了方便大家理解timing各个属性的意义,我在知乎找到一位网友对于timing写的简介(忘了姓名,后来找不到了,见谅),在此转载一下。
timing: {
// 同一个浏览器上一个页面卸载(unload)结束时的时间戳。如果没有上一个页面,这个值会和fetchStart相同。
navigationStart: 1543806782096,
// 上一个页面unload事件抛出时的时间戳。如果没有上一个页面,这个值会返回0。
unloadEventStart: 1543806782523,
// 和 unloadEventStart 相对应,unload事件处理完成时的时间戳。如果没有上一个页面,这个值会返回0。
unloadEventEnd: 1543806782523,
// 第一个HTTP重定向开始时的时间戳。如果没有重定向,或者重定向中的一个不同源,这个值会返回0。
redirectStart: 0,
// 最后一个HTTP重定向完成时(也就是说是HTTP响应的最后一个比特直接被收到的时间)的时间戳。
// 如果没有重定向,或者重定向中的一个不同源,这个值会返回0.
redirectEnd: 0,
// 浏览器准备好使用HTTP请求来获取(fetch)文档的时间戳。这个时间点会在检查任何应用缓存之前。
fetchStart: 1543806782096,
// DNS 域名查询开始的UNIX时间戳。
//如果使用了持续连接(persistent connection),或者这个信息存储到了缓存或者本地资源上,这个值将和fetchStart一致。
domainLookupStart: 1543806782096,
// DNS 域名查询完成的时间.
//如果使用了本地缓存(即无 DNS 查询)或持久连接,则与 fetchStart 值相等
domainLookupEnd: 1543806782096,
// HTTP(TCP) 域名查询结束的时间戳。
//如果使用了持续连接(persistent connection),或者这个信息存储到了缓存或者本地资源上,这个值将和 fetchStart一致。
connectStart: 1543806782099,
// HTTP(TCP) 返回浏览器与服务器之间的连接建立时的时间戳。
// 如果建立的是持久连接,则返回值等同于fetchStart属性的值。连接建立指的是所有握手和认证过程全部结束。
connectEnd: 1543806782227,
// HTTPS 返回浏览器与服务器开始安全链接的握手时的时间戳。如果当前网页不要求安全连接,则返回0。
secureConnectionStart: 1543806782162,
// 返回浏览器向服务器发出HTTP请求时(或开始读取本地缓存时)的时间戳。
requestStart: 1543806782241,
// 返回浏览器从服务器收到(或从本地缓存读取)第一个字节时的时间戳。
//如果传输层在开始请求之后失败并且连接被重开,该属性将会被数制成新的请求的相对应的发起时间。
responseStart: 1543806782516,
// 返回浏览器从服务器收到(或从本地缓存读取,或从本地资源读取)最后一个字节时
//(如果在此之前HTTP连接已经关闭,则返回关闭时)的时间戳。
responseEnd: 1543806782537,
// 当前网页DOM结构开始解析时(即Document.readyState属性变为“loading”、相应的 readystatechange事件触发时)的时间戳。
domLoading: 1543806782573,
// 当前网页DOM结构结束解析、开始加载内嵌资源时(即Document.readyState属性变为“interactive”、相应的readystatechange事件触发时)的时间戳。
domInteractive: 1543806783203,
// 当解析器发送DOMContentLoaded 事件,即所有需要被执行的脚本已经被解析时的时间戳。
domContentLoadedEventStart: 1543806783203,
// 当所有需要立即执行的脚本已经被执行(不论执行顺序)时的时间戳。
domContentLoadedEventEnd: 1543806783216,
// 当前文档解析完成,即Document.readyState 变为 'complete'且相对应的readystatechange 被触发时的时间戳
domComplete: 1543806783796,
// load事件被发送时的时间戳。如果这个事件还未被发送,它的值将会是0。
loadEventStart: 1543806783796,
// 当load事件结束,即加载事件完成时的时间戳。如果这个事件还未被发送,或者尚未完成,它的值将会是0.
