
一文总结Integral Pose Regression方法的方方面面

极市导读
本文并不打算只局限于介绍论文的内容,而是希望结合自己过去读过的文章和经验,对Integral Pose Regression做一个较为全面的分析,给出一些个人的思考,希望能对大家有所帮助~ >>加入极市CV技术交流群,走在计算机视觉的最前沿
Integral Pose Regression是一个非常好用的定位方法,不只局限于姿态估计,而是在目标检测、人脸、人手、物体等任何需要定位的任务中都可以用到。
本篇笔记写作的契机是ICLR 2022的一篇工作Dive Deeper Into Integral Pose Regression,作者团队是上一篇ICCV 2021工作的原班人马,用一系列实验全面探索和验证了Soft-Argmax方法的方方面面性质。对于这些实验和结论,有一部分我觉得也许有更好更合理的解释,因此,这篇笔记我并不打算只局限于介绍这篇论文的内容,而是希望结合自己过去读过的文章和经验,对Integral Pose Regression做一个较为全面的分析,给出一些个人的思考,希望能对大家有所帮助~
当然,这些解释也都是来自于过去我读过的论文,属于前人的智慧,功劳属于论文作者们。
0. 前言
其实一直以来我有注意到一个问题,关键点定位方法分为Heatmap-based和Regression-based两个大类,这毋庸置疑,但Integral Pose Regression(后文写作IPR)究竟应该归入哪一类,在过往的论文中大家的意见其实是不太统一的:
一方面,这名字里都有Regression,算它是Regression-based好像是天经地义吧;另一方面,IPR隐式地学习了关键点的Heatmap,还像Heatmap-based方法一样有decoding过程,说它Heatmap-based好像也没毛病。因此为了清晰起见,本篇笔记将会把Heatmap-based方法用Detection-based方法来描述。
既不受Detection-based方法昂贵的计算束缚,又有着比Regression-based方法更高的精度,IRP就是这样特殊的一个,在精度和速度的天平上简直是得天独厚的存在,因此把目光聚焦在它身上也是理所当然的了,在轻量姿态估计模型设计时,这也是我优先选择的方案。
但是在以往的经验里,IPR虽然比纯数值回归方法精度更高,但在高分辨率、算力充足时,跟Detection-based方法相比还是有不小差距的。
