
京东智能客服言犀启发式问答技术揭秘
文章作者:邹波、宋双永、孙博秋
1. 背景介绍
2. 落地情况
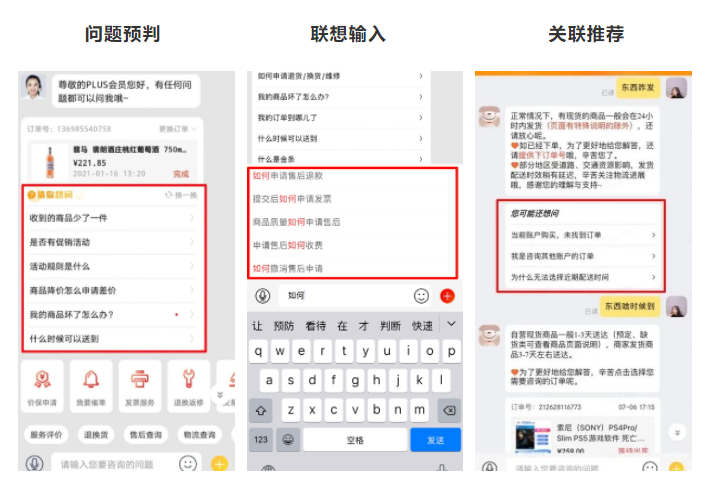
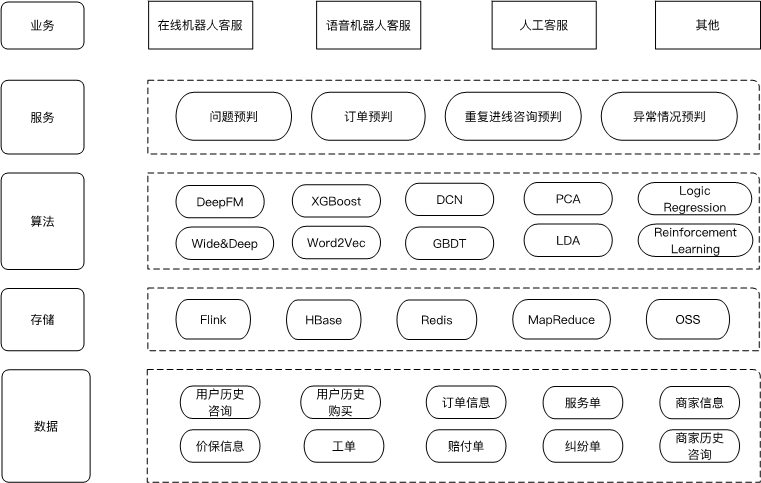
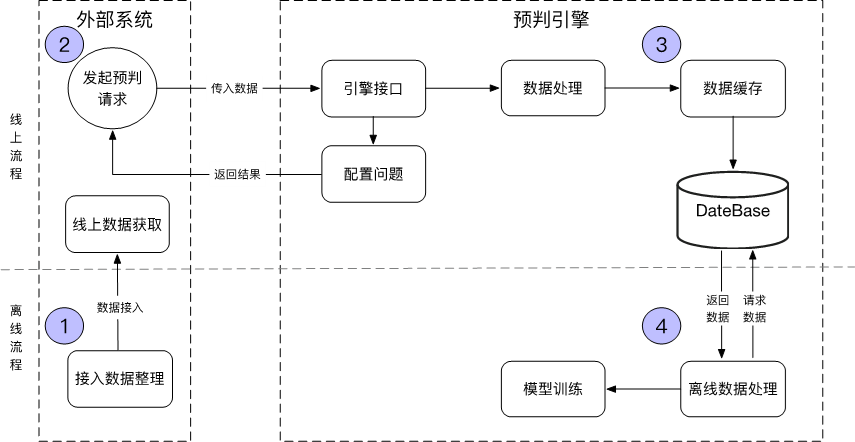
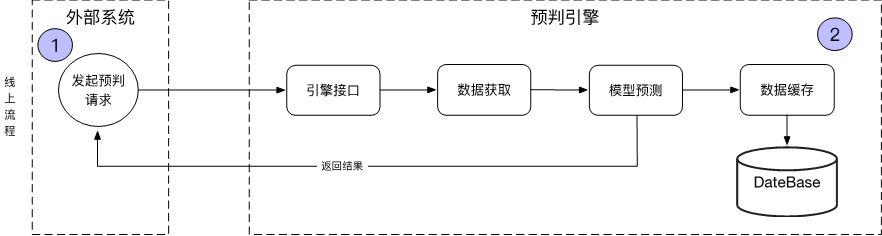
3. 算法技术介绍
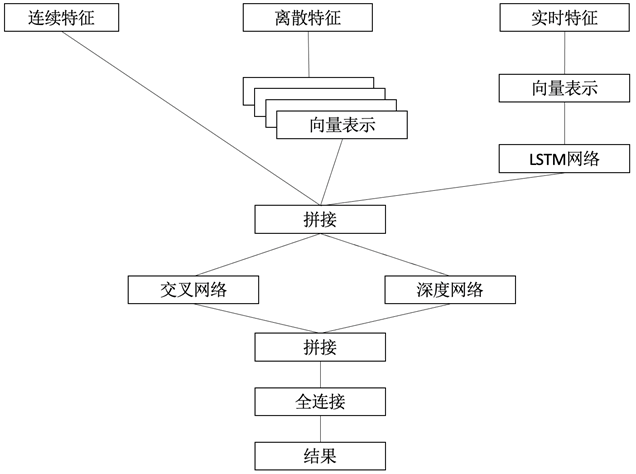
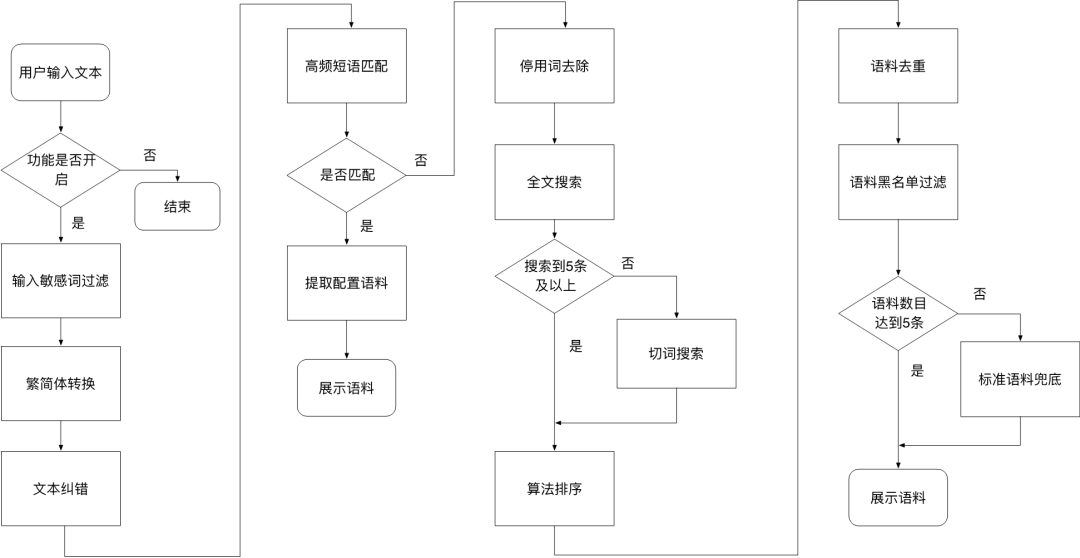
