
【数据竞赛】2020腾讯广告算法大赛冠军方案分享及代码


用户出现的总次数和天数 用户点击广告的总次数 用户点击不同广告、产品、类别、素材、广告主的总数 用户每天每条广告点击的平均次数,均值和方差
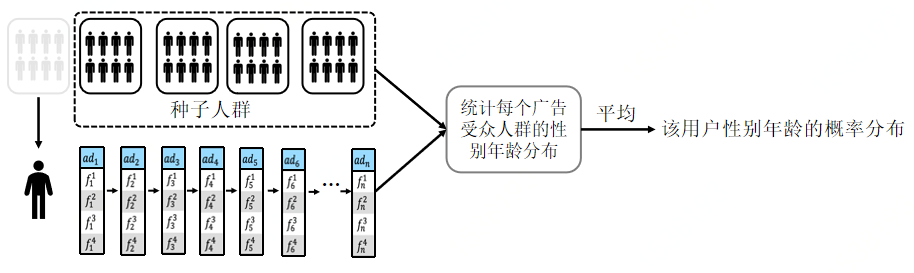
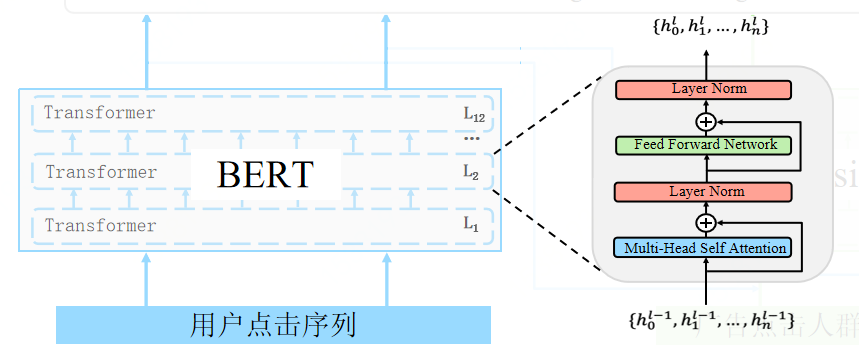
