
基于 eBPF 的 Kubernetes 可观测实践

背景介绍
Cloud Native
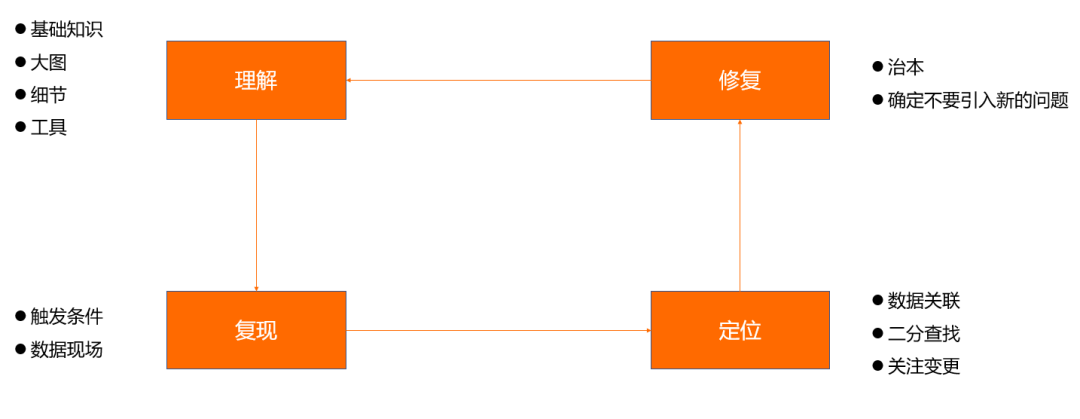
问题排查的原则
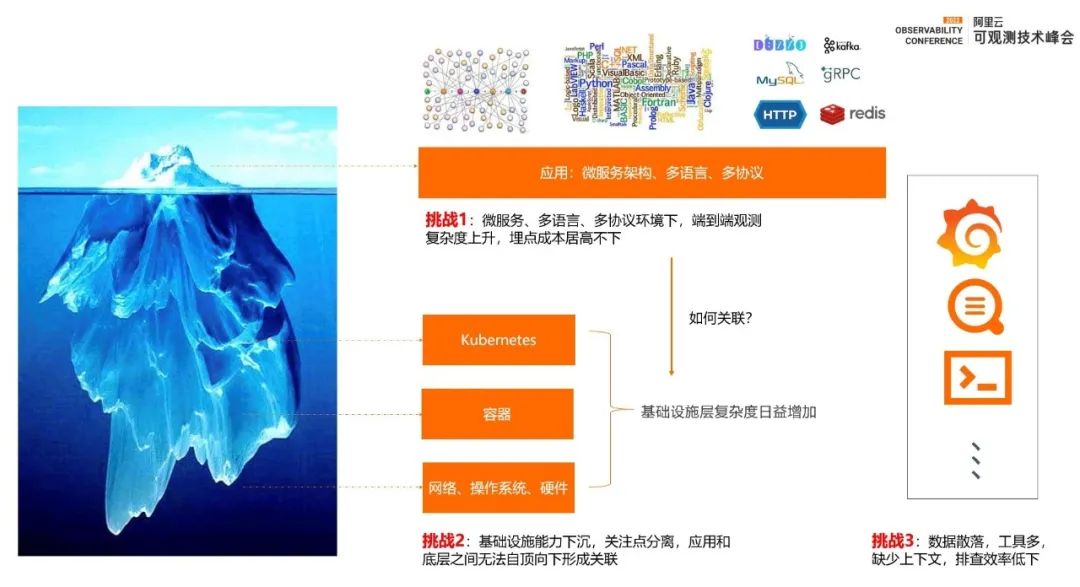
Kubernetes 可观测挑战
