
OCR光学字符识别方法汇总(附开源代码)
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
本文转载自AI算法修炼营
文本是人类最重要的信息来源之一,自然场景中充满了形形色色的文字符号。光学字符识别(OCR)相信大家都不陌生,就是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
工业场景的图像文字识别更加复杂,出现在很多不同的场合。例如医药品包装上的文字、各种钢制部件上的文字、容器表面的喷涂文字、商店标志上的个性文字等。在这样的图像中,字符部分可能出现在弯曲阵列、曲面异形、斜率分布、皱纹变形、不完整等各种形式中,并且与标准字符的特征大不相同,因此难以检测和识别图像字符。
对于文字识别,实际中一般首先需要通过文字检测定位文字在图像中的区域,然后提取区域的序列特征,在此基础上进行专门的字符识别。但是随着CV发展,也出现很多端到端的End2End OCR。
传统的OCR技术通常使用opencv算法库,通过图像处理和统计机器学习方法从图像中提取文本信息,包括二值化、噪声滤波、相关域分析、AdaBoost等。传统的OCR技术根据处理方法可分为三个阶段:图像准备、文本识别和后处理。
一、图像准备预处理:
文字区域定位:连通区域分析、MSER
文字矫正:旋转、仿射变换
文字分割:二值化、过滤噪声
二、文字识别:
分类器识别:逻辑回归、SVM、Adaboost
三、后处理:规则、语言模型(HMM等)
针对简单场景下的图片,传统OCR已经取得了很好的识别效果。传统方法是针对特定场景的图像进行建模的,一旦跳出当前场景,模型就会失效。随着近些年深度学习技术的迅速发展,基于深度学习的OCR技术也已逐渐成熟,能够灵活应对不同场景。
目前,基于深度学习的场景文字识别主要包括两种方法,第一种是分为文字检测和文字识别两个阶段;第二种则是通过端对端的模型一次性完成文字的检测和识别。
2.1 阶段一:文字检测
文字检测定位图片中的文本区域,而Detection定位精度直接影响后续Recognition结果。

图1.1
如图1.1中,红框代表“LAN”字符ground truth(GT),绿色框代表detection box。在GT与detection box有相同IoU的情况下,识别结果差异巨大。所以Detection对后续Recognition影响非常大!
目前已经有很多文字检测方法,包括:EAST/CTPN/SegLink/PixelLink/TextBoxes/TextBoxes++/TextSnake/MSR/...,具体来说:
