
微信搜一搜中的智能问答技术

本文约7600字,建议阅读15分钟
本文给大家介绍微信搜一搜中的智能问答技术。

背景介绍 基于图谱的问答 基于文档的问答 未来展望


基于图谱的问答事实型query,答案形式是实体短语类的短答案。例如“刘德华的妻子”,或者实体集合“中国四大名著”,还有时间/数字等。 第二类是观点型query,答案形式是“是或否”,例如像“高铁可以逃票吗”等。 第三类是摘要型query,不同于前两类短答案,答案可能需要用长句的摘要来回答,通常是“为什么”、“怎么办”、“怎么做”等问题。 最后一类是列表型query,通常是流程、步骤相关的问题,答案需要用列表做精确的回答。

结构化数据,来源于百科、豆瓣等垂类网站的infobox。优点是质量高,便于获取和加工;缺点是只覆盖头部知识,覆盖率不够。例如“易建联的身高”、“无间道1的导演是谁”。 非结构化的通用文本,来源于百科、公众号等互联网网页文本库。优点是覆盖面广,但缺点在于文本质量参差不齐,对医疗、法律等专业领域知识的覆盖度和权威度不够。 非结构化的专业垂类网站问答库,来源于专业领域垂类站点的问答数据,通常以问答对的形式存在。优点是在专业领域知识覆盖广、权威度高。
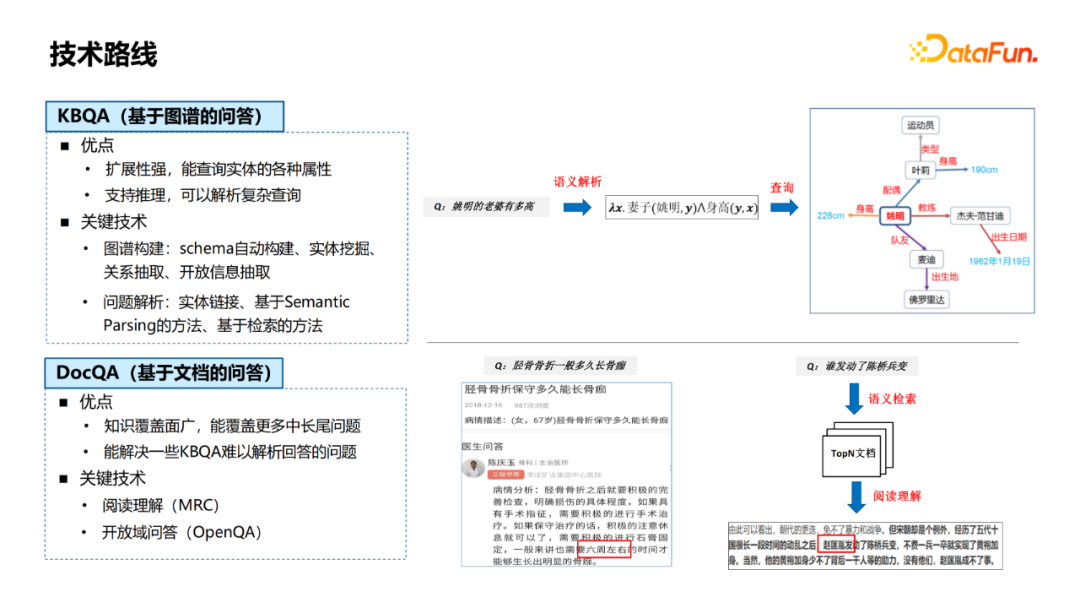
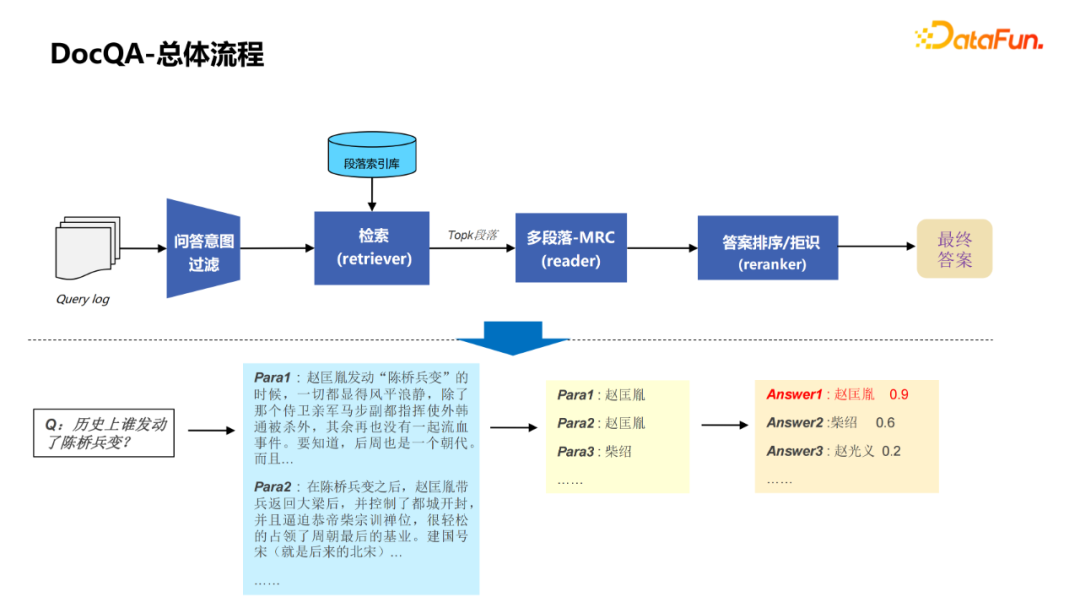