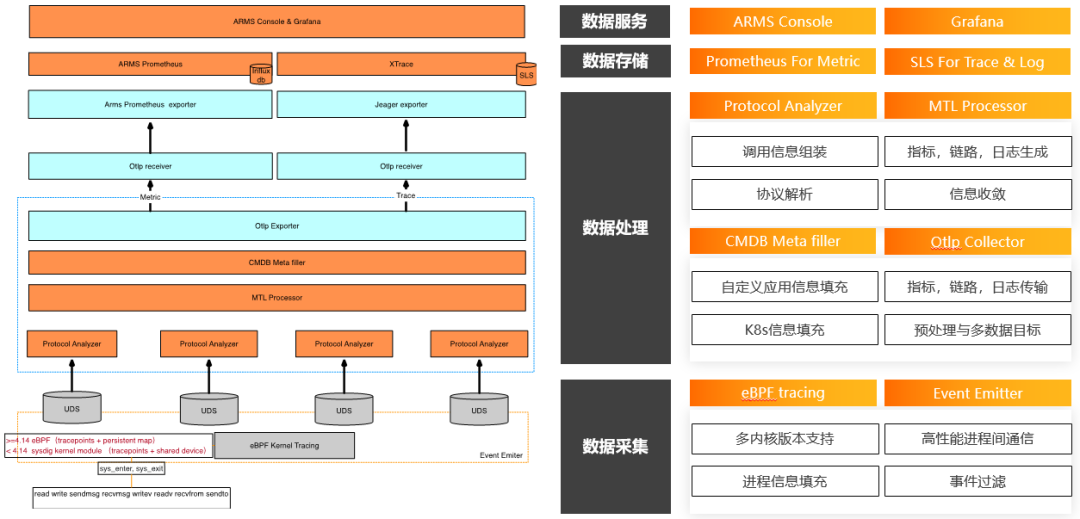
基于 eBPF 的可观测实践分享
Cloud Native
eBPF 介绍
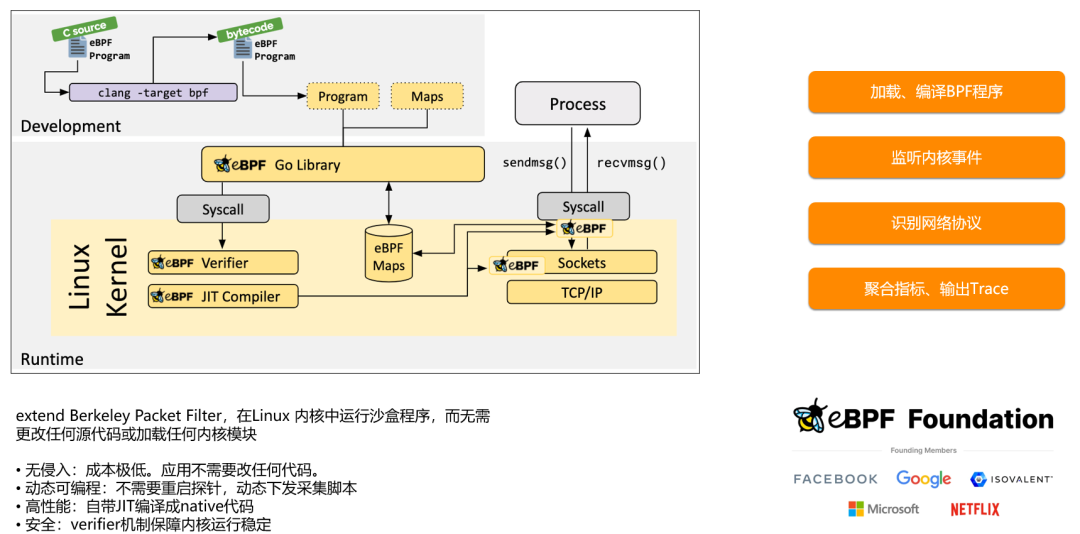
如何进行无侵入式多语言的协议解析
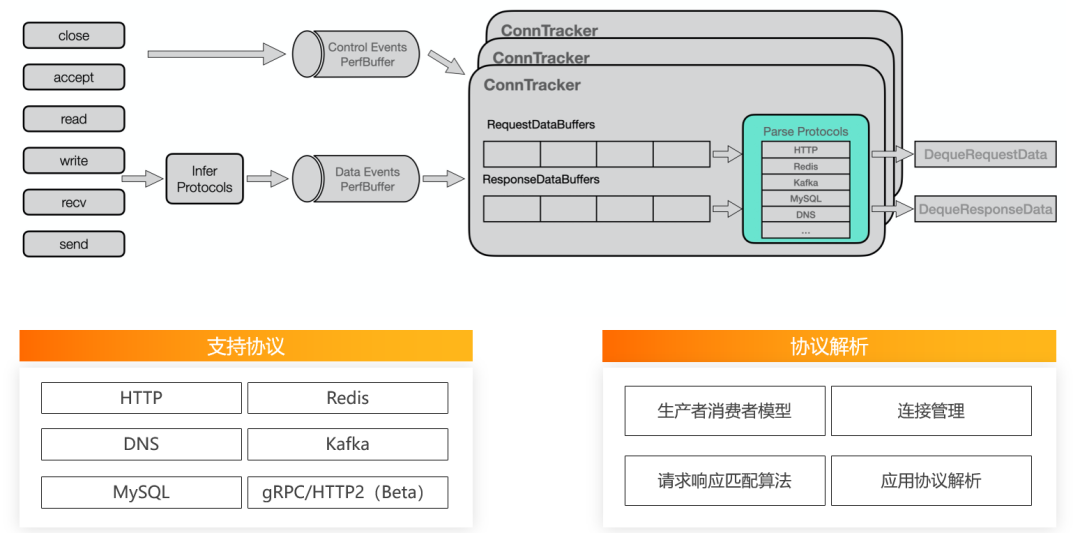
线上问题与解决方法