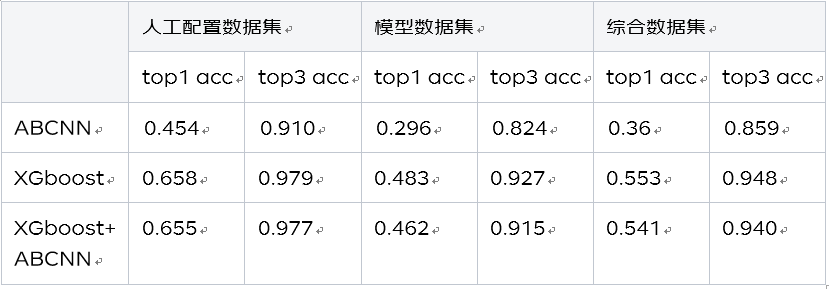
实验一:仅用文本特征+统计特征,作为baseline 实验二:直接增加意图特征,用于排序模型 实验三:不直接使用意图特征,而是建立基于prefix的意图预测模型,将预测的prefix意图用于排序模型
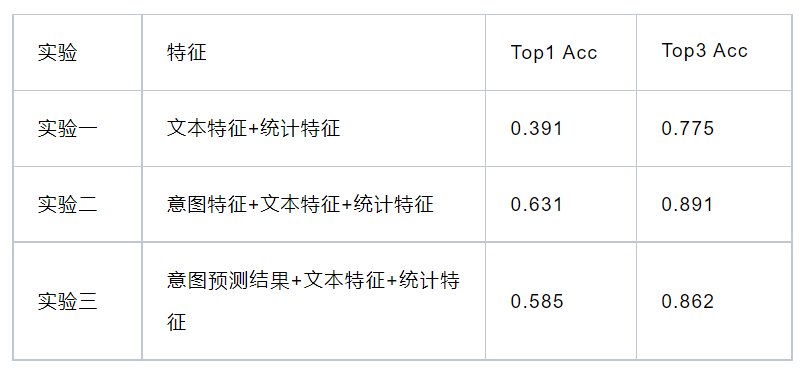
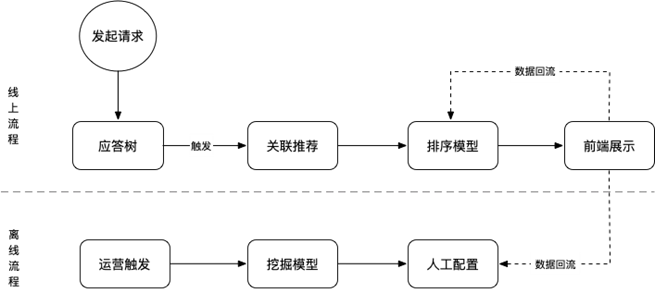
运营触发:运营判断该答案节点需要配置关联推荐问题,触发关联推荐离线问题挖掘流程 挖掘模型:自动挖掘关联推荐问题,供运营同学配置关联问题参考。 