loadEventEnd: 1543806783802
}
通过以上数据,我们可以得到几个有用的时间
// 重定向耗时
redirect: timing.redirectEnd - timing.redirectStart,
// DOM 渲染耗时
dom: timing.domComplete - timing.domLoading,
// 页面加载耗时
load: timing.loadEventEnd - timing.navigationStart,
// 页面卸载耗时
unload: timing.unloadEventEnd - timing.unloadEventStart,
// 请求耗时
request: timing.responseEnd - timing.requestStart,
// 获取性能信息时当前时间
time: new Date().getTime(),
还有一个比较重要的时间就是白屏时间,它指从输入网址,到页面开始显示内容的时间。
将以下脚本放在前面就能获取白屏时间。
通过这几个时间,就可以得知页面首屏加载性能如何了。
另外,通过window.performance.getEntriesByType('resource')这个方法,我们还可以获取相关资源(js、css、img...)的加载时间,它会返回页面当前所加载的所有资源。
它一般包括以下几个类型
sciprt link img css fetch other xmlhttprequest
我们只需用到以下几个信息
// 资源的名称
name: item.name,
// 资源加载耗时
duration: item.duration.toFixed(2),
// 资源大小
size: item.transferSize,
// 资源所用协议
protocol: item.nextHopProtocol,
现在,写几行代码来收集这些数据。
// 收集性能信息
const getPerformance = () => {
if (!window.performance) return
const timing = window.performance.timing
const performance = {
// 重定向耗时
redirect: timing.redirectEnd - timing.redirectStart,
// 白屏时间
whiteScreen: whiteScreen,
// DOM 渲染耗时
dom: timing.domComplete - timing.domLoading,
// 页面加载耗时
load: timing.loadEventEnd - timing.navigationStart,
// 页面卸载耗时
unload: timing.unloadEventEnd - timing.unloadEventStart,
// 请求耗时
request: timing.responseEnd - timing.requestStart,
// 获取性能信息时当前时间
time: new Date().getTime(),
}
return performance
}
// 获取资源信息
const getResources = () => {
if (!window.performance) return
const data = window.performance.getEntriesByType('resource')
const resource = {
xmlhttprequest: [],
css: [],
other: [],
script: [],
img: [],
link: [],
fetch: [],