统一可观测交互界面
Cloud Native
统一告警
eBPF 技术的无侵入性以及多语言支持的特性使得开箱即用成为了可能。基于此,阿里云可观测团队开始构建统一可观测界面。
统一的关联分析逻辑

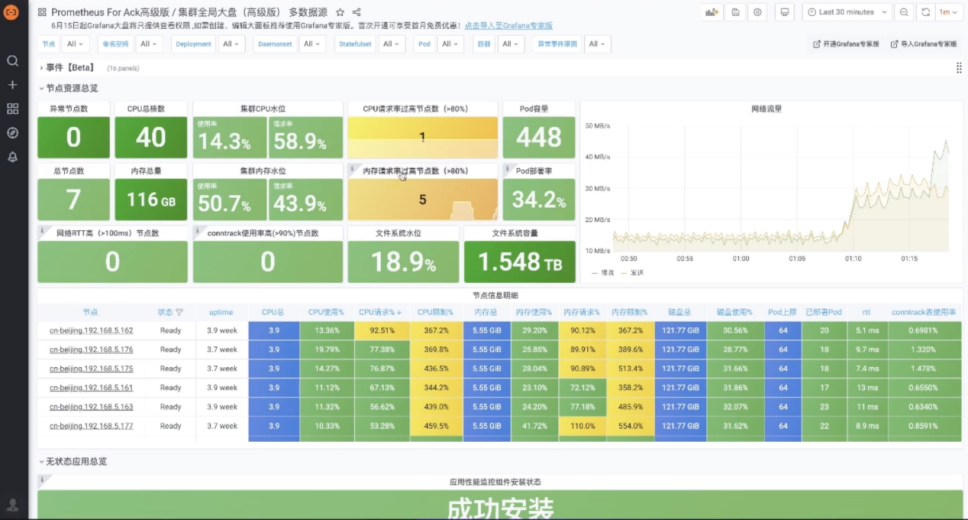
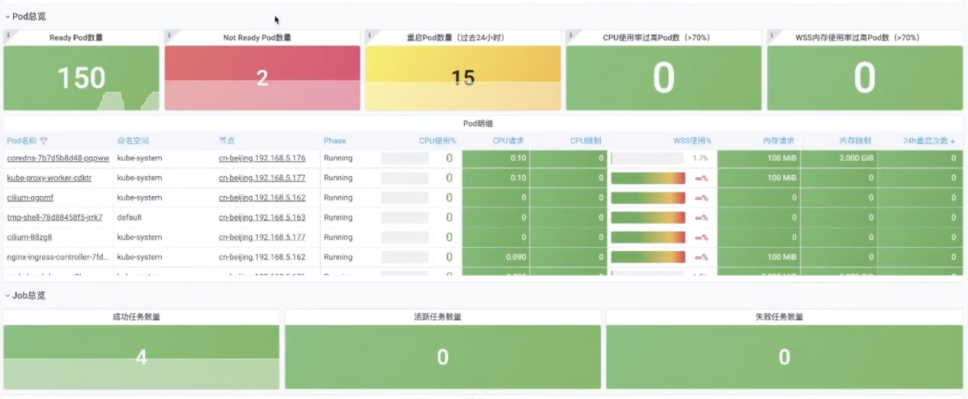
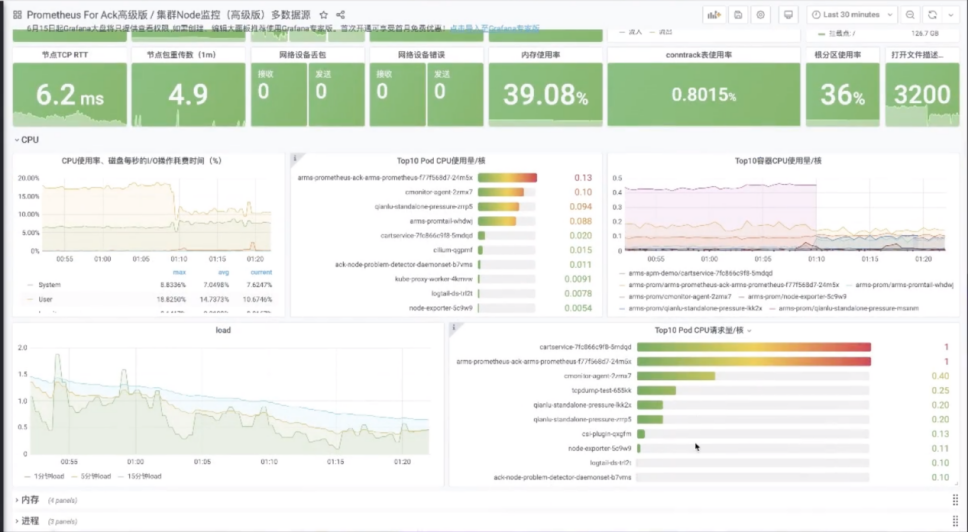
统一 Grafana 大盘
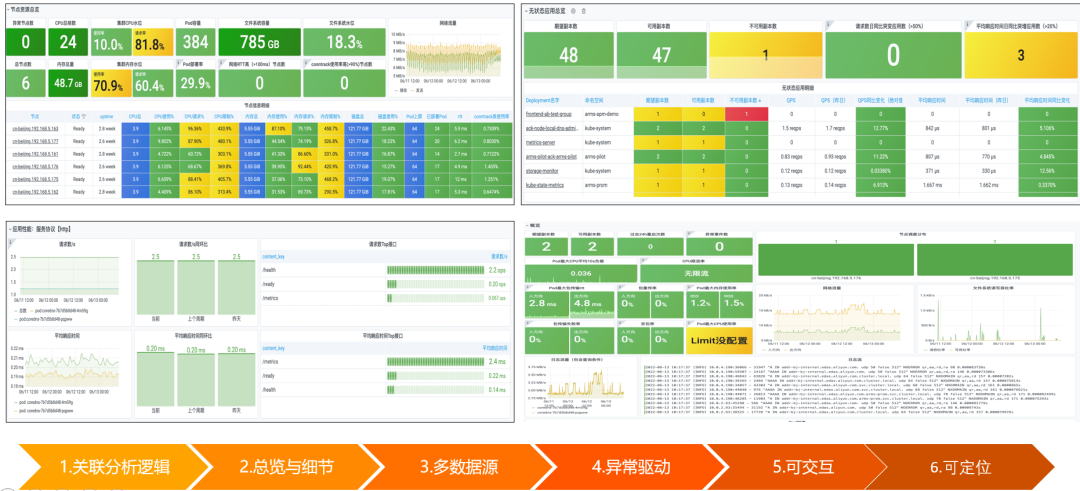
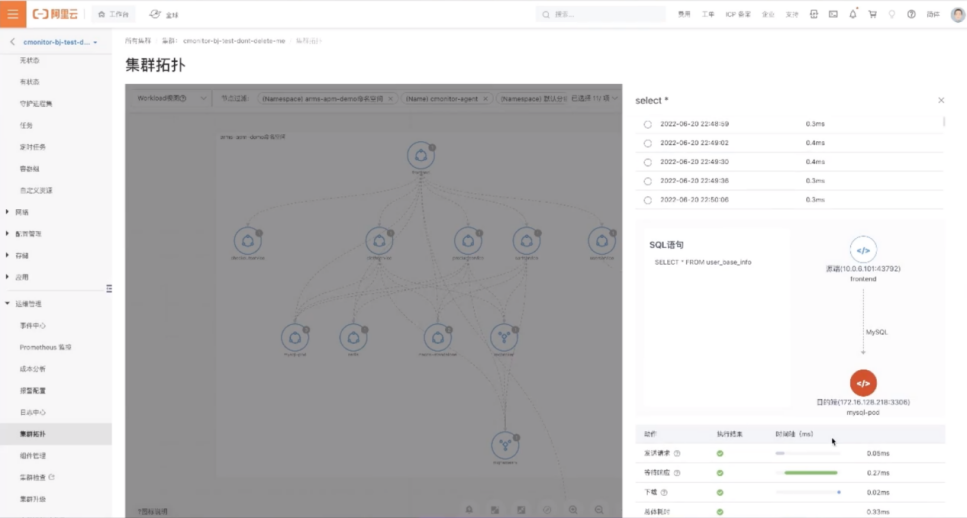
统一拓扑图
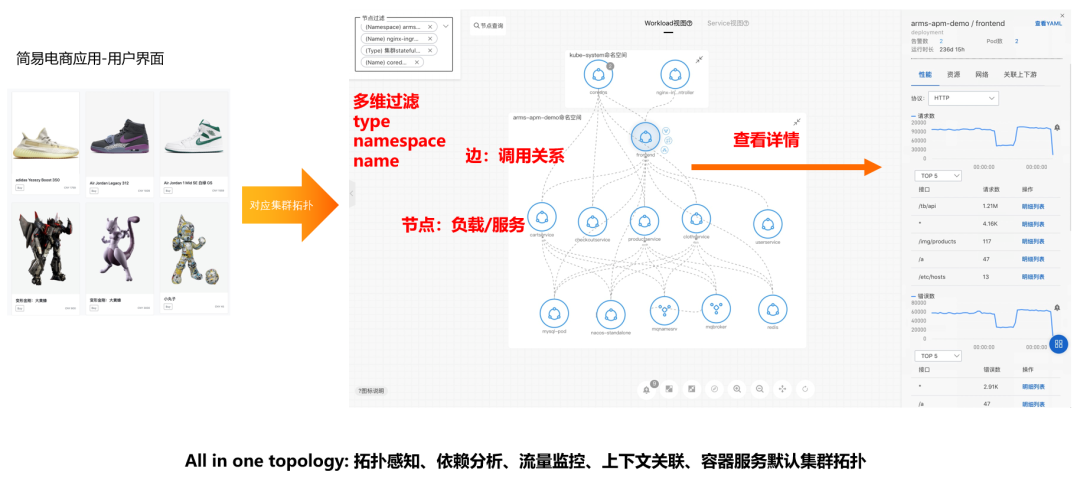
