
混沌工程推动可观测性的最佳实践 | IDCF

来源:混沌工程实践 作者:水球潘/JohnnyPan
本文中,我们使用 DDD 领域建模的方法,设计了一个合理且复杂的微服务叫车系统,并在该系统之上,利用OpenTelemetry进行了可观测性构造实践,最后采用“强化混沌工程”的方法论,借助故障注入手段,实现了用于验证可观测性价值的最佳实践,并将游戏冲关的玩法融入软件开发的生命周期中,提升应用的排障能力,以此降低系统的MTTR。
一、一个类 Uber 叫车试点应用

为了达到应用可观测性构造的效果,需要设计一个足够复杂的试点应用,这里我选择了这个类 Uber App 的设计和开发。
1.1 领域建模
首先,通过领域驱动设计DDD的事件风暴,集众人之力完成该试点应用的领域模型设计:
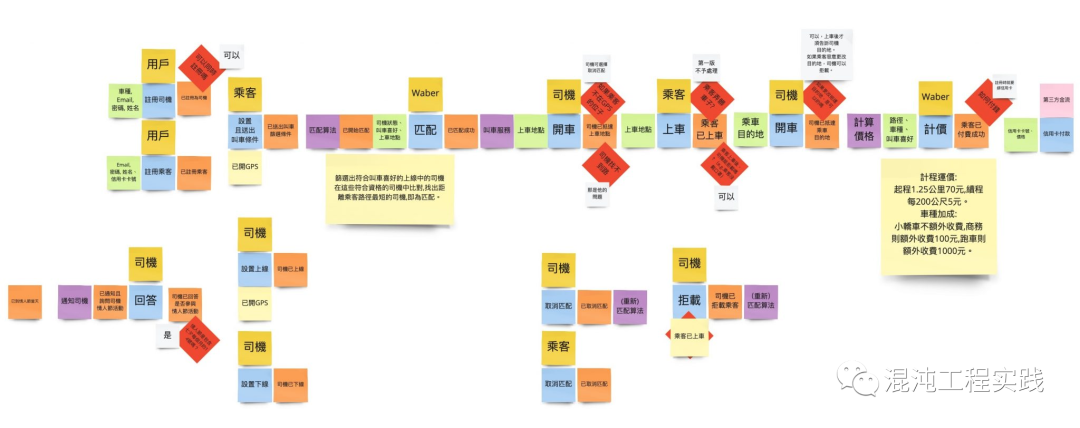
随后观察领域中重复出现的名词,找出限界上下文:
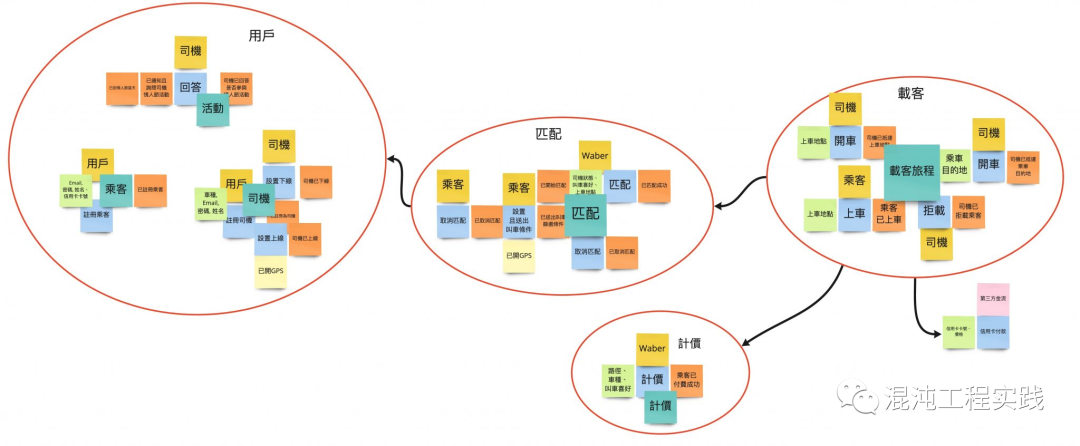
这样,类 Uber 叫车试点应用的领域模型建模完毕。
1.2 微服务架构设计
接着,我们继续设计试点应用微服务化的系统架构:
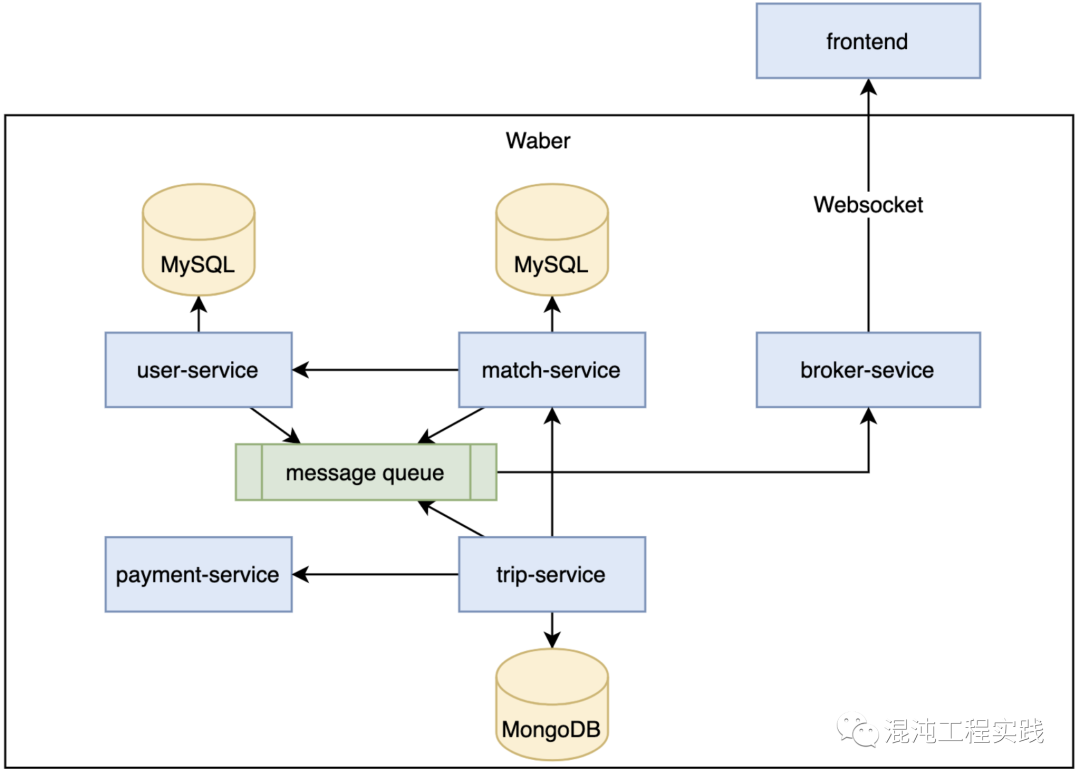
类 Uber 叫车试点应用有五个微服务,其中四个是由限界上下文衍生出来的,包括:
- User 乘客
- Match 叫车匹配
- Trip 载客旅程
- Payment 支付金流
二、OpenTelemetry 构造可观测性
平常在开发环境中,遇到Bug的时候为求方便,都会开启调试器,借助中断来确认应用的行为是否符合预期,但是,一旦应用部署到各环境中,便不能再使用调试器来观察应用的行为了。