KBQA的优点是扩展性强,能查询实体的各种属性,同时支持推理,可以解析复杂查询。例如图中右边的一个例子,“姚明的老婆有多高”可以解析得到中间的语义表达式,从而转换成知识图谱的查询,得到问题的答案。涉及的关键技术是图谱构建(包括schema构建、实体挖掘、关系抽取、开放信息抽取技术)和问题解析(包括实体链接、基于semantic parsing的问题解析方法、基于检索的问题解析方法等技术)。 DocQA相较于KBQA的优点是覆盖面更广,能覆盖更多中长尾的问题,同时能解决一些KBQA难以解析的问题。例如,“中国历史上第一个不平等条约”这个query,很难解析成结构化的表达,涉及到的技术主要包括阅读理解(MRC)、开放域问答(OpenQA)。
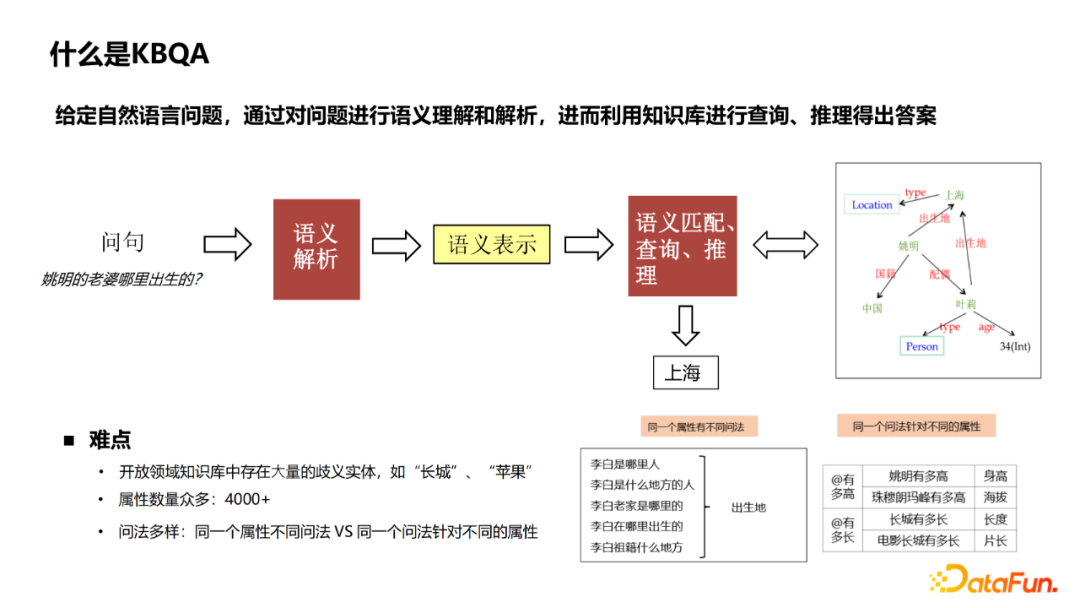
