点击上方“智能算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:https://zhuanlan.zhihu.com/p/345472885
本篇文章来介绍一下 AAAI 2021 会议录取的目标检测相关论文,主要包含:一般的 2D 目标检测、旋转目标检测、视频目标检测、弱监督、域自适应等方向。
一、Learning Modulated Loss for Rotated Object Detection
学习用于旋转目标检测的调制损失
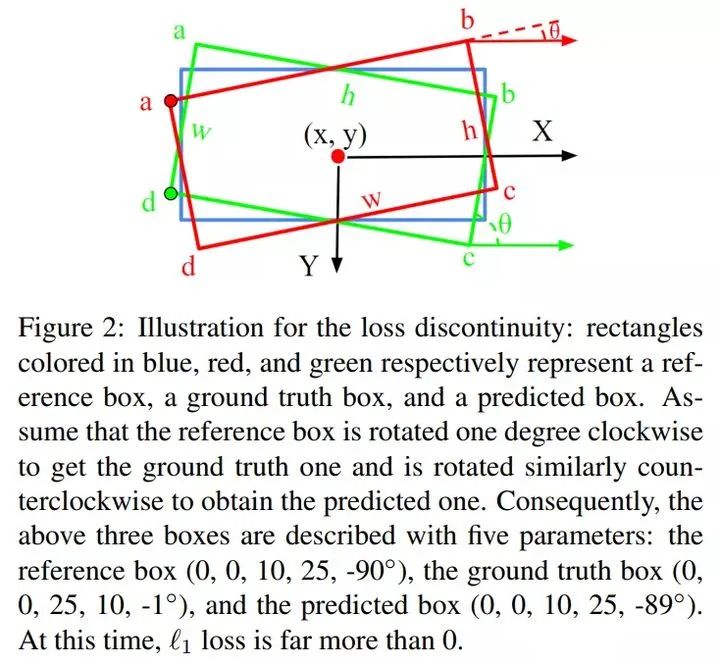
蓝色框:reference box 参考框 ;红色:ground truth ;绿色:预测框参考框是:假设参考盒顺时针旋转一度,得到 ground truth,同样逆时针旋转,得到预测值。如上图中两个 θ 。因此,上述三个框,可以用5个参数来描述。参考框:(0,0,10,25,-90度), 真实框(0,0,25,10,-1度), 预测框(0,0,10,25,-89度)现在流行的旋转检测方法通常使用五个参数(中心点坐标xy,宽度,高度和旋转角度)来描述旋转的边界框,并将l1损失描述为损失函数。在本文中,我们认为上述整合可能会导致训练不稳定性和性能退化,这是由于角度固有的周期性以及相关的宽度和高度突然交换所导致的损失不连续性。考虑到使用不同测量单位的五个参数之间的回归不一致,该问题更加明显。我们将上述问题称为旋转灵敏度误差 rotation sensitivity error (RSE),并提出了调制旋转损耗 modulated rotation loss 以消除损耗不连续性。我们的新损失 Loss 与八参数回归相结合,进一步解决了参数回归不一致的问题。实验表明,我们的方法在公共航空影像基准DOTA和UCAS-AOD上具有最先进的性能。它的泛化能力也在 ICDAR2015,HRSC2016 和 FDDB上得到了验证。从图1 可以看到质量上的改进,并且源代码将随论文的发布一起发布。
二、R3Det:Refined Single-Stage Detector with Feature Refinement for Rotating Object
R3Det:具有特征优化的单阶段旋转目标检测器
github code!!!arxiv上作者提交了6版论文。惊呆了,很认真的样子,还有代码,可信!但在实际设置中,对于大宽高比,密集分布和类别不平衡的旋转目标检测仍然存在困难。提出了一种快速,准确且端到端的的旋转目标检测器。考虑到现有精炼单级检测器的特征未对齐的缺点,这篇论文设计了一个特征精炼模块来获取更准确的特征以提高旋转目标检测性能。特征精炼模块的关键思想是通过特征插值将当前精炼的边界框位置信息重新编码为对应的特征点,以实现特征重构和对齐。(精炼阶段是refined stages)本文提出了一种端到端的精细化单级旋转检测器,采用从粗到细粒度的渐进式回归方法,实现快速、准确的物体检测。