Pandas知识点-统计运算函数
共
1853字,需浏览
4分钟
·
2021-04-19 14:39

统计运算非常常用。本文介绍Pandas中的统计运算函数,这些统计运算函数基本都可以见名知义,使用起来非常简单。
一、数据准备
数据文件是600519.csv,将此文件放到代码同级目录下,从文件中读取出数据。
为了使数据简洁一点,只保留数据中的部分列和前100行,并设置“日期”为索引。
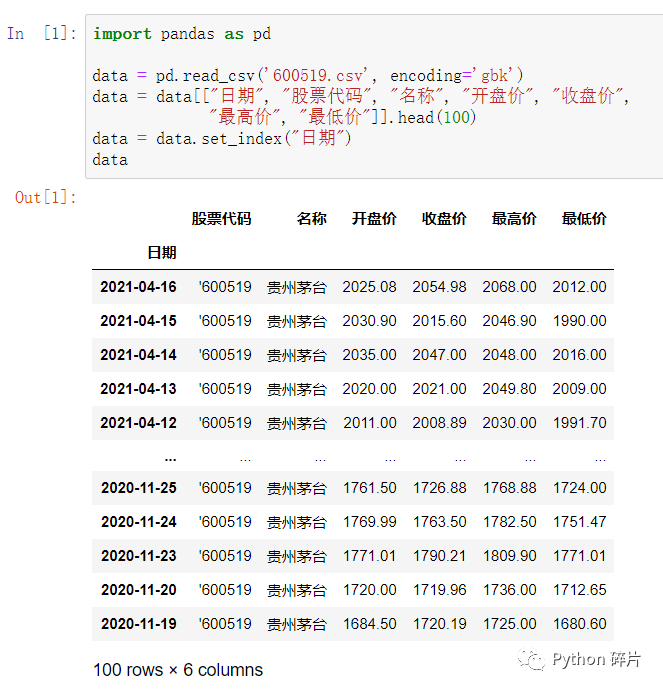
读取的原始数据如上图,本文使用这些数据来介绍统计运算函数。
二、最大值和最小值
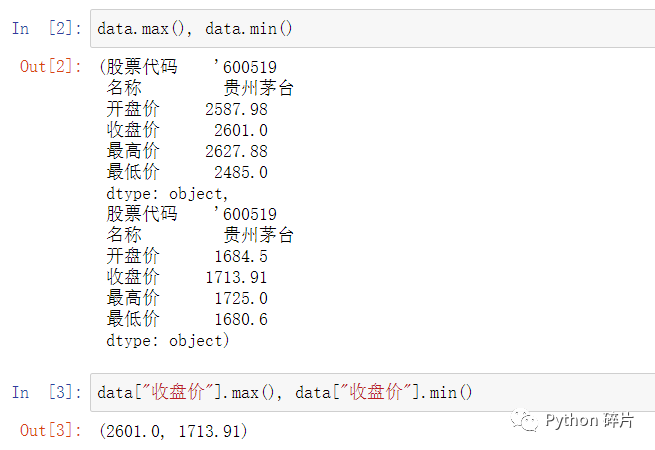
max(): 返回数据的最大值。使用DataFrame数据调用max()函数,返回结果为DataFrame中每一列的最大值,即使数据是字符串或object也可以返回最大值。
在Pandas中,数据的获取逻辑是“先列后行”,所以max()默认返回每一列的最大值,axis参数默认为0,如果将axis参数设置为1,则返回的结果是每一行的最大值,后面介绍的其他统计运算函数同理。根据DataFrame的数据特点,每一列的数据属性相同,进行统计运算是有意义的,而每一行数据的数据属性不一定相同,进行统计计算一般没有实际意义,极少使用,所以本文也不进行举例。
min(): 返回数据的最小值。使用DataFrame数据调用min()函数,返回结果为DataFrame中每一列的最小值,即使数据是字符串或object也可以返回最小值。使用Series数据调用max()或min()时,返回Series中的最大值或最小值,后面介绍的其他统计运算函数同理。
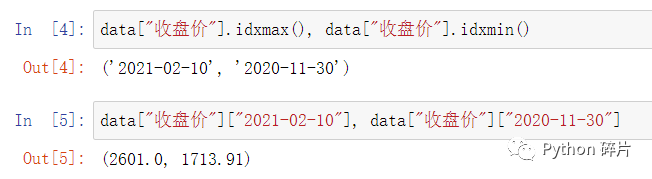
idxmax(): 返回最大值的索引。在numpy中,使用argmax()和argmin()获取最大值的索引和最小值的索引,在Pandas中使用idxmax()和idxmin(),实际上idxmax()和idxmin()可以理解成对argmax()和argmin()的封装。
使用idxmax()和idxmin()时,一般是用Series数据调用,用DataFrame数据调用可能会报TypeError。
三、均值和中位数
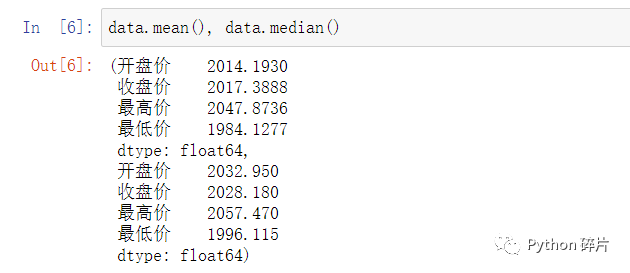
