
2021年9月快手,社科广告算法面试题分享!
文 | 七月在线
编 | 小七


目录
FIGHTING
问题1:l1,l2公式,区别
问题2:二分查找
问题3:翻转数组二分查找
问题4:决策树都用什么指标,信息增益是什么
问题5:auc含义公式
问题1:l1,l2公式,区别
L1/L2的区别
L1是模型各个参数的绝对值之和。
L2是模型各个参数的平方和的开方值。
L1会趋向于产生少量的特征,而其他的特征都是0。
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0。
L1的作用是为了矩阵稀疏化。假设的是模型的参数取值满足拉普拉斯分布。
L2的作用是为了使模型更平滑,得到更好的泛化能力。假设的是参数是满足高斯分布。
问题2:二分查找
leetcode704,搜索区间两端闭, while条件带等号,mid要加减1。
代码如下︰
时间复杂度:o(logN)。
空间复杂度︰o(1)。
问题3:翻转数组二分查找
该题为leetcode153题:数组不包含重复元素,并且只要当前的区间长度不为 1,pivot 就不会与 high 重合;而如果当前的区间长度为 1,这说明我们已经可以结束二分查找了。因此不会存在nums [ pivot ] = nums [ high ] 的情况。
当二分查找结束时,我们就得到了最小值所在的位置。
代码如下:
问题4:决策树都用什么指标,信息增益是什么
信息增益,信息增益率,基尼指数
信息增益是以某特征划分数据集前后的熵的差值,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。
问题5:auc含义公式
AUC是ROC曲线下面的面积,AUC可以解读为从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。AUC反映的是分类器对样本的排序能力。AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。



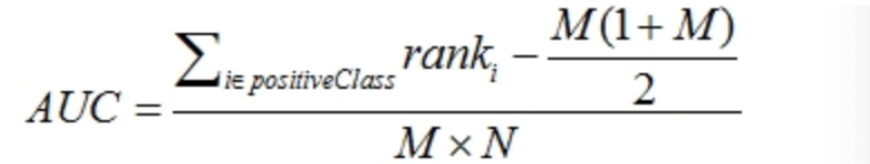
— 推荐阅读 — 最新大厂面试题

AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