// 获取资源信息时当前时间
time: new Date().getTime(),
}
data.forEach(item => {
const arry = resource[item.initiatorType]
arry && arry.push({
// 资源的名称
name: item.name,
// 资源加载耗时
duration: item.duration.toFixed(2),
// 资源大小
size: item.transferSize,
// 资源所用协议
protocol: item.nextHopProtocol,
})
})
return resource
}
小结
通过对性能及资源信息的解读,我们可以判断出页面加载慢有以下几个原因:
资源过多 网速过慢 DOM元素过多
除了用户网速过慢,我们没办法之外,其他两个原因都是有办法解决的,性能优化将在下一节《性能优化》中会讲到。
错误监控
现在能捕捉的错误有三种。
资源加载错误,通过 addEventListener('error', callback, true)在捕获阶段捕捉资源加载失败错误。js 执行错误,通过 window.onerror捕捉 js 错误。promise 错误,通过 addEventListener('unhandledrejection', callback)捕捉 promise 错误,但是没有发生错误的行数,列数等信息,只能手动抛出相关错误信息。
我们可以建一个错误数组变量errors在错误发生时,将错误的相关信息添加到数组,然后在某个阶段统一上报,具体如何操作请看代码
// 捕获资源加载失败错误 js css img...
addEventListener('error', e => {
const target = e.target
if (target != window) {
monitor.errors.push({
type: target.localName,
url: target.src || target.href,
msg: (target.src || target.href) + ' is load error',
// 错误发生的时间
time: new Date().getTime(),
})
}
}, true)
// 监听 js 错误
window.onerror = function(msg, url, row, col, error) {
monitor.errors.push({
type: 'javascript',
row: row,
col: col,
msg: error && error.stack? error.stack : msg,
url: url,
// 错误发生的时间
time: new Date().getTime(),
})
}
// 监听 promise 错误 缺点是获取不到行数数据
addEventListener('unhandledrejection', e => {
monitor.errors.push({
type: 'promise',
msg: (e.reason && e.reason.msg) || e.reason || '',
// 错误发生的时间
time: new Date().getTime(),
})
})
小结
通过错误收集,可以了解到网站错误发生的类型及数量,从而可以做相应的调整,以减少错误发生。
完整代码和 DEMO 请看我另一篇文章前端性能和错误监控的末尾,大家可以复制代码(HTML文件)在本地测试一下。
数据上报
性能数据上报
性能数据可以在页面加载完之后上报,尽量不要对页面性能造成影响。
window.onload = () => {