Demo 演示:基于 eBPF 的统一交互页面
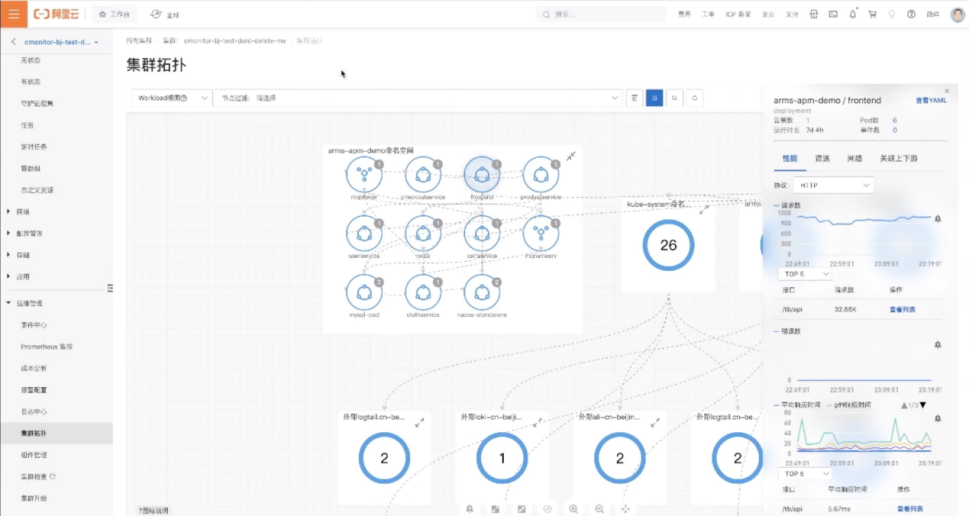
在容器服务 ACK 进入一个集群后,点击运维管理,进入集群拓扑功能页面。如果没有安装 eBPF 探针则会提示安装,安装完成后开箱即用,可以获得整个集群的流量拓扑。

