
OCR光学字符识别方法汇总
作者丨吴建明wujianming@知乎
编辑丨计算机视觉与机器学习
链接丨https://zhuanlan.zhihu.com/p/121074333
工业场景的图像文字识别更加复杂,出现在很多不同的场合。例如医药品包装上的文字、各种钢制部件上的文字、容器表面的喷涂文字、商店标志上的个性文字等。在这样的图像中,字符部分可能出现在弯曲阵列、曲面异形、斜率分布、皱纹变形、不完整等各种形式中,并且与标准字符的特征大不相同,因此难以检测和识别图像字符。
对于文字识别,实际中一般首先需要通过文字检测定位文字在图像中的区域,然后提取区域的序列特征,在此基础上进行专门的字符识别。但是随着CV发展,也出现很多端到端的End2End OCR。
文字区域定位:连通区域分析、MSER .文字矫正:旋转、仿射变换 文字分割:二值化、过滤噪声
分类器识别:逻辑回归、SVM、Adaboost

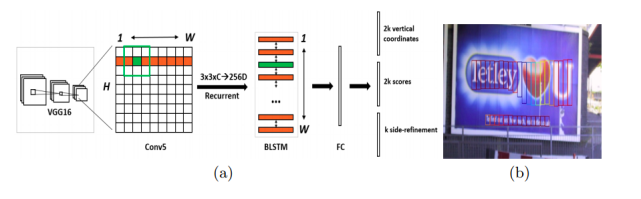
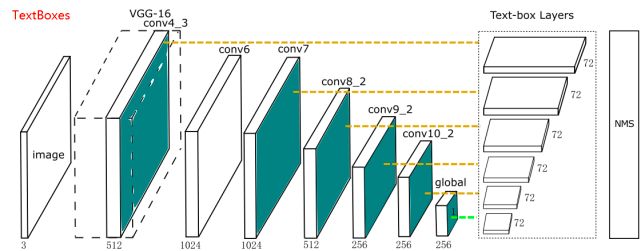
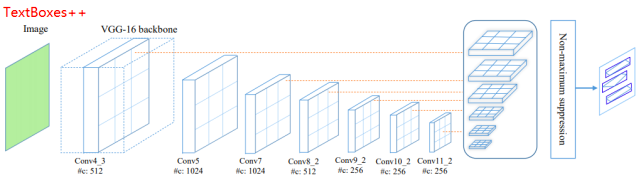
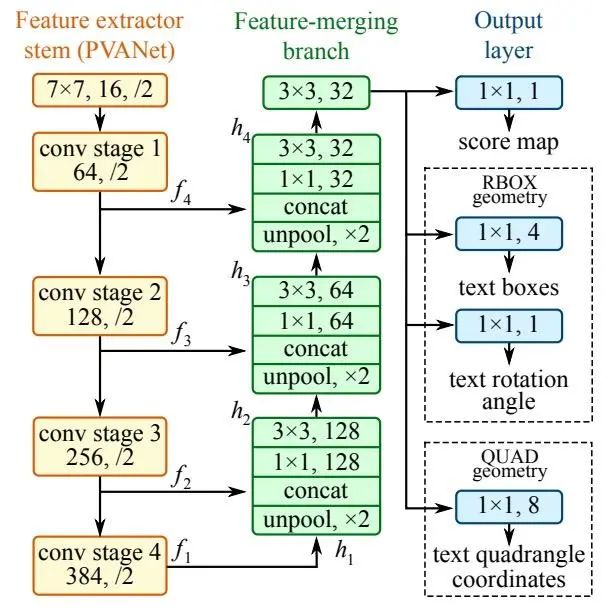
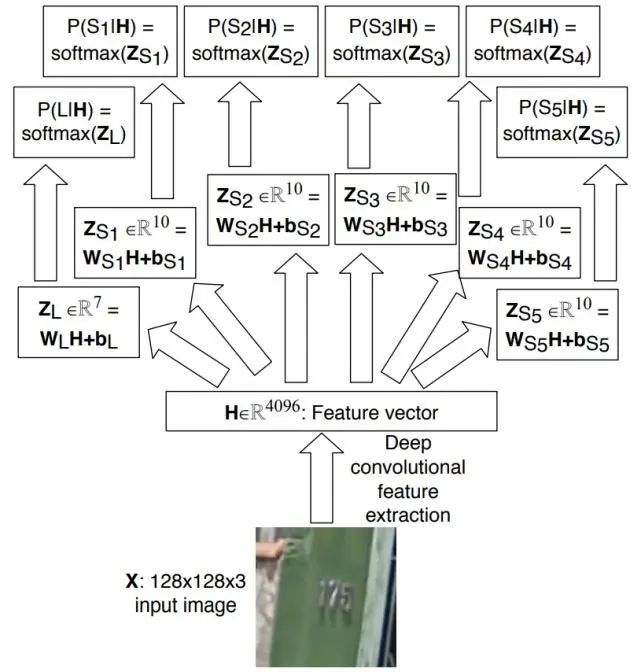
Robust Scene Text Recognition with Automatic Rectification. CVPR2016.
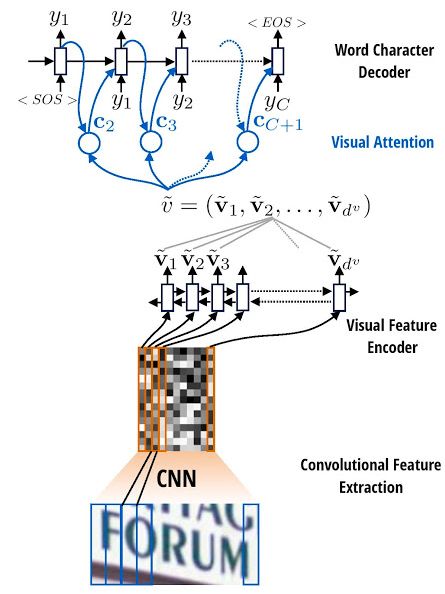
Scene Text Recognition from Two-Dimensional Perspective. AAAI2018.