究竟是哪些原因导致了IPR的性能不如Detection-based方法?
1. 对比Detection-based方法
如果想弄清楚IPR性能不足的原因,跟Detection-based方法进行仔细的对比是很有必要的。我们知道,IPR是作为Detection-based方法的一个“改进”方案提出来的,解决了Detection-based方法解码过程Argmax操作不可导的问题,还能避开特征图分辨率的量化误差,整体的流程是与Detection-based方法高度一致的:输入图片被网络编码成概率热图,然后通过一个解码操作得到预测坐标。
总的来说,区别主要体现在三个方面:
解码方式 监督方式 性能表现
解码方式上,Detection-based方法采用Argmax操作获取概率热图的最大值点坐标:
IPR采用了Soft-Argmax方式解码,先用Softmax对概率热图进行归一化,然后用求期望的方式得到预测坐标:
这里的Softmax用到了一个平滑参数来调节概率分布的形状,读过我ICCV 2021那篇解读文章的同学应该很清楚了,不了解的小伙伴也可以自行查阅。
监督方式上,Detection-based方法通过人工渲染高斯热图,逐像素地对网络的输出进行监督,一般采用MSE Loss:
IPR通过坐标值直接进行监督,采用L1或L2 Loss,而过去的实验结果显示L1 Loss效果更佳:
在RLE工作中,作者从极大似然估计的角度指出,L1或L2 Loss实际上是对数据分布的不同先验假设,L2 Loss是假设数据分布服从高斯分布,而L1 Loss是假设服从拉普拉斯分布。
但总体而言,IPR的监督方式是缺乏对概率分布的形状约束的,换句话说,IPR对概率热图的学习是隐式的,网络学成什么样完全自由发挥。
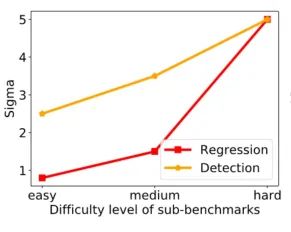
最后在性能表现上,Removing the bias of Integral Pose Regression对COCO数据集样本难易程度进行了精细地划分:
easy:画面出现11-17个点,遮挡率小于10%,或分辨率大于128px hard:画面出现1-5个点,遮挡率大于50%,或分辨率为32-64px medium:中间情况
通过对比可以发现,在easy样本上Detection-based方法表现优于IPR,medium样本上两种方法性能差不多,hard样本上IPR表现更好。