所谓的可观测性,指的是应用在被部署到某个线上环境后,其本身还能透过“某种机制”来让开发人员,便捷地观测应用本身在线上“各个时间点”的行为。
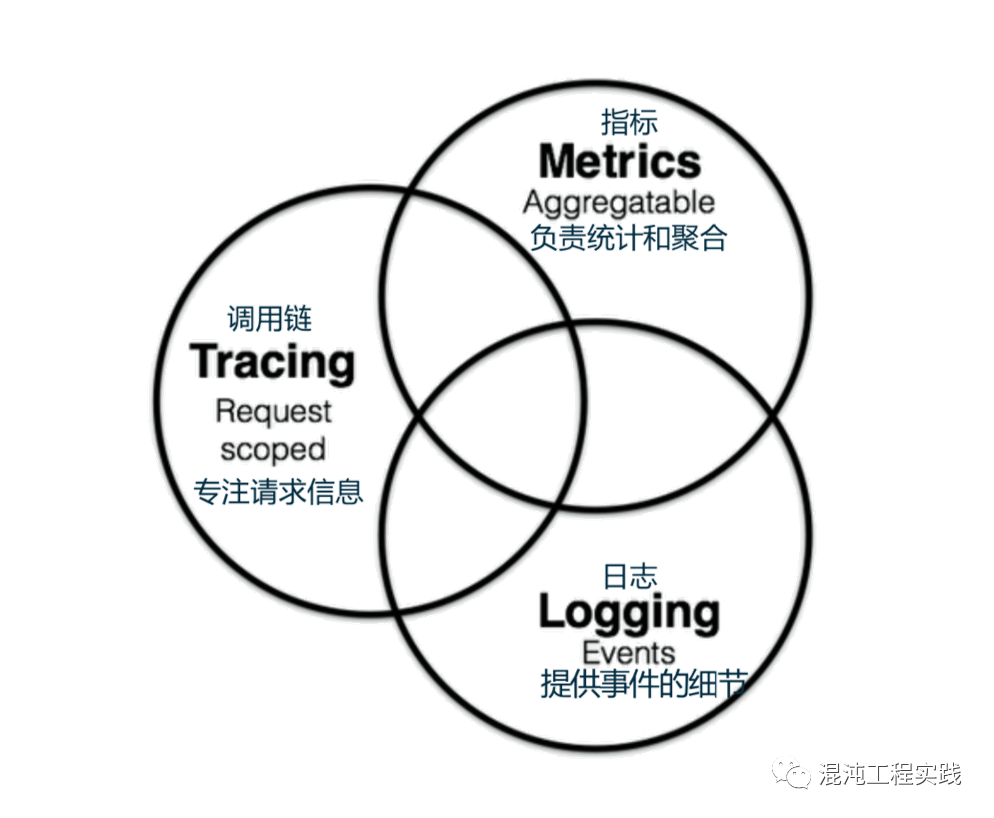
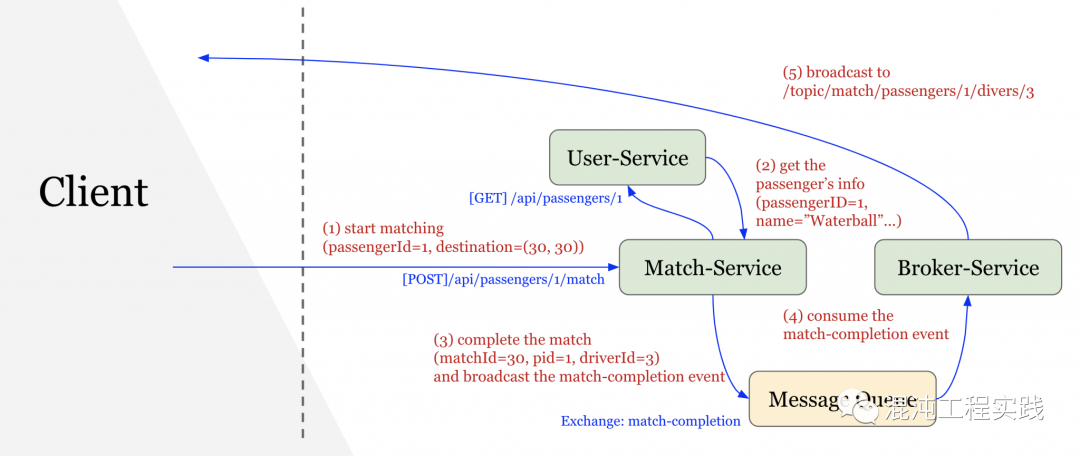
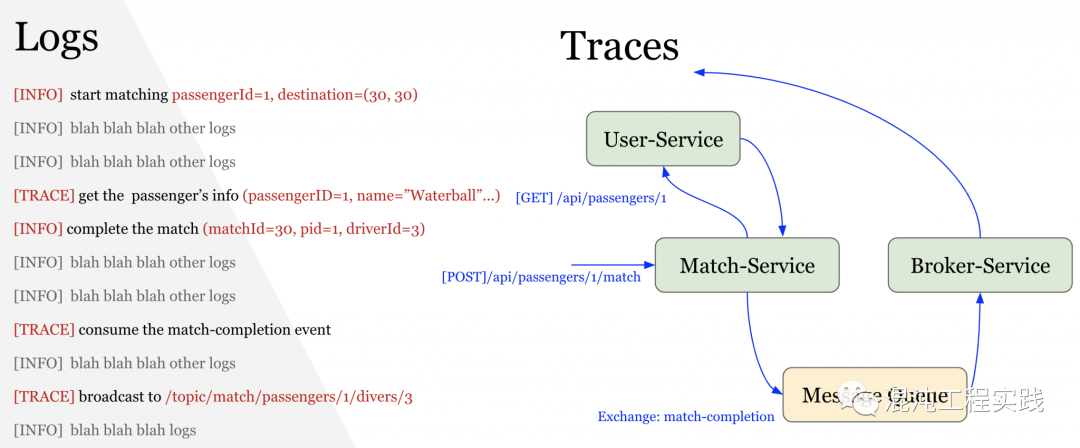
OpenTelemetry的发明并非要解决新的问题,而是一个在可观测性三大支柱的需求下,实现单一标准的框架。我们决定要尝试OpenTelemetry这一项CNCF近期推出的技术框架。我们先来看一下在以前,我们都是如何做到分布式链路追踪的?OpenTracing + Jaeger:
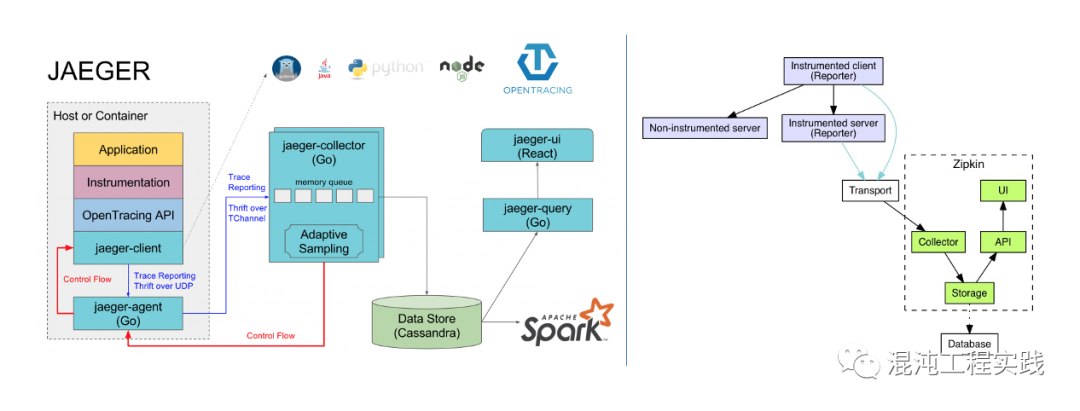
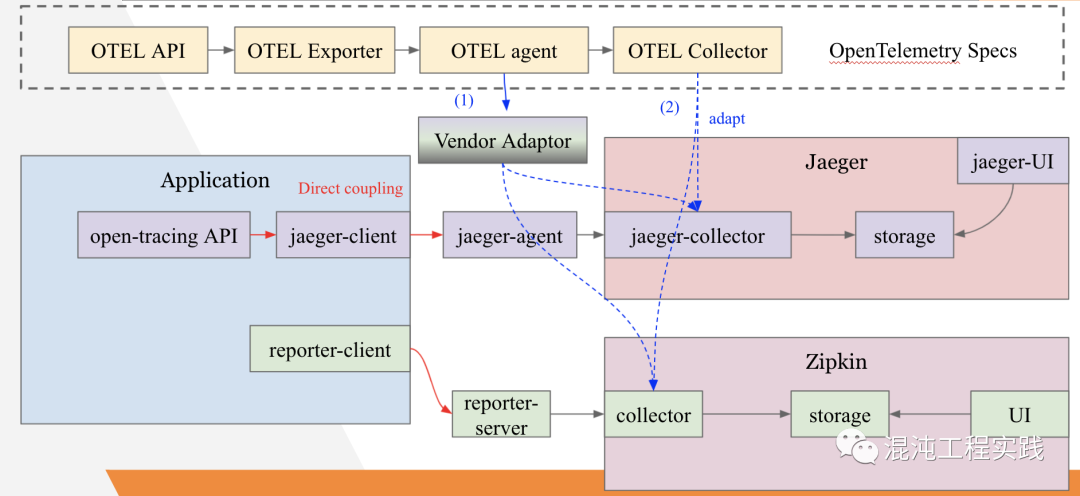
为了要在应用中做分布式链路追踪,以往我们都必须直接依赖厂商链路追踪产品的SDK来去埋点,但如此一来,未来如果决定要更换厂商时,则应用会有很大一部分需要重写。OpenTelemetry扮演的就正是那一层抽象的标准接口,如果应用依赖的是OpenTelemetry的API,那未来要更换厂商时,就只需要改变OpenTelemetry的配置就行,任何一行代码都不需要重写。2.3 Java Agent 的自动采集首先要先到Github下载OpenTelemetry最新释出的Java Agent JAR。