考虑到现有精细化单级检测器存在特征错位的缺点,我们设计了一个特征细化模块,通过获得更精确的特征来提高检测性能。特征细化模块的关键思想是通过像素化的特征插值,将当前精细化边界框的位置信息重新编码到对应的特征点上,实现特征重构和对齐。为了更准确地进行旋转估计,提出了近似的 SkewIoU 损失,解决了 SkewIoU 的计算无法推导的问题。在三个流行的遥感公共数据集 DOTA、HRSC2016、UCAS-AOD以及一个场景文本数据集 ICDAR2015 上的实验表明了我们方法的有效性。Tensorflow 和 Pytorch 版本代码都有。实际上,在文本检测和遥感目标检测领域主要面临三个挑战:1)大长宽比:对于大长宽比的目标,SkewIOU分数对角度的变化十分敏感3)类别不平衡,很多多类旋转目标数据集的类别极度不平衡在这篇论文中,主要讨论如何设计一个精确且快速的旋转目标检测器。首先,论文发现旋转锚框(Anchors)可以在目标密集场景发挥更好的效果,而水平锚框可以以更少的数量实现更高的召回率。因此,在本文精炼的单级检测器中使用两种形式的锚框进行组合,即在第一阶段使用水平锚框以提高速度和产生更多候选框。然后在精炼阶段去使用旋转锚框以适应目标密集场景。第二,论文还指出现有的精炼单级检测器存在特征未对齐的问题,极大的限制了分类和精炼阶段回归的可靠性。本文设计了一个特征精炼模块(FRM),该模块使用特征插值来获取精炼Anchor的位置信息并重建特征图实现特征对齐。FRM还可以在第一阶段之后减少精炼边界框的数量,从而加速模型。将这三种技术结合在一起,本文的方法可以在三个公开旋转目标检测数据集(包括DOTA,HRSC2016和ICDRA2015)上实现SOTA性能。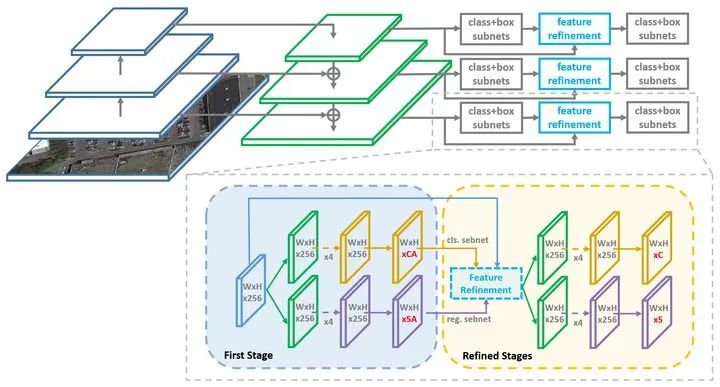 此方法是一个基于RetinaNet的单级旋转目标检测器,命名为R3Det。将精炼阶段(可以多次添加和重复)添加到网络以精炼边界框,并在精炼阶段添加特征精炼模块(FRM)以重建特征图。在单阶段旋转目标检测任务中,对预测边界框进行连续的精炼可以提高回归精度,因此特征精炼是必要的。应该注意的是,FRM也可以在其他单级检测器如SSD中使用。
此方法是一个基于RetinaNet的单级旋转目标检测器,命名为R3Det。将精炼阶段(可以多次添加和重复)添加到网络以精炼边界框,并在精炼阶段添加特征精炼模块(FRM)以重建特征图。在单阶段旋转目标检测任务中,对预测边界框进行连续的精炼可以提高回归精度,因此特征精炼是必要的。应该注意的是,FRM也可以在其他单级检测器如SSD中使用。1、带旋转目标检测功能的RetinaNet