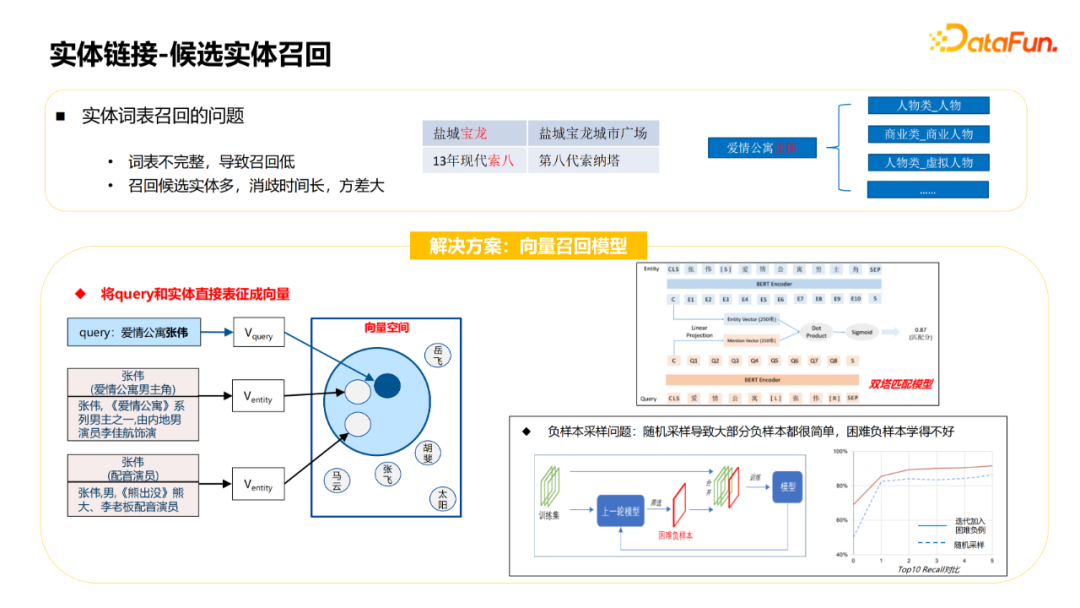
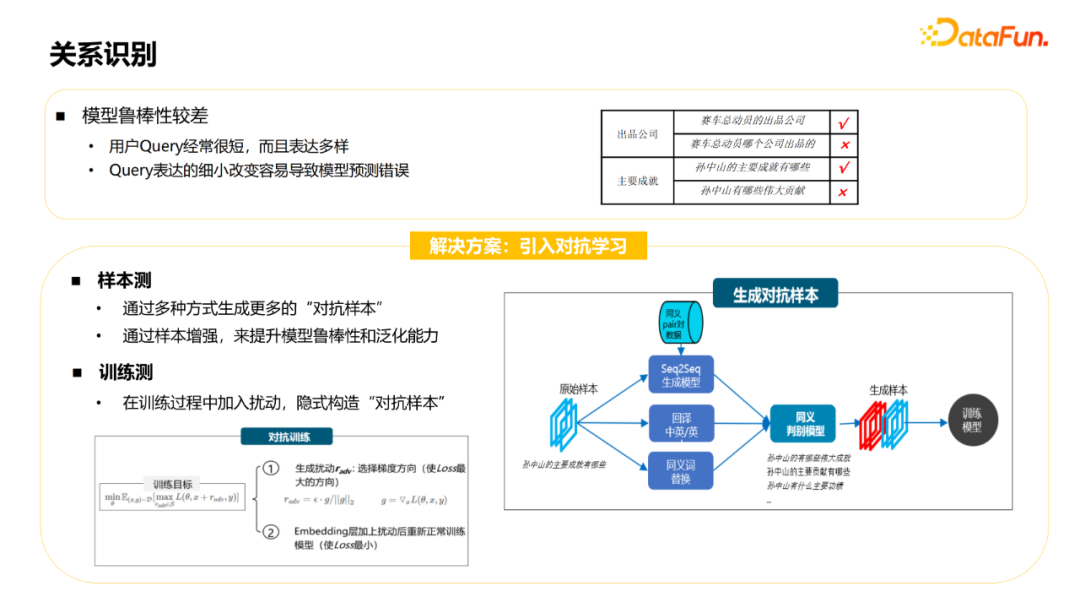
开放领域知识库中存在大量的歧义实体,例如“长城”、“苹果”,可能在知识库中存在多种类型的同名实体。从query中识别出正确的实体是整个KBQA中一个比较关键的模块。 开放域的知识图谱属性众多,需要从4000+属性中识别出正确的属性。 自然语言的问法多样,同一个属性有不同问法,例如询问李白的出生地,可以有“李白是哪里人”、“李白老家是哪里的”等多种不同的表达。同一个问法也可能针对不同的属性,例如“姚明有多高”、“珠穆朗玛峰有多高”,同样是“有多高”,但询问属性分别是身高和海拔。