mean(): 返回数据的均值。使用DataFrame数据调用mean()函数,返回结果为DataFrame中每一列的平均值,mean()与max()和min()不同的是,不能计算字符串或object的平均值,所以会自动将不能计算的列省略。
median(): 返回数据的中位数。使用DataFrame数据调用median()函数,返回结果为DataFrame中每一列的中位数,median()也不能计算字符串或object的中位数,会自动将不能计算的列省略。
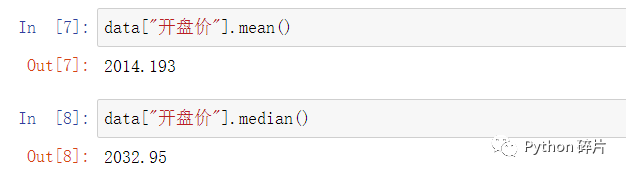
使用Series数据调用mean()或median()时,返回Series中的均值或中位数。
四、标准差和方差
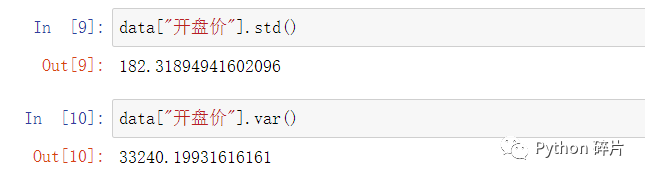
var(): 返回数据的方差。方差是标准差的平方,可以进行相互验证。
五、求和、累计求和
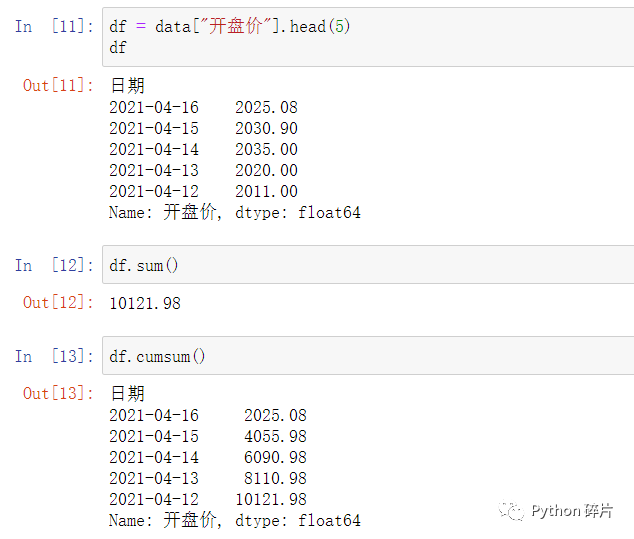
sum(): 对数据求和。为了避免数值过大,只取5个数据进行演示,返回结果为所有数据的和。
cumsum(): 对数据累计求和。累计求和是指,对当前数据及其前面的所有数据求和。如索引1的累计求和结果为索引0、索引1的数值之和,索引2的累计求和结果为索引0、索引1、索引2的数值之和,以此类推。
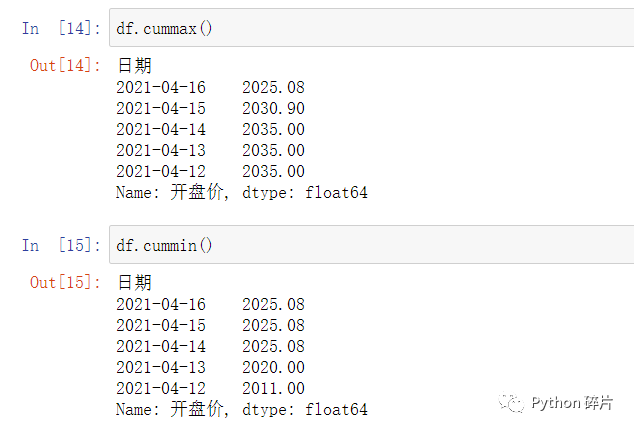
这两个函数的累计原理都与cumsum()相同,此外还有累计求积函数cumprod()等,分别有不同的应用场景。
六、综合统计函数
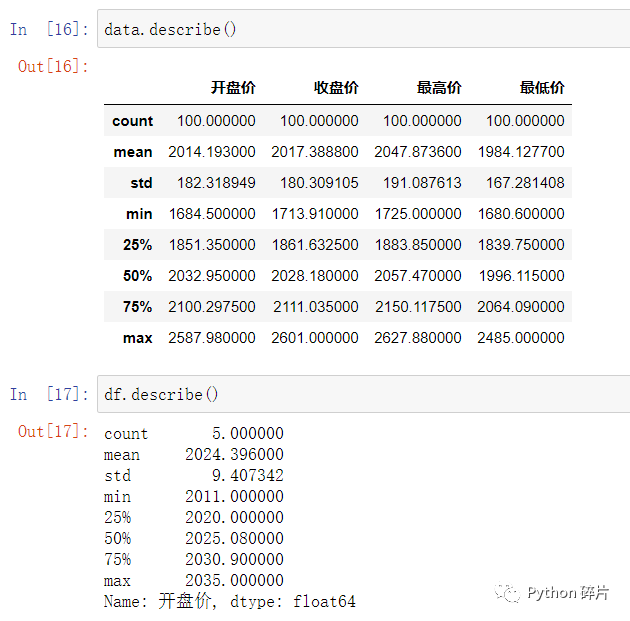
describe(): 综合统计函数,可以同时返回数据中的数据量、均值、标准差、最小值、最大值,以及上四分位数、中位数、下四分位数。可以一次返回数据的多个统计属性,使用起来很方便。
此外,还有一些统计函数本文没有介绍,比如count()统计数据量、abs()求绝对值等。假如Pandas提供的函数不满足我们的统计需求,还可以借助apply()函数自定义统计运算,后面的文章再继续介绍。
如果需要代码和数据,可以点击关注公众号“Python碎片”,然后在后台回复“pandas06”关键字获取本文代码和数据。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报
 下载APP
下载APP