
手把手带你入门Python爬虫Scrapy

导读:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。

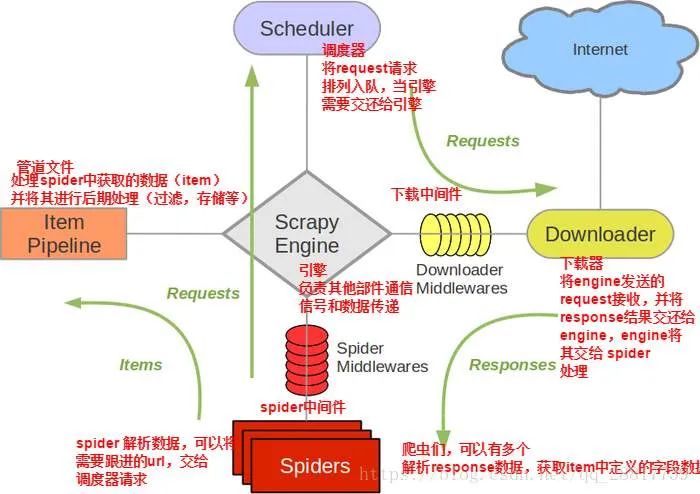
调度器(Scheduler) 下载器(Downloader) 爬虫(Spider) 中间件(Middleware) 实体管道(Item Pipeline) Scrapy引擎(Scrapy Engine)
def parse(self, response):
pass
python3 -m pip install scrapy #这个可能需要花掉一段时间,如果你的网络快可能就比较快,如果你出现超时导致没有安装成功可以继续执行这个命令scrapy startproject lab #创建新的Scrapy项目,注意一下,如果此命令没有你就需要配置一下Scrapy 的环境变量
cd lab #进入创建的项目目录
scrapy genspider labs http://lab.scrapyd.cn/page/1/ # 生成spider 代码class LabItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()def parse(self, response):
items=LabItem() #实例化一个数据对象,用于返回
for sel in response.xpath('//div[@class="col-mb-12 col-8"]'):
print(sel)
for i in range(len(sel.xpath('//div[@class="quote post"]//span[@class="text"]/text()'))):
title = sel.xpath('//div[@class="quote post"]//span[@class="text"]/text()')[i].get()
author = sel.xpath('//div[@class="quote post"]//small[@class="author"]/text()')[i].get()
items["title"]=title
items["author"] = author
yield items #返回提出来的每一个数据对象from itemadapter import ItemAdapter
import json
class FilePipeline(object):
def open_spider(self, spider):
print("当爬虫执行开始的时候回调:open_spider")
def __init__(self):
print("创建爬虫数据存储文件")
self.file = open('test.json',"w", encoding="utf-8")
def process_item(self, item, spider):
print("开始处理每一条提取出来的数据")
content = json.dumps(dict(item),ensure_ascii=False)+"\n"
self.file.write(content)
return item
def close_spider(self, spider):
print("当爬虫执行结束的时候回调:close_spider")
self.file.close()
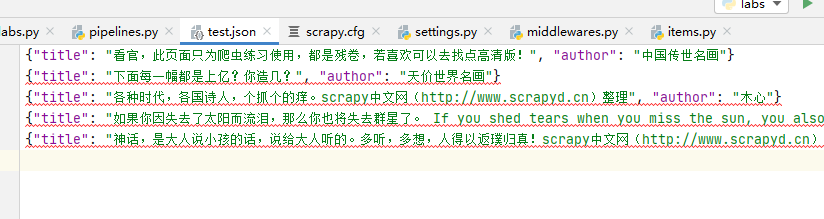
这里是自定义的一个pipeline,所以还需要在setting.py 文件里面把它配置上,如下:
ITEM_PIPELINES = {
'lab.pipelines.FilePipeline': 300,
}

评论