
超详细教程!手把手带你使用Raft分布式共识性算法

导语 |从头理一遍Raft会给你带来新的体验与收获,让你从根本上理解Raft,理解它被提出的背景,在此背景下又是如何解决实际问题的,这才是从头实现一个Raft所带来的真正收益。本文聚焦在Raft算法的实现上,不对Raft本身做过多介绍,从领导者选举、日志同步、持久化和快照等几个层面进行展开讲解。
一、介绍
Raft目前是最著名的分布式共识性算法,被广泛的应用在etcd、k8s中。
根据Raft论文,可将Raft拆分为如下4个功能模块:
领导者选举
日志同步、心跳
持久化
日志压缩,快照
这4个模块彼此并不完全独立,如日志的同步情况左右着领导者选举,快照也影响着日志同步等等;为了前后的递进性,对于一些功能的实现,可能会出现改动和优化,比如日志同步实现后,在数据持久化部分又会对同步做一些优化,提高主、从节点日志冲突解决的性能。
二、领导者选举
Raft算法是目前使用最为广泛的分布式共识性算法,在数据共识性的问题上,Raft使用「强领导者」模型,即:
一个集群中有且只有一个领导者。
所有数据写请求,都必须由领导者处理,领导者接受后再同步给其它节点。
领导者是绝对的「土皇帝」,不断地向追随者发送号令(同步日志)。
因此,在一个使用Raft算法的集群中,「领导者选举」是集群的第一步。一个集群的节点个数往往是「奇数」,如 3、5 等,这样就避免了选举时会发生脑裂(出现了多个领导者)的情况。
(一)节点状态
在Raft集群中,一个节点会存在如下3种状态:
追随者(Follower),追随领导者,接收领导者日志,并实时同步。
协调者(Candidate),选举时会触发的状态,如追随者一定时间内未收到来自领导者的心跳包,追随者会自动切换为协调者,并开始选举操作,向集群中的其它节点发送投票请求,待收到半数以上的选票时(如3节点集群,需收到2票,含自己的1票),协调者升级成为领导者。
领导者(Leader),集群土皇帝,不断地向集群其它节点发号施令(心跳、日志同步),其它节点接到领导者日志请求后成为其追随者。
因此在具体谈到Raft算法实现之前,我们需要先来解决这三个状态。首先我们需要对节点这个概念进行抽象,如下:
// raft.gotype Raft struct {mu sync.Mutex // 锁peers []*labrpc.ClientEnd // 集群信息persister *Persister // 持久化me int // 当前节点 iddead int32 // 是否死亡,1 表示死亡,0 还活着state PeerState // 节点状态currentTerm int // 当前任期votedFor int // 给谁投过票leaderId int // 集群 leader idapplyCh chan ApplyMsg // apply message channel}
在这段代码中,Raft结构体是对Raft节点的一个抽象,每一个Raft实例可表示一个Raft节点,每一个节点会有集群元数据(peers),节点元数据(me、state、currentTerm等)等信息。在领导者选举部分,有3个重要的字段需要说明:
state:节点状态,当前节点处于领导者、还是追随者。
votedFor:投票记录,当前节点在当前任期内给「那个」节点投过票。
currentTerm:节点当前所在的任期。
「任期」是Raft算法中一个非常重要的概念,你可以将其理解为「逻辑时钟」,每一个节点在初始化时,状态为追随者,任期为0,当一定时间内未收到领导者日志后,会自动成为协调者,并给自己投票,且任期+1,如下面的becomeCandidate函数:
// state.gotype PeerState stringconst (Follower PeerState = "follower"Candidate PeerState = "candidate"Leader PeerState = "leader")func (rf *Raft) becomeLeader() {rf.state = Leaderrf.leaderId = rf.me}func (rf *Raft) becomeCandidate() {rf.state = Candidaterf.votedFor = rf.me // vote for merf.currentTerm += 1}func (rf *Raft) becomeFollower(term int) {rf.state = Followerrf.votedFor = -1rf.currentTerm = term}
在这里,我们定义了Follower、Candidate和Leader三种状态,一个节点可以在这三种状态中切换,如becomeLeader函数,会将当前节点切换为领导者状态,并且设置leaderId为自己。becomeCandidate函数上面也谈到了,节点成为协调者后会增加任期,并给自己投票;调用becomeFollower函数时,节点会切换为追随者状态,且重置votedFor字段,追随者更新任期后,重新拥有「选票权」,可以进行投票。
这里抛出2个问题:选举过程是如何产生的?任期在选举过程中发挥了什么作用了?下面我们来一一解答。
(二)选举
Raft集群节点初始化时,会在节点内部存储集群元数据(如 peers),节点需要通过集群元数据信息与其它节点进行沟通,而沟通的方式是RPC请求。
选举指的是,集群中的某一个节点,在成为协调者后,不满足于自己现在状态,迫切的想要成为领导者(土皇帝),虽然它给自己投了1票,但很显然1票是不够,它需要其它节点的选票才能成为领导者。
因此协调者会与其它节点进行沟通协商(RPC请求),当然它暂时不会沟通别的,只会向其它节点发送投票RPC请求(RequestVote RPC请求);因此选举的过程实则就是:追随者未收到日志同步(也可理解为心跳)转变成为协调者,给自己投票后迫切地想成为领导者,并通过RPC请求其它节点给自己投票。
翻译成代码,大致如下:
// raft.gofunc Make(peers []*labrpc.ClientEnd, me int,persister *Persister, applyCh chan ApplyMsg) *Raft {rf := &Raft{}rf.peers = peersrf.persister = persisterrf.me = merf.votedFor = -1rf.state = Followerrf.currentTerm = 0rf.leaderId = -1rf.applyCh = applyChrf.readPersist(persister.ReadRaftState())// start ticker goroutine to start electionsgo rf.ticker()return rf}
Make函数负责新建一个Raft节点,抛开applyCh,readPersist这些东西先不管,我们关注的是state,votedFor,currentTerm这些字段。和上面说的一致,节点初始化时为追随者状态,且拥有选票(votedFor为-1),并且任期为0。那么这个追随者是如何超时成为协调者的呢?答案在ticker这个函数中:
// raft.gofunc (rf *Raft) ticker() {for rf.killed() == false {time.Sleep(getRandElectTimeout())rf.mu.Lock()// 如果已经是 leader 了,则跳过下面逻辑if rf.state == Leader {rf.mu.Unlock()continue}rf.becomeCandidate()var votes int32 = 1 // 自己的一票for peerId, _ := range rf.peers {if peerId == rf.me { // 跳过自己,向其它节点发送请求continue}go rf.sendRequestVoteToPeer(peerId, &votes)}rf.mu.Unlock()}}
ticker是由go关键字开启的一个死循环(loop),即节点被创建后会一直运行,除非节点被杀死,永远不会停止。进入循环后,节点会通过Sleep函数休眠一段时间,这段时间就是节点的心跳超时时间,在这段时间内,如果当前节点还未收到来自领导者的心跳请求,那么节点就会自动从追随者切换到协调者,当然由于日志暂时还未实现,因此目前ticker会休眠一段后,自动成为协调者,这部分将在后面一一完成。
节点成为协调者后,会向集群中的其它节点发送投票RPC请求,即sendRequestVoteToPeer函数。
该函数会向其它节点发送RequestVote RPC请求,在论文中,RequestVote是这样定义的:

图中划红线的字段暂时不需要。转化为代码如下:
type RequestVoteArgs struct {Term int // 请求者任期CandidateId int // 请求者 id}type RequestVoteReply struct {Term int // 回复者任期VoteGranted bool // 是否投票,true 则投票}
RequestVoteArgs是RequestVote RPC请求参数,RequestVoteReply是响应结果。请求者通过sendRequestVote函数向某个节点发送RequestVote RPC请求:
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {ok := rf.peers[server].Call("Raft.RequestVote", args, reply)return ok}
其它节点受到请求后,会自动调用RequestVote函数进行处理:
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {rf.mu.Lock()defer rf.mu.Unlock()reply.Term = rf.currentTermreply.VoteGranted = falseif args.Term < rf.currentTerm {return}// 发现任期大的,成为 followerif args.Term > rf.currentTerm {rf.becomeFollower(args.Term)}if rf.votedFor == -1 || rf.votedFor == args.CandidateId {reply.VoteGranted = truerf.votedFor = args.CandidateId // 投票后,记得更新 votedFor}}
注意:这里,我们无需纠结这个RPC是如何产生的,只需要知道sendRequestVote发出的RPC请求会被RequestVote函数处理然后返回。
这个地方,我们再来回答刚才提出的问题:任期在选举过程中究竟有何作用了?
「任期」表示节点的逻辑时钟,任期高的节点拥有更高的话语权。在RequestVote这个函数中,如果请求者的任期小于当前节点任期,则拒绝投票;如果请求者任期大于当前节点人气,那么当前节点立马成为追随者。
「投票」建立在双方任期一致的情况下,如果当前节点未投过票(即 votedFor为-1),或者已经给请求者投过票,那么仍然可以为请求者投票(VoteGranted=true),投票后需设置votedFor字段为请求者id。
我们再回到sendRequestVoteToPeer这个函数上来,协调者通过该函数向其它节点发送投票请求,并在函数中对请求结果进行处理,如下:
func (rf *Raft) sendRequestVoteToPeer(peerId int, votes *int32) {rf.mu.Lock()args := RequestVoteArgs{Term: rf.currentTerm,CandidateId: rf.me,}reply := RequestVoteReply{}rf.mu.Unlock()ok := rf.sendRequestVote(peerId, &args, &reply)if !ok {return}rf.mu.Lock()defer rf.mu.Unlock()// 如果当前的状态不为 candidate,那么将不能接受选票,所以直接返回if rf.state != Candidate || args.Term != rf.currentTerm {return}if reply.Term > rf.currentTerm {rf.becomeFollower(reply.Term)return}if reply.VoteGranted {atomic.AddInt32(votes, 1)curVotes := int(atomic.LoadInt32(votes))if curVotes >= (len(rf.peers)+1)/2 {rf.becomeLeader()return}}}
代码3~7行,请求者将自己的任期、id信息包装为请求结构体,并通过sendRequestVote函数发送RPC请求。代码16~30行,请求者拿到响应结果后,处理响应数据。首先判断节点是否为协调者,如不是则直接返回,如果在发送RPC过程中,节点任期发生了变化(不同任期的选票不能使用),也直接返回;如果发现回复者任期大,那么立马成为追随者并返回;增加选票数,如果超过了半数,协调者立即成为领导者。
在这里,我们也发现了一条黄金铁律:任期大的节点对任期小的拥有绝对的话语权,一旦发现任期大的节点,立马成为其追随者。
(三)小结
领导者选举主要工作可总结如下:
三个状态,节点状态之间的转换函数。
1个loop——ticker。
1个RPC请求和处理,用于投票。
另外,ticker会一直运行,直到节点被kill,因此集群领导者并非唯一,一旦领导者出现了宕机、网络故障等问题,其它节点都能第一时间感知,并迅速做出重新选举的反应,从而维持集群的正常运行,毕竟国不可一日无主,Raft集群一旦失去了领导者,就无法工作。
对于领导者而言,一旦当选,就必须不停的向其它节点宣示自己的地位,只要朕还在一日,尔等仍是太子。
那么领导者如何向其它节点宣示自己的地位了?这就是日志同步这个模块要解决的问题。
三、日志同步
日志同步是领导者独有的权利,领导者向追随者发送日志,追随者同步日志。
日志同步要解决如下两个问题:
领导者宣示自己的主权,追随者不可造反(再次选举)。
领导者将自己的日志数据同步到追随者,达到数据备份的效果。
同样地,日志同步也需要与其它节点进行沟通,对应论文中的AppendEntriesArgs RPC请求,如下图所示:

将其翻译为代码:
// log.gotype AppendEntriesArgs struct {Term int // leader 任期LeaderId int // leader idPrevLogIndex int // leader 中上一次同步的日志索引PrevLogTerm int // leader 中上一次同步的日志任期Entries []LogEntry // 同步日志LeaderCommit int // 领导者的已知已提交的最高的日志条目的索引}type AppendEntriesReply struct {Term int // 当前任期号,以便于候选人去更新自己的任期号Success bool // 是否同步成功,true 为成功}
在RPC参数有几个重要字段:
PreLogIndex:领导者与节点上一次同步的日志序号。
PreLogTerm:领导者与节点上一次同步的日志任期。
Entries:待同步日志数据。
LeaderCommit:领导者日志提交序号。
领导者与追随者之间的日志同步有一种特殊情况:Entries为空,即无日志同步,既然没有日志需要发送,那么为什么要发送AppendEntries请求了?
因为领导者需要宣示自己的权利,如果领导者不发送请求,那么追随者会认为领导者「死亡」了,会自发的进行下一轮选举,霸道的领导者肯定不愿意这种情况发生,因此即使日志是空的,也要发送AppendEntries请求,这种特殊的场景被称为「心跳」。
追随者在一定时间内收到日志同步请求或者心跳,都会重置自己「选举超时时间」,因此就不会发出下一轮选举,领导者一直是安全的。
既然领导者需要不断地与追随者同步日志,那么领导者如何知道追随者日志的同步情况了?
Raft节点使用nextIndex,matchIndex等字段来维护这些信息,如下:
type Raft struct {// ....省略state PeerStatecurrentTerm int // 当前任期votedFor int // 给谁投过票leaderId int // 集群 leader idapplyCh chan ApplyMsg // apply message channel// 2B+ log rLog // 日志+ lastReceivedFromLeader time.Time // 上一次收到 leader 请求的时间+ nextIndex []int // 下一个待发送日志序号,leader 特有+ matchIndex []int // 已同步日志序号,leader 特有+ commitIndex int // 已提交日志序号+ lastApplied int // 已应用日志序号}
log:节点日志数据。
lastReceivedFromLeader:上一次收到leader请求的时间。
nextIndex:节点下一个待同步的日志序号。
matchIndex:节点已同步的日志序号。
commitIndex:已提交的日志序号。
lastApplied:已应用的日志序号。
(一)日志
Raft集群中的节点通过日志来保存数据,且日志是只可追加的(Append-only),如下图所示:
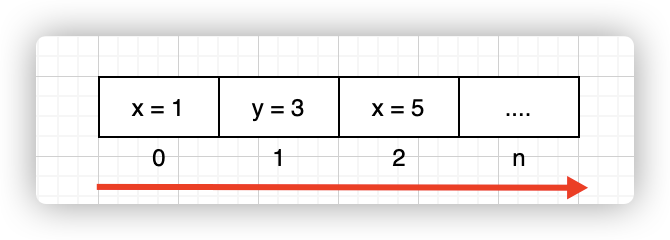
以KV为例,日志可以看作是一个不断增加的数组,从0开始,序号为0的日志内容为x=1,即将x的值设为1;由于旧日志不可修改,因此如果需要修改x,那么就只能通过追加覆盖的方式,即序号为2的日志x=5。
那么日志「已提交」与「已应用」有什么区别了?