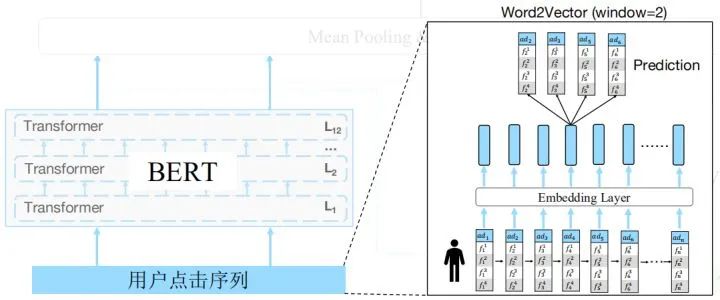
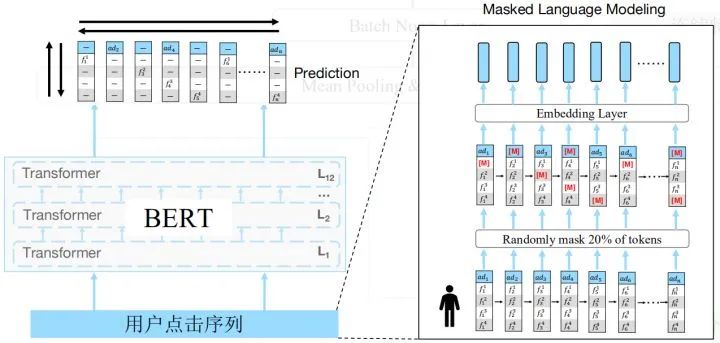
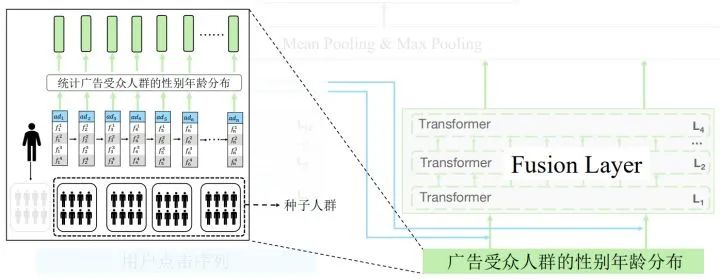
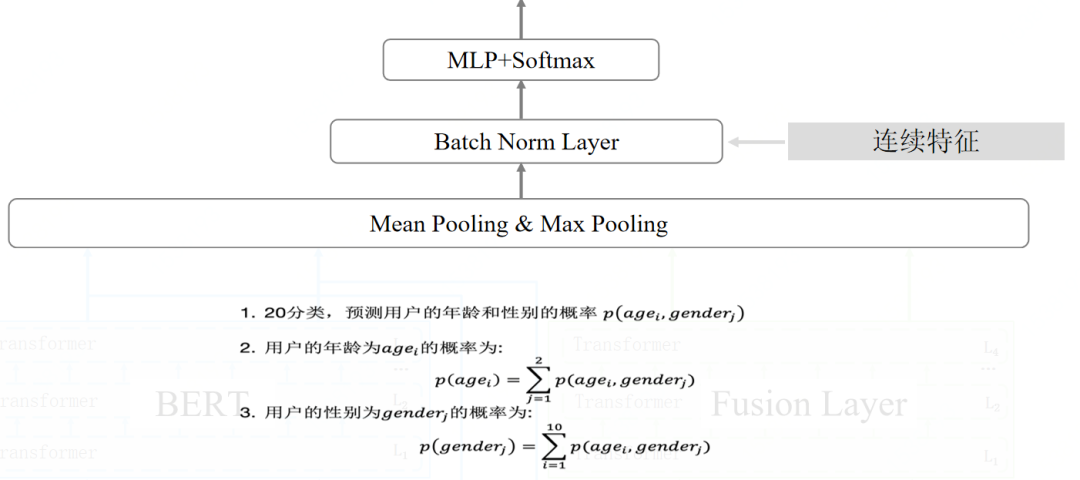