// 在浏览器空闲时间获取性能及资源信息
// https://developer.mozilla.org/zh-CN/docs/Web/API/Window/requestIdleCallback
if (window.requestIdleCallback) {
window.requestIdleCallback(() => {
monitor.performance = getPerformance()
monitor.resources = getResources()
})
} else {
setTimeout(() => {
monitor.performance = getPerformance()
monitor.resources = getResources()
}, 0)
}
}
当然,你也可以设一个定时器,循环上报。不过每次上报最好做一下对比去重再上报,避免同样的数据重复上报。
错误数据上报
我在DEMO里提供的代码,是用一个errors数组收集所有的错误,再在某一阶段统一上报(延时上报)。
其实,也可以改成在错误发生时上报(即时上报)。这样可以避免在收集完错误延时上报还没触发,用户却已经关掉网页导致错误数据丢失的问题。
// 监听 js 错误
window.onerror = function(msg, url, row, col, error) {
const data = {
type: 'javascript',
row: row,
col: col,
msg: error && error.stack? error.stack : msg,
url: url,
// 错误发生的时间
time: new Date().getTime(),
}
// 即时上报
axios.post({ url: 'xxx', data, })
}
SPA
window.performanceAPI 是有缺点的,在 SPA 切换路由时,window.performance.timing的数据不会更新。
所以我们需要另想办法来统计切换路由到加载完成的时间。
拿 Vue 举例,一个可行的办法就是切换路由时,在路由的全局前置守卫beforeEach里获取开始时间,在组件的mounted钩子里执行vm.$nextTick函数来获取组件的渲染完毕时间。
router.beforeEach((to, from, next) => {
store.commit('setPageLoadedStartTime', new Date())
})
mounted() {
this.$nextTick(() => {
this.$store.commit('setPageLoadedTime', new Date() - this.$store.state.pageLoadedStartTime)
})
}
除了性能和错误监控,其实我们还可以做得更多。
用户信息收集
navigator
使用window.navigator可以收集到用户的设备信息,操作系统,浏览器信息...
UV(Unique visitor)
是指通过互联网访问、浏览这个网页的自然人。访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只被计算一次。一天内同个访客多次访问仅计算一个UV。
在用户访问网站时,可以生成一个随机字符串+时间日期,保存在本地。在网页发生请求时(如果超过当天24小时,则重新生成),把这些参数传到后端,后端利用这些信息生成 UV 统计报告。
PV(Page View)
即页面浏览量或点击量,用户每1次对网站中的每个网页访问均被记录1个PV。用户对同一页面的多次访问,访问量累计,用以衡量网站用户访问的网页数量。
