
【CV】Python+OpenCV模板匹配实现机器视觉
机器视觉系统是通过机器视觉产品(即图像摄取装置,分CMOS和CCD两种)将被摄取目标转换成图像信号,传送给专用的图像处理系统,得到被摄目标的形态信息,根据像素分布和亮度、颜色等信息,转变成数字化信号;图像系统对这些信号进行各种运算来抽取目标的特征,进而根据判别的结果来控制现场的设备动作。

模板匹配是一种最原始、最基本的模式识别方法,研究某一特定对象物的图案位于图像的什么地方,进而识别对象物,这就是一个匹配问题。它是图像处理中最基本、最常用的匹配方法。模板匹配具有自身的局限性,主要表现在它只能进行平行移动,若原图像中的匹配目标发生旋转或大小变化,该算法无效。
简单来说,模板匹配就是在整个图像区域发现与给定子图像匹配的小块区域。
工作原理:在带检测图像上,从左到右,从上向下计算模板图像与重叠子图像的匹配度,匹配程度越大,两者相同的可能性越大。

目标图.jpg

模板图.jpg
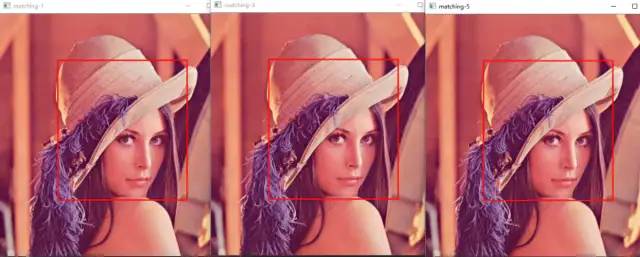
模板匹配.jpg
上一篇文章讲了图像纠偏:
纠偏之后如果在没有OCR的条件下,就可以使用模板匹配进行自动识别。
下面我们用模板识别的方法来自动提取信用卡的卡号。

credit_card_01.png(目标图)
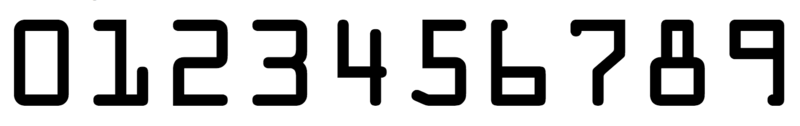
ocr_a_reference.png(模板图)
No BB,show code:
# 导入工具包from imutils import contoursimport numpy as npimport argparseimport cv2import myutils
其中 myutils 是自己写的工具包:
myutils .py
import cv2def sort_contours(cnts, method="left-to-right"):reverse = Falsei = 0if method == "right-to-left" or method == "bottom-to-top":reverse = Trueif method == "top-to-bottom" or method == "bottom-to-top":i = 1boundingBoxes = [cv2.boundingRect(c) for c in cnts] #用一个最小的矩形,把找到的形状包起来x,y,h,w(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),key=lambda b: b[1][i], reverse=reverse))return cnts, boundingBoxesdef resize(image, width=None, height=None, inter=cv2.INTER_AREA):dim = None(h, w) = image.shape[:2]if width is None and height is None:return imageif width is None:r = height / float(h)dim = (int(w * r), height)else:r = width / float(w)dim = (width, int(h * r))resized = cv2.resize(image, dim, interpolation=inter)return resized
# 设置参数ap = argparse.ArgumentParser()ap.add_argument("-i", "--image", required=True,help="path to input image")ap.add_argument("-t", "--template", required=True,help="path to template OCR-A image")args = vars(ap.parse_args())
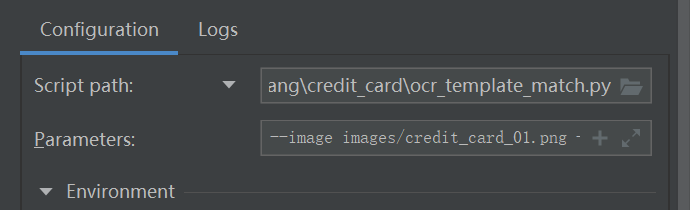
在运行时需要配置输入的目标图像和模板图像,在pycharm中的Edit Configurations中进行配置。
配置代码为:
--image
images/credit_card_01.png
--template
images/ocr_a_reference.png
# 利用信用卡第一的数字来指定信用卡类型FIRST_NUMBER = {"3": "American Express","4": "Visa","5": "MasterCard","6": "Discover Card"}
# 绘图展示def cv_show(name,img):cv2.imshow(name, img)cv2.waitKey(0)cv2.destroyAllWindows()
在做好所有配置,写好所有函数之后,开始我们模板匹配的操作:
首先处理模板,把每个数字的最小矩形框找到:
# 读取一个模板图像img = cv2.imread(args["template"])# 展示模板cv_show('img',img)

ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)cv_show('ref',ref)

ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]cv_show('ref',ref)

refCnts, hierarchy = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cv2.drawContours(img,refCnts,-1,(0,0,255),3)cv_show('img',img)

# 打印有多少个轮廓print (np.array(refCnts).shape)refCnts = myutils.sort_contours(refCnts, method="left-to-right")[0] #排序,从左到右,从上到下
对找到的每个矩形框按顺序匹配上0-9的数字:
digits = {}# 遍历每一个轮廓for (i, c) in enumerate(refCnts):# 计算外接矩形并且resize成合适大小y, w, h) = cv2.boundingRect(c)roi = ref[y:y + h, x:x + w]roi = cv2.resize(roi, (57, 88))# 每一个数字对应每一个模板= roi
下面开始处理目标图像,通过对目标图片进行滤波、灰度、Sobel算子边缘检测、自适应阈值处理、闭运算、膨胀、腐蚀、轮廓检测等一系列形态学操作。利用信用卡号的特定长宽比锁定卡号位置并截取出来:
# 初始化卷积核rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))#读取输入图像,预处理image = cv2.imread(args["image"])cv_show('image',image)

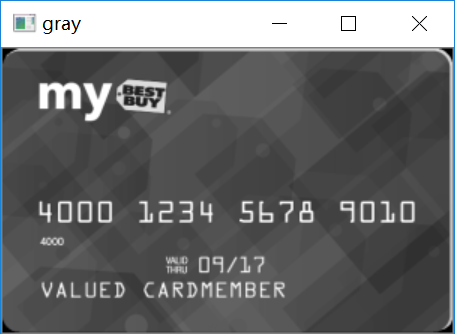
image = myutils.resize(image, width=300)#灰度图gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)cv_show('gray',gray)
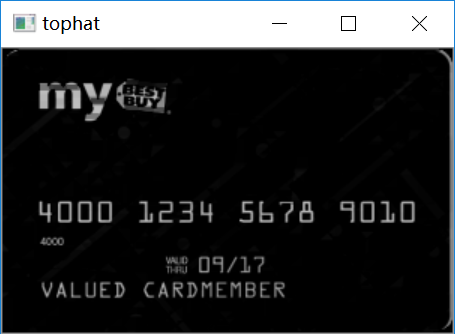
#礼帽操作,突出更明亮的区域tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)cv_show('tophat',tophat)
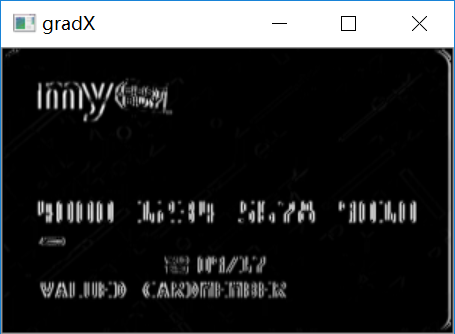
#sobel算子边缘检测gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, #ksize=-1相当于用3*3的ksize=-1)gradX = np.absolute(gradX)(minVal, maxVal) = (np.min(gradX), np.max(gradX))#归一化gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))gradX = gradX.astype("uint8")print (np.array(gradX).shape)cv_show('gradX',gradX)
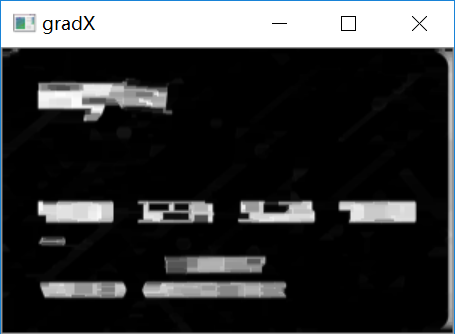
#通过闭操作(先膨胀,再腐蚀)将数字连在一起gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)cv_show('gradX',gradX)#THRESH_OTSU会自动寻找合适的阈值,适合双峰,需把阈值参数设置为0thresh = cv2.threshold(gradX, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]cv_show('thresh',thresh)
#再来一个闭操作thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel) #再来一个闭操作cv_show('thresh',thresh)
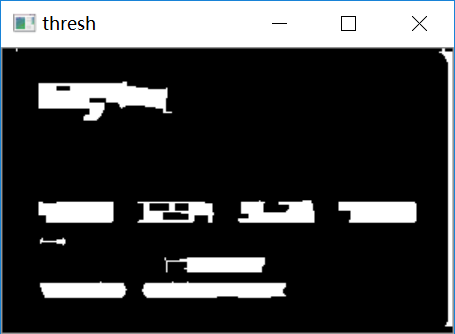
# 计算轮廓threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)cnts = threshCntscur_img = image.copy()cv2.drawContours(cur_img,cnts,-1,(0,0,255),3)cv_show('img',cur_img)
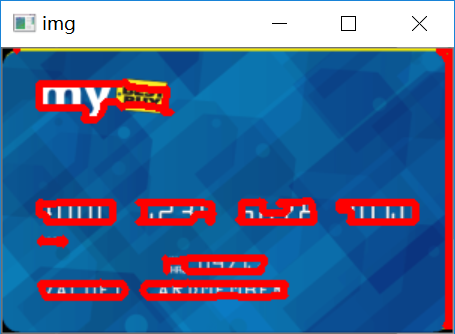
最后一步,遍历所有轮廓,以数字块特有的长宽比锁定数据区域,再跟模板做匹配,得到每一个数字块的值,并在信用卡上显示出来:
locs = []for (i, c) in enumerate(cnts):# 计算矩形(x, y, w, h) = cv2.boundingRect(c)ar = w / float(h)if ar > 2.5 and ar < 4.0:if (w > 40 and w < 55) and (h > 10 and h < 20):locs.append((x, y, w, h))locs = sorted(locs, key=lambda x:x[0])output = []for (i, (gX, gY, gW, gH)) in enumerate(locs):# initialize the list of group digitsgroupOutput = []group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]cv_show('group',group)group = cv2.threshold(group, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]cv_show('group',group)digitCnts,hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)digitCnts = contours.sort_contours(digitCnts,method="left-to-right")[0]for c in digitCnts:(x, y, w, h) = cv2.boundingRect(c)roi = group[y:y + h, x:x + w]roi = cv2.resize(roi, (57, 88))cv_show('roi',roi)scores = []for (digit, digitROI) in digits.items():result = cv2.matchTemplate(roi, digitROI,cv2.TM_CCOEFF)(_, score, _, _) = cv2.minMaxLoc(result)scores.append(score)groupOutput.append(str(np.argmax(scores)))cv2.rectangle(image, (gX - 5, gY - 5),(gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)cv2.putText(image, "".join(groupOutput), (gX, gY - 15),cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)output.extend(groupOutput)
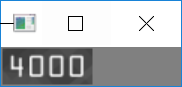