https://github.com/open-telemetry/opentelemetry-java-instrumentation/releases接下来只需要将这个JAR,在Dockerfile中将其COPY到镜像中,然后在CMD中有关Java的执行指令中,添加javaagent参数,将其指向JAR的位置,一并执行就行。

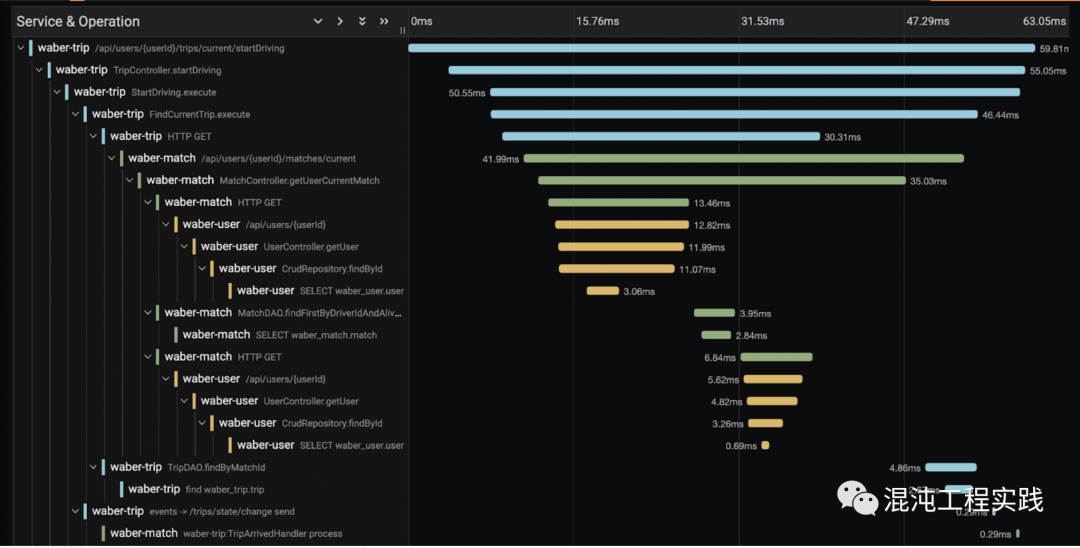
- 第一种方法:由环境变量去设置 include / exclude 的类别或方法。
- 第二种方法:使用 @WithSpan 来增加想要被放进 Trace 的方法。
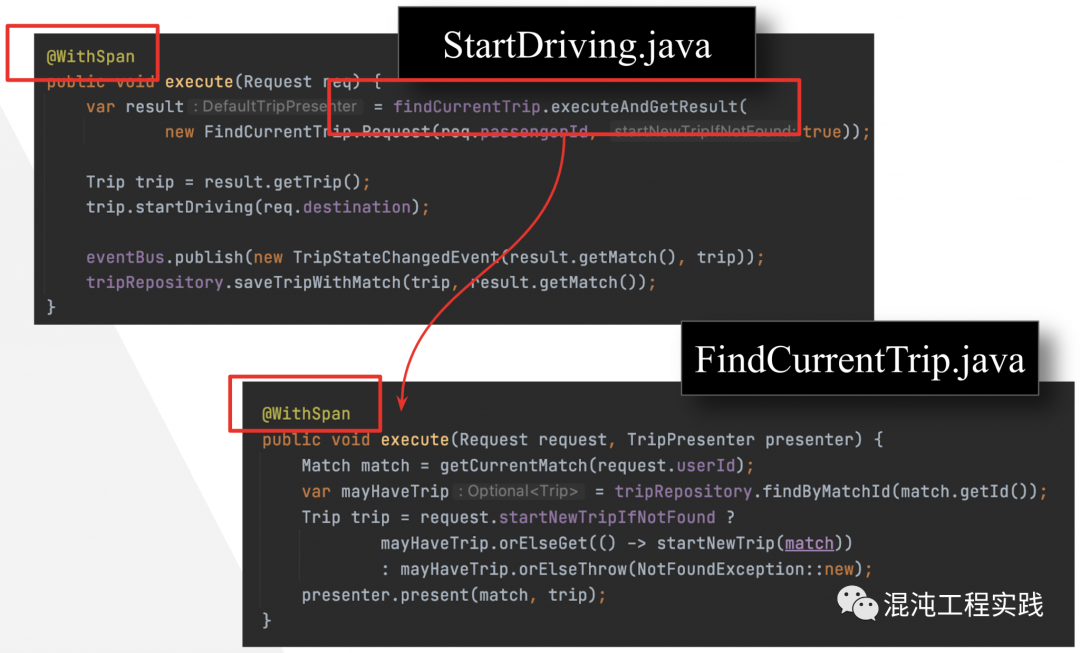
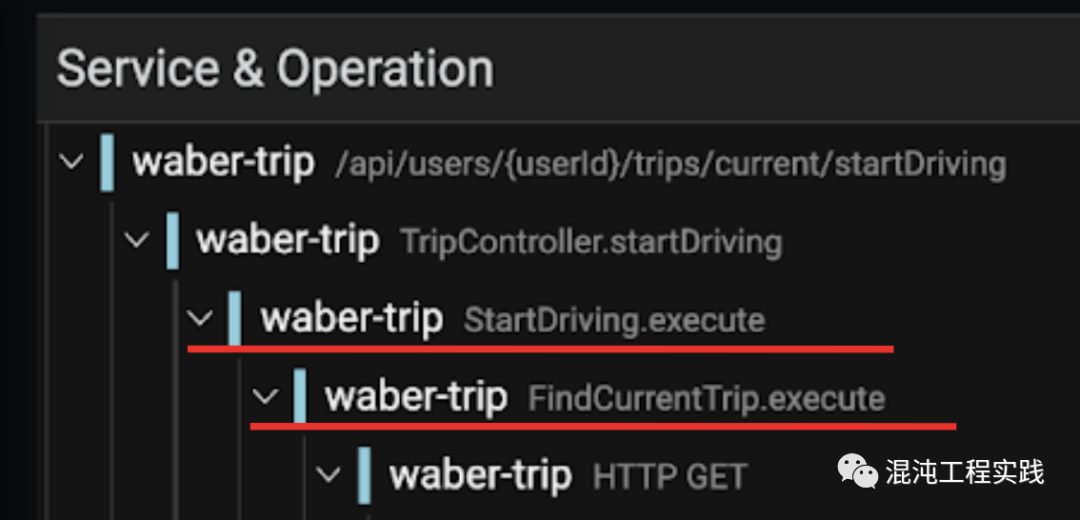
一直以来,SRE 都希望能够最小化可观测性构造实践,以减少其所带来的额外维护成本。因此,我们需要一种新的最佳实践,来证明可观测性构造的价值。
三、推动可观测性的最佳实践
 经过了思考与设计,最后我参考了混沌工程的精神,开发出一个方法,可以告诉我“目前的可观测性实践是否仍有缺陷”?我把这个方法称之为“强化混沌工程”。3.1 叫车流量的自动化模拟但是,目前仅有一个类 Uber 的叫车系统,还需要模拟乘客和司机的行为,来自动化地产生合理的叫车流量。
经过了思考与设计,最后我参考了混沌工程的精神,开发出一个方法,可以告诉我“目前的可观测性实践是否仍有缺陷”?我把这个方法称之为“强化混沌工程”。3.1 叫车流量的自动化模拟但是,目前仅有一个类 Uber 的叫车系统,还需要模拟乘客和司机的行为,来自动化地产生合理的叫车流量。 如上所附的动画所示,在经过数日的开发后,终于做出了一个简单的自动化叫车流量产生系统。动画中呈现的是五个司机和一个乘客的情况模拟。