目标分类子网和目框回归子网虽然结构一样,但使用单独的参数。RetinaNet提出了Focal Loss来解决类别不平衡引起的问题,大大的提高了单级目标检测器的精度。x,y,w,h, θ中, θ表示高w对x的锐角角度, θ在负二分之派(-90度)到0之间。倾斜交并比分数(SkewIOU)对角度很敏感,轻度的偏移都会导致SkewIOU快速下降。多个refined stage的IOU阈值从0.5 , 0.6 , 0.7 无数个0.7这样设置。许多精炼检测器仍然使用相同的特征图来执行多个分类和回归,而没有考虑边界框位置变化引起的特征未对齐。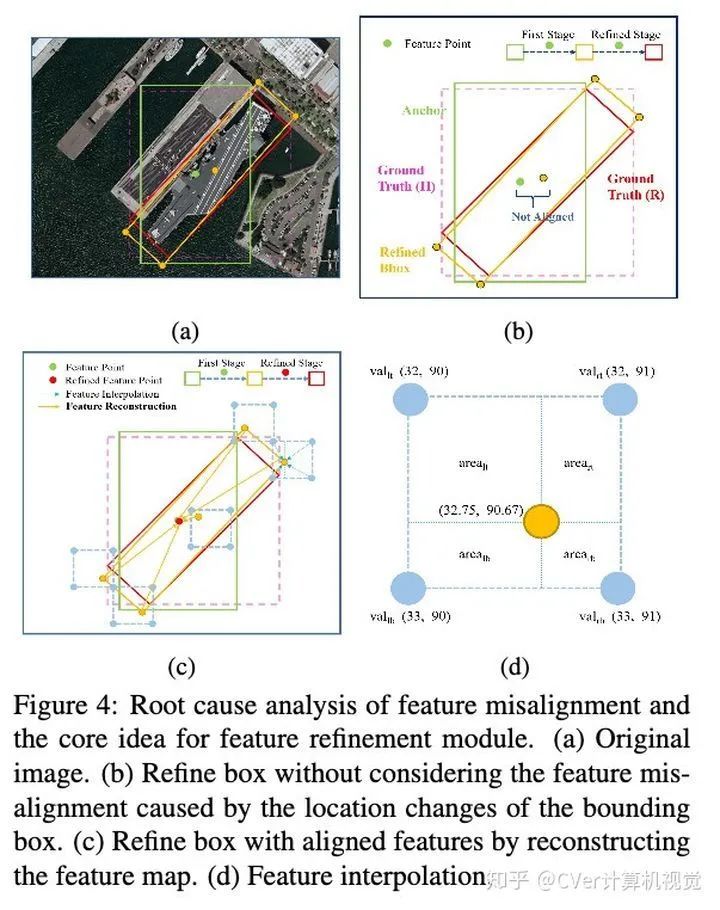 Figure4(b)展示了没有特征对齐的框精炼过程,导致了特征不准确,这对于大宽高比和数量少的样本是不利的。本文提出将当前精炼的边界框(橙色矩形)的位置信息重新编码为相应的特征点(红色的点),然后通过重建整个特征图来实现特征对齐。整个过程如Figure4(c)所示,为了准确的获取精炼边界框的位置特征信息,本文使用了双线性插值的方法。解决特征偏移的FRM模块的核心是特征重构。和其它两级旋转目标检测器(包含R2CNN,RRPN等)使用的ROIAlign相比,FRM精度速度均有优势,
Figure4(b)展示了没有特征对齐的框精炼过程,导致了特征不准确,这对于大宽高比和数量少的样本是不利的。本文提出将当前精炼的边界框(橙色矩形)的位置信息重新编码为相应的特征点(红色的点),然后通过重建整个特征图来实现特征对齐。整个过程如Figure4(c)所示,为了准确的获取精炼边界框的位置特征信息,本文使用了双线性插值的方法。解决特征偏移的FRM模块的核心是特征重构。和其它两级旋转目标检测器(包含R2CNN,RRPN等)使用的ROIAlign相比,FRM精度速度均有优势,- ROI Align具有更多的采样点(默认有7x7x4=196个),而减少采样点会极大的影响目标检测器的性能。FRM仅仅采样5个特征点,约为ROI Align的1/40,这为FRM提供了巨大的速度优势。
在进行分类和回归之前,ROI Align仅需要获得与ROI对应的特征。相比之下,FRM首先获得与特征点对应的特征(实例级别),然后重建整个特征图(图像级别)。最终,与基于ROI Align的全连接网络结构相比,基于FRM的方法可以获得更高效率和更少参数的全卷积结构。
三、Dynamic Anchor Learning for Arbitrary-Oriented Object Detection
用于任意方向目标检测的动态anchor学习
基于anchor的算法在训练时首先根据将预设的anchor和目标根据IoU大小进行空间匹配,以一定的阈值(如0.5)选出合适数目的anchor作为正样本用于回归分配的物体。但是这会导致两个问题:
进一步加剧的正负样本不平衡。对于旋转目标检测而言,预设旋转anchor要额外引入角度先验,使得预设的anchor数目成倍增加。此外,旋转anchor角度稍微偏离gt会导致IoU急剧下降,所以预设的角度参数很多。(例如旋转文本检测RRD设置13个角度,RRPN每个位置54个anchor)。