页面停留时间
传统网站
用户在进入 A 页面时,通过后台请求把用户进入页面的时间捎上。过了 10 分钟,用户进入 B 页面,这时后台可以通过接口捎带的参数可以判断出用户在 A 页面停留了 10 分钟。
SPA
可以利用 router 来获取用户停留时间,拿 Vue 举例,通过router.beforeEach``destroyed这两个钩子函数来获取用户停留该路由组件的时间。
浏览深度
通过document.documentElement.scrollTop属性以及屏幕高度,可以判断用户是否浏览完网站内容。
页面跳转来源
通过document.referrer属性,可以知道用户是从哪个网站跳转而来。
小结
通过分析用户数据,我们可以了解到用户的浏览习惯、爱好等等信息,想想真是恐怖,毫无隐私可言。
前端监控部署教程
前面说的都是监控原理,但要实现还是得自己动手写代码。为了避免麻烦,我们可以用现有的工具 sentry 去做这件事。sentry 是一个用 python 写的性能和错误监控工具,你可以使用 sentry 提供的服务(免费功能少),也可以自己部署服务。现在来看一下如何使用 sentry 提供的服务实现监控。
注册账号
打开https://sentry.io/signup/网站,进行注册。
 选择项目,我选的 Vue。
选择项目,我选的 Vue。
安装 sentry 依赖
选完项目,下面会有具体的 sentry 依赖安装指南。 根据提示,在你的 Vue 项目执行这段代码
根据提示,在你的 Vue 项目执行这段代码npm install --save @sentry/browser @sentry/integrations @sentry/tracing,安装 sentry 所需的依赖。再将下面的代码拷到你的main.js,放在new Vue()之前。
import * as Sentry from "@sentry/browser";
import { Vue as VueIntegration } from "@sentry/integrations";
import { Integrations } from "@sentry/tracing";
Sentry.init({
dsn: "xxxxx", // 这里是你的 dsn 地址,注册完就有
integrations: [
new VueIntegration({
Vue,
tracing: true,
}),
new Integrations.BrowserTracing(),
],
// We recommend adjusting this value in production, or using tracesSampler
// for finer control
tracesSampleRate: 1.0,
});
然后点击第一步中的skip this onboarding,进入控制台页面。如果忘了自己的 DSN,请点击左边的菜单栏选择Settings->Projects-> 点击自己的项目 ->Client Keys(DSN)。
创建第一个错误
在你的 Vue 项目执行一个打印语句console.log(b)。这时点开 sentry 主页的 issues 一项,可以发现有一个报错信息b is not defined: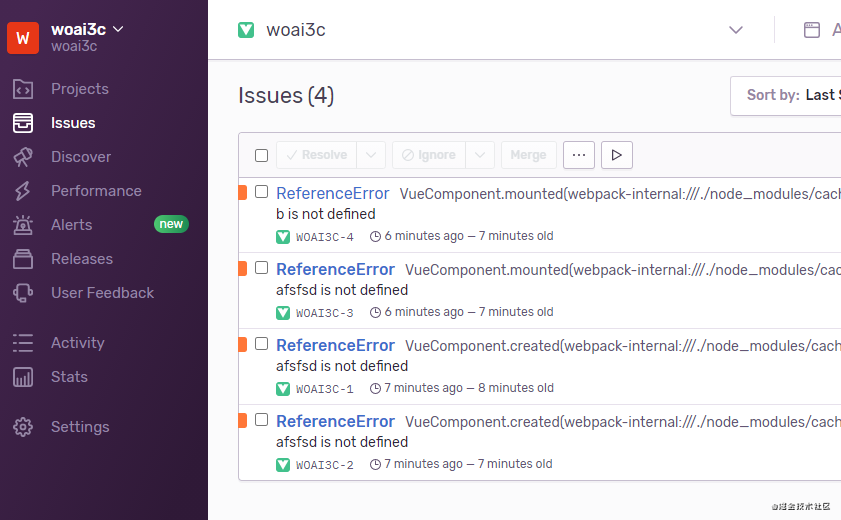 这个报错信息包含了错误的具体信息,还有你的 IP、浏览器信息等等。但奇怪的是,我们的浏览器控制台并没有输出报错信息。这是因为被 sentry 屏蔽了,所以我们需要加上一个选项