2.1.1 CTPN [1]
CTPN是ECCV 2016提出的一种文字检测算法,由Faster RCNN改进而来,结合了CNN与LSTM深度网络,其支持任意尺寸的图像输入,并能够直接在卷积层中定位文本行。
CTPN由检测小尺度文本框、循环连接文本框、文本行边细化三个部分组成,具体实现流程为:
1、使用VGG16网络提取特征,得到conv5_3的特征图;
2、在所得特征图上使用3*3滑动窗口进行滑动,得到相应的特征向量;
3、将所得特征向量输入BLSTM,学习序列特征,然后连接一个全连接FC层;
最后输出层输出结果。
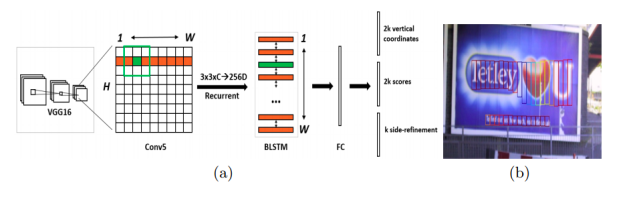
CTPN是基于Anchor的算法,在检测横向分布的文字时能得到较好的效果。此外,BLSTM的加入也进一步提高了其检测能力。
2.1.2 TextBoxes/TextBoxes++ [2,3]
TextBoxes和TextBoxes++模型都来自华中科技大学的白翔老师团队,其中TextBoxes是改进版的SSD,而TextBoxes++则是在前者的基础上继续扩展。
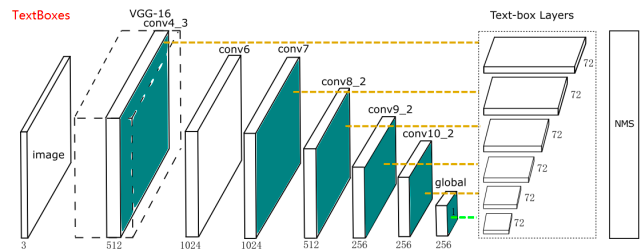
TextBoxes共有28层卷积,前13层来自于VGG-16(conv_1到conv4_3),后接9个额外的卷积层,最后是包含6个卷积层的多重输出层,被称为text-box layers,分别和前面的9个卷积层相连。由于这些default box都是细长型的,使得box在水平方向密集在垂直方向上稀疏,从而导致该模型对水平方向上的文字检测结果较好。
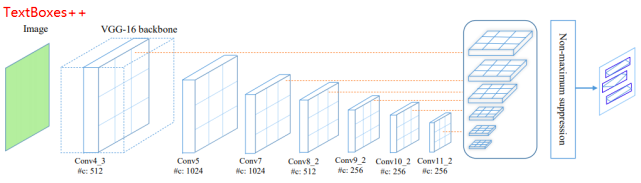
TextBoxes++保留了TextBoxes的基本框架,只是对卷积层的组成进行了略微调整,同时调整了default box的纵横比和输出阶段的卷积核大小,使得模型能够检测任意方向的文字。
2.1.3 EAST [4]
EAST算法是一个高效且准确的文字检测算法,仅包括全卷积网络检测文本行候选框和NMS算法过滤冗余候选框两个步骤。
其网络结构结合了HyperNet和U-shape思想,由三部分组成:
特征提取:使用PVANet/VGG16提取四个级别的特征图;
特征合并:使用上采样、串联、卷积等操作得到合并的特征图;
输出层:输出单通道的分数特征图和多通道的几何特征图。
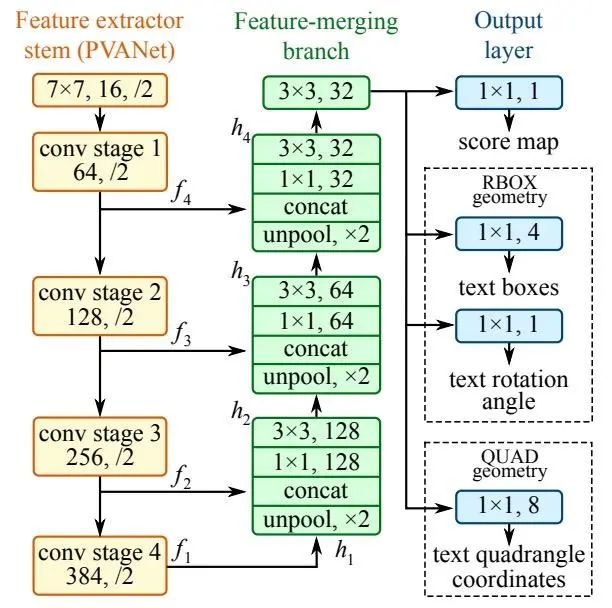