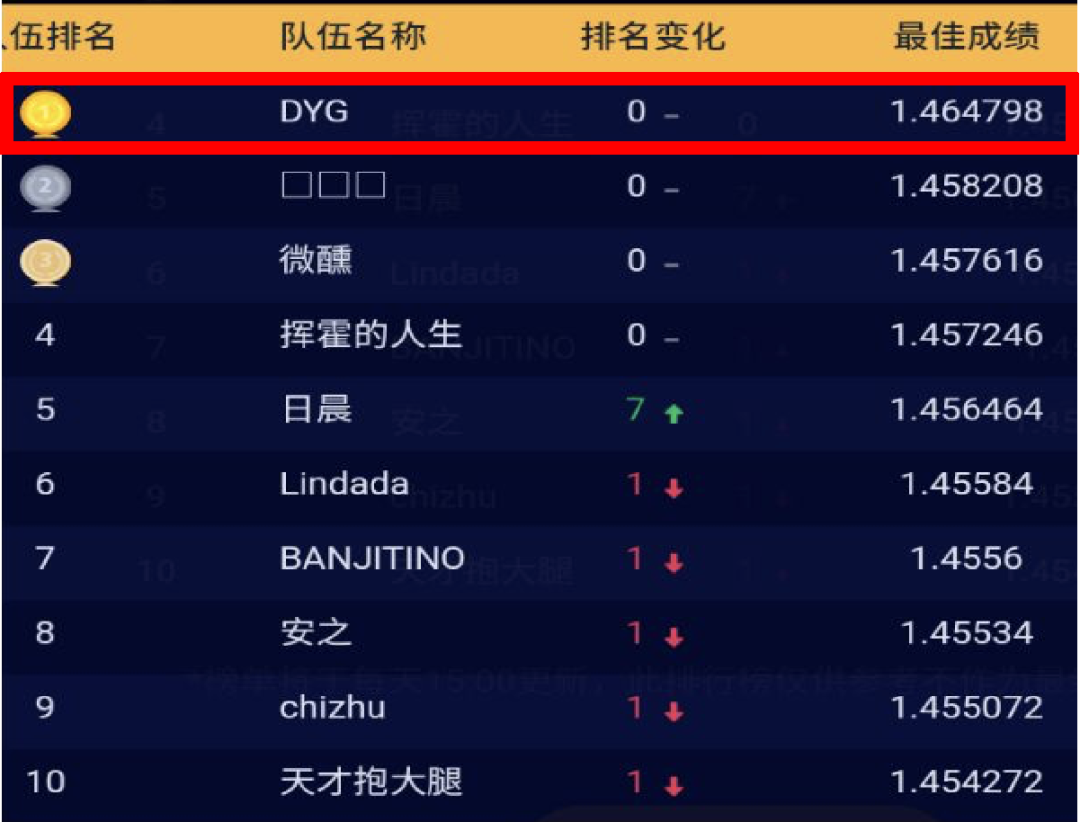
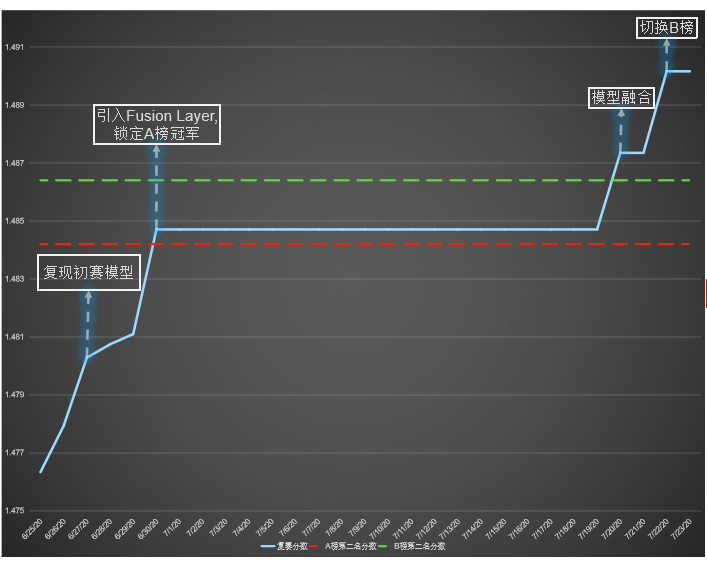
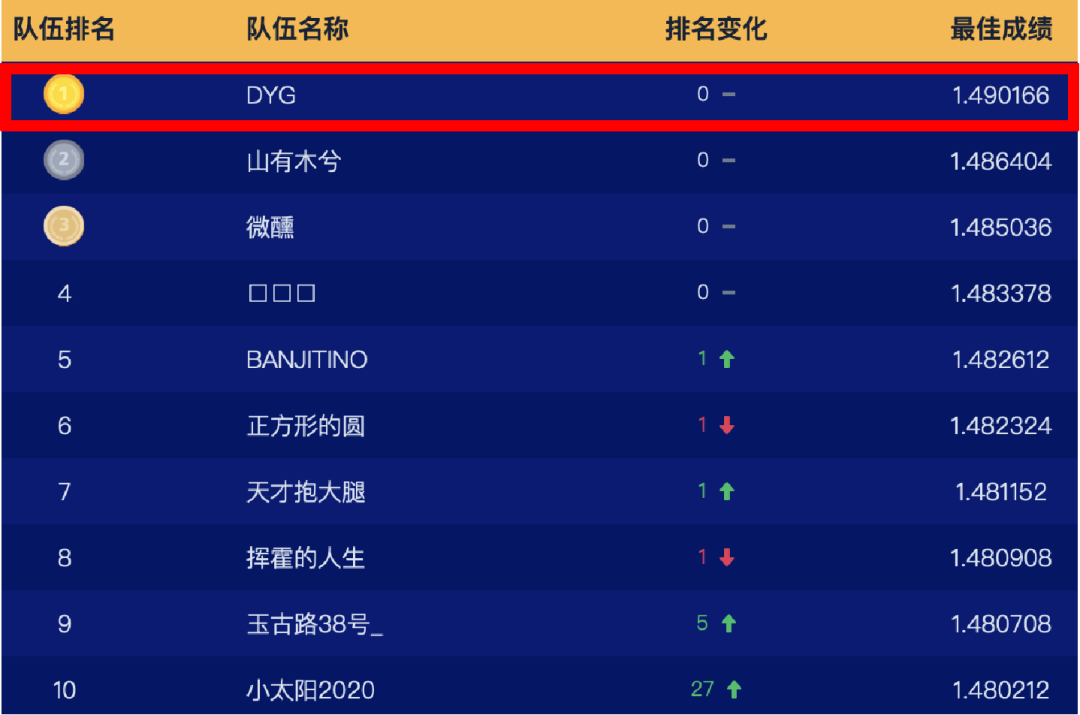
改进BERT并运用到人口属性预测场景
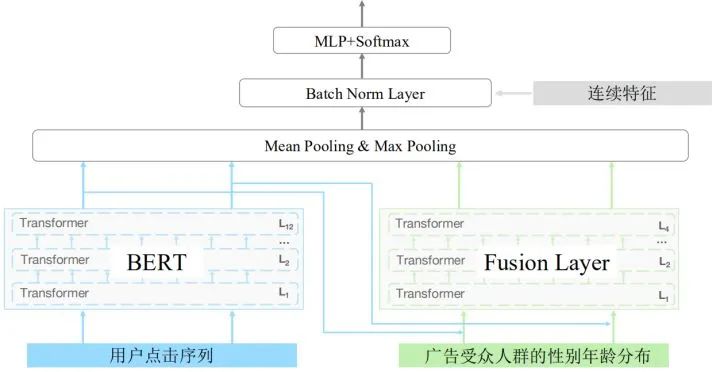