仍以上图为例,假设日志的提交序号为2,即x=5已提交,但是日志的应用序号为1,即x=5未应用,但已提交,因此实际可见的数据其实是这样的:
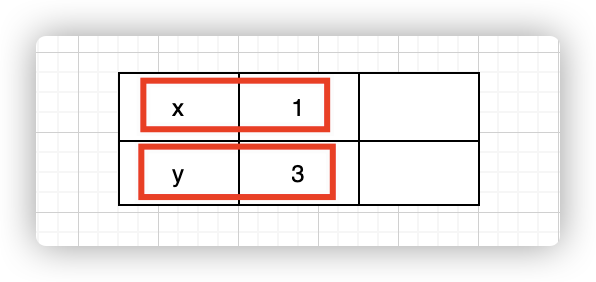
x值为1,而y为3,而一旦日志2被应用后,x值就会被更改(日志数据不变,x可见数据会变),如下:
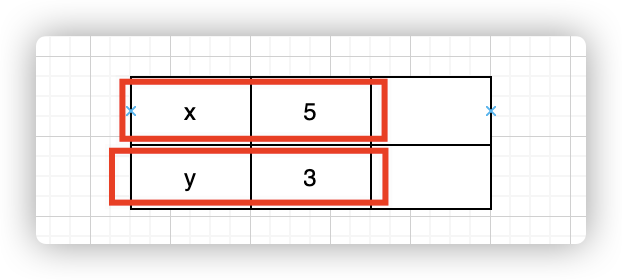
虽然日志数据没有发生改变,但是x可见值却发生了改变,可以将日志序号理解为版本,新版本会覆盖旧版本的值。
(二)状态机
已提交的日志被应用后才会生效,那么数据的可见性由何种机制来保证了?Raft使用了状态机来保证相同日志被应用不同节点后,数据是一致的。如下图所示:
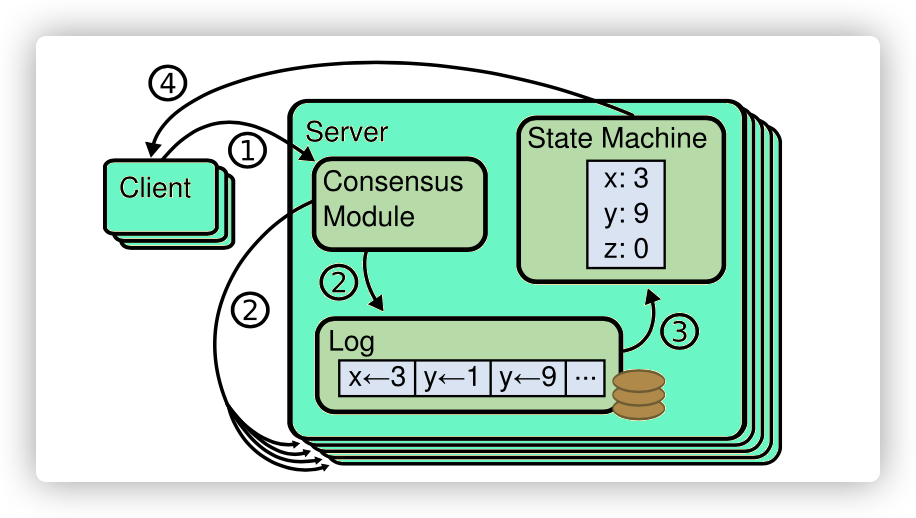
状态机保证了不同节点在被应用了相同日志后,数据的可见性是一致的,这样就能保证集群数据的一致性,这也是Raft算法的根本目的所在。
继续来看log这个字段,Raft节点将所有日志以追加的方式保存到了log 中,log本质上是一个数组(切片),如下:
// rLog.gotype LogEntry struct {Term int // 任期Command interface{} // 命令}type rLog struct {Entries []LogEntry}func defaultRLog() rLog {return rLog{Entries: []LogEntry{{Term: 0,Command: nil,},},}}func (l *rLog) entryAt(index int) LogEntry {return l.Entries[index-l.first()]}func (l *rLog) append(entry ...LogEntry) {l.Entries = append(l.Entries, entry...)}func (l *rLog) last() int {if len(l.Entries) == 0 {return 0}return len(l.Entries) - 1}func (l *rLog) lastTerm() int {return l.Entries[l.last()].Term}func (l *rLog) first() int {return 0}func (l *rLog) firstTerm() int {return l.Entries[l.first()].Term}func (l *rLog) size() int {return len(l.Entries)}
每一条日志都可被抽象为LogEntry,其有两个字段:
Term:日志任期。
Command:日志内容,任意类型,根据具体业务来实现。
rLog结构体用来保存节点日志,其核心字段Entries就是用来存储日志内容的切片。我们顺便也给rLog定义了一系列函数方便访问日志数据(避免每次在业务中对切片进行操作)。
注意:defaultRLog函数返回一个默认的rLog,根据Raft论文中的阐述,日志切片的第一个作为占位使用,因此在初始化时,我们推入了一个Command为nil的日志。
(三)同步
日志同步是领导者独有的功能,因此在成为领导者后,第一时间就是初始化 nextIndex、matchIndex 并且开始日志同步,如下:
func (rf *Raft) becomeLeader() {rf.state = Leaderrf.leaderId = rf.me+ l := len(rf.peers)+ rf.nextIndex = make([]int, l)+ rf.matchIndex = make([]int, l)+ for i := 0; i < l; i++ {+ // nextIndex[0] 表示 0 号 peer+ rf.nextIndex[i] = rf.log.last() + 1 // 初始值为领导者最后的日志序号+1+ rf.matchIndex[i] = 0 // 初始值为 0,单调递增+ }+ go rf.ping()}
这里,我们就能发现nextIndex、matchIndex的含义了,成为领导者后,领导者并不知道其它节点的日志情况,因此与其它节点需要同步那么日志,领导者并不知道,因此他选择了「试」。nextIndex、macthIndex 的长度都是节点个数,如3,其中nextIndex[0]、matchIndex[0]分别用来保存节点0的下一个待同步日志序号、已同步日志序号。
nextIndex初始化值为log.last+1,即领导者最后一个日志序号+1,因此其实这个日志序号是不存在的,显然领导者也不指望一次能够同步成功,而是拿出一个值来试探。
matchIndex初始化值为0,这个很好理解,因为他还未与任何节点同步成功过,所以直接为0。
最后领导者通过ping函数来周期性地向其它节点同步日志(或心跳),如下:
func (rf *Raft) ping() {for rf.killed() == false {rf.mu.Lock()if rf.state != Leader {rf.mu.Unlock()// 如果不是 leader,直接退出 loopreturn}for peerId, _ := range rf.peers {if peerId == rf.me {// 更新自己的 nextIndex 和 matchIndexrf.nextIndex[peerId] = rf.log.size()rf.matchIndex[peerId] = rf.nextIndex[peerId] - 1continue}go rf.sendAppendEntriesToPeer(peerId)}rf.mu.Unlock()time.Sleep(heartbeatInterval)}}
和ticker一样,ping同样是一个死循环,但是领导者独有的。一旦发现当前状态不为leader,立马退出循环(代码第4行),领导者通过sendAppendEntriesToPeer函数向其它所有节点(自己除外)发送AppendEntries RPC请求。与RequestVote类似,调用sendAppendEntries函数发送请求:
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)return ok}
请求达到节点后,会自动调用AppendEntries函数处理请求:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {rf.mu.Lock()defer rf.mu.Unlock()reply.Term = rf.currentTermreply.Success = falseif args.Term < rf.currentTerm {return}// 如果你大,那就成为 followerif args.Term > rf.currentTerm {rf.becomeFollower(args.Term)rf.leaderId = args.LeaderId}if rf.state != Follower {rf.becomeFollower(args.Term)}rf.leaderId = args.LeaderIdrf.lastReceivedFromLeader = time.Now()logSize := rf.log.size()// 日志、任期冲突直接返回if args.PrevLogIndex >= logSize || rf.log.entryAt(args.PrevLogIndex).Term != args.PrevLogTerm {return}entriesSize := len(args.Entries)insertIndex := args.PrevLogIndex + 1entriesIndex := 0// 遍历日志,找到冲突日志for {// 超过了长度 breakif insertIndex >= logSize || entriesIndex >= entriesSize {break}// 日志冲突,breakif rf.log.entryAt(insertIndex).Term != args.Entries[entriesIndex].Term {break}insertIndex++entriesIndex++}// 追加日志中尚未存在的任何新条目if entriesIndex < entriesSize {// [0,insertIndex) 是之前已经同步好的日志rf.log.subTo(insertIndex - rf.log.first())rf.log.append(args.Entries[entriesIndex:]...)}// 取两者的最小值if args.LeaderCommit > rf.commitIndex {rf.commitIndex = minInt(args.LeaderCommit, rf.log.last())}reply.Success = true}
AppendEntries处理请求是比较复杂的,首先代码7~14行,二者几乎一致,如果任期小则拒绝,任期大,则称为其追随者。代码15~19行,如果收到AppendEntries请求,当前节点必须立马成为追随者(土皇帝来了!),并且更新leaderId和 lastReceivedFromLeader,即更新超时心跳时间。
代码22行,如果日志完全冲突,上一个同步日志序号超过了当前节点的日志大小,或者任期不一致,那么直接返回false。
代码25~46行,解决日志部分冲突的问题,如果集群发生了领导者更换,新领导者的日志与现有节点日志有很多冲突,那么需要依次遍历日志,找到不冲突的起始序号,删除冲突日志,然后继续同步(由于Raft的特性,如果后面的日志是匹配的,那么前面的日志一定是匹配的)。
代码48~49行,根据领导者日志提交序号来更新日志提交序号,日志提交序号=min(leaderCommit, last)。
最后返回true给领导者,同步成功。领导者收到这个响应后,处理:
func (rf *Raft) sendAppendEntriesToPeer(peerId int) {rf.mu.Lock()nextIndex := rf.nextIndex[peerId]prevLogTerm := 0prevLogIndex := 0entries := make([]LogEntry, 0)// 可能会存在 nextIndex 超过 rf.log 的情况if nextIndex <= rf.log.size() {prevLogIndex = nextIndex - 1}prevLogTerm = rf.log.entryAt(prevLogIndex).Termentries = rf.log.getEntries(nextIndex-rf.log.first(), rf.log.size())args := AppendEntriesArgs{Term: rf.currentTerm,LeaderId: rf.me,PrevLogIndex: prevLogIndex,PrevLogTerm: prevLogTerm,Entries: entries,LeaderCommit: rf.commitIndex,}reply := AppendEntriesReply{}rf.mu.Unlock()// 发送 RPC 的时候不要加锁ok := rf.sendAppendEntries(peerId, &args, &reply)if !ok {return}rf.mu.Lock()defer rf.mu.Unlock()if rf.state != Leader || args.Term != rf.currentTerm {return}if reply.Term > rf.currentTerm {rf.becomeFollower(reply.Term)rf.leaderId = peerIdreturn}if reply.Success {// 1. 更新 matchIndex 和 nextIndexrf.matchIndex[peerId] = prevLogIndex + len(args.Entries)rf.nextIndex[peerId] = rf.matchIndex[peerId] + 1// 2. 计算更新 commitIndexnewCommitIndex := getMajorIndex(rf.matchIndex)if newCommitIndex > rf.commitIndex {rf.commitIndex = newCommitIndex}} else {// 同步失败,回退一步rf.nextIndex[peerId] -= 1if rf.nextIndex[peerId] < 1 {rf.nextIndex[peerId] = 1}}}
回到sendAppendEntriesToPeer函数中来,领导者通过该函数向其它节点发送同步日志,首先领导者通过nextIndex获取发送节点下一个要同步的日志序号,将其-1就是上一个已同步的日志序号。然后将这些信息包装为参数发送给节点,收到节点响应后,根据结果来处理。
代码31行,如果不再是领导者、前后任期不一致,直接返回。代码34行,黄金铁律,发现任期大的,立马成为追随者。
代码41~47行,如果同步成功则更新该节点的matchIndex和nextIndex,并且根据matchIndex来推进commitIndex;这里原理很简单,领导者的commitIndex必须建立在集群的大部分节点均已匹配的基础上,因此getMajorIndex实则取的是 matchIndex的中位数,这个地方的序号已经被大部分节点同步到了,因此就可以用来更新领导者的commitIndex。
代码50~53行,如果同步失败了,更新nextIndex,这个地方比较粗暴,直接回退-1,不断的试探,直至试出匹配值(待优化)。
在ping函数中,领导者正是通过不间断的日志同步,冲突则重新同步的方式来与其它节点同步数据,若所有节点日志均已同步完成,那么AppendEntries被视为心跳,控制追随者勿发起新的选举。
(四)完善选举
在领导者选举中,我们提到是否投出选票还与日志有关,那么有何关联了?