EAST算法借助其独特的结构和简练的pipline,可以检测不同方向、不同尺寸的文字且运行速度快,效率高。
2.2 阶段二:文字识别
通过文字检测对图片中的文字区域进行定位后,还需要对区域内的文字进行识别。针对文字识别部分目前存在几种架构,下面将分别展开介绍。
3.2.1 CNN + softmax [5]
此方法主要用于街牌号识别,对每个字符识别的架构为:先使用卷积网络提取特征,然后使用N+1个softmax分类器对每个字符进行分类。具体流程如下图所示:
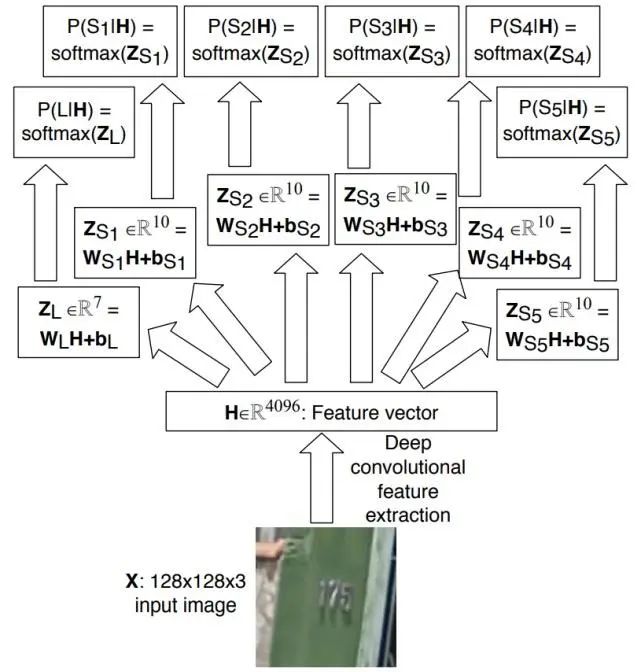
使用此方法可以处理不定长的简单文字序列(如字符和字母),但是对较长的字符序列识别效果不佳。
3.2.2 CNN + RNN + attention [6]
本方法是基于视觉注意力的文字识别算法。主要分为以下三步:
模型首先在输入图片上运行滑动CNN以提取特征;
将所得特征序列输入到推叠在CNN顶部的LSTM进行特征序列的编码;
使用注意力模型进行解码,并输出标签序列。
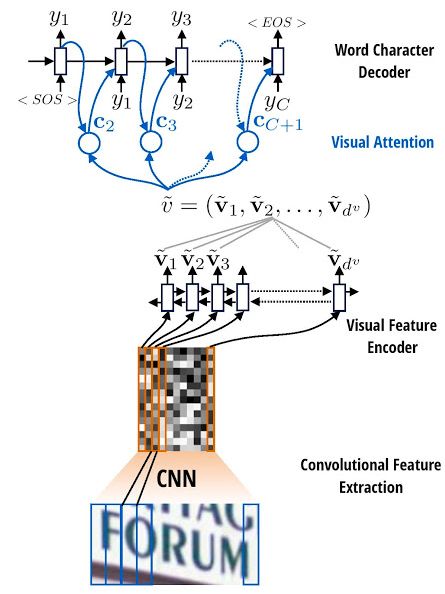
本方法采用的attention模型允许解码器在每一步的解码过程中,将编码器的隐藏状态通过加权平均,计算可变的上下文向量,因此可以时刻读取最相关的信息,而不必完全依赖于上一时刻的隐藏状态。
3.2.3 CNN + stacked CNN + CTC [7]
上一节中提到的CNN + RNN + attention方法不可避免的使用到RNN架构,RNN可以有效的学习上下文信息并捕获长期依赖关系,但其庞大的递归网络计算量和梯度消失/爆炸的问题导致RNN很难训练。基于此,有研究人员提出使用CNN与CTC结合的卷积网络生成标签序列,没有任何重复连接。
这种方法的整个网络架构如下图所示,分为三个部分:
注意特征编码器:提取图片中文字区域的特征向量,并生成特征序列;
卷积序列建模:将特征序列转换为二维特征图输入CNN,获取序列中的上下文关系;
CTC:获得最后的标签序列。
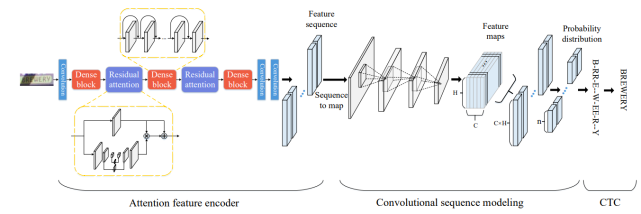
本方法基于CNN算法,相比RNN节省了内存空间,且通过卷积的并行运算提高了运算速度。
3.2.4 特定的弯曲文本行识别
对于特定的弯曲文本行识别,早在CVPR2016就已经有了相关paper:
Robust Scene Text Recognition with Automatic Rectification. CVPR2016.