在PIPNet工作中有分析到,Detection-based方法由于受纹理信息影响严重,因此一旦遇到严重遮挡,响应区很容易丢失或偏移,而Regression-based方法则能更好地记住关键点之间的相对位置关系。
2. Heatmap的“局部性”
在理想情况下,一个训练良好的关键点定位模型,输出的关键点Heatmap上的响应区应该是像这样的:
其响应值集中在一块局部区域内,以外的地方响应几乎为0,响应值最大的地方对应了目标点,这非常合理,假如我们从人类标注的角度来理解,人是有一定几率犯错的,当我们在标注一个关键点时,也是以真实位置为中心的一个概率分布,距离越远,被人标注的概率越低,这里我姑且称之为“局部性”。
你是否想过,IPR和Detection-based方法生成的Heatmap相比,局部性有何差异?
首先让我们验证一下局部性是否真实存在。
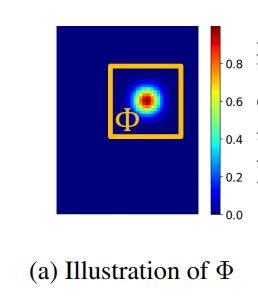
我们定义一个以关键点为中心,长宽均为2s+1的矩形区域,对该区域内的响应值求和记为A,通过改变s的大小缩放矩形区域,来观察A的变化趋势:
结果很明显,当s增大到一定程度时,A(s)几乎等于1,并且这个上升趋势在前期非常明显,这说明大量的高响应值集中在中心区域。
并且我们可以发现,IPR有着比Detection-based更强的局部性。换句话说,IPR的heatmap分布更加“尖锐”。
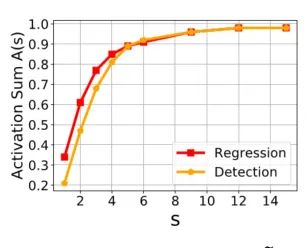
这个性质在所有难度的样本上均被观察到:
假如在不同难易程度的样本上进行对比,我们可以发现,越简单的样本上,这种局部性的差异越明显:
论文实验指出了这个现象,但并没有给出一个解释。ICCV 2021的RLE工作指出,数据是存在一个真实概率分布的,只不过我们不知道那是什么样,而我们的训练是建立在我们对概率分布的假设上的。
在使用L2 Loss时,实际上我们是假设数据服从高斯分布,概率密度函数为:
如果我们假设 为一个常量, 损失函数就会退化为
而在Detection-based方法中,我们更是直接逐像素地监督模型去学习高斯分布。
在使用L1 Loss,实际上我们则是假设数据服从拉普拉斯分布,密度函数为:
同样可以退化为 Loss:
更牛的是,RLE方法甚至把基于数据学到的真实分布进行了可视化:
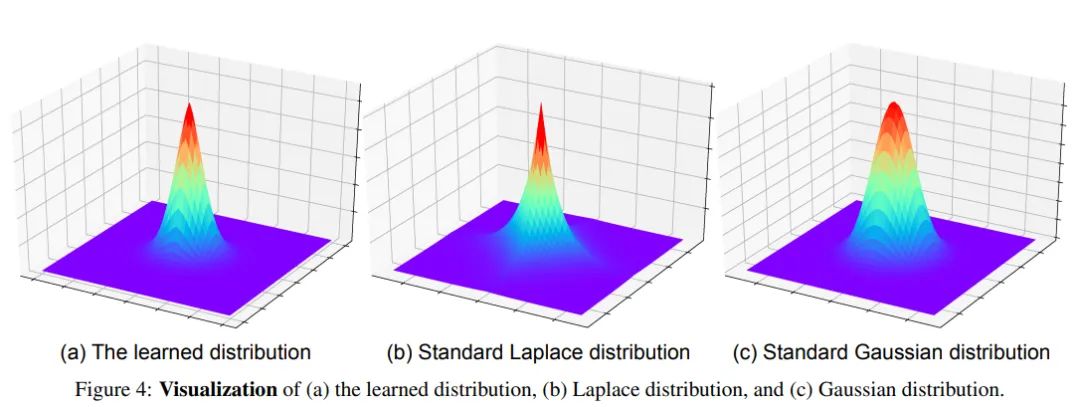