实则也简单,为了保证日志「更加完善」的节点能够当选领导者,因此选票会向日志完善的节点倾斜,这被称为upToDate条件。如下:
type RequestVoteArgs struct {// ...// 2B+ LastLogTerm int+ LastLogIndex int}func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {// Your code here (2A, 2B).// 1. 如果 term < currentTerm 返回 false (5.2 节)// 2. 如果 votedFor 为空或者为 candidateId,并且候选人的日志至少和自己一样新,那么就投票给他(5.2 节,5.4 节)rf.mu.Lock()defer rf.mu.Unlock()// 省略....+ upToDate := false+ // 如果两份日志最后的条目的任期号不同,那么任期号大的日志新+ if args.LastLogTerm > rf.log.lastTerm() {+ upToDate = true+ }+ // 如果两份日志最后的条目任期号相同,那么日志比较长的那个就新+ if rf.log.lastTerm() == args.LastLogTerm && args.LastLogIndex >= rf.log.last() {+ upToDate = true+ }+ if (rf.votedFor == -1 || rf.votedFor == args.CandidateId) && upToDate {+ reply.VoteGranted = true+ rf.votedFor = args.CandidateId // 投票后,记得更新 votedFor+ }}func (rf *Raft) sendRequestVoteToPeer(peerId int, votes *int32) {rf.mu.Lock()args := RequestVoteArgs{Term: rf.currentTerm,CandidateId: rf.me,+ LastLogIndex: rf.log.last(),+ LastLogTerm: rf.log.lastTerm(),}// 省略....}
请求者在发送RequestVote请求时,会附带上自己日志的最后序号和任期;回复者接收到这两条信息后,会将其与自己的任期和日志进行比较,来看看双方谁的日志比较完整。首先比较任期,任期大的更新话语权,如果请求者的最后任期大,那么upToDate为true,如果任期相同,但请求者的日志序号大或者相等,那么upToDate为true,只有当upToDate为true 时,当前节点才能投出选票。
(五)日志应用
在Raft节点中还有lastApplied这个重要的字段,维护着当前节点的日志应用序号。在日志同步的过程中,commitIndex会不断的更新,但lastApplied似乎一直没有变过,因为我们把它遗忘了,按照Raft论文的说话,一旦发现commitIndex大于lastApplied,应该立马将可应用的日志应用到状态机中。
那么如何应用了?答案就是applyCh这个字段。
Raft节点本身是没有状态机实现的,状态机应该由Raft的上层应用来实现,因此我们不会谈论如何实现状态机,只需将日志发送给applyCh这个通道即可。如下:
func (rf *Raft) applyLog() {for rf.killed() == false {time.Sleep(applyInterval)rf.mu.Lock()msgs := make([]ApplyMsg, 0)for rf.commitIndex > rf.lastApplied {rf.lastApplied++ // 上一个应用的++// 超过了则回退,并 breakif rf.lastApplied >= rf.log.size() {rf.lastApplied--break}msg := ApplyMsg{CommandValid: true,Command: rf.log.entryAt(rf.lastApplied).Command,CommandIndex: rf.lastApplied,}msgs = append(msgs, msg)}rf.mu.Unlock()for _, msg := range msgs {rf.applyCh <- msg}}}
applyLog是Raft实现中的第三个死循环,且每个节点都有。主要工作就是周期性的检查commitIndex与lastApplied,一旦发现commitIndex 大于lastApplied,立马将lastApplied值推到与commitIndex一致。ApplyMsg是应用日志的结构体定义,如下:
type ApplyMsg struct {CommandValid bool // 是否有效,无效则不应用Command interface{} // 日志命令CommandIndex int // 日志序号}
ApplyMsg会被发送到applyCh通道中,上层服务接收到后,将其应用到状态机中。applyLog同样是通过go关键字开启的一个协程,如下:
func Make(peers []*labrpc.ClientEnd, me int,persister *Persister, applyCh chan ApplyMsg) *Raft {rf := &Raft{}// 省略...rf.applyCh = applyCh// 2B+ rf.log = defaultRLog()+ rf.lastReceivedFromLeader = time.Now()+ rf.commitIndex = 0+ rf.lastApplied = 0// initialize from state persisted before a crashrf.readPersist(persister.ReadRaftState())// start ticker goroutine to start electionsgo rf.ticker()+ go rf.applyLog()return rf}
(六)小结
日志同步主要工作可总结如下:
2个loop,ping领导者独有,applyLog所有节点均有,推进日志应用。
1个RPC请求和处理,用于日志同步。
完善选举,加入日志完整度判断。
到此,选举、日志同步均已完成,那么如果集群中的节点发生了宕机,已经同步好的日志都丢了怎么办?如何解决这个问题,这就是持久化模块的功能了。
四、持久化
数据持久化是Raft四大模块中最简单的一部分。在Raft论文中指出,需要持久化的字段只有三个:

分别是currentTerm(当前任期),votedFor(给谁投过票),log(日志数据)。数据落盘的编码方式有很多种,这里我们选择比较简单的gob编码,代码实现如下:
// 将数据持久化到磁盘func (rf *Raft) persist() {w := new(bytes.Buffer)e := labgob.NewEncoder(w)e.Encode(rf.currentTerm)e.Encode(rf.votedFor)e.Encode(rf.log)data := w.Bytes()rf.persister.SaveRaftState(data)}// 从磁盘中读取数据并解码func (rf *Raft) readPersist(data []byte) {if data == nil || len(data) < 1 {return}r := bytes.NewBuffer(data)d := labgob.NewDecoder(r)var (currentTerm intvotedFor intlog rLog)if d.Decode(¤tTerm) != nil ||d.Decode(&votedFor) != nil ||d.Decode(&log) != nil {DPrintf("decode persisted state err.")} else {rf.currentTerm = currentTermrf.votedFor = votedForrf.log = log}}
persist函数负责将当前Raft节点中需要持久化的字段保存至磁盘中,而 readPersist函数负责从磁盘中读取数据并反序列化为currentTerm、votedFor和log三个字段。对于readPersist函数,在Raft节点创建的时候调用它一次,如下:
func Make(peers []*labrpc.ClientEnd, me int,persister *Persister, applyCh chan ApplyMsg) *Raft {rf := &Raft{}// 省略// initialize from state persisted before a crashrf.readPersist(persister.ReadRaftState())// 省略return rf}
而persist函数则稍微复杂一些,不过只需记住一条黄金铁律即可:currentTerm、votedFor和log任何一个字段只要发生了更改,立马调用persist函数。在投票模块中,节点状态改变、投出选票等操作均会引起这三个字段的改变,在改变后加上persist函数即可:
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {// 省略// 发现任期大的,成为 followerif args.Term > rf.currentTerm {rf.becomeFollower(args.Term)+ rf.persist()}// 省略if (rf.votedFor == -1 || rf.votedFor == args.CandidateId) && upToDate {reply.VoteGranted = truerf.votedFor = args.CandidateId // 投票后,记得更新 votedFor+ rf.persist()}}func (rf *Raft) sendRequestVoteToPeer(peerId int, votes *int32) {// 省略if reply.Term > rf.currentTerm {rf.becomeFollower(reply.Term)+ rf.persist()return}// 省略}
在ticker函数中,如果心跳超时节点会自发成为协调者,任期和选票均会发生改变,因此:
func (rf *Raft) ticker() {for rf.killed() == false {// 省略rf.becomeCandidate()+ rf.persist()// 省略}}