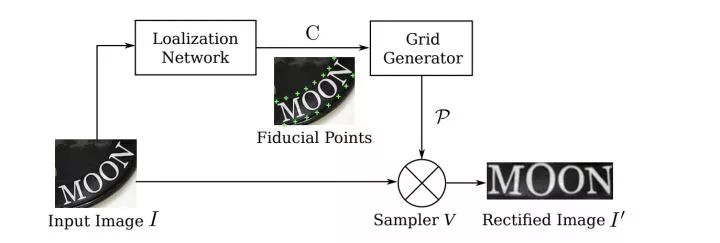
定位网络:针对输入图像预测N个变换矩阵,相应的输出N个文本区域,最后借助双线性差值提取相应区域; 识别网络:使用N个提取的文本图像进行文本识别。 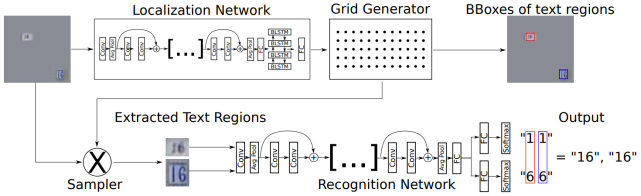

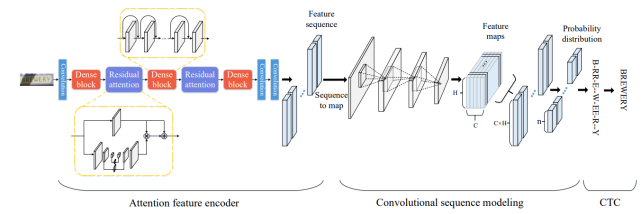
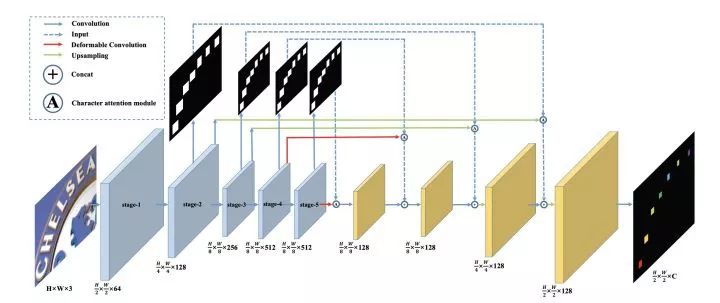
卷积共享:从输入图象中提取特征,并将底层和高层的特征进行融合; 文本检测:通过转化共享特征,输出每像素的文本预测; ROIRotate:将有角度的文本块,通过仿射变换转化为正常的轴对齐的本文块; 文本识别:使用ROIRotate转换的区域特征来得到文本标签。
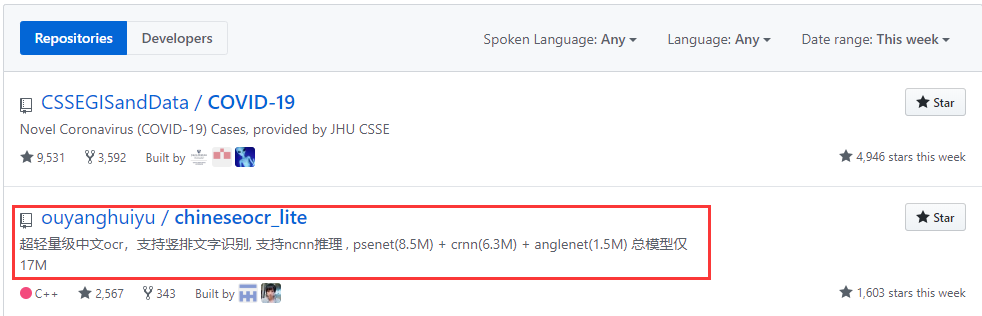
提供轻量的backone检测模型psenet(8.5M),crnn_lstm_lite(9.5M) 和行文本方向分类网络(1.5M) 任意方向文字检测,识别时判断行文本方向 crnn\crnn_lite lstm\dense识别(ocr-dense和ocr-lstm是搬运chineseocr的) 支持竖排文本识别 ncnn 实现 (支持lstm) mnn 实现





Ubuntu 18.04 Python 3.6.9 Pytorch 1.5.0.dev20200227+cpu
nihui 大佬实现的 crnn_lstm 推理 升级 crnn_lite_lstm_dw.pth 模型 crnn_lite_lstm_dw_v2.pth , 精度更高 提供竖排文字样例以及字体库(旋转 90 度的字体)
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》
评论