我们可以发现,在COCO数据集上关键点的真实分布实际上是介于拉普拉斯和高斯分布之间的,边缘比高斯分布更尖锐,比拉普拉斯分布更平滑。
基于以上内容,我们再回看论文的实验结果,会发现IPR更强的局部性是非常合理的,毕竟在监督时我们就是在隐式地学习拉普拉斯分布。
另一方面, 论文也对Detection-based方法监督时, 用不同的 渲染高斯热图进行了实验, 发现 时模型可以取得最优, 这应该说明, 在这个时候高斯分布跟数据真实分布之间的差异是 最小的:
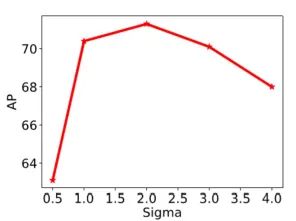
这里我其实在想,如果用基于RLE学到的数据真实分布来渲染Target Heatmap,是不是可以取得比当前基于高斯热图更好的性能,以及不同sigma下的拉普拉斯热图监督对Detection-based方法的影响,有空我也许会实验验证一下。
2. Heatmap的“形状约束”
在DSNT方法提出的论文里,作者就意识到了这种方法缺少对概率分布的形状约束。
简单来说,由于Soft-Argmax计算流程是对输出特征图进行Softmax归一化后,求期望作为坐标值,直接通过坐标值进行监督,因此只要期望值正确,loss就会降低,但一个期望值对应的分布形状是任意的,缺乏约束的结果就是网络的学习目标不确定,预测的Heatmap可能出现“多峰”、“扁平”、最大响应值点偏移等情况。
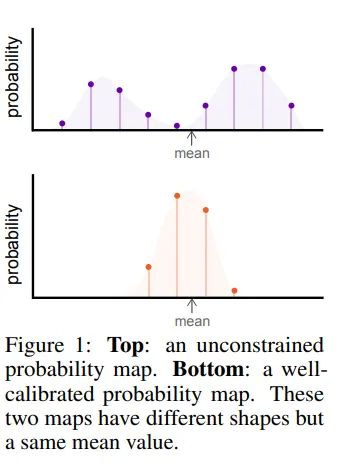
在Removing the bias of Integral Pose Regression工作的实验中也展现了,由于Softmax本身的性质,在响应值不够强时,会出现期望值跟最大响应值位置有偏差(白色点为计算得到的期望值):
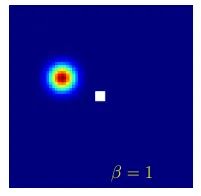
解决的方案也很简单,对分布的形状加上约束。
基于我们对概率密度函数的假设,我们可以在网络预测的Heatmap上加一个监督信息,论文作者延续了Detection-based方法的策略,直接用高斯热图进行监督:
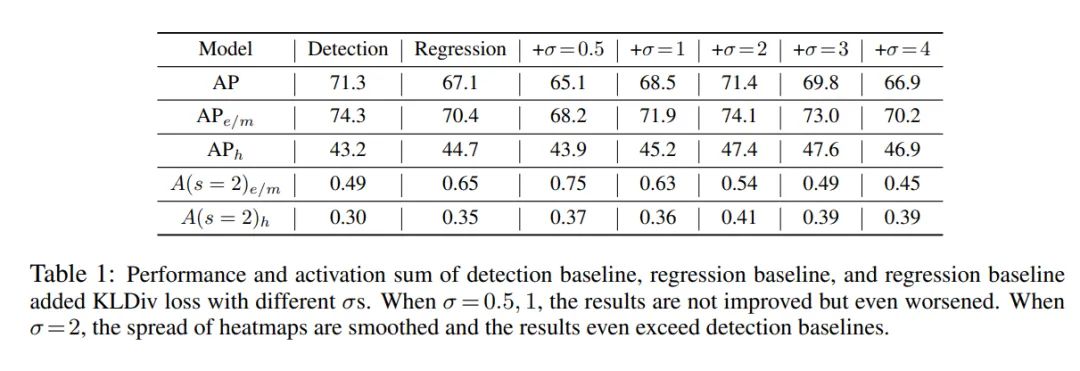
这张图我觉得其实可以仔细品一下。
首先从第一行可以看到,除了非常极端的和的情况性能下降,其他情况均有性能提升,可见增加形状约束是有效的。第二行在easy和medium样本上的表现也符合这一规律。
而第三行hard样本上的结果可以发现,除了极端小的,其余情况都得到了性能提升,即使是取到4这样一个相对较大的值。
我认为这是由于困难样本下模型预测的Heatmap本身就是非常不规则的,上面我们描述的各种问题在困难样本下也会更加严重,因此对它增加约束带来的收益也更加明显。这一点也从最后一行的数据得到了支持,可以看到增加约束后,hard所有情况下A(s=2)都比不加约束更大,这说明加约束之前的Heatmap更加“扁平扩散”,而导致性能降低,纯属监督信息过于“自信”,在遮挡严重的困难样本上如此自信地要求模型学,这根本办不到嘛。
在验证了形状约束的有效性后,我们自然应该想到,用高斯分布来约束真的是最好的?RLE作者的另一篇NeurIPS 2021的文章Sampling-Argmax对不同的约束方法进行了仔细的实验对比:

实验指出,通过人工假设分布进行监督方式约束形状,并不是最好的,而且一旦超参数选择不对还可能导致性能下降,Sampling-Argmax通过重参数技巧提出了一种不用预定义超参数的方式来监督形状。
3. 监督方式与梯度差异
对于Detection-based方法,梯度的形式非常直观:
会逐像素地监督Heatmap上的响应值。但Inegreal Regression的梯度就比较复杂了:
总的来说,梯度由左右两个因子相乘得到。左边是归一化后的Heatmap响应值,右边是每个响应像素位置相对于目标的位置差异。
这样的梯度形式带来的问题是:一方面,只要响应值偏小,很容易出现梯度消失;另一方面,如果目标点处于特征图的角落,梯度值的数量级就会偏大。这两个因子相乘组成的梯度值非常的不稳定,很难保证训练过程中loss稳定地下降。
在这个问题上,论文进行了更进一步的实验,枚举了四种响应区和GT的关系:
响应区很大,响应值接近随机 响应区小,跟GT相隔较远 响应区小,处于特征图角落 响应区小,跟GT相隔很近
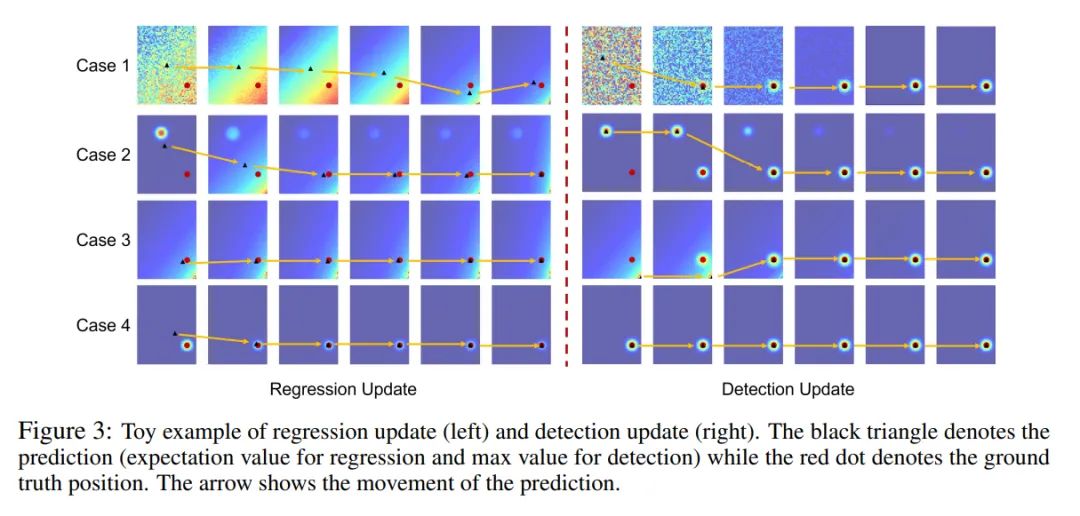
通过对比可以明显看到,Detection-based方法受益于明确的监督信息和良好的梯度,能很快学出正确且形状良好的响应区。而IPR则很容易出现,最终学到的响应区虽然期望值跟GT相等,但响应区却不在期望值对应的位置。
梯度形式的差异使得IPR的训练过程比起Detection-based方法艰难得多。
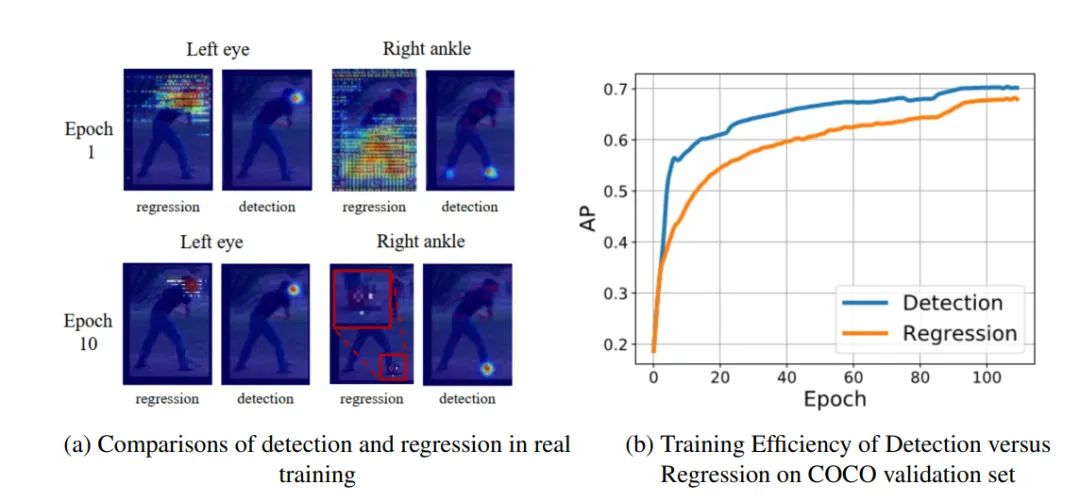
