
全平台都能用的 pandas 运算加速神器
阅读本文大概需要 3 分钟。
1 简介
随着其功能的不断优化与扩充,pandas已然成为数据分析领域最受欢迎的工具之一,但其仍然有着一个不容忽视的短板——难以快速处理大型数据集,这是由于pandas中的工作流往往是建立在单进程的基础上,使得其只能利用单个处理器核心来实现各种计算操作,这就使得pandas在处理百万级、千万级甚至更大数据量时,出现了明显的性能瓶颈。
本文要介绍的工具modin就是一个致力于在改变代码量最少的前提下,调用起多核计算资源,对pandas的计算过程进行并行化改造的Python库,并且随着其近期的一系列内容更新,modin基于Dask开始对Windows系统同样进行了支持,使得我们只需要改变一行代码,就可以在所有平台上获得部分pandas功能可观的计算效率提升。

2 基于 modin 的 pandas 运算加速
modin支持 Windows、Linux以及Mac系统,其中Linux与Mac平台版本的modin工作时可基于并行运算框架Ray和Dask,而Windows平台版本目前只支持 Dask 作为计算后端(因为Ray没有 Win 版本),安装起来十分方便,可以用如下3种命令来安装具有不同后端的 modin:
pip install modin[dask] # 安装dask后端
pip install modin[ray] # 安装ray后端(windows不支持)
pip install modin[all] # 推荐方式,自动安装当前系统支持的所有后端
本文在Win10系统上演示modin的功能,执行命令:
pip install modin[all]
成功安装modin+dask之后,在使用modin时,只需要将我们习惯的import pandas as pd变更为import modin.pandas as pd即可,接下来我们来看一下在一些常见功能上,pandasVSmodin性能差异情况。
首先我们分别使用pandas和modin读入一个大小为1.1G的csv文件esea_master_dmg_demos.part1.csv,来自kaggle(https://www.kaggle.com/skihikingkevin/csgo-matchmaking-damage/data),记录了关于热门游戏CS:GO的一些玩家行为数据,因为体积过大,请感兴趣的读者朋友自行去下载:

为了区分他们,在导入时暂时将modin.pandas命名为mpd:
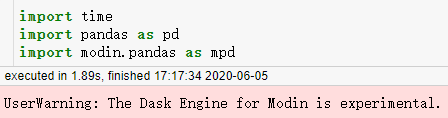
可以看到因为是Win平台,所以使用的计算后端为Dask,首先我们来分别读入文件查看耗时:
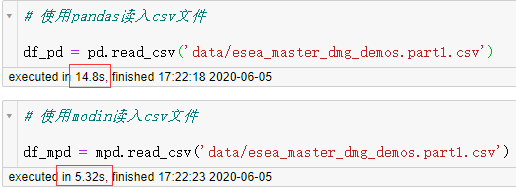
借助jupyter notebook记录计算时间的插件,可以看到原生的pandas耗时14.8秒,而modin只用了5.32秒,接着我们再来试试concat操作:
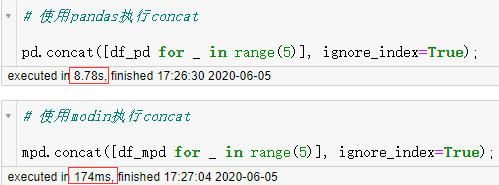
可以看到在pandas花了8.78秒才完成任务的情况下,modin仅用了 0.174 秒,取得了惊人的效率提升。接下来我们再来执行常见的检查每列缺失情况的任务:

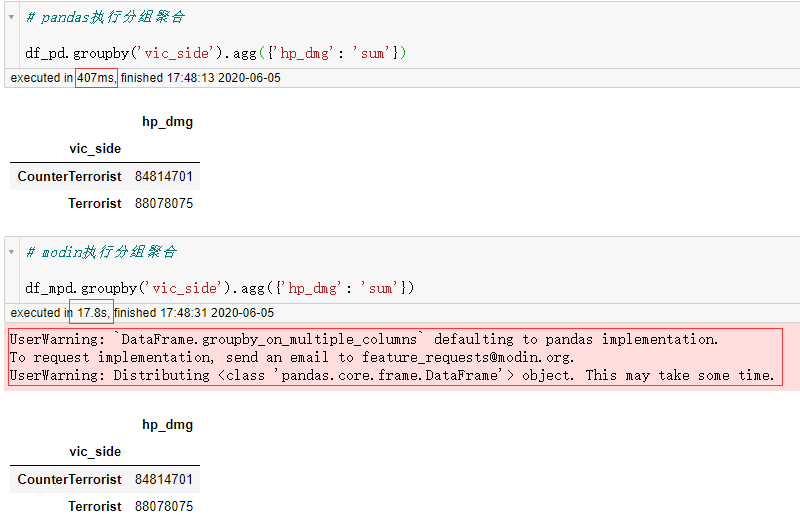
这时耗时差距虽然不如 concat操作时那么巨大,也是比较可观的,但是 modin毕竟是一个处于快速开发迭代阶段的工具,其针对 pandas的并行化改造尚未覆盖全部的功能,譬如分组聚合功能。
对于这部分功能,modin会在执行代码时检查自己是否支持,对于尚未支持的功能 modin会自动切换到 pandas单核后端来执行运算,但由于 modin中组织数据的形式与 pandas不相同,所以中间需要经历转换:

这种时候 modin的运算反而会比 pandas慢很多:
因此我对 modin持有的态度是在处理大型数据集时,部分应用场景可以用其替换 pandas,即其已经完成可靠并行化改造的 pandas功能,你可以在官网对应界面(https://modin.readthedocs.io/en/latest/supported_apis/index.html )查看其已经支持及尚未良好支持的功能,,因为 modin还处于快速开发阶段,很多目前无法支持的功能也许未来不久就会被加入 modin:

以上就是本文的全部内容,如有疑问欢迎在评论区与我讨论。
-END-
本文示例代码于Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
推荐阅读
1
2
3
4
崔庆才
静觅博客博主,《Python3网络爬虫开发实战》作者
隐形字
个人公众号:进击的Coder


长按识别二维码关注