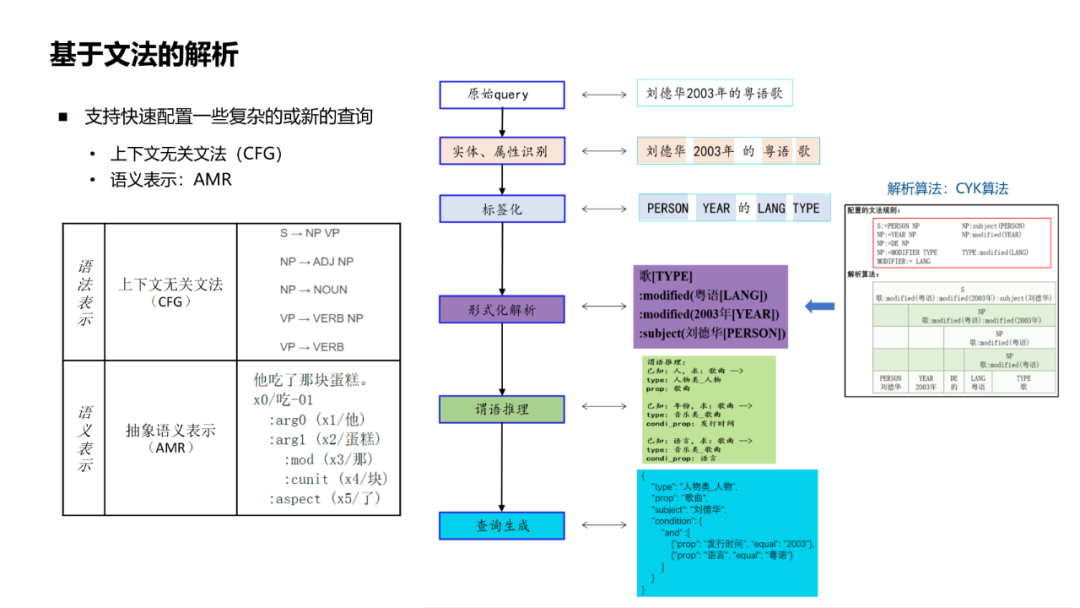
方案一:检索式的方法。把query和候选答案(知识图谱中的候选节点)表征为向量计算相似度。优点是可以进行端到端的训练,但可解释性和可扩展性差,难以处理限定、聚合等复杂类型的query。 方案二:基于解析的方法。把query解析成可查询的结构化表示,然后去知识图谱中查询。这种方法的优点是可解释性强,符合人能理解的图谱显示推理过程,但依赖高质量的解析算法。综合考虑优缺点,我们在实际工作中主要采用的是这种方法。
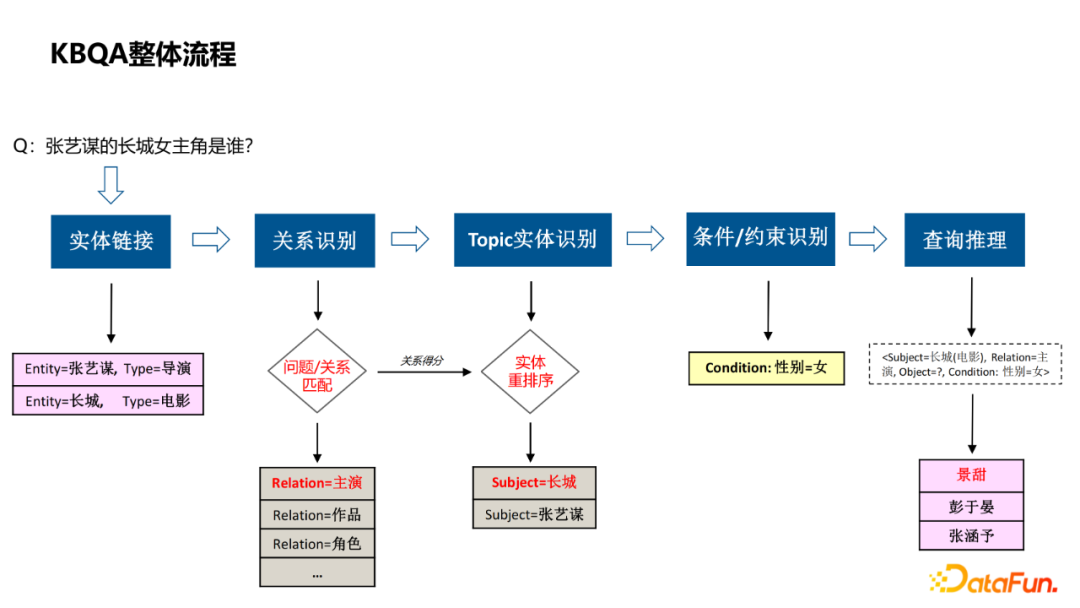
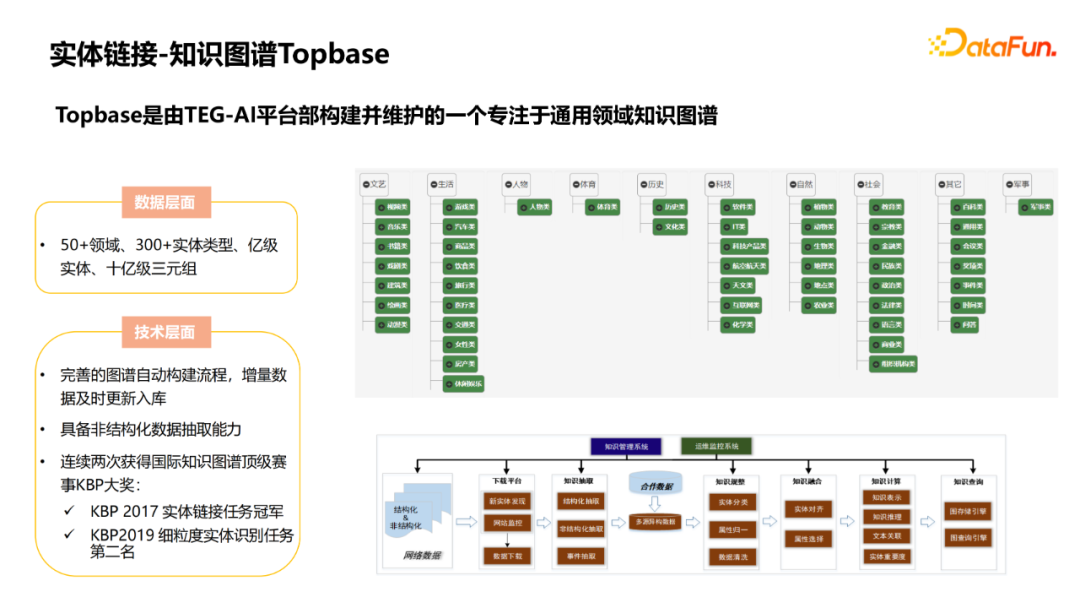