如上所附的动画所示,在经过数日的开发后,终于做出了一个简单的自动化叫车流量产生系统。动画中呈现的是五个司机和一个乘客的情况模拟。| 序号 | 描述 |
|---|---|
| 1 | 乘客进行叫车匹配 |
| 2 | 系统完成匹配,并且匹配到了某一司机 |
| 3 | 该名司机开始此次载客服务,并且朝着乘客的上车地点开车,移动的过程中不断地向伺服器更新自身座标 |
| 4 | 乘客进行叫车匹配 |
| 5 | 系统完成匹配,并且匹配到了某一司机 |
| 6 | 该名司机开始此次服务,并朝着乘客的上车地点开车,移动的过程中不断地向服务端更新自身座标 |
| 7 | 乘客不断接收到司机最新的座标 |
| 8 | 司机抵达乘客的上车地点,确认乘客上车后,司机将状态调整成“已上车” |
| 9 | 司机开车前往目的地,移动的过程中不断地向服务端更新自身座标 |
| 10 | 司机抵达乘客欲前往的目的地,结束了服务 |
| 11 | 叫车流程结束,乘客将自己的座标更新到了随机的位置并开始了下一次的叫车匹配 |
看似简单的叫车流程,其背后的工作其实是必须由五个微服务以及 RabbitMQ 来协作完成的,现在我们已经能够创造大量且合理的叫车流量,总算可以来开始实践“强化混沌工程”了。
3.2 强化混沌工程
从 SRE 的视角上,可观测性构造的价值在于,我们要花多少时间才能够察觉并修复好生产系统发现的问题,即 MTTR。
现在已经有了“自动化叫车流量生成器”,也有评判可观测性构造的标准MTTR,那剩下我最缺的就是“故障”了。