提出融合后验概率分布的方法及模型
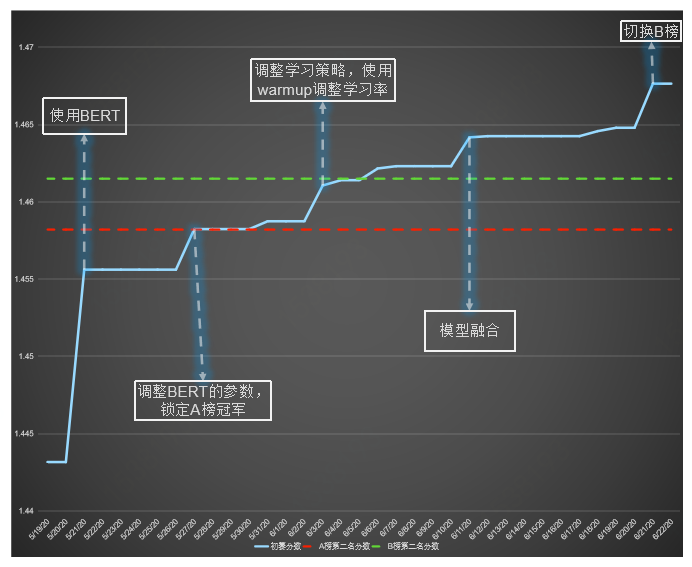
预训练模型越大越好?
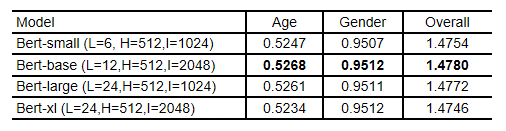
如何进一步改善预训练模型?
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):
评论