这个报错信息包含了错误的具体信息,还有你的 IP、浏览器信息等等。但奇怪的是,我们的浏览器控制台并没有输出报错信息。这是因为被 sentry 屏蔽了,所以我们需要加上一个选项logErrors: true。 然后再查看页面,发现控制台也有报错信息了:
然后再查看页面,发现控制台也有报错信息了: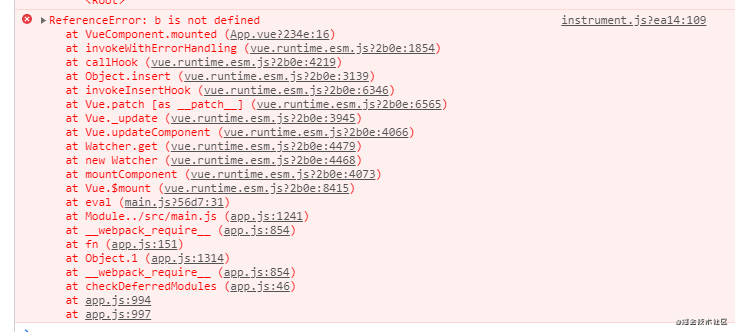
上传 sourcemap
一般打包后的代码都是经过压缩的,如果没有 sourcemap,即使有报错信息,你也很难根据提示找到对应的源码在哪。下面来看一下如何上传 sourcemap。首先创建 auth token。

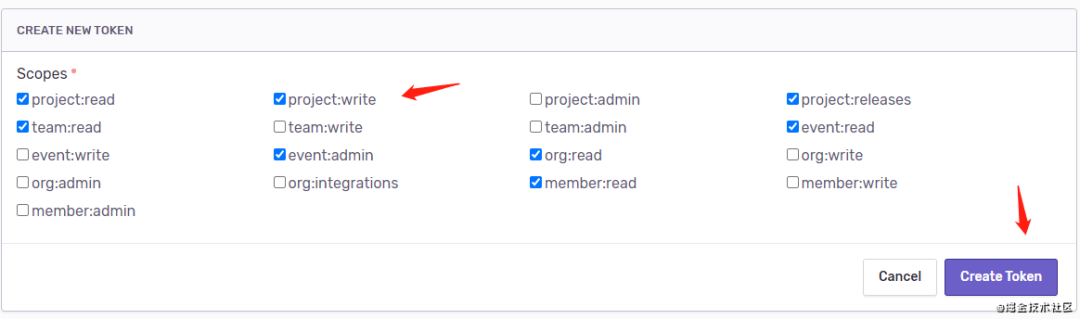
 这个生成的 token 一会要用到。安装
这个生成的 token 一会要用到。安装sentry-cli和@sentry/webpack-plugin:
npm install sentry-cli-binary -g
npm install --save-dev @sentry/webpack-plugin
安装完上面两个插件后,在项目根目录创建一个.sentryclirc文件(不要忘了在.gitignore把这个文件添加上,以免暴露 token),内容如下:
[auth]
token=xxx
[defaults]
url=https://sentry.io/
org=woai3c
project=woai3c
把 xxx 替换成刚才生成的 token。org是你的组织名称。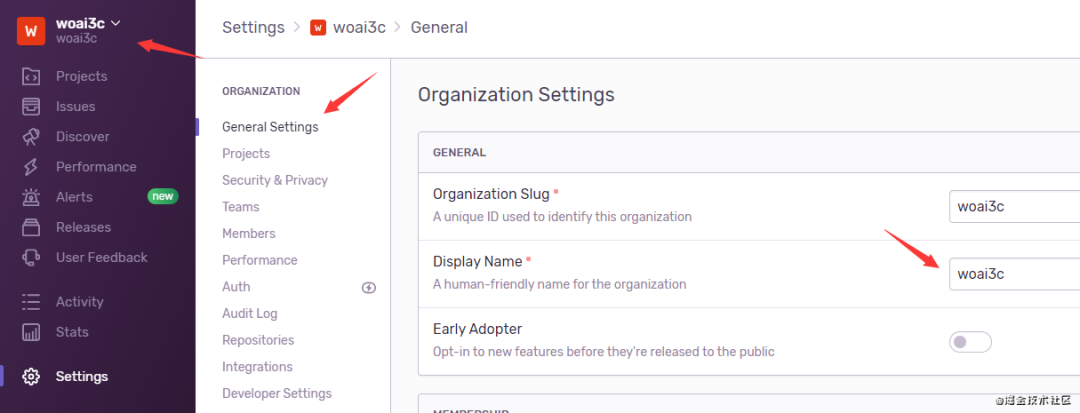
project是你的项目名称,根据下面的提示可以找到。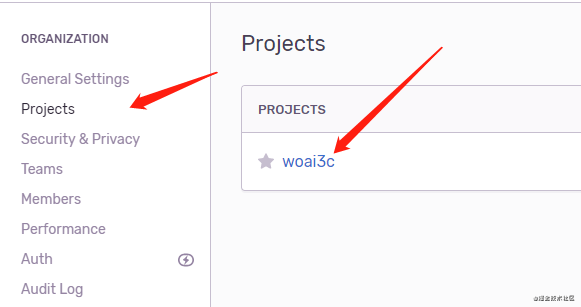
 在项目下新建
在项目下新建vue.config.js文件,把下面的内容填进去:
const SentryWebpackPlugin = require('@sentry/webpack-plugin')
const config = {
configureWebpack: {
plugins: [
new SentryWebpackPlugin({
include: './dist', // 打包后的目录
ignore: ['node_modules', 'vue.config.js', 'babel.config.js'],
}),
],
},
}
// 只在生产环境下上传 sourcemap
module.exports = process.env.NODE_ENV == 'production'? config : {}
填完以后,执行npm run build,就可以看到sourcemap的上传结果了。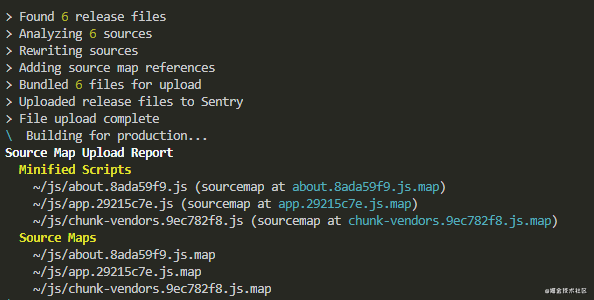 我们再来看一下没上传 sourcemap 和上传之后的报错信息对比。未上传 sourcemap
我们再来看一下没上传 sourcemap 和上传之后的报错信息对比。未上传 sourcemap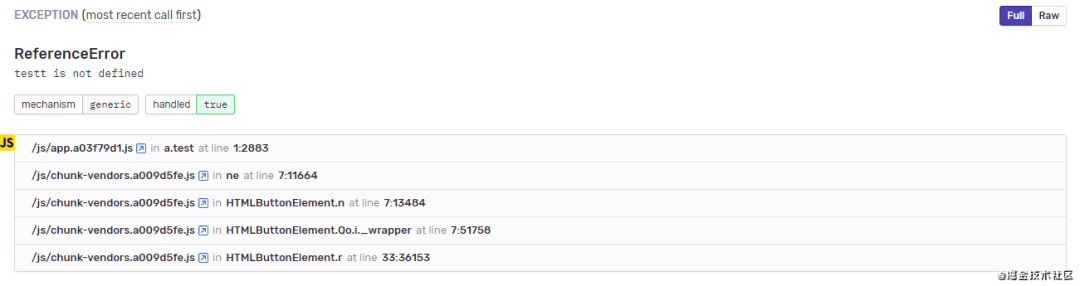
 已上传 sourcemap
已上传 sourcemap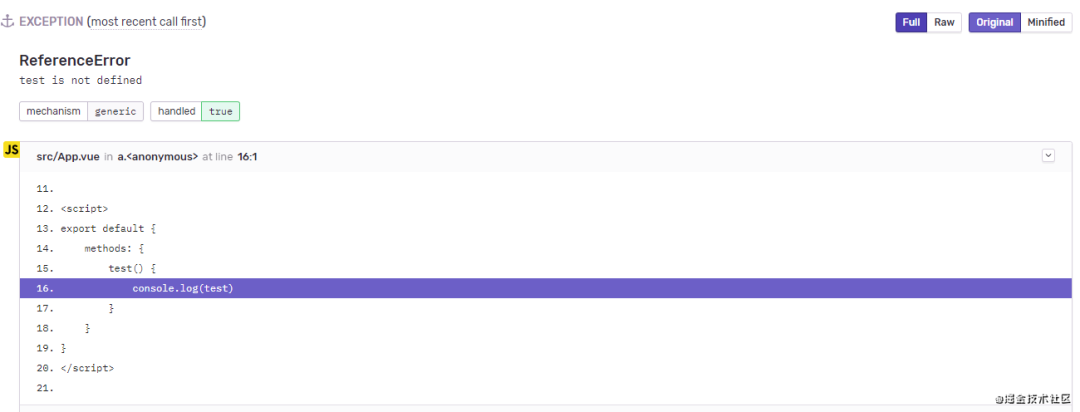
 可以看到,上传 sourcemap 后的报错信息更加准确。
可以看到,上传 sourcemap 后的报错信息更加准确。
切换中文环境和时区

 选完刷新即可。
选完刷新即可。
性能监控
 打开 performance 选项,就能看到你每个项目的运行情况。具体的参数解释请看文档Performance Monitoring。
打开 performance 选项,就能看到你每个项目的运行情况。具体的参数解释请看文档Performance Monitoring。