微服务等分布式系统在开发和运维上带来更高的门槛和复杂度,因此混沌工程便也开始被不断提倡。讲白一点,混沌工程就是“有目的地对待测系统搞破坏来提早揭露系统的问题”。
为了揭露系统的问题,我们需要先对待测系统定义其稳态。以类 Uber 叫车试点应用来说,稳态便是“能够完整且顺畅地执行每一个叫车流程”。
借鉴了混沌工程的思维,将其运用到可观测性场景中的话,则是“要有目的地在系统中搞破坏来提早揭露可观测性构造的缺陷”。
对此,由于使用场景较为特殊,是否有现存的第三方工具,能够满足类 Uber 叫车试点应用定制化的混沌场景,我并没有太大的自信,因此我决定自己实作一个能够实现混沌工程的技术架构,以下图所示:
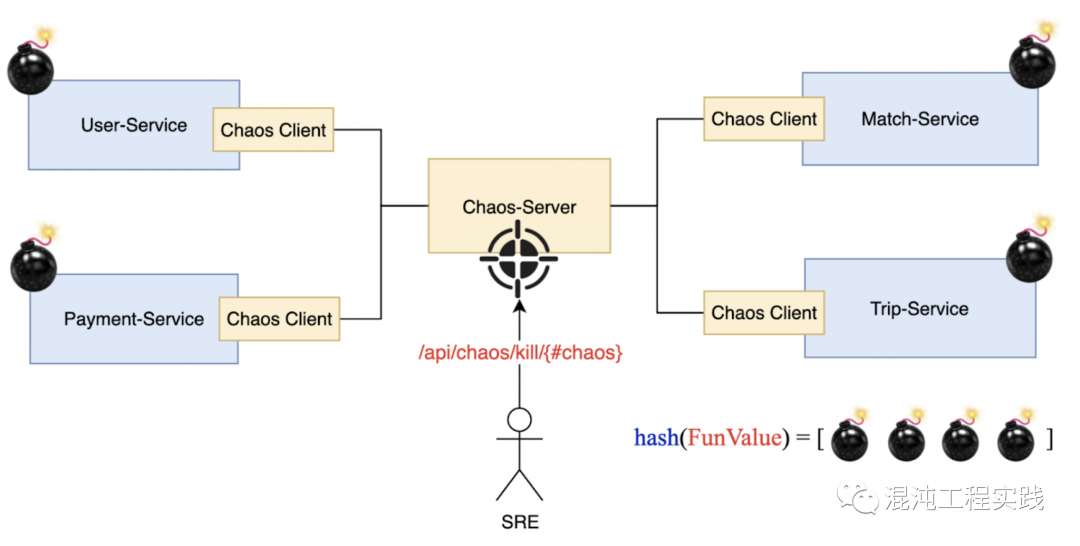
新开了一个服务在图正中央,称之为Chaos-Server。
而在应用各个服务中都会执行一个Chaos Client ,即Chaos Agent。
Chaos-Server和各个Chaos-Client互相沟通,传递指令,来实现整个混沌工程的流程。
我们只需要在Chaos的操作页上对Chaos-Server下达命令就好。
3.3 冲关游戏的基本玩法
我们把混沌工程的流程设计成了一款冲关游戏,下面是基本的玩法:
| 序号 | 步骤描述 |
|---|---|
| 1 | 部署好Chaos-Server和Chaos-Client,启动自动化叫车流量生成器。 |
| 2 | 浏览Chaos操作页 /api/chaos ,这个页面可以用来对Chaos-Server下达指令。 |
| 3 | 开始一个新的关卡:每一个关卡都可以由一串随意的字串来产生。 |
