
PyWebIO,让 Pandas 原地起飞的神器!
我想很多人用 Python 就是用 pandas 进行数据分析,并且你大概率每天就用到 pandas 那几个函数处理结构大致相似的数据。
每天重复写着同样的代码,很辛苦,于是就会有人想到用 Pyinstaller 进行打包,但是打包的痛苦,尤其是各种乱七八糟的报错只能说试过的都懂。
但你有想过将要打包的功能,做到网页上去吗?这样只要有个公网ip就能随时随地、不限设备的去访问。你可能会想过,但是当你尝试去实现,发现 Python 开发页面动不动就是 Django/flask 这样的大家伙,很容易劝退。
本文我就将基于之前介绍过的 PyWebIO 库,讲一下如何不写一行前端代码,仅用一个不到100行的py脚本制作下面的页面
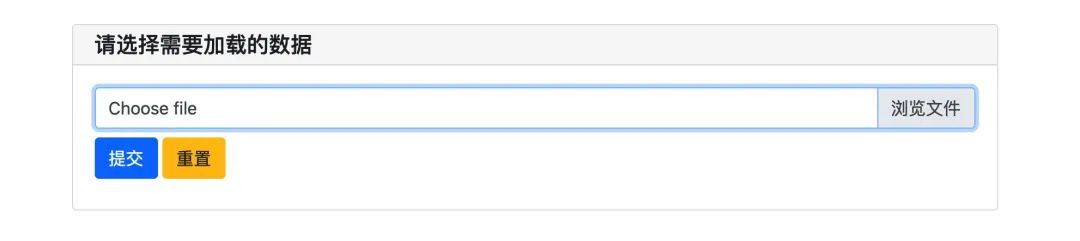
上传数据
首先是数据的加载,在 PyWebIO 中实现这个操作非常简单,只需要一行代码即可在页面添加一个上传文件的部件
file = file_upload('请选择需要加载的数据')