性能优化
性能优化主要分为两类:
加载时优化 运行时优化
例如压缩文件、使用 CDN 就属于加载时优化;减少 DOM 操作,使用事件委托属于运行时优化。在解决问题之前,必须先找出问题,否则无从下手。所以在做性能优化之前,最好先调查一下网站的加载性能和运行性能。
手动检查
检查加载性能
一个网站加载性能如何主要看白屏时间和首屏时间。
白屏时间:指从输入网址,到页面开始显示内容的时间。 首屏时间:指从输入网址,到页面完全渲染的时间。
将以下脚本放在前面就能获取白屏时间。
首屏时间比较复杂,得考虑有图片和没有图片的情况。如果没有图片,则在window.onload事件里执行new Date() - performance.timing.navigationStart即可获取首屏时间。如果有图片,则要在最后一个在首屏渲染的图片的onload事件里执行new Date() - performance.timing.navigationStart获取首屏时间,实施起来比较复杂,在这里限于篇幅就不说了。
检查运行性能
配合 chrome 的开发者工具,我们可以查看网站在运行时的性能。
打开网站,按 F12 选择 performance,点击左上角的灰色圆点,变成红色就代表开始记录了。这时可以模仿用户使用网站,在使用完毕后,点击 stop,然后你就能看到网站运行期间的性能报告。如果有红色的块,代表有掉帧的情况;如果是绿色,则代表 FPS 很好。
另外,在 performance 标签下,按 ESC 会弹出来一个小框。点击小框左边的三个点,把 rendering 勾出来。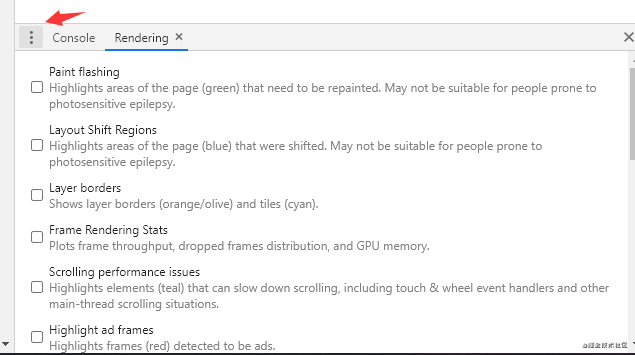

这两个选项,第一个是高亮重绘区域,另一个是显示帧渲染信息。把这两个选项勾上,然后浏览网页,可以实时的看到你网页渲染变化。
利用工具检查
监控工具
可以部署一个前端监控系统来监控网站性能,上一节中讲到的 sentry 就属于这一类。
chrome 工具 Lighthouse
如果你安装了 Chrome 52+ 版本,请按 F12 打开开发者工具。
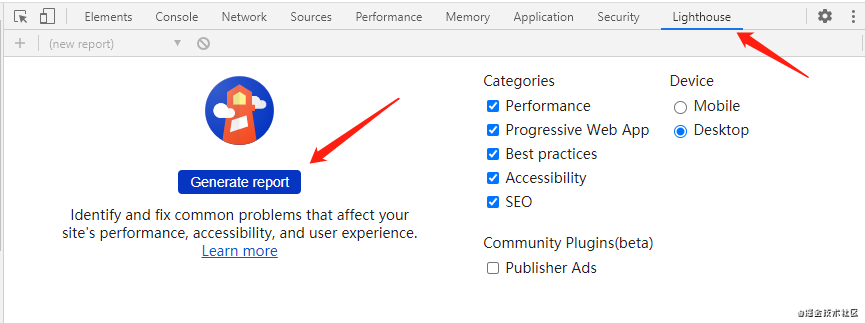 它不仅会对你网站的性能打分,还会对 SEO 打分。
它不仅会对你网站的性能打分,还会对 SEO 打分。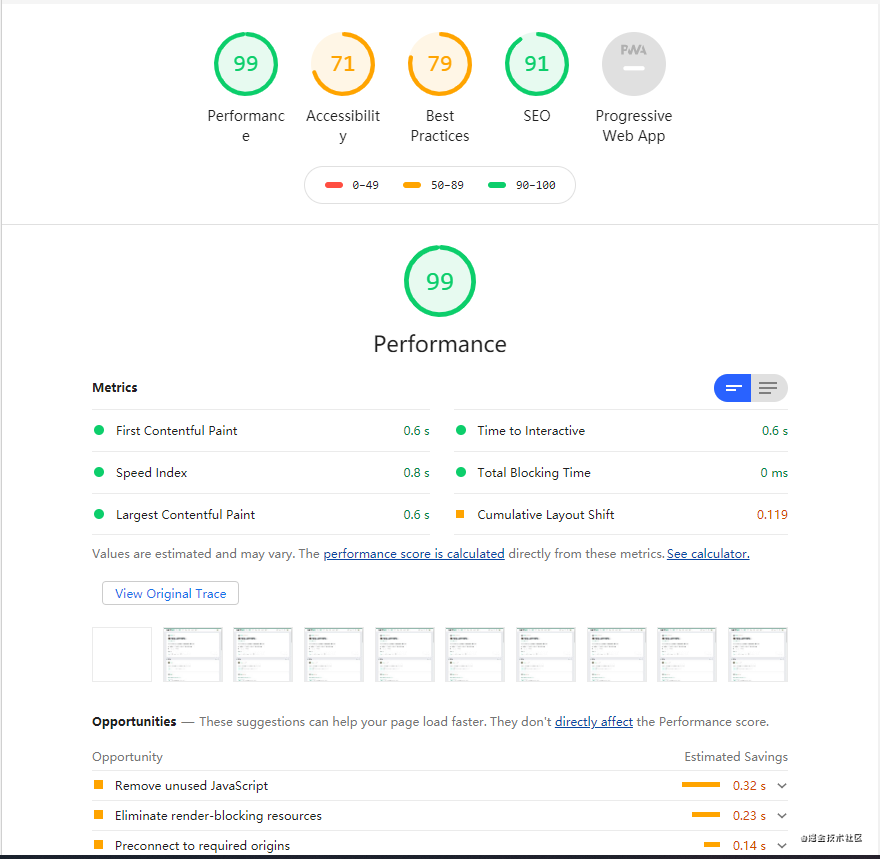 使用 Lighthouse 审查网络应用
使用 Lighthouse 审查网络应用
如何做性能优化
网上关于性能优化的文章和书籍多不胜数,但有很多优化规则已经过时了。所以我写了一篇性能优化文章前端性能优化 24 条建议(2020),分析总结出了 24 条性能优化建议,强烈推荐。
重构
《重构2》一书中对重构进行了定义:
所谓重构(refactoring)是这样一个过程:在不改变代码外在行为的前提下,对代码做出修改,以改进程序的内部结构。重构是一种经千锤百炼形成的有条不紊的程序整理方法,可以最大限度地减小整理过程中引入错误的概率。本质上说,重构就是在代码写好之后改进它的设计。
重构和性能优化有相同点,也有不同点。
相同的地方是它们都在不改变程序功能的情况下修改代码;不同的地方是重构为了让代码变得更加易读、理解,性能优化则是为了让程序运行得更快。
重构可以一边写代码一边重构,也可以在程序写完后,拿出一段时间专门去做重构。没有说哪个方式更好,视个人情况而定。
如果你专门拿一段时间来做重构,建议你在重构一段代码后,立即进行测试。这样可以避免修改代码太多,在出错时找不到错误点。
重构的原则
