
学习bert过程中的思考,少走弯路

向AI转型的程序员都关注了这个号???
机器学习AI算法工程 公众号:datayx
最近参加了一个nlp的比赛,做文本情感分类的。发现传统神经网络的效果的确赶不上bert。就研究了一下bert。其实真正运行bert的操作非常简单。但因为找不到教程在最初还是走了很多弯路的。
但在走弯路的同时我觉得我学到了很多之前不知道的东西,就用这篇博文记录一下。我觉得这些思考和收获让我对模型的理解和使用水平都提高了一个层次。甚至我后面跑起来bert很大程度上也要归功于这期间对模型理解的提升。
这篇博文的内容都不仅适用于bert。
防止神经网络模型过拟合的两种基本方法
1.dropout
dropout就是在训练的时候随机的使一部分神经元冻结
代码实现可以像这样:

2.正则化
正则化相当于一个惩罚项,可以防止模型变得过于复杂。
1)L0范数
L0范数是指参数矩阵W中含有零元素的个数,L0范数限制了参数的个数不会过多,这也就简化了模型,当然也就能防止过拟合。
2)L1范数
L1范数是参数矩阵W中元素的绝对值之和,L1范数相对于L0范数不同点在于,L0范数求解是NP问题,而L1范数是L0范数的最优凸近似,求解较为容易。L1常被称为LASSO.
3)L2范数
L2范数是参数矩阵W中元素的平方之和,这使得参数矩阵中的元素更稀疏,与前两个范数不同的是,它不会让参数变为0,而是使得参数大部分都接近于0。L1追求稀疏化,从而丢弃了一部分特征(参数为0),而L2范数只是使参数尽可能为0,保留了特征。L2被称为Rigde.
模型融合
忽然发现keras的代码真的好用,我之前以为keras的模型都必须先定义好,然后整个compile,其实不是,做好的模型也可以接层,比如这样:
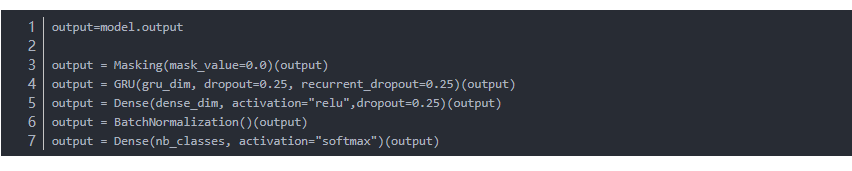
第一个model就是封装好的albert模型,这样就对albert加了一层随即遮挡,一层GRU,一层前馈,一层归一和最后的一个输出层。
输出的归一化
有一段时间我的模型出了这样一个问题,就是他的预测类别都会是同一个值。为什么会有这个问题呢?
先来看一看常用的输出层激活函数:sigmoid和softmax的图像
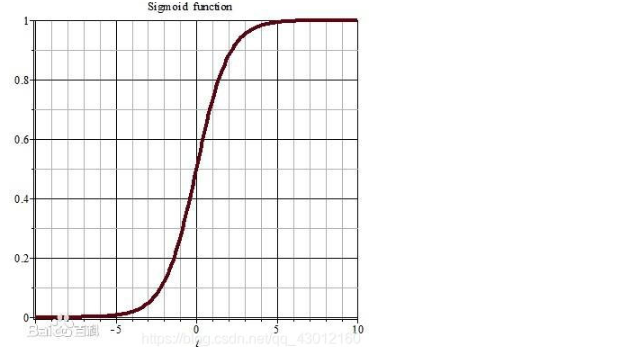
softmax的:

对于(-∞,-5]∪[5,+∞)的大部分数据,他们的值都会非常的趋近0/1,所以要是数据不至于大部分分布在这些没有区分度的区域,我们要把数据全都归约到中间有区分度的部分。即在输出层前:

按道理说是这样的,后来我发现我的错误其实是因为一个维度错误。。。
低学习率
优化器的学习率最好低一点,我现在一般设(1e-5)。
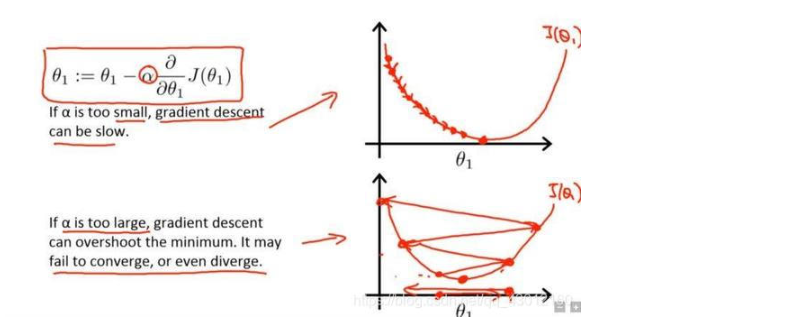
我们都知道模型的训练是一个梯度下降求极值的过程。
图1就是低学习率的情况,图2就是学习率比较高的情况。
较高的学习率可能导致梯度下降时步长过大,无法准确达到极值。
所以优化器一般设置低学习率。
finetune
fine-tune是迁移学习中的一个概念。bert就可以看作是一种迁移学习。
迁移学习就是先用一些通用数据进行训练,再根据实际任务进行单独的训练。
比如bert,bert就是google用维基的中文语料进行的预训练产生的模型。
(就是bert里的那个非常大的ckpt文件)
然后我们在要用的时候再根据自己的任务对模型进行针对性的训练(fine-tune),让它执行针对性的任务。
我的理解是预训练的时候应该是要冻结输出层的,只训练中间层,类似于构造生成词向量的过程。然后我们fine-tune的时候主要是对输出层进行训练,道理类似于根据已有的词向量构造预测的过程。
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码