人工配置:基于挖掘结果,人工选择性的配置关联问题到系统中 数据回流:前端点击数据,可以返回给人工配置模块,供运营参考并调整配置
应答树:用户请求经过机器人的意图识别和应答模块,已定位到具体的答案节点 关联推荐:该答案节点配置有关联问题推荐,根据已配置的内容出关联问题 排序模型:基于配置的关联问题,模型重新进行排序,给出最终的推荐问题供前端展示。可参考用户订单、当前意图、用户历史点击等信息,建立排序模型。 数据回流:用户点击信息,可以回流用于线上排序模型的建模 离线挖掘模型
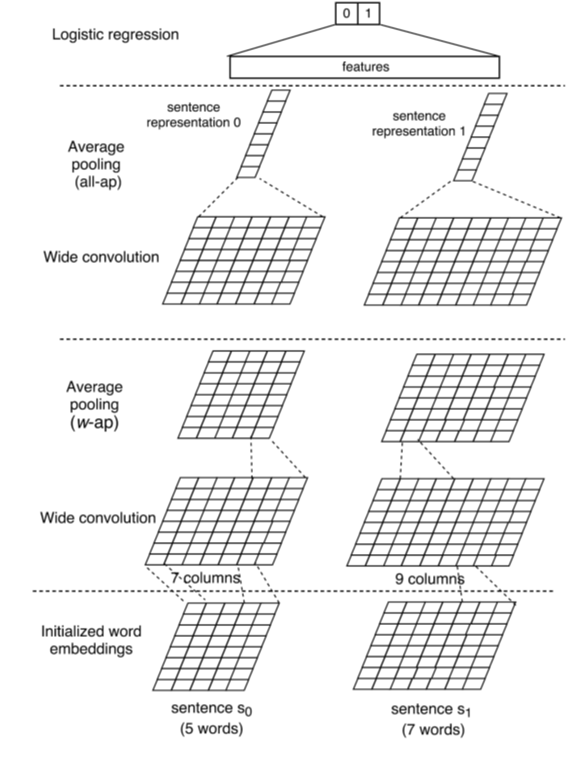
4. 未来提升空间
评论