
目标检测新技能!引入知识图谱:Reasoning-RCNN
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

如下图a中的右上角部分,有一个模糊的白色的物体,我们人的思维方式就是去思考:首先它很像一个CCTV(也就是闭路是摄像机),我们之前在b图中看到过。其次再观察他的周围,是马路,车,一个小的金属设备在监视着着车,所以他应该就是一个CCTV。B图中展示了其对象之间的图谱关系,这个就可以放到知识图谱里面去并且合并到detection
pipline中。

章节目录
知识图谱引入
实验部分
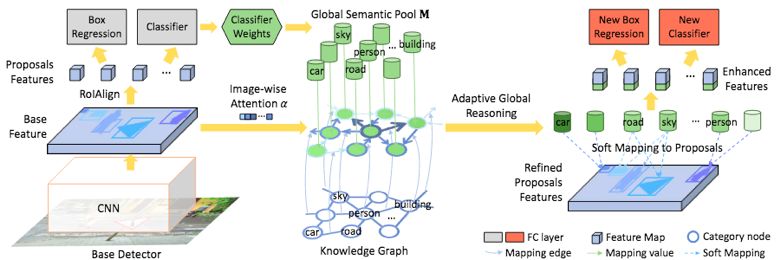
那么Reasoning RCNN具体是怎么做的呢?首先,这篇文章实际上不是提出了一个新的检测方法,而是对传统检测做一个增强,具体如下图。
概括来说:首先就需要建立一个对于所有类别的一个语义池 semantic
pool,他们之间的权重是来自于传统目标检测的的网络的分类层。随后需要一个类别级别的知识图谱去编码存在的语义知识。(主要是属性,关系),在这个知识谱图中进行演化和传播。最后要做的就是特征的增强,这里的增强在检测中就是对分类特征的增强,每个区域新增强的特征被concat到原始的特征,来提升classification和localization的性能。
Reasoning RCNN可以基于任意base detector 比如Faster RCNN.
box,这个分类器产生的权重将会生成前面提到的global semantic
pool,(分类器关于每个类别的权重实际上包含了高层次的语义信息,因为在训练这个分类器的时候,其是整个图片进行了参与,分类器的参数不断更新,global
pool也不断被训练),然后知识图谱被引入,并将其输入到自适应推理模块。通过refine的模块去产生一个增强的特征。这个增强的模块是通过拼接而形成的。图中是蓝色与绿色。
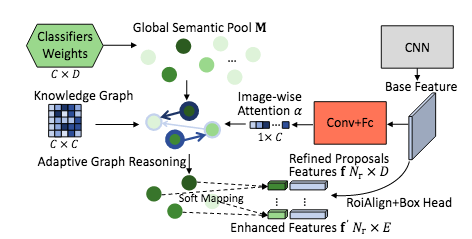
自适应attention是使用image feature来计算的,以自动发现最相关的类别以进行自适应推理,具体如下图,其实就是通过softmax
function得到。从categories到proposal对增强功能进行软映射,以获得区域性增强功能f’,最终对得到的增强特征与原始特征连接在一起。作为新的特征去送往网络产生新的结果。

如下表中可以看到在base detector不同的时候,此方法带来了很多的性能提升。
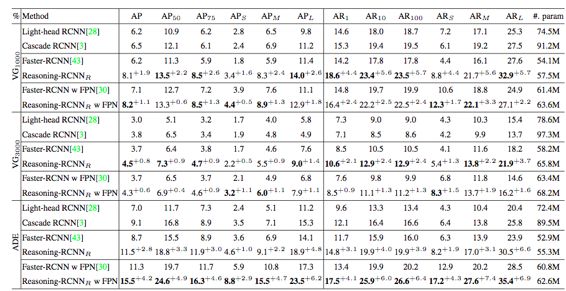
下表可以看出来在小样本上的增益是最大的,也进一步证明了作者提出的方法的有效性。
下图是fastaer rcnn和加入此方法之后的可视化对比,可以看到检测效果有很多提升,少了很多漏检问题,因此也是从一方面展示了此方法检测的优越性。


END
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~