事不过三,三则重构。即不能重复写同样的代码,在这种情况下要去重构。 如果一段代码让人很难看懂,那就该考虑重构了。 如果已经理解了代码,但是非常繁琐或者不够好,也可以重构。 过长的函数,需要重构。 一个函数最好对应一个功能,如果一个函数被塞入多个功能,那就要对它进行重构了。
重构手法
在《重构2》这本书中,介绍了多达上百个重构手法。但我觉得有两个是比较常用的:
提取重复代码,封装成函数 拆分太长或功能太多的函数
提取重复代码,封装成函数
假设有一个查询数据的接口/getUserData?age=17&city=beijing。现在需要做的是把用户数据:{ age: 17, city: 'beijing' }转成 URL 参数的形式:
let result = ''
const keys = Object.keys(data) // { age: 17, city: 'beijing' }
keys.forEach(key => {
result += '&' + key + '=' + data[key]
})
result.substr(1) // age=17&city=beijing
如果只有这一个接口需要转换,不封装成函数是没问题的。但如果有多个接口都有这种需求,那就得把它封装成函数了:
function JSON2Params(data) {
let result = ''
const keys = Object.keys(data)
keys.forEach(key => {
result += '&' + key + '=' + data[key]
})
return result.substr(1)
}
拆分太长或功能太多的函数
假设现在有一个注册功能,用伪代码表示:
function register(data) {
// 1. 验证用户数据是否合法
/**
* 验证账号
* 验证密码
* 验证短信验证码
* 验证身份证
* 验证邮箱
*/
// 2. 如果用户上传了头像,则将用户头像转成 base64 码保存
/**
* 新建 FileReader 对象
* 将图片转换成 base64 码
*/
// 3. 调用注册接口
// ...
}
这个函数包含了三个功能,验证、转换、注册。其中验证和转换功能是可以提取出来单独封装成函数的:
function register(data) {
// 1. 验证用户数据是否合法
// verify()
// 2. 如果用户上传了头像,则将用户头像转成 base64 码保存
// tobase64()
// 3. 调用注册接口
// ...
}
如果你对重构有兴趣,强烈推荐你阅读《重构2》这本书。参考资料:
《重构2》
总结
写这篇文章主要是为了对我这一年多工作经验作总结,因为我基本上都在研究前端工程化以及如何提升团队的开发效率。希望这篇文章能帮助一些对前端工程化没有经验的新手,通过这篇文章入门前端工程化。
如果这篇文章对你有帮助,请点一下赞,感激不尽。
求职启事
本人具有三年+前端工作经验,32岁,高中学历,现寻求天津、北京地区的前端工作机会。下面是我掌握的一些技能:
熟练掌握 HTML、CSS、JavaScript。 熟练掌握 Vue 全家桶并研究过 Vue1.0 源码及 Vue3.0 部分源码。 使用 nodejs 写过脚本和个人博客,没有开发过企业应用。 学习计算机原理并实现一个简单的 cpu 和内存模块运行在模拟器上(github 项目地址)。 学习操作系统并做实验实现了一个简单的内核(github 项目地址)。 学习编译原理写过一个简单编译器(github 项目地址)。 对计算机网络应用层和传输层的知识比较了解。 数据结构与算法有学习过,还刷了 300+ 道 leetcode,但效果不是很好。
社交网站
Github 知乎
如果您觉得我的条件还可以,可以私信我或在评论区留言,谢谢。