| 4 | 调用 API,如/api/chaos/fun/56a8d709-9c22-489e-b44e-6d86f81796b2,其中的随意字串就是新关卡的唯一标识。 |
| 5 | 一群特定未知的Chaos就被埋好在应用的各个服务中了。 |
| 6 | 接下来继续在Chaos操作页上进行,操作页上会显示所有候选的Chaos名单,并且还会显示在这些Chaos中,有几个真的被激活了。 |
| 7 | 冲关开始后,自动化叫车流量生成器便会进入到“不稳定”的状态,由于Chaos的缘故,叫车流程将会受到影响而被阻断。因此我们可以开始进行排障了。 |
| 8 | 在排障过程中,利用可观测性构造去观察应用行为,看看能否在最短的时间内找出问题来。 |
| 9 | 一旦找到任何潜在的问题,对照Chaos操作页上的名字,选择最可疑的那一个将其杀掉。 |
| 10 | 由于Chaos的名字直接以破坏的内容进行命名,因此我们能根据名字来去进行揣测。 |
| 11 | 如果杀掉成功,则Chaos的数量会少一个。反之,则会显示讯息:”You are mis-killing trip.SaveTripDelay, he is not the mole!”。 |
| 12 | 反反覆覆地游玩,直到将所有Chaos赶尽杀绝为止。 |
| 13 | 如果最后发现无法通关,则代表可观测性不够完整,此时应该要记下笔记,对原先的稳态假说进行修正,并再次进行同一个关卡。 |
3.4 体验一次真正的冲关游戏
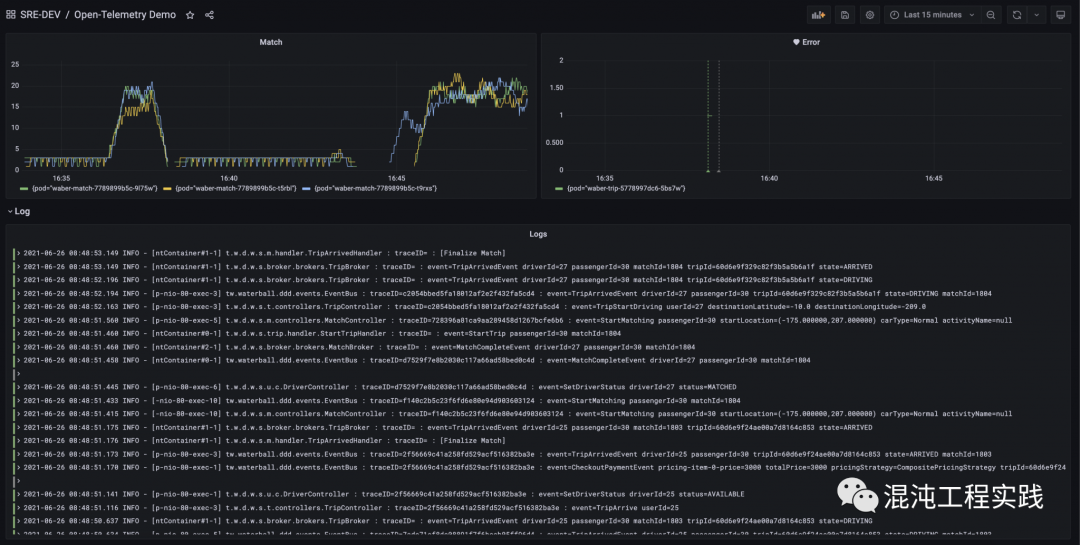
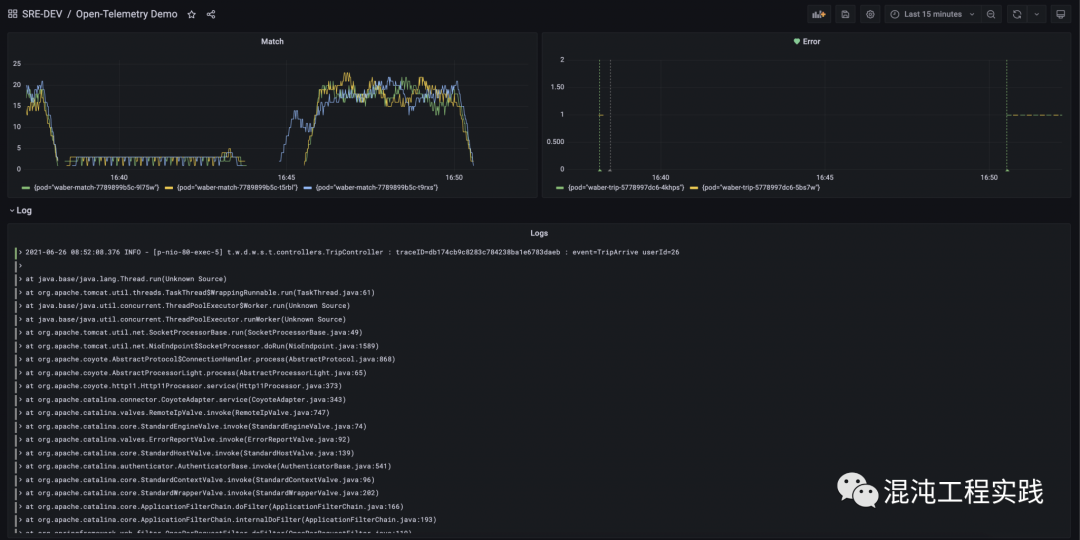
首先到Grafana的仪表盘上,可以看到三个基本面板:上方为 Metrics,包括:左上为即时的叫车匹配数量,右上为应用中的错误数量;而下方则显示即时的 Logs。
开始一个新的关卡 56a8d709-9c22-489e-b44e-6d86f81796b2:

发现叫车流程整个卡住了,看来,Chaos是真的开始在搞破坏了…。
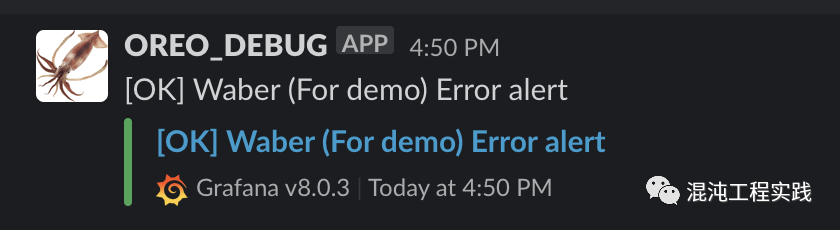
一段时间之后,便在Slack频道上收到了一个错误告警,告诉我们是时候去排障了。
同时也在面板上发现上方叫车匹配的数量急剧下滑,而下方也开始产生出了错误日志:
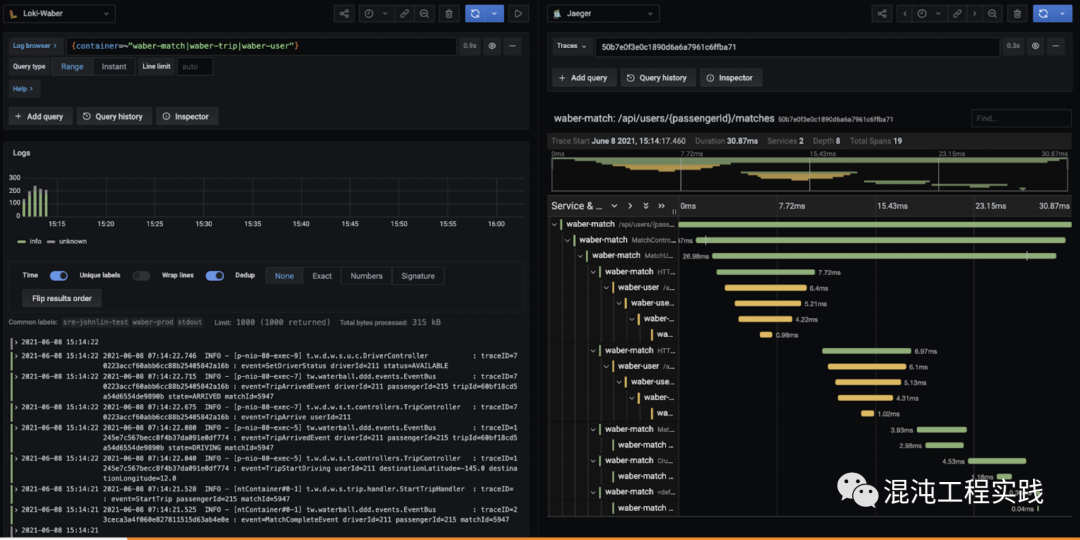
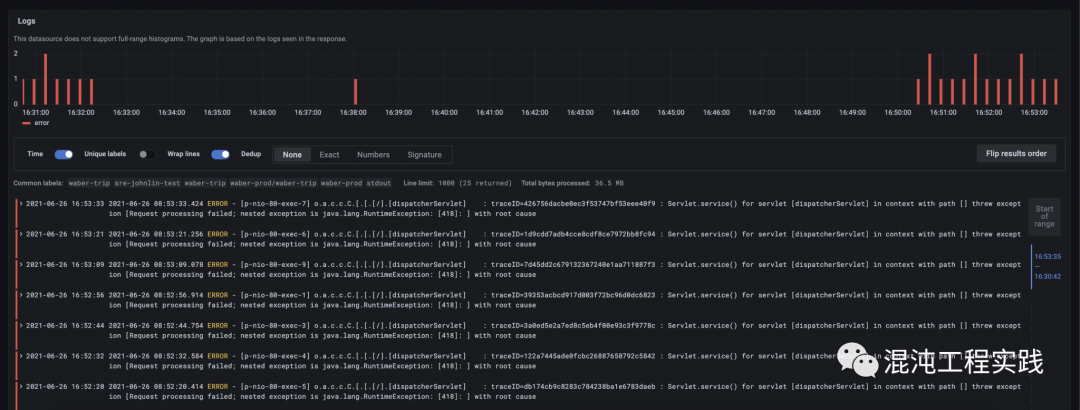
搜索带 “ERROR” 的日志,使用Loki的查询语法:
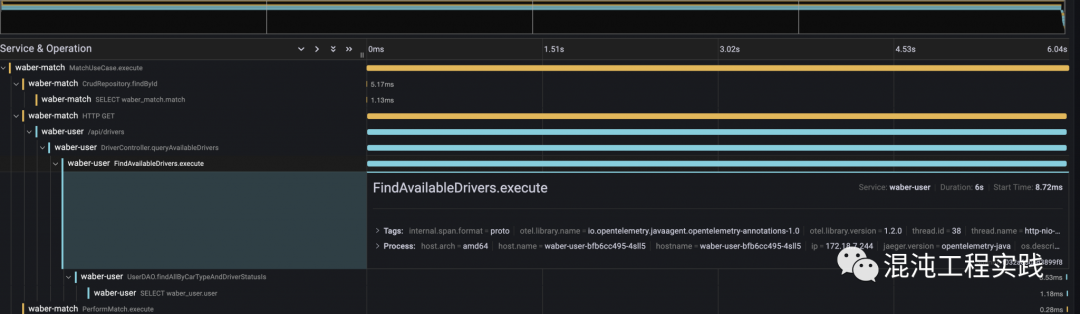
点击其中一个错误日志,并且从日志的 traceID 栏,直接开启右半部 Jaeger 的 trace 页面。
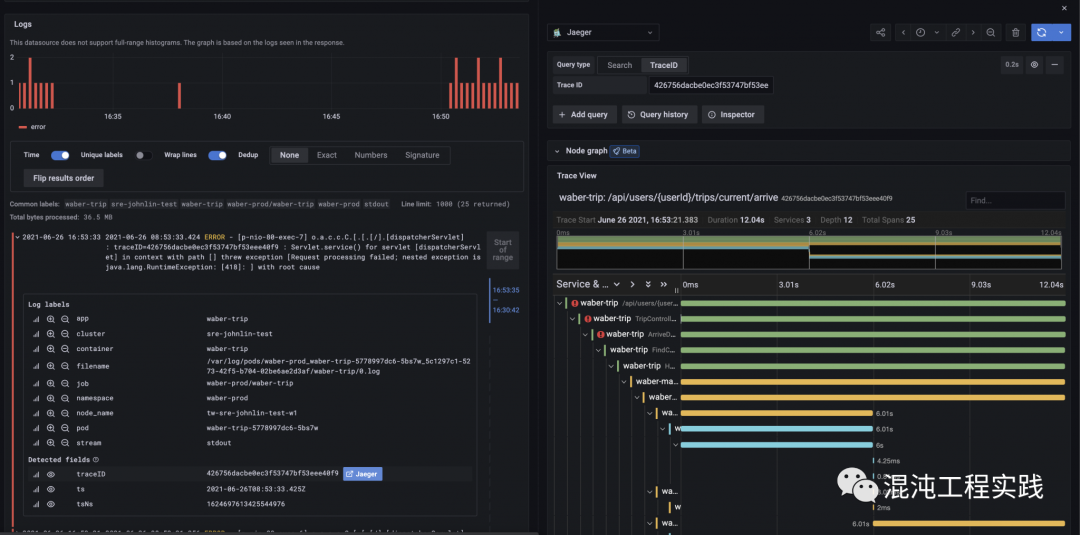
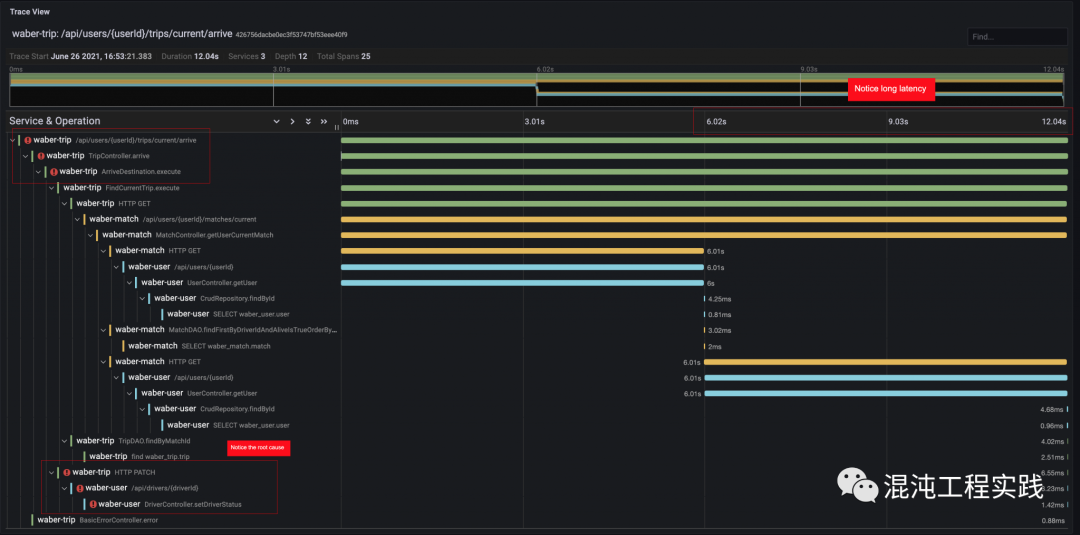
直接从 trace 上观察,可以看到整个微服务的上半部是顺利的,但到下方调用 /api/drivers/{driverId} 这个 API 时发生了错误。
同时,观察这个 trace 的执行时间,竟然高达了12秒!发现瓶颈为 /api/users/{userId} 这个API。
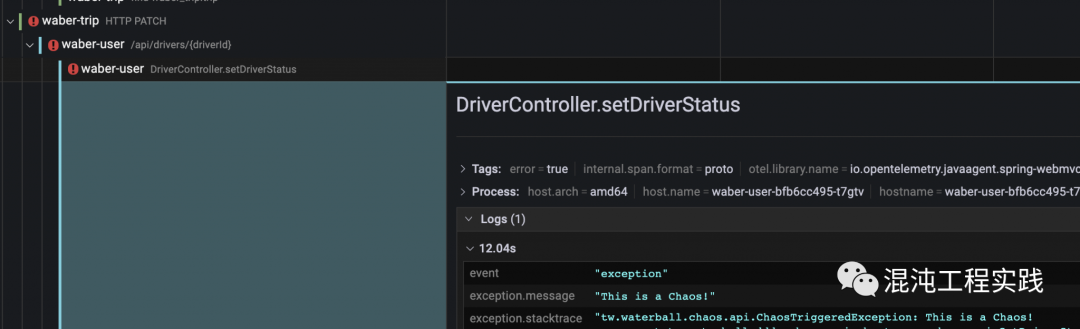
点击 span 可以看到更多详细信息,而从 DriverController.setDriverStatus 这个方法的 span 中可以看见 exception.message 明目张胆地告诉你,它就是Chaos!
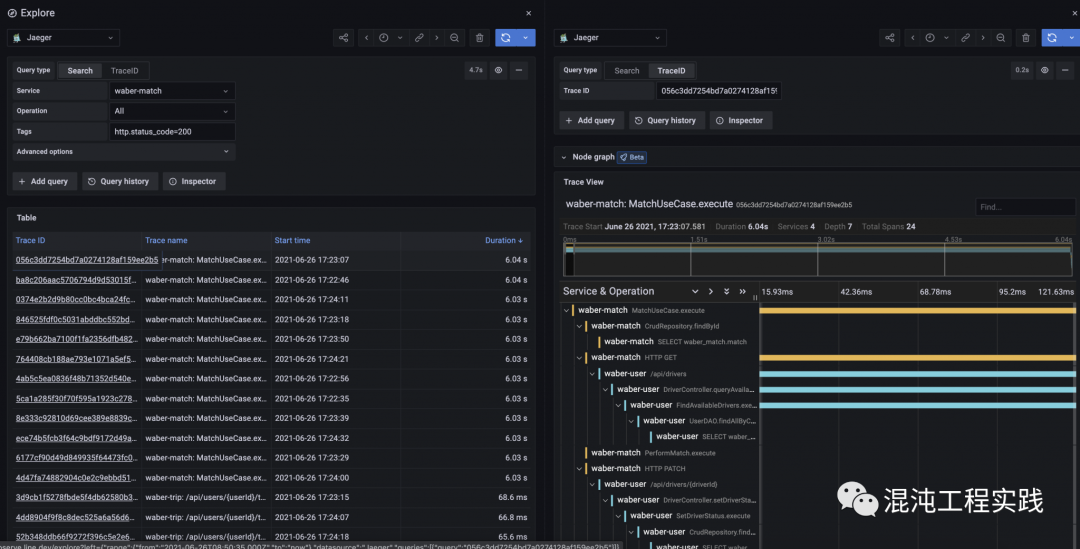
回到操作页面上,把对应到的两个Chaos杀掉:
- user.SetDriverStatusAPIBlocked
- user.FindUserDelay



四、结束语
本文中,我们使用 DDD 领域建模的方法,设计了一个合理且复杂的微服务叫车系统,并在该系统之上,利用OpenTelemetry进行了可观测性构造实践,最后采用“强化混沌工程”的方法论,借助提早揭露实践瑕疵的故障注入手段,实现了用于验证可观测性构造价值的最佳实践方式,以游戏冲关的玩法融入软件开发的生命周期中,提升我们对应用的排障能力,以此降低可观测性构造的MTTR。 IDCF DevOps黑客马拉松,独创端到端DevOps体验,精益创业+敏捷开发+DevOps流水线的完美结合,2021年仅有的3场公开课,数千人参与并一致五星推荐的金牌训练营,追求卓越的你一定不能错过!9月11-12日,上海站,企业组队参赛&个人参赛均可,一年等一回,错过等一年,赶紧上车~👇
IDCF DevOps黑客马拉松,独创端到端DevOps体验,精益创业+敏捷开发+DevOps流水线的完美结合,2021年仅有的3场公开课,数千人参与并一致五星推荐的金牌训练营,追求卓越的你一定不能错过!9月11-12日,上海站,企业组队参赛&个人参赛均可,一年等一回,错过等一年,赶紧上车~👇