论文地址:arxiv.org/abs/1603.03915
对于弯曲不规则文本,如果按照之前的识别方法,直接将整个文本区域图像强行送入CNN+RNN,由于有大量的无效区域会导致识别效果很差。所以这篇文章提出一种通过STN网络学习变换参数,将Rectified Image对应的特征送入后续RNN中识别。
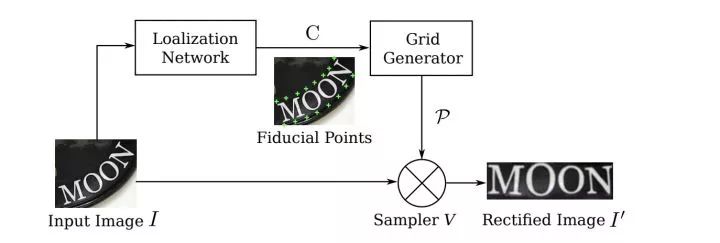
其中Spatial Transformer Network(STN)核心就是将传统二维图像变换(如旋转/缩放/仿射等)End2End融入到网络中。具体二维图像变换知识请翻阅:Homograph单应性从传统算法到深度学习:https://zhuanlan.zhihu.com/p/74597564
Scene Text Recognition from Two-Dimensional Perspective. AAAI2018.
该篇文章于MEGVII 2019年提出。首先在文字识别网络中加入语义分割分支,获取每个字符的相对位置。
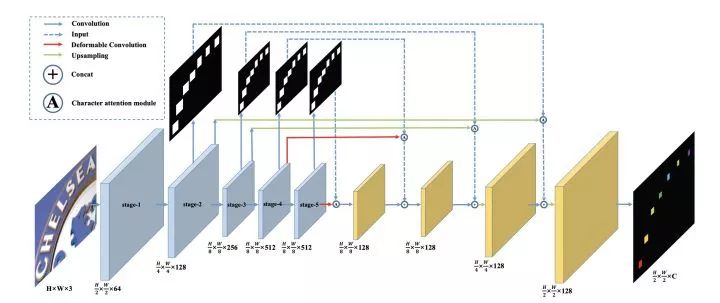
其次,在获取每个字符位置后对字符进行分类,获得文字识别信息。该方法采用分类解决识别问题,并没有像传统方法那样使用RNN。

除此之外,在文章中还是使用了Deformable Convolution可变形卷积。相比传统3x3卷积,可变形卷积可以提取文字区域不同形状的特征。

3.3 端对端文字识别
使用文字检测加文字识别两步法虽然可以实现场景文字的识别,但融合两个步骤的结果时仍需使用大量的手工知识,且会增加时间的消耗,而端对端文字识别能够同时完成检测和识别任务,极大的提高了文字识别的实时性。
3.3.1 STN-ORC [8]
STN-OCR使用单个深度神经网络,以半监督学习方式从自然图像中检测和识别文本。网络实现流程如下图所示,总体分为两个部分:
定位网络:针对输入图像预测N个变换矩阵,相应的输出N个文本区域,最后借助双线性差值提取相应区域;
识别网络:使用N个提取的文本图像进行文本识别。
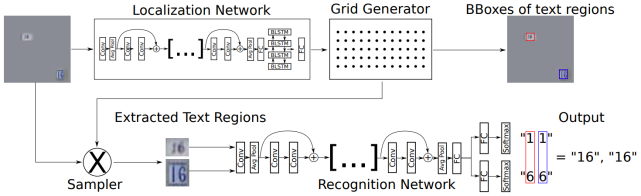
本方法的训练集不需要bbox标注,使用友好性较高;但目前此模型还不能完全检测出图像中任意位置的文本,需要在后期继续调整。
3.3.2 FOTS [9]
FOTS是一个快速的端对端的文字检测与识别框架,通过共享训练特征、互补监督的方法减少了特征提取所需的时间,从而加快了整体的速度。其整体结构如图所示:

卷积共享:从输入图象中提取特征,并将底层和高层的特征进行融合;
文本检测:通过转化共享特征,输出每像素的文本预测;
ROIRotate:将有角度的文本块,通过仿射变换转化为正常的轴对齐的本文块;
文本识别:使用ROIRotate转换的区域特征来得到文本标签。
FOTS是一个将检测和识别集成化的框架,具有速度快、精度高、支持多角度等优点,减少了其他模型带来的文本遗漏、误识别等问题。
提供轻量的backone检测模型psenet(8.5M),crnn_lstm_lite(9.5M) 和行文本方向分类网络(1.5M)
任意方向文字检测,识别时判断行文本方向
crnn\crnn_lite lstm\dense识别(ocr-dense和ocr-lstm是搬运chineseocr的)
支持竖排文本识别
ncnn 实现 (支持lstm)
mnn 实现





Ubuntu 18.04
Python 3.6.9
Pytorch 1.5.0.dev20200227+cpu
nihui 大佬实现的 crnn_lstm 推理
升级 crnn_lite_lstm_dw.pth 模型 crnn_lite_lstm_dw_v2.pth , 精度更高