分类回归的不一致。当前很多工作讨论这个问题,即预测结果的分类得分和定位精度不一致,导致通过NMS阶段以及根据分类conf选检测结果的时候有可能选出定位不准的,而遗漏抑制了定位好的anchor。目前工作的解决方法大致可以分为两类:网络结构入手和label assignment优化,参见related work这里不再赘述。
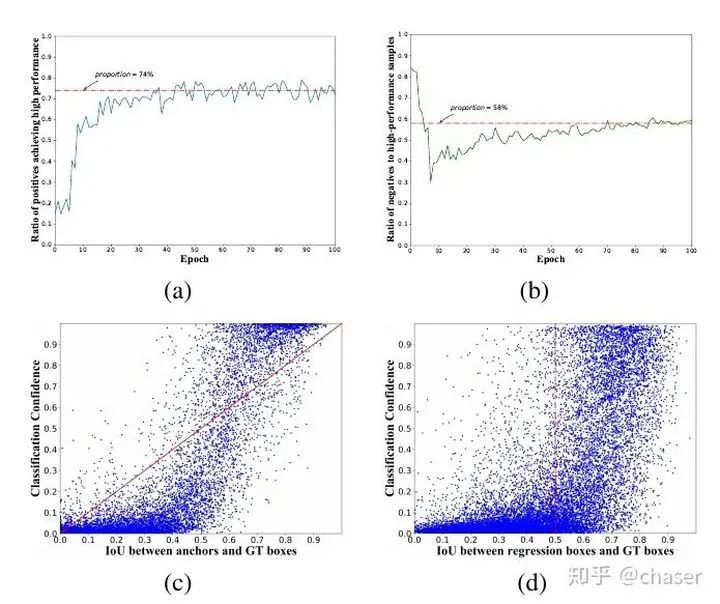
统计了训练过程的所有样本IoU分布,以及分类回归分数散点图,结果如下图。我们将anchor和gt的IoU称为输入IoU,pred box和gt的IoU称为输出IoU。从中看出:74%左右的正样本anchor回归的pred box后依然是高质量样本(IoU>0.5);近一半的高质量样本回归自负样本,这说明负样本还有很大的利用空间,当前基于输入IoU的label assignment选正样本的效率并不高,有待优化。
图c说明,当前的基于输入IoU的标签分配会诱导分类分数和anchor初始定位能力成正相关。而我们期望的结果是pred box的分类回归能力成正相关。从这里可以认为基于输入IoU的标签分配是导致分类回归不一致的原因之一。这个很好理解,划分样本的时候指定的初始对齐很好的为正样本,其回归后就算产生了不好的预测结果,分类置信还是很高,因为分类回归任务是解耦的;反之很多初始对齐不好的anchor被分成负样本,即使能预测好,由于分数很低,无法在inference被输出。
进一步统计了预测结果的分布如d,可以看到在低IoU区间分类器表现还行,能有效区分负样本,但是高IoU区间如0.7以上,分类器对样本质量的区分能力有限。【问:表面上右半区密密麻麻好像分类器完全gg的样子,但是我们正常检测器并没有出现分类回归的异常,高分box的定位一般也不赖,为什么?一是由于很多的IoU 0.5以上的点都是负样本的,即使定位准根本不会被关注到;二是预测的结果中,只要有高质量的能被输出就行了,其他都会被NMS掉,体现在图中就是右上角可以密密麻麻无所谓,只要右下角没有太多点可视化的检测结果就不会太差。】
四、YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design
YOLObile:通过压缩编译CoDesign在移动设备上进行实时目标检测
比 YOLOv3 快 7 倍,同时准确率更高。在手机上实现 19FPS 实时高准确率目标检测。
YOLObile 框架通过“压缩-编译”协同设计在手机端实现了高准确率实时物体检测。该框架使用了一种新提出的名为“块打孔”的权重剪枝方案,来对模型进行有效的压缩。他们还提出了一种高效的 GPU-CPU 协同计算优化方案来进一步提高计算资源的利用率和执行速度,并在他们的编译器优化技术的协助下,最终在手机端实现高准确率的实时物体检测。相比 YOLOv3 完整版,该框架快 7 倍,在手机上实现 19FPS 实时高准确率目标检测。并且同时准确率(mAP)高于 YOLOv3,并没有牺牲准确率提高计算速度。