
算术运算是最基本的运算,看起来很简单,但也有一些需要注意的地方,本文中会依次介绍。
一、Pandas算术运算函数介绍
基本的算术运算是四则运算(加、减、乘、除)和乘方等。Pandas中都实现了对应的算术运算函数,如add()、sub()、mul()、div()等,常用的算术运算函数见下表。
| 算术运算函数 | 用法介绍(以DataFrame为例)
| 描述 |
| add() | df1.add(df2) | df1与df2进行加法运算 |
radd()
| df1.radd(df2)
| df2与df1进行加法运算
|
sub()
| df1.sub(df2)
| 用df1减df2 |
rsub()
| df1.rsub(df2)
| 用df2减df1
|
mul()
| df1.mul(df2)
| df1与df2进行乘法运算
|
rmul()
| df1.rmul(df2)
| df2与df1进行乘法运算
|
div()
| df1.div(df2)
| 用df1除df2
|
rdiv()
| df1.rdiv(df2)
| 用df2除df1
|
truediv()
| df1.truediv(df2)
| 用df1除df2
|
rtruediv()
| df1.rtruediv(df2)
| 用df2除df1
|
floordiv()
| df1.floordiv(df2)
| 用df1除df2,取整除
|
rfloordiv()
| df1.rfloordiv(df2)
| 用df2除df1,取整除
|
| mod() | df1.mod(df2)
| 用df1除df2,取余数
|
| rmod() | df1.rmod(df2)
| 用df2除df1,取余数
|
| pow() | df1.pow(df2)
| 计算df1的df2次方,df1^df2 |
| rpow() | df1.rpow(df2)
| 计算df2的df1次方,df2^df1
|
在Pandas中,这些函数的用法和运算规则都相同,运算结果的数据结构也都相同。所以本文中只以加法运算函数add()作为例子,使用其他函数时将函数名进行替换即可。如果有特殊的地方,会单独说明。
二、DataFrame与数字的算术运算

DataFrame与数字相加时,会将DataFrame中的每一个数都与指定数字相加,返回一个新的DataFrame(不是修改原DataFrame,而是返回一个新的DataFrame)。
add()函数的作用与运算符“+”(加号)的作用一样,运算结果也相同。其他算术运算函数与加法的用法一样,也都可以用对应的运算符代替。
在进行除法运算时,如果被除数是0,得到的结果可能是inf(表示无穷大,与Python的浮点数精度有关),也可能是NaN(空值)。在后面的所有运算中都一样。
每一个算术运算函数都有一个r字母开头的对应函数,起到的作用是交换运算数字的位置,如交换两个加数的位置、交换被除数与除数的位置、交换底数与指数的位置。
三、Series与数字的算术运算

Series与数字相加时,与DataFrame相同,也是将Series中的每一个数都与指定数字相加,返回一个新的Series。
四、两个DataFrame算术运算
1. 两个形状和索引相同的DataFrame进行运算

两个DataFrame相加,如果DataFrame的形状和对应的索引都一样,直接将对应位置(按行索引和列索引确定位置)的数据相加,得到一个新的DataFrame。
2. 两个形状或索引不一样的DataFrame进行运算

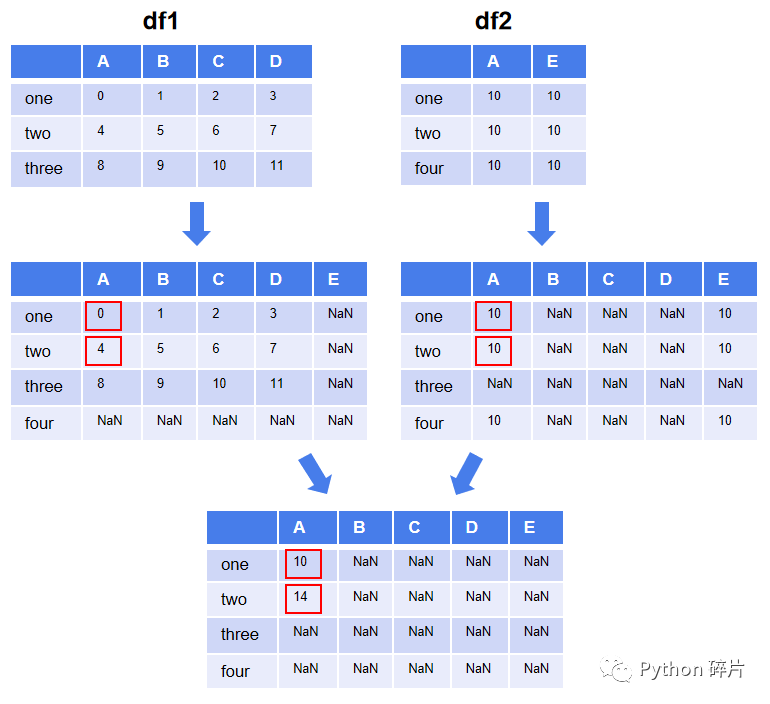
两个DataFrame相加,如果DataFrame的形状和索引不完全一样,只会将两个DataFrame中行索引和列索引对应的数据相加,生成一个形状能兼容两个DataFrame的新DataFrame,在没有运算结果的位置填充空值(NaN)。
当且仅当两个DataFrame中都有值时,才会有运算结果,其他位置的结果都为空值,运算原理如下图。
在运算结果中有很多空值,如果需要进行空值填充,可以使用fillna()函数。
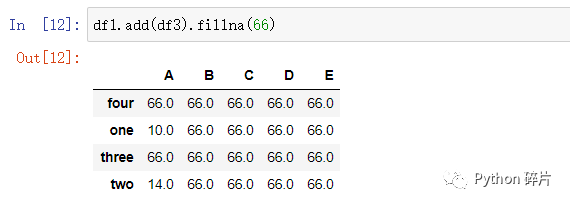
fillna(value): 运算出结果后,将所有空值的位置都填充成指定值。
在算术运算函数中,可以使用fill_value参数,在运算前先填充数据。
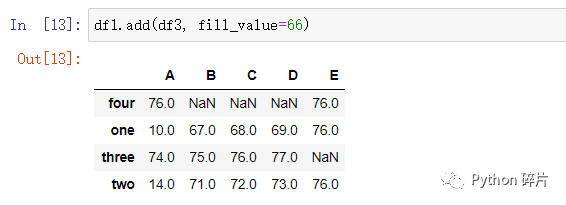
与fillna()函数不同,使用fill_value参数是先填充数据再进行运算,而fillna()函数是先运算再对结果填充,所以两者的结果不一样。
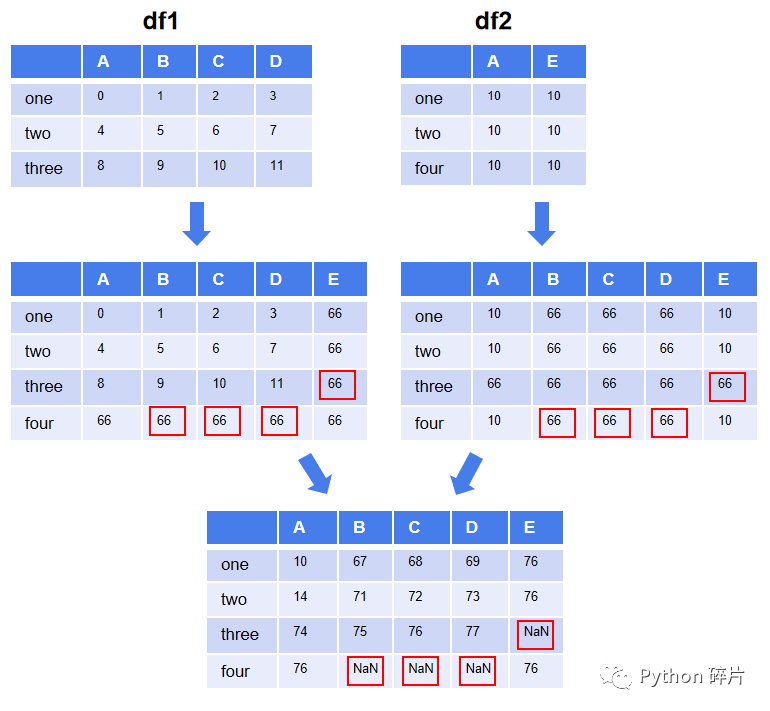
使用fill_value参数填充数据后再进行运算,如果两个DataFrame中的数据都是填充值,则此位置的结果为空值,运算原理如下图。
五、两个Series算术运算
1. 两个形状和索引相同的Series进行运算

两个Series相加,如果形状和索引都一样,直接将对应位置(按行索引确定位置)的数据相加,得到一个新的Series。
2. 两个形状或索引不一样的Series进行运算
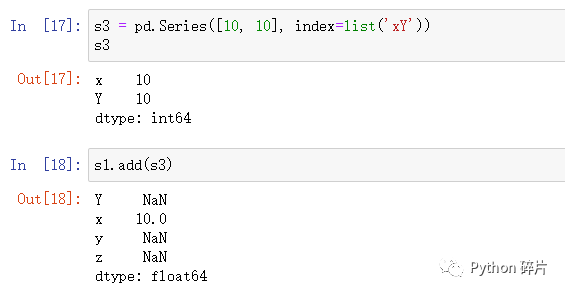
两个Series相加,如果形状和索引不完全一样,只会将行索引对应的数据相加,生成一个形状能兼容两个Series的新Series,在没有运算结果的位置填充空值(NaN)。
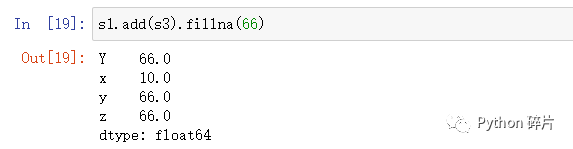
可以使用fillna()函数对运算结果中的空值进行填充。
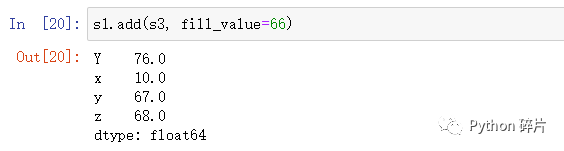
可以使用fill_value参数先填充数据再进行运算。
与DataFrame不同的是,使用fill_value参数先填充数据再进行运算时,结果中不会有空值。因为Series是一维数据,对Series填充时,不存在两个Series都是填充值的行索引。
六、DataFrame与Series算术运算
1. Series的行索引与DataFrame的列索引相同

在Series与DataFrame进行算术运算时,默认会将Series看成是一行数据(而不是一列),在add()函数中,axis参数默认为1或'columns'。
如果Series的索引与DataFrame的列索引相同,会将Series依次与DataFrame中的每一行数据进行运算,得到一个新的DataFrame。
2. Series的行索引与DataFrame的行索引相同
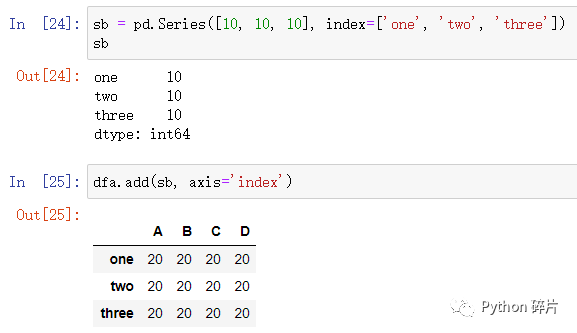
如果Series的索引与DataFrame的行索引对应,要使Series按列与DataFrame运算,可以将axis参数设置成0或'index',这样会将Series依次与DataFrame中的每一列数据进行运算,得到一个新的DataFrame。
3. Series的行索引与DataFrame的行索引或列索引不完全相同
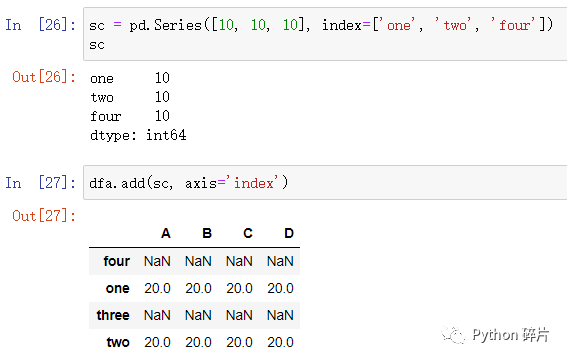
此时,DataFrame与Series的运算原理同两个DataFrame进行算术运算,会得到一个形状能兼容DataFrame和Series的新DataFrame。其中Series可以按行运算,也可以按列运算,取决于axis参数。
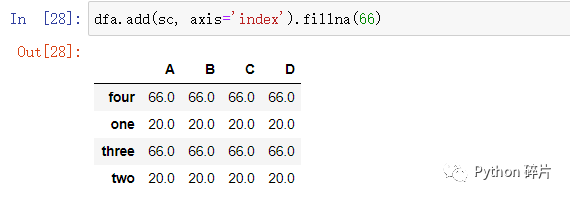
fillna()函数的用法也一样,对运算结果进行空值填充。
但是,DataFrame与Series的算术运算不支持fill_value参数,不能先填充再运算,会报错。
以上就是Pandas中的算术运算函数介绍,如果需要本文代码,可以点击关注公众号“Python碎片”,然后在后台回复“pandas07”关键字获取完整代码。