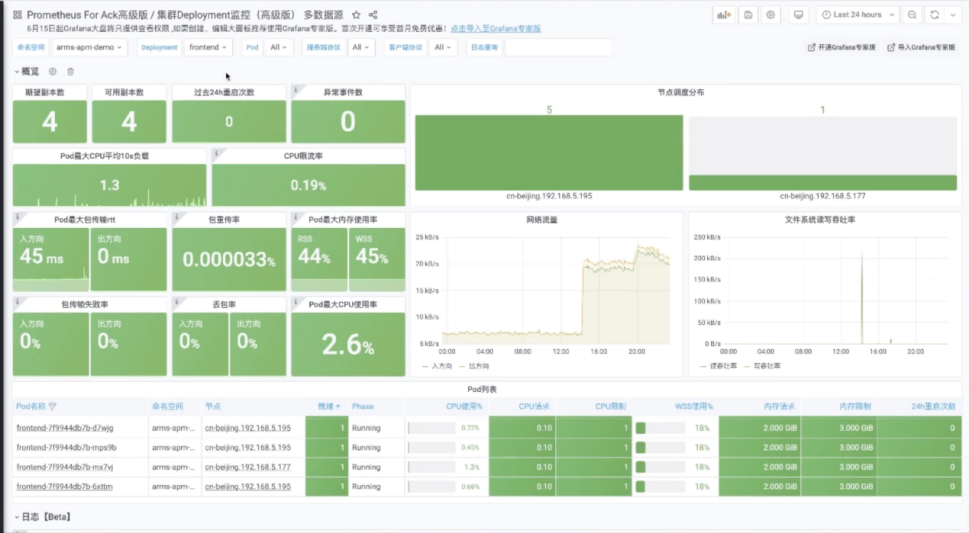
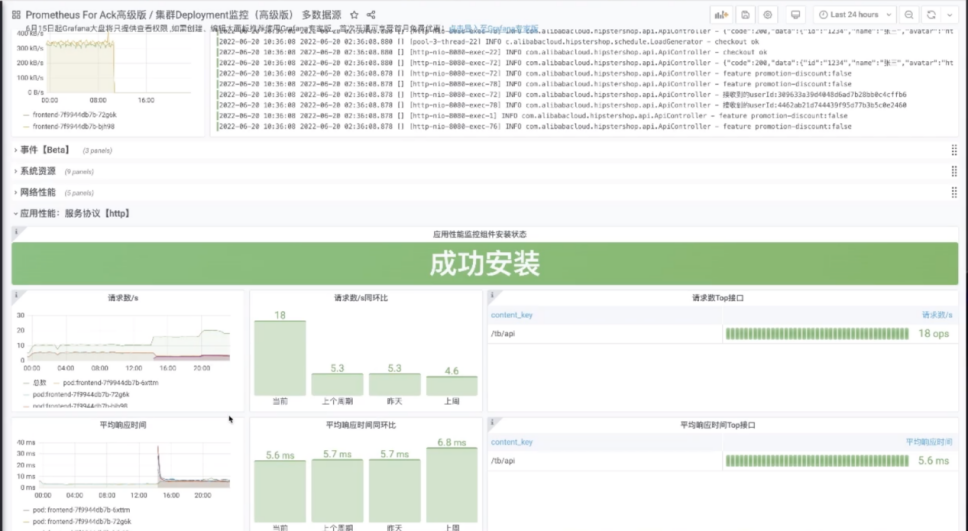
总结与展望
Cloud Native
总结
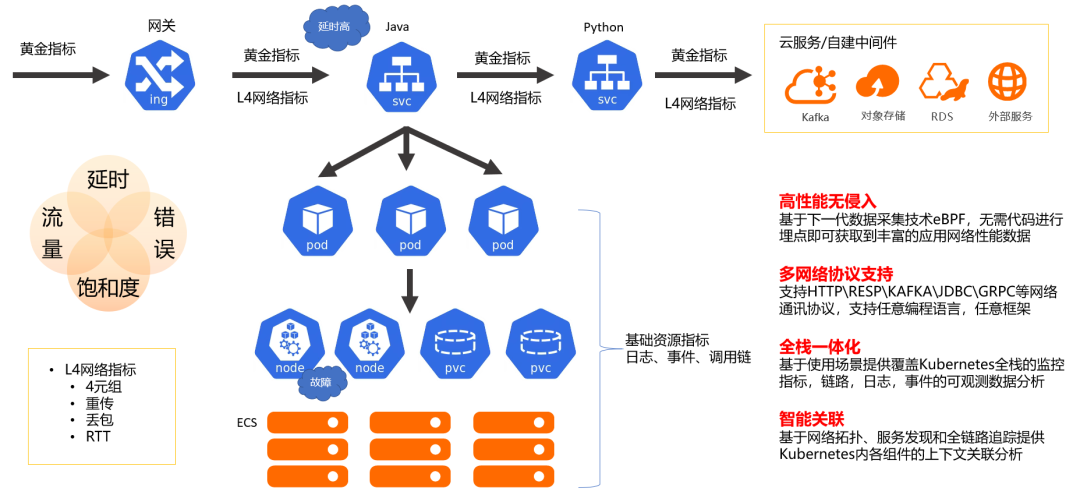
阿里云可观测团队构建了 kubernetes 统一监控,无侵入式地提供多语言、应用性能黄金指标,支持多种协议,结合 Kubernetes 管控层与网络系统层监控,提供全栈一体式的可观测体验。通过流量拓扑、链路、资源的关系,可进行关联分析,进一步提升在 Kubernetes 环境下排查问题的效率。
展望

未来,阿里云可观测团队将进一步挖掘 eBPF 全覆盖、无侵入、可编程的特性,在以下三个方面持续发力:
评论