当然有上传就有读取的操作,虽然后台已经将数据文件读取了,但默认不是用 pandas 读取的很难操作,所以我们可以用下面的代码将文件名字读取出来之后,再用 pandas 进行读取。
df = read_file(file['filename'])
读取之后呢,就会进入到下面的页面,我们继续讲解该其他功能的实现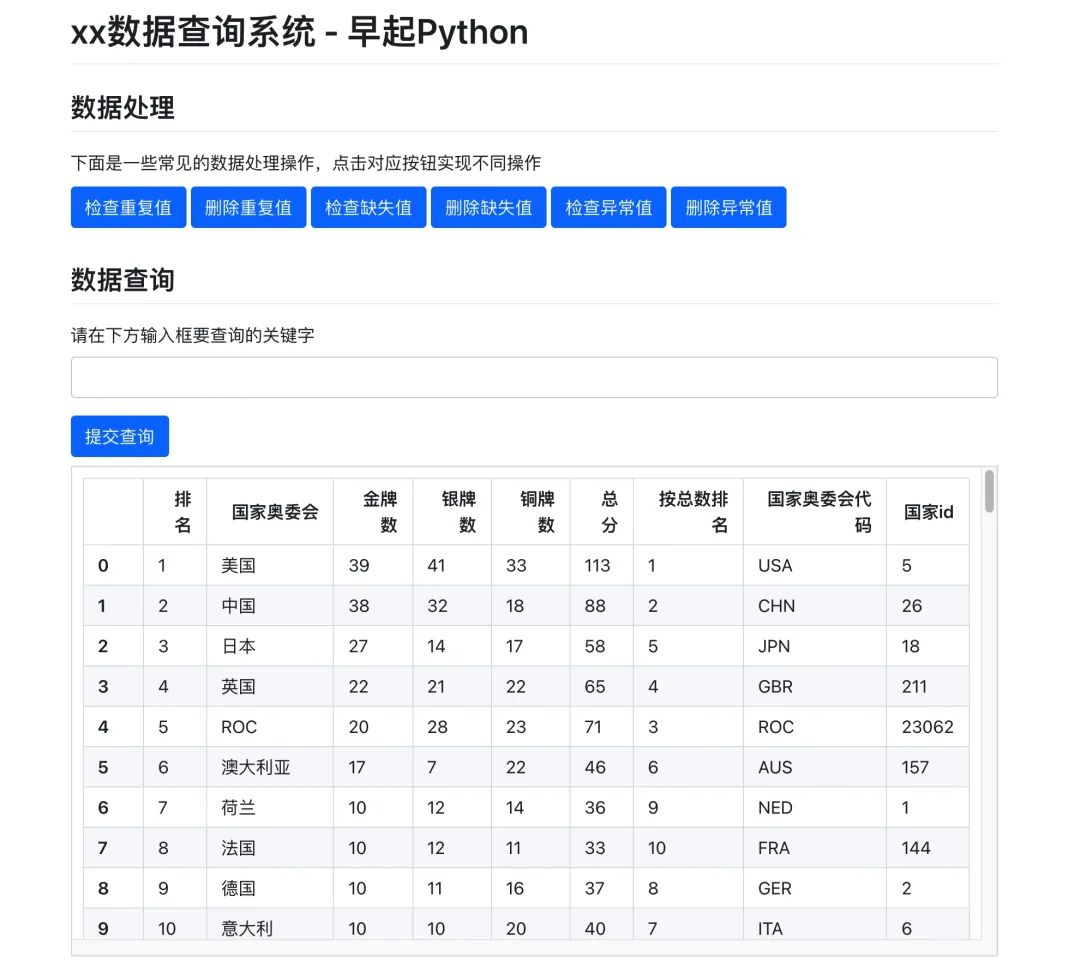
添加按钮与事件
有关标题和文字部分的讲解见该系列第一篇文章,本文不再赘述。
现在来重点讲解一下,如何添加一个按钮,简单来说就是如何实现像下图一样,点击按钮实现对应功能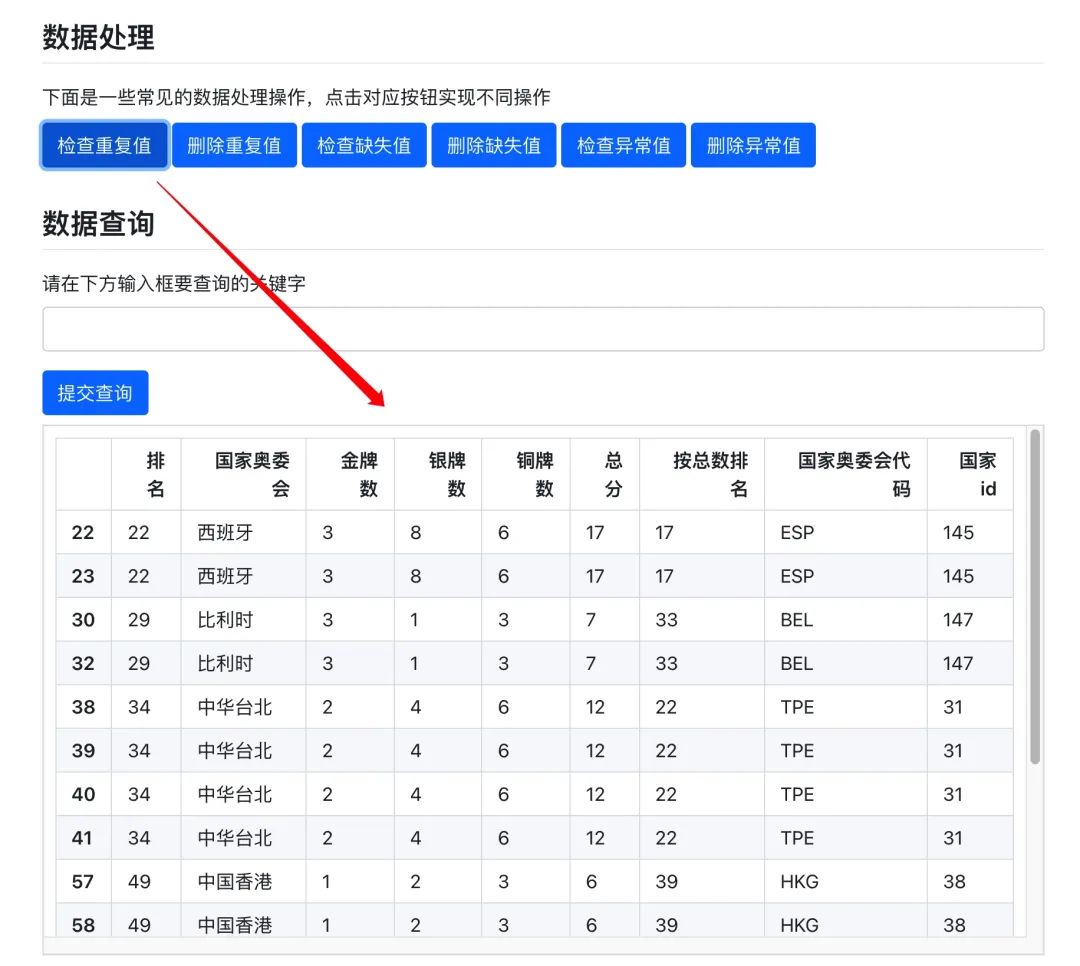
这就分为两个操作,添加按钮和绑定对应按钮的事件,在 PyWebIO 中,我们可以使用 put_buttons 添加一个按钮,并使用 onclick 绑定该按钮对应的事件
put_buttons(['关闭'], onclick=lambda _: close_popup())
例如上面代码就添加了一个关闭的按钮,点击就会关闭弹窗,到我们的页面来,我们有一排按钮,怎么实现?