同时值得注意的是,这个左眼和右脚踝的实验中,左眼是一个被完全遮挡的点,可以看成一种hard case,IPR学到的Heatmap形状相当散乱,并且学习缓慢;Detection-based方法尽管学到的Heatmap也存在扩散问题,但还是能更快地定位。这个不难理解,当感受野足够大时,即使被遮挡,人眼这种位置非常明确的关键点是比较容易学习的。
反观右脚踝的情况,由于位置非常清晰属于easy case,IPR学到的Heatmap相当尖锐,响应值完全集中在几个像素上,但红框放大可以看到,出现了“双峰”。
还有一个有意思的现象是,在训练一个epoch的Detection-based结果里,左右脚踝同时出现了响应区,这也是这种方法的特点,很容易受纹理信息影响,在一些如遮挡严重的情况下,由于纹理信息缺失,Detection-based方法的定位会很容易不准。
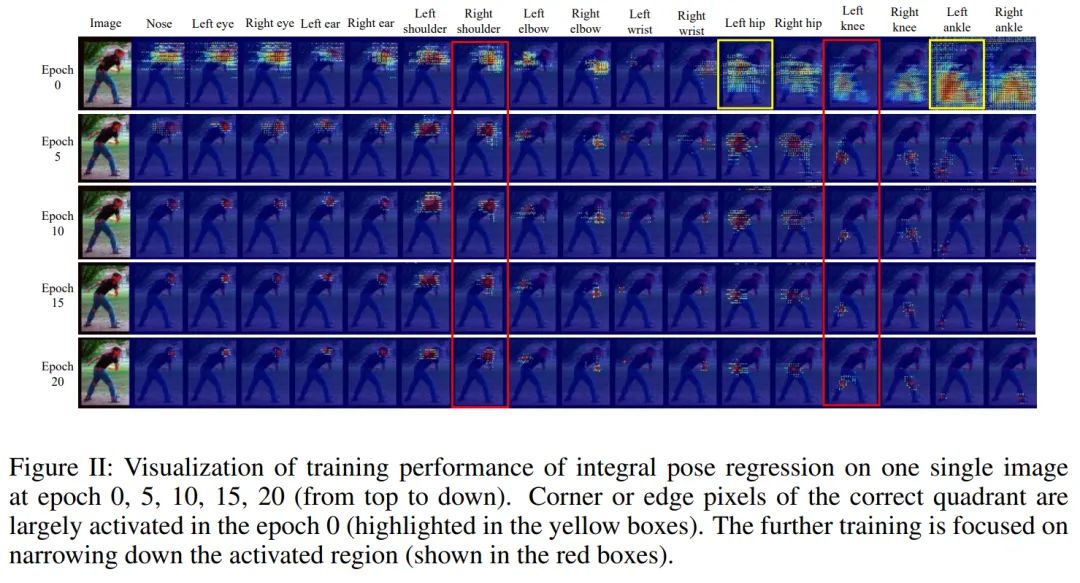
通过更详细的实验对比可以看到,在IPR训练初期,很大的一片区域都被激活了,而随后的训练重心都集中在收缩响应范围。
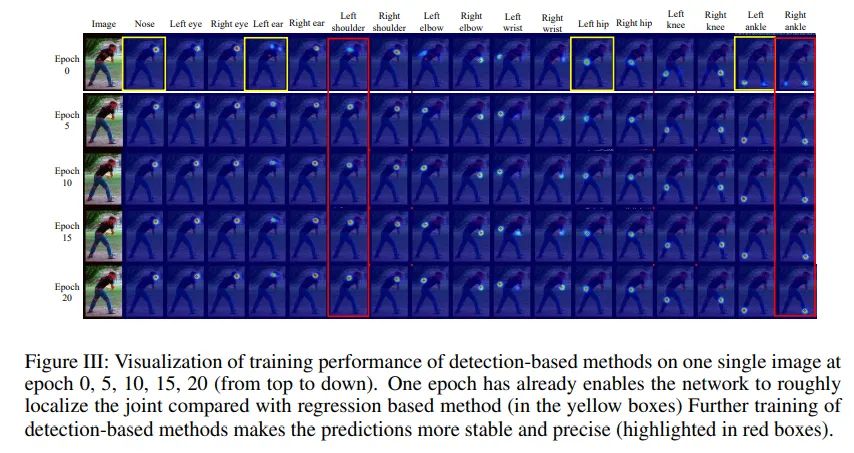
而Detection-based方法在训练初期,能很快定位到正确的响应区域,接下来的时间主要学习的是让响应区的概率分布形状更稳定,或通过语义信息来消除纹理相似性带来的误判。
这几个实验清晰地告诉我们,一个好的监督方式对学习效率的影响是非常重要的。
4. 总结
结合目前我读过的所有论文,目前我认为Integral Pose Regression方法的性能劣势主要来源于四个方面:
Softmax性质引入的偏差 数据真实分布与人工预定义的简单分布存在差异 缺乏概率分布性质约束导致的学习目标不明确 梯度形式不稳定导致学习效率低下
针对这四个方面也各自涌现了一批优秀的工作来解决问题,使得Integral Pose Regression方法在追赶Detection-based方法的道路上一路高歌猛进,从去年开始重铸Regression荣光,已经陆续出现了Regerssion大于Heatmap的征兆,我对此也是满怀期待,毕竟Detection方法昂贵的计算量和繁琐的后处理都是关键点定位算法在落地时的严重阻碍。希望通过本文能让大家对Soft-Argmax这个方法有更全面和深入的理解。
能读到这里已经是本文的优质读者了,如果你觉得对你有帮助,希望能给我点一个赞。感谢相伴~
公众号后台回复“CVPR 2022”获取论文合集打包下载~

觉得有用麻烦给个在看啦~ 