同样地,在日志同步模块也会引发日志、状态的改变:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {// 省略// 如果你大,那就成为 followerif args.Term > rf.currentTerm {rf.becomeFollower(args.Term)rf.leaderId = args.LeaderId+ rf.persist()}if rf.state != Follower {rf.becomeFollower(args.Term)+ rf.persist()}// 省略// 追加日志中尚未存在的任何新条目if entriesIndex < entriesSize {// [0,insertIndex) 是之前已经同步好的日志rf.log.subTo(insertIndex - rf.log.first())rf.log.append(args.Entries[entriesIndex:]...)+ rf.persist()}reply.Success = true}func (rf *Raft) sendAppendEntriesToPeer(peerId int) {// 省略if reply.Term > rf.currentTerm {rf.becomeFollower(reply.Term)rf.leaderId = peerId+ rf.persist()return}// 省略}
对于persist的调用时机其实是很容易把握的,只需记住任何引起该三个字段发生改变的操作都必须紧接着一次persist函数即可。
(一)优化冲突同步
在日志同步模块中,我们提到:如果同步失败了,更新nextIndex,这个地方比较粗暴,直接回退1,不断的试探,直至试出匹配值(待优化)。
每次-1的试探是非常低效了,试想一下,如果二者日志相差几百,那么就得几百次试探,集群可能需要很久才都达到一致。因此提高同步效率,我们需要优化同步冲突问题。
思路也很简单,在同步发生冲突后,不再靠领导者一点点试探,而是追随者主动告诉领导者冲突的日志序号和任期,下次领导者直接通过冲突序号、任期再次同步即可。
为此,我们需要给Reply增加两个字段分别表示冲突任期和序号:
type AppendEntriesReply struct {+ ConflictTerm int // 日志冲突任期+ ConflictIndex int // 日志冲突序号Term int // 当前任期号,以便于候选人去更新自己的任期号Success bool}
在AppendEntries处理中,如果日志发生了完全冲突,需要遍历日志找到冲突任期、序号:
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {// 省略// 日志、任期冲突直接返回+ if args.PrevLogIndex >= logSize {+ reply.ConflictIndex = rf.log.size()+ reply.ConflictTerm = -1+ return+ }+ if rf.log.entryAt(args.PrevLogIndex).Term != args.PrevLogTerm {+ reply.ConflictTerm = rf.log.entryAt(args.PrevLogIndex).Term+ for i := rf.log.first(); i < rf.log.size(); i++ {+ if rf.log.entryAt(i).Term == reply.ConflictTerm {+ reply.ConflictIndex = i+ break+ }+ }+ return+ }// 省略}
代码第4~6行,如果领导者上一次同步日志序号大于当前节点的日志大小,那么冲突序号就是日志大小,冲突任期为-1。代码9~16行,如果上一次同步序号仍在日志内,但是当前节点在该序号的日志任期与领导者任期不同,那么设置冲突任期为当前节点序号的任期,并遍历日志找到第一个有任期冲突的日志序号,并设置为ConflictIndex。
有了日志冲突任期和序号后,领导者收到同步失败后,就能立马对下一次同步做出调整:
func (rf *Raft) sendAppendEntriesToPeer(peerId int) {// 省略if reply.Success {// 1. 更新 matchIndex 和 nextIndexrf.matchIndex[peerId] = prevLogIndex + len(args.Entries)rf.nextIndex[peerId] = rf.matchIndex[peerId] + 1// 2. 计算更新 commitIndexnewCommitIndex := getMajorIndex(rf.matchIndex)- if newCommitIndex > rf.commitIndex {+ if newCommitIndex > rf.commitIndex && rf.log.entryAt(newCommitIndex).Term == rf.currentTerm {rf.commitIndex = newCommitIndex}} else {+ if reply.ConflictTerm == -1 {+ rf.nextIndex[peerId] = reply.ConflictIndex+ } else {+ // Upon receiving a conflict response, the leader should first search its log for conflictTerm.+ // If it finds an entry in its log with that term,+ // it should set nextIndex to be the one beyond the index of the last entry in that term in its log.+ lastIndexOfTerm := -1+ for i := rf.log.last(); i >= rf.log.first(); i-- {+ if rf.log.entryAt(i).Term == reply.ConflictTerm {+ lastIndexOfTerm = i+ break+ }+ }+ // If it does not find an entry with that term, it should set nextIndex = conflictIndex.+ if lastIndexOfTerm < 0 {+ rf.nextIndex[peerId] = reply.ConflictIndex+ } else {+ // 如果找到了冲突的任期,那么 +1 就是下一个需要同步的+ rf.nextIndex[peerId] = lastIndexOfTerm + 1+ }+ }}}
代码14~15行,如果冲突任期为-1,证明日志任期无问题,因此我们只需更新冲突序号。代码20~32行,如果冲突任期不为-1,那么从日志尾部向头部遍历,找到冲突任期所在的最后一个日志序号A,然后判断该序号是否小于0,若小于0,则表示找不到该冲突任期的序号,因此下一次同步序号仍然为冲突序号,否则下一次同步序号为A+1。
另外,你是否发现了代码9~10行也发生了改变,对于commitIndex的更新,我们新增了一个判断条件:新的提交日志序号的任期必须与节点当前任期一致。
为什么要加上这个条件了?在论文Figure 8中有其说明,主要是为了保证领导者只能提交自己任期的日志,不能提交其它任期日志,从而保证原来任期的日志不会被覆盖。具体可参考。
(二)小结
数据持久化是Raft中最简单的一个模块,只需掌握持久化时机,细心一点就能完成。
解决了数据持久化和日志冲突问题后,我们再来引入一个新的问题,日志只能以追加方式进行操作,那么如果某一条数据被修改了很多次,那么日志中存在了该数据的多个版本,如果数据量庞大,那么就会造成很大的空间浪费,相应地,对于日志持久化也会带来很大的性能影响,那么如何解决这个问题呢?答案就是快照。
五、快照
节点是无法容忍日志数据无限增加的。为了解决这个问题,Raft引入了快照机制,例如,一个Raft节点当前日志序号范围是[0,100),对范围为 [0,50]日志进行快照后,日志范围就变成为[51,100)。如下图:
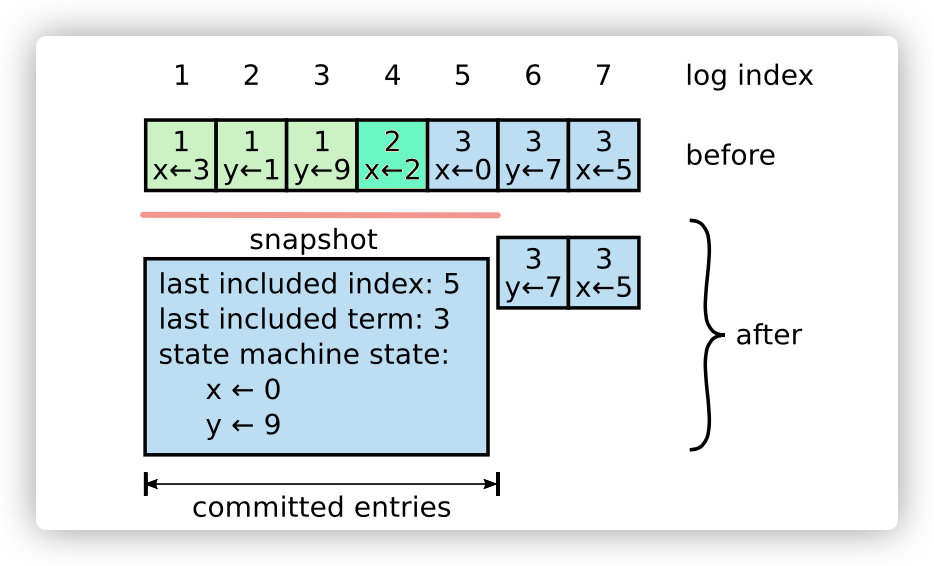
x,y值有多条日志,但实际上大部分日志都是可被删除的,因此快照机制直接将1~5号日志融合,合并成一个快照块。
快照块的存储方式与日志不同,主要分为三个部分:
lastIncludeIndex,快照块所包含的最后一个日志序号,即图中5。
lastIncludeTerm,快照块所包含的最后一个日志任期,即图中3。
state,状态机数据,由上层应用来处理,Raft节点不做处理。
为什么我们无需保存快照块的第一个日志序号呢?快照只会从头开始,不会从日志切片中间截断,因此只需保存最后一个日志序号。
注意,在快照后,日志切片会发生截断,日志切片序号与日志序号会有不兼容问题,如下:
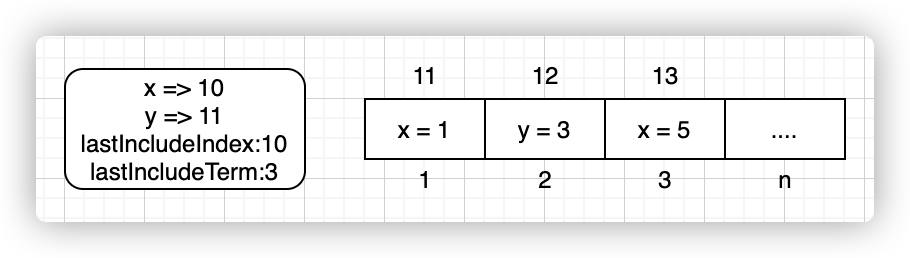
日志经过快照后,切片序号仍然是1、2、3(0 号作为占位,无实际意义),但是日志序号却是11、12、13,因此如果再使用日志序号来从日志切片中获取日志,需有一个转换操作,这个操作也很简单:
切片序号=日志序号-lastIncludeIndex。
因此,我们需要重构rLog这个结构体和其方法:
type rLog struct {Entries []LogEntry+ LastIncludedIndex int+ LastIncludedTerm int}func defaultRLog() rLog {return rLog{Entries: []LogEntry{{Term: 0,Command: nil,},},+ LastIncludedIndex: 0,+ LastIncludedTerm: 0,}}func (l *rLog) entryAt(index int) LogEntry {+ if index < l.LastIncludedIndex || index > l.LastIncludedIndex+len(l.Entries) {+ panic(fmt.Sprintf("lastIncludeIndex: %d, but index: %d is invalid", l.LastIncludedIndex, index))+ }+ return l.Entries[index-l.LastIncludedIndex]}// 最后序号func (l *rLog) last() int {if len(l.Entries) == 0 {return 0}+ return len(l.Entries) + l.LastIncludedIndex - 1}// 最后任期func (l *rLog) lastTerm() int {+ return l.Entries[l.last()-l.LastIncludedIndex].Term}// 第一个序号func (l *rLog) first() int {+ return l.LastIncludedIndex}// 日志长度func (l *rLog) size() int {+ return len(l.Entries) + l.LastIncludedIndex}