答案是用一个 list,然后将每个按钮对应的事件也用一个list传给后台即可
put_buttons(['检查重复值','删除重复值','检查缺失值','删除缺失值','检查异常值','删除异常值'], onclick=[lambda: chongfu(df,res_table),
lambda: chongfuchuli(
df,
res_table),
lambda: other(),
lambda: other(),
lambda: other(),
lambda: other()])
按钮设置好了之后,就是该按钮对应操作函数的开发了,例如查找重复值,这对于刷了 pandas300题 的同学来说,完全不是问题
df1 = df[df.国家奥委会.duplicated() == True]
但是这只是用 pandas 将重复值查找出来了,怎样让网页显示出来,这又是下一个问题。
显示数据
在上面,我们搞定了点击按钮就将重复值筛选出来,但是如何让前端展示表格。
在 PyWebIO 中展示表格一般像下面一样,将数据转换为多级列表,再用过markdown渲染出来
但是如果再写一个转换函数,就略显麻烦,幸运的是 pandas 可以直接输出html,所以我们可以将数据先转化为 html 再嵌入页面中,就像前端的 iframe 一样,这部分代码如下
put_scrollable(res_table,horizon_scroll=True,height=450)
res_table.reset(put_html(df1.to_html(border=0)))
通过循环这样的操作,我们给每一个按钮都添加一个功能函数,函数内写入 pandas 操作部分与前端显示部分就能完成第一部分数据处理的操作。
pin - 持续性输入
下面一个功能是数据筛选,即给定关键词,输出包含该关键词的行。
看起来很简单,但这却是 PyWebIO 中最难的部分,因为 PyWebIO 默认是同步的代码,也就是如果一个输入框没有输入内容,那么后面的全部代码都不会展示。
这也是为什么,在第一个页面,没有上传文件,后面的页面代码都没有输出,显然如果这里还用同样的方法是不可以的。
这就用到 pin 方法,可以简单的按照异步的思路去理解,也就是说我们先创建一个输入框和一个提交按钮,再用回调函数进行绑定
put_markdown('## 数据查询')
pin.put_input('res', label='请在下方输入框要查询的关键字', type=TEXT)
put_buttons(['提交查询'], lambda _: chaxun(res_table,df,pin.pin['res']))
就像上面一样,先使用 pin.put_input 创建输入框,再使用 put_buttons 添加一个按钮并绑定对应操作,这里看起来代码不长,但是实际写代码时是需要花费一定时间思考的!
到这里,至此我们的页面主要逻辑就介绍完毕,至于一些细节性的修改例如文字、标题等大家可以自行研究源码学习!
小结
通过上面的讲解,我们可以发现,没有写一行前端,就完成了一个简单的数据查询与处理页面的开发,这就是 PyWebIO 魅力所在!
当然弊端也是有的,就是它最大的优点也是它最大的缺点,不写前端代码可以不用关注样式,从而导致页面过于简单。所以你应该合理评估自己对页面样式的评估来选择是否使用它!
但不论如何,我都会在后续的文章中,分享如何用 PyWebIO 开发更多的页面!喜欢这个系列的话可以给本文点赞、留言、在看!
注:本文的完整代码,可以在后台回复 1105 获取!