提供竖排文字样例以及字体库(旋转 90 度的字体)
参考文献:
[1] Tian Z et al. Detecting text in natural image with connectionist text proposal network[C]//European conference on computer vision. Springer, Cham, 2016.
[2] Liao M et al. Textboxes: A fast text detector with a single deep neural network [C]//Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[3] Liao M et al. Textboxes++: A single-shot oriented scene text detector[J]. IEEE transactions on image processing, 2018.
[4] Zhou X et al. EAST: an efficient and accurate scene text detector[C]// Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.
[5] Goodfellow I J et al. Multi-digit number recognition from street view imagery using deep convolutional neural networks[J]. 2013.
[6] Deng Y et al. Image-to-markup generation with coarse-to-fine attention[C]// Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
[7] Gao Y et al. Reading scene text with fully convolutional sequence modeling[J]. Neurocomputing, 2019.
[8] Bartz C et al. STN-OCR: A single neural network for text detection and text recognition[J]. arXiv preprint arXiv:1707.08831, 2017.
[9] Liu X et al. Fots: Fast oriented text spotting with a unified network [C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
推荐阅读
(点击标题可跳转阅读)
最详细、最完整的相机标定讲解
深度学习+机器视觉=下一代检测
视觉检测系统最经典的结构你了解吗?
机器视觉技术的十大应用领域
工业相机和普通相机究竟有什么不同?
基于机器视觉和深度学习的智能缺陷检测
波士顿等移动机器人的视觉算法解析
2020年37个人工智能技术发展趋势
机器视觉的光源选型及打光方案分析
光学三维测量技术及应用
国内80%搞机器视觉的工程师,走的路子是错的!
视觉+机器人,如何实现连接器的自动装配?
机器视觉技术发展的五大趋势
搞懂机器视觉基本内容,这份PPT就够了
3D视觉技术在机器人抓取作业中的应用实例
基于机器视觉的粗糙度检测方案
机器视觉常用图像软件对比及分析
工业相机编程流程及SDK接口使用汇总
本文仅做学术分享,如有侵权,请联系删文。