rLog新增了LastIncludedIndex和LastIncludedTerm两个字段,分别用于表示当前节点最后一个快照块的lastIncludedIndex、lastIncludedTerm值。另外,在entryAt函数中,读日志需要将日志序号减去LastIncludedIndex值,第一个日志序号应该是LastIncludedIndex值,即first函数,size函数也需要加上LastIncludedIndex后才能得到当前所有日志的总大小。
同时,Raft节点需要新增一个snapshopt字段用来保存快照数据,如下:
type Raft struct {// 省略+ snapshot []byte}func Make(peers []*labrpc.ClientEnd, me int,persister *Persister, applyCh chan ApplyMsg) *Raft {rf := &Raft{}// 省略rf.readPersist(persister.ReadRaftState())+ rf.snapshot = persister.ReadSnapshot()+ rf.commitIndex = rf.log.LastIncludedIndex+ rf.lastApplied = rf.log.LastIncludedIndex// 省略return rf}
Raft在新建时,还需从磁盘中读取持久化的快照数据,且commitIndex、lastApplied的初始值不再是0,而是LastIncludedIndex。现在,我们来解决最后两个问题:何时快照?快照如何执行?
首先第1个问题:何时快照?
上层应用发送快照数据给Raft实例。
领导者发送快照RPC请求给追随者。
对于第1点,前面我们谈到,状态机在上层应用中,因此上层应用知道状态机数据以及日志应用情况,当上层应用觉得日志序号过大(或者其它触发情况),就会将状态机数据、日志应用号通过Snapshot函数发送给Raft实例,如下:
func (rf *Raft) Snapshot(index int, snapshot []byte) {rf.mu.Lock()defer rf.mu.Unlock()// 拒绝快照过的,也拒绝还未提交的if index <= rf.log.LastIncludedIndex || index > rf.commitIndex {return}rf.log.Entries = append([]LogEntry{{Term: 0, Command: nil}}, rf.log.Entries[index-rf.log.LastIncludedIndex+1:]...)rf.log.LastIncludedIndex = indexrf.log.LastIncludedTerm = rf.log.entryAt(index).Termrf.snapshot = snapshotrf.persistStateAndSnapshot(snapshot)}
Snapshot函数接受index,snapshot两个参数,snapshot为快照数据,index是快照数据中最后一个日志序号。代码第5行,判断index与 commitIndex、lastIncludeIndex之间的关系,如果index大于commitIndex,证明快照数据中的日志,当前节点还未提交,因此无法快照;如果index小于等于lastIncludeIndex证明上一次快照已经包含了本次快照数据,所以拒绝。
代码8~12行,接受快照数据,并持久化快照,然后更新LastIncludedIndex,LastIncludedTerm,并切截断日志切片,将已快照部分日志从切片中删除。
任何一个节点都可由上层应用通过Snapshot函数调用来执行快照。如果一个新加入集群的追随者,其日志大幅度落后领导者,如果仅靠日志同步请求来,那么是不够快的(还得一个一个日志的应用),这个时候领导者可以选择将快照发给追随者,追随者直接使用快照就能迅速与其它节点保持数据一致。
因此对于领导者,还有另外一个InstallSnapshot RPC请求,参数与响应定义如下:
type InstallSnapshotArgs struct {Term intLeaderId intLastIncludedIndex intLastIncludedTerm intData []byte}type InstallSnapshotReply struct {Term int}
领导者发送RPC时,需携带本次快照请求的快照数据、LastIncludedIndex、LastIncludedTerm以及任期,而追随者只需回复自己的任期即可,因此对于追随者而言即使快照请求失败也不会有其它影响,而任期代表着话语权,这与其它RPC请求一样。与AppendEntries类似,领导者通过sendInstallSnapshot函数发送快照请求,RPC达到时会调用InstallSnapshot函数进行处理:
// peer 接受 leader InstallSnapshot 请求func (rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) {rf.mu.Lock()defer rf.mu.Unlock()reply.Term = rf.currentTermif args.Term < rf.currentTerm {return}// Send the entire snapshot in a single InstallSnapshot RPC.// Don't implement Figure 13's offset mechanism for splitting up the snapshot.if args.Term > rf.currentTerm {rf.becomeFollower(args.Term)rf.persist()}if rf.state != Follower {rf.becomeFollower(args.Term)rf.persist()}rf.leaderId = args.LeaderIdrf.lastReceivedFromLeader = time.Now()// 拒绝,如果你的小,证明我已经快照过了,无需再次快照if args.LastIncludedIndex <= rf.log.LastIncludedIndex {return}msg := ApplyMsg{SnapshotValid: true,Snapshot: args.Data,SnapshotTerm: args.LastIncludedTerm,SnapshotIndex: args.LastIncludedIndex,}go func() {// 应用快照 msgrf.applyCh <- msg}()}// 发送 InstallSnapshotfunc (rf *Raft) sendInstallSnapshot(server int, args *InstallSnapshotArgs, reply *InstallSnapshotReply) bool {ok := rf.peers[server].Call("Raft.InstallSnapshot", args, reply)return ok}
代码3~20行,与AppendEntries几乎一致,判断任期是否需要成为追随者,刷新leaderId和接收时间。代码第22行,判断当前快照的LastIncludedIndex与当前节点的LastIncludedIndex之间的大小,如果小于等于,证明快照数据已经存在,直接拒绝即可。
代码25~34行,将快照数据封装到ApplyMsg中,并通过ApplyCh发送给上层应用。
和日志应用一样,快照应用也是通过发送ApplyMsg,ApplyMsg结构体中增加了快照相关的字段:
type ApplyMsg struct {CommandValid boolCommand interface{}CommandIndex int// 2D+ SnapshotValid bool+ Snapshot []byte+ SnapshotTerm int+ SnapshotIndex int}
当CommandValid为true时,应用的是日志,SnapshotValid为true时,应用的是快照。领导者得到快照响应后做如下处理:
// sendInstallSnapshotToPeer 向其它 peer 发送快照请求func (rf *Raft) sendInstallSnapshotToPeer(peerId int) {rf.mu.Lock()args := InstallSnapshotArgs{Term: rf.currentTerm,LeaderId: rf.me,LastIncludedIndex: rf.log.LastIncludedIndex,LastIncludedTerm: rf.log.LastIncludedTerm,Data: rf.snapshot,}reply := InstallSnapshotReply{}rf.mu.Unlock()ok := rf.sendInstallSnapshot(peerId, &args, &reply)if !ok {return}rf.mu.Lock()defer rf.mu.Unlock()// 如果当前的状态不为 leader,那么将不能接受if rf.state != Leader || args.Term != rf.currentTerm {return}if reply.Term > rf.currentTerm {rf.becomeFollower(reply.Term)// 你的任期大,我成为你的追随者rf.leaderId = peerIdrf.persist()return}// 注意,快照和日志同步一样,需要更新 matchIndex 和 nextIndex// 发送完快照后,更新了 matchIndex 和 nextIndex,因此在快照期间的日志同步将需要重新来rf.matchIndex[peerId] = args.LastIncludedIndexrf.nextIndex[peerId] = args.LastIncludedIndex + 1}
代码20~29行,与AppendEntries一致,判断任期与状态。代码32~33行,快照后更新matchIndex、nextIndex。
领导者在发现某个节点同步日志序号落后LastIncludedIndex的情况下就会决定发送快照,如下:
func (rf *Raft) ping() {for rf.killed() == false {// 省略for peerId, _ := range rf.peers {// 省略// 当 leader 发现一个 follower 的 nextIndex[follower] - 1, 即 prevLogIndex// 小于 leader 节点的快照时刻时,就会通过 RPC 调用发快照过去+ prevLogIndex := rf.nextIndex[peerId] - 1+ if prevLogIndex < rf.log.LastIncludedIndex {+ go rf.sendInstallSnapshotToPeer(peerId)+ } else {+ go rf.sendAppendEntriesToPeer(peerId)+ }}// 省略}}
第2个问题,快照如何执行?
上层应用通过Snapshot函数来执行快照;
上层应用通过CondInstallSnapshot函数来执行快照。
你应该也发现了,追随者收到快照请求后,并没有立即更新snapshot、log等数据,而是将其包装为了ApplyMsg发送给了上层应用。
那是因为如果Raft实例单独应用了快照,而上层应用不知道,那么就会造成二者的数据不统一。收到ApplyMsg后,上层应用会调用CondInstallSnapshot函数来真正的应用快照,如下:
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {rf.mu.Lock()defer rf.mu.Unlock()// 已快照过了,拒绝if lastIncludedIndex <= rf.commitIndex {return false}// 快照后的处理工作defer func() {rf.log.LastIncludedIndex = lastIncludedIndexrf.log.LastIncludedTerm = lastIncludedTermrf.snapshot = snapshotrf.commitIndex = lastIncludedIndexrf.lastApplied = lastIncludedIndexrf.persistStateAndSnapshot(snapshot) // 持久化快照}()// 删除掉 lastIncludedIndex 之前的日志记录if lastIncludedIndex <= rf.log.last() && rf.log.entryAt(lastIncludedIndex).Term == lastIncludedTerm {// [rf.log.LastIncludedIndex, lastIncludedIndex) 是当前 snapshot 中的日志数据,所以应该删除// 前面需要一个占位rf.log.Entries = append([]LogEntry{{Term: 0, Command: nil}}, rf.log.Entries[lastIncludedIndex-rf.log.LastIncludedIndex+1:]...)return true}// 快照,删除所有 log entriesrf.log.Entries = []LogEntry{{Term: 0, Command: nil}}return true}
和Snapshot类似,CondInstallSnapshot会判断lastIncludedIndex,然后截断日志切片,并且更新log,snapshot,commitIndex,lastApplied等字段,然后持久化快照数据。注意,CondInstallSnapshot还需要判断快照任期是否一致,否则删除所有日志。另外,为什么 CondInstallSnapshot中更新了commitIndex,lastApplied,而 Snapshot却没有?
因为Snapshot是由上层应用直接触发的,建立在当前Raft实例的基础上,而CondInstallSnapshot虽然也是上层应用来调用,但却是领导者触发的,因此追随者的commitIndex,lastApplied字段需要与快照保持一致。
(一)完善日志同步
在引入了lastIncludeIndex以后,日志同步可能与快照之间相互冲突,例如快照更新了lastIncludeIndex的同时AppendEntries在发送日志,却不知道日志发生了截断,因此在取日志数据的时候会发生冲突,我们可以在日志发送前对其判断一次:
func (rf *Raft) sendAppendEntriesToPeer(peerId int) {// 省略nextIndex := rf.nextIndex[peerId]prevLogTerm := 0prevLogIndex := 0entries := make([]LogEntry, 0)// 可能会存在 nextIndex 超过 rf.log 的情况if nextIndex <= rf.log.size() {prevLogIndex = nextIndex - 1}// double check,检查 prevLogIndex 与 lastIncludeIndex+ if rf.log.LastIncludedIndex != 0 && prevLogIndex < rf.log.LastIncludedIndex {+ rf.mu.Unlock()+ return+ }// 省略}
在LastIncludedIndex非0,即已经发生了快照的情况下,如果待同步日志序号小,那么直接返回,本次日志无需同步,快照中已经存在了。另外追随者在受到日志同步请求时,发现同步日志的序号小于自己的LastIncludedIndex时,会直接将LastIncludedIndex作为ConflictIndex返回给领导者。
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {// 省略rf.leaderId = args.LeaderIdrf.lastReceivedFromLeader = time.Now()+ if args.PrevLogIndex < rf.log.LastIncludedIndex {+ reply.ConflictIndex = rf.log.LastIncludedIndex+ reply.ConflictTerm = -1+ return}// 省略}
(二)小结
快照主要工作可总结如下:
1个RPC请求和处理,用于快照。
两个快照应用函数CondInstallSnapshot和Snapshot。
完善日志同步,加入LastIncludedIndex判断。
快照机制并不复杂,关键是日志切片序号与日志序号发生了脱离,需要 LastIncludedIndex来转换;快照请求与日志同步请求大同小异,不过快照最终都是由上层应用来触发,从而保证二者的数据一致性。
六、总结
Raft算法实现是颇具挑战力的,从理解到实现需要走很长的一段路,也正因如此才能收获颇丰。下面让我们来总结一下Raft算法实现的几个重要脉络:
3个状态,follwer,candidate和leader,状态切换的核心在于任期与心跳;
3个loop,ticker,ping,applyLog,其中ping是leader独有的死循环,用于日志同步和快照,ticker用于超时后发起选举,applyLog是最简单的一个死循环,负责将通道中发送日志数据;
3个RPC请求,RequestVote,AppendEntries,InstallSnapshot,分别用于请求投票、日志同步和快照,其中AppendEntries和InstallSnapshot都有leader独有的,二者处理也十分类似;
2条黄金铁律:发现任期大的立即成为其追随者;任何引起currentTerm,votedFor,log改变的操作后,立即持久化数据。
当然Raft算法想要应用在工业上,还需更多的打磨与优化,不推荐造轮子,而是直接使用成品,比如:hashicorp/raft。而从头撸一遍Raft会给你带来新的体验与收获,让你从根上理解Raft,理解它被提出的背景,在此背景下又是如何解决实际问题的,这才是从头实现一个Raft所带来的真正收益。
参考资料:
1.Raft论文
2.6.824实验室2:raft
3.raft指南
作者简介

高佩东
腾讯后端工程师
腾讯后端工程师,平平凡凡小码农,普普通通打工人。
推荐阅读
Pulsar与Rocketmq、Kafka、Inlong-TubeMQ,谁才是消息中间件的王者?
gRPC如何在Golang和PHP中进行实战?7步教你上手!
如何保证MySQL和Redis的数据一致性?10张图带你搞定!