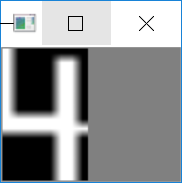


最后把匹配出来的数字进行输出,提交给用户。
# 打印结果print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))print("Credit Card #: {}".format("".join(output)))cv2.imshow("Image", image)cv2.waitKey(0)
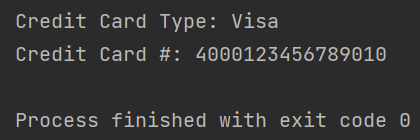
本文为大家分享了机器视觉检测与识别信用卡卡号的一种思路,首先如果照片拍得有噪声,可以先对目标图像进行常规的预处理像高斯滤波、中值滤波去除噪声。接着利用需要识别目标本身特定的长宽比锁定目标具体位置。而获取图像轮廓边缘进而求得长宽比的方法多种多样,本次分享利用Sobel算子进行边缘检测然后通过膨胀、腐蚀等形态学操作去除多余轮廓和毛刺。最后进行轮廓检测,获取每个轮廓的坐标信息。此时,我们可以利用坐标信息转换为轮廓的长宽比信息。如此,从目标图片截取需要识别图片的问题就迎刃而解了。
成功截取图片后我们的思路是:将每一个数字分割,单独存放,为后续进行的模板匹配识别提供方便。可以仿照上面截取目标图片的大致思路,经过预处理和进一步形态学处理后检测轮廓。同样利用长宽比和检测出来的坐标信息分割出单个字符并保存。
经过上面两步,我们已经获得了单个数字的图片,此时我们利用已经准备好的模板库,与之进行特征值运算比较。与数字图片相似度最高的模板标签即为模板识别的输出结果。按照相同的方法识别余下字符,并将他们打印出来,这就是本次项目所实现的效果,将目标图片的信用卡号识别并打印出来。
这个思路同样可以用于车牌的自动识别,电表读数的自动识别。
完美。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: