
【机器学习入门】图解超经典的KNN算法

出品:Python数据之道(ID:PyDataLab)
作者:Peter,来自读者投稿
编辑:Lemon
图解超经典的KNN算法
本文中介绍的机器学习算法中的一种监督学习的算法:KNN 算法,全称是 K-Nearest Neighbor,中文称之为 K 近邻算法。
它是机器学习可以说是最简单的分类算法之一,同时也是最常用的分类算法之一。在接下来的内容中,将通过以下的几个方面的内容对该算法进行详细的讲解:
1、算法思想
思想
首先对 KNN 算法的思想进行简单的描述:
KNN 算法是一个基本的分类和回归的算法,它是属于监督学习中分类方法的一种。其大致思想表述为:
给定一个训练集合 M 和一个测试对象 n ,其中该对象是由一个属性值和未知的类别标签组成的向量。 计算对象 m 和训练集中每个对象之间的距离(一般是欧式距离)或者相似度(一般是余弦相似度),确定最近邻的列表 将最近邻列表中数量占据最多的类别判给测试对象 z 。 一般来说,我们只选择训练样本中前 K 个最相似的数据,这便是 k-近邻算法中 k 的出处。
用一句俗语来总结 KNN 算法的思想:物以类聚,人以群分
说明
所谓的监督学习和非监督学习,指的是训练数据是否有类别标签,如果有则是监督学习,否则是非监督学习 在监督学习中,输入变量和输出变量可以连续或者离散的。如果输入输出变量都是连续型变量,则称为回归问题(房价预测);如果输出是离散型变量,则称之为分类问题(判断患者是否属于患病) 在无监督学习中,数据是没有任何标签的,主要是各种聚类算法(以后学习)
2、算法步骤
KNN 算法的步骤非常简单:
计算未知实例到所有已知实例的距离; 选择参数 K(下面会具体讲解K值的相关问题)根据多数表决( Majority-Voting)规则,将未知实例归类为样本中最多数的类别
3、图解 KNN 算法
K 值影响
下面通过一组图形来解释下 KNN 算法的思想。我们的目的是:判断蓝色的点属于哪个类别
我们通过变化 K 的取值来进行判断。在该算法中K的取值一般是奇数,防止两个类别的个数相同,无法判断对象的类别
K=1、3、5、7…….
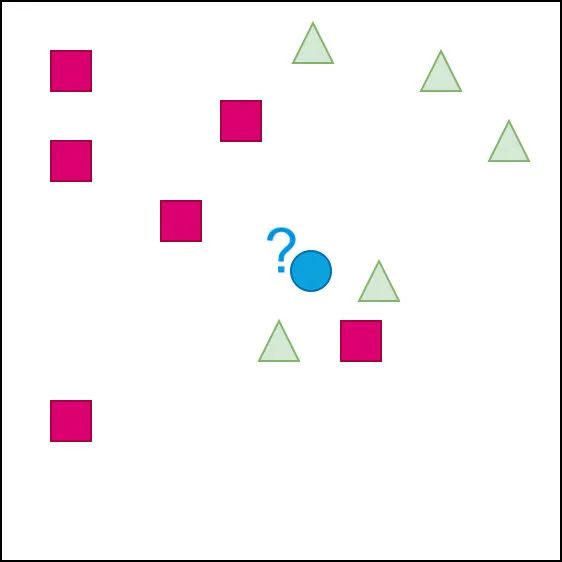
首先如果 K=1:会是什么的情况?
根据图形判断:蓝色图形应该是属于三角形
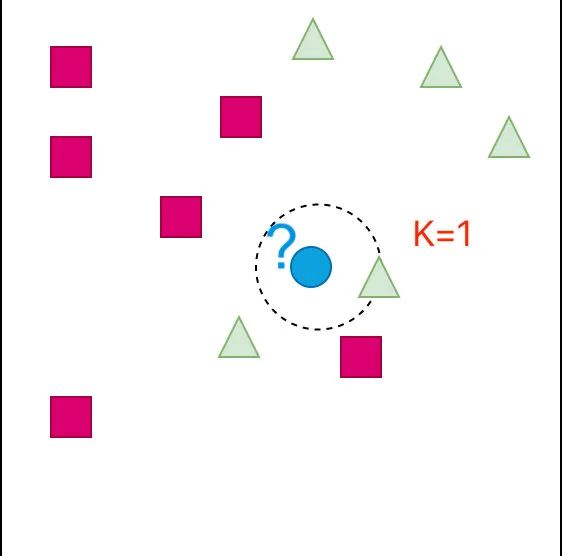
K=3 的情形
从图中可以看出来:蓝色部分还是属于三角形

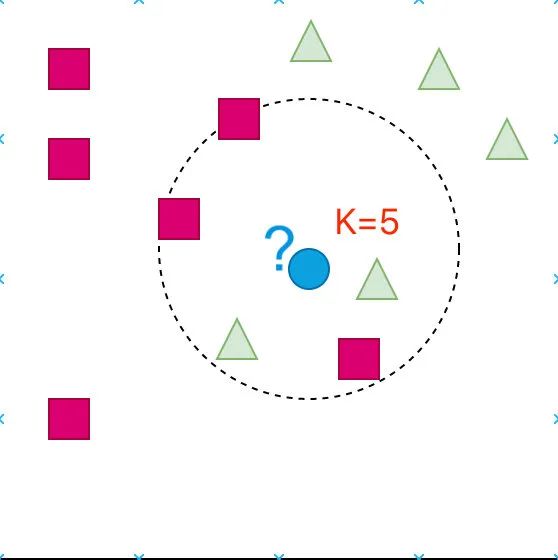
K=5 的情形:
此时我们观察到蓝色部分属于正方形了
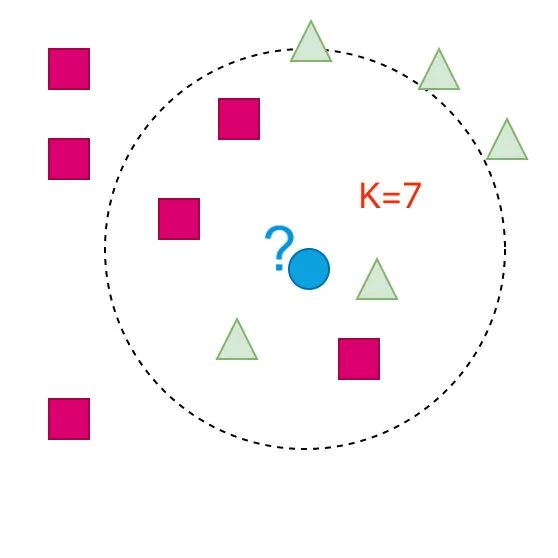
K=7 的情形:
这个时候蓝色部分又变成了三角形
小结
当 K 取值不同的时候,判别的结果是不同的。所以该算法中K值如何选择将非常重要,因为它会影响到我们最终的结果。
4、K 值选取
交叉验证
上面的一系列图形中已经说明了该算法中K值对结果的影响。那么 K 值到底该如何选择呢?谜底揭晓:交叉验证
K 值一般是通过交叉验证来确定的;经验规则来说,一般 k 是低于训练样本数的平方根。
所谓交叉验证就是通过将原始数据按照一定的比例,比如 6/4 ,拆分成训练数据集和测试数据集,K 值从一个较小的值开始选取,逐渐增大,然后计算整个集合的方差,从而确定一个合适的 K 值。
经过使用交叉验证,我们会得到类似如下的图形,从图形中可以明显的:
当 K 先不断增大的时候,误差率会先进行降低。因为数据会包含更多的样本可以使用,从而分类效果会更好; 当 K=10 的附近,出现误差率的变化,建议 K=9 或者 11 ; 当 K 不断增大的时候,误差率将会不断增加。此时,KNN 算法将会变得没有意义。比如有 50 个样本,当 K 增加到 45 的时候,算法没有意义,几乎使用了全部样本数据,没有体现出最近邻的思想。

K 值过小
k值太小:容易受到噪声点的影响
用较小的邻域中的实例进行预测; 近似误差减小,估计误差增大; 预测结果对近邻的实例点非常敏感;如果近邻点恰好是噪声,预测出错。
K 值过大
k 值太大:分类太多,太细,导致包含太多其他类别的点
用较大的邻域中的实例点进行预测; 减少学习的估计误差,但是近似误差增大; 与输入实例较远的点的训练实例也会起预测作用; k 值增大意味着整个模型变得简单。
5、距离问题
常见距离
在上面的算法原理中提到,需要计算测试对象和训练集合中每个对象距离。在机器学习中,两个对象之间的距离包含:
常用的距离有以下几种:
欧式距离 曼哈顿距离 切比雪夫距离 闵可夫斯基距离 标准欧式距离 马氏距离 汉明距离 夹角余弦 杰卡德相似系数
在 KNN 算法中我们一般采用的是欧式距离(常用)或者曼哈顿距离
欧式距离
N维空间的距离:
当 n=2 时候,称之为欧式距离:
其中 X 称之为到原点的欧式距离
曼哈顿距离
曼哈顿距离是闵可夫斯基距离的一种特殊情形。闵可夫斯基距离指的是:
当 p=2,变成欧式距离;
当 p=1,变成曼哈顿距离;
当 p 区域无穷,变成切比雪夫距离;
6、算法优缺点
优点
简单易用,而且非常容易弄懂基本原理, KNN算法可以说是机器算法中最简单易懂的算法。即使初学者没有太多的基础,相信也能明白它的原理。算法是惰性的,模型训练时间快。 KNN算法没有明确的数据训练过程,或者说它根本不需要进行数据的训练,直接可以对测试对象进行判断。适合用于多分类问题(对象具有多个标签)。
缺点
对计算机的内存要求高:因为它存储了整个训练数据,性能较低 算法的可解释差,对结果不能给出一定的解释规则
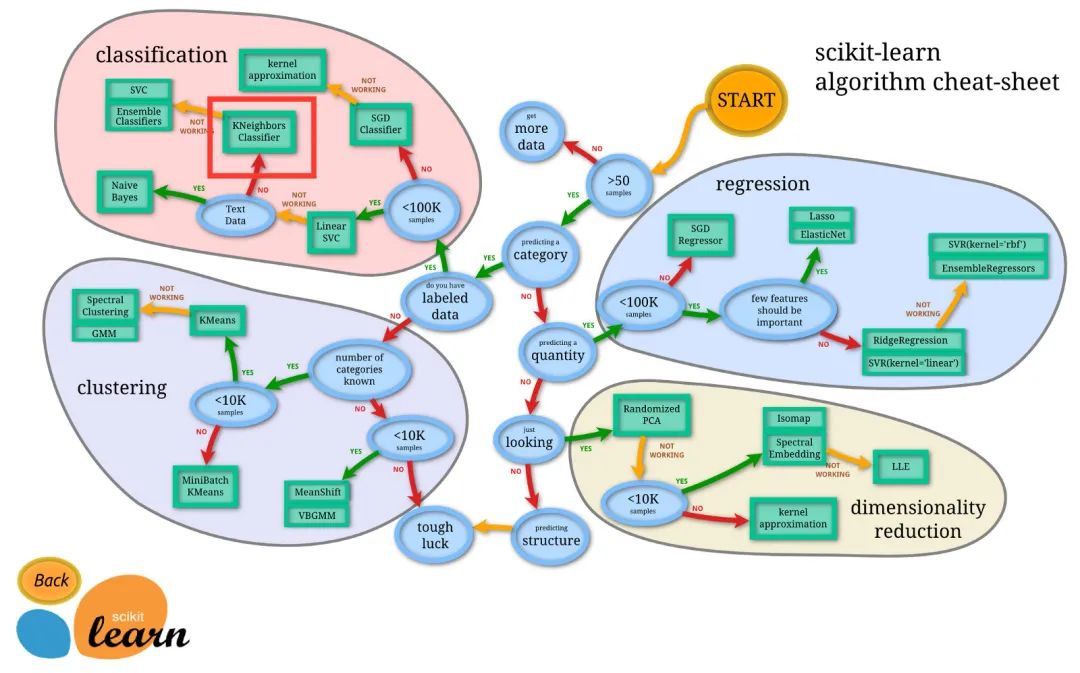
什么时候使用 KNN 算法?scikit-learn 官方中的一张图给出了一个答案:
7、KNN算法实现
下面通过一个简单的算法来实现 KNN 算法,主要步骤为:
创建数据集合和标签 利用欧式距离,使用 KNN算法进行分类计算欧式距离 距离的排序(从大到小) 统计 K 个样本中出现次数多的,归属于该类别

作者简介 Peter,硕士毕业僧一枚,从电子专业自学Python入门数据行业,擅长数据分析及可视化。喜欢数据,坚持跑步,热爱阅读,乐观生活。个人格言:不浮于世,不负于己 个人站点:www.renpeter.cn,欢迎常来小屋逛逛
本文来自公众号读者投稿,欢迎各位童鞋向公号投稿,点击下面图片了解详情!

往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/y7uvZF6
本站qq群704220115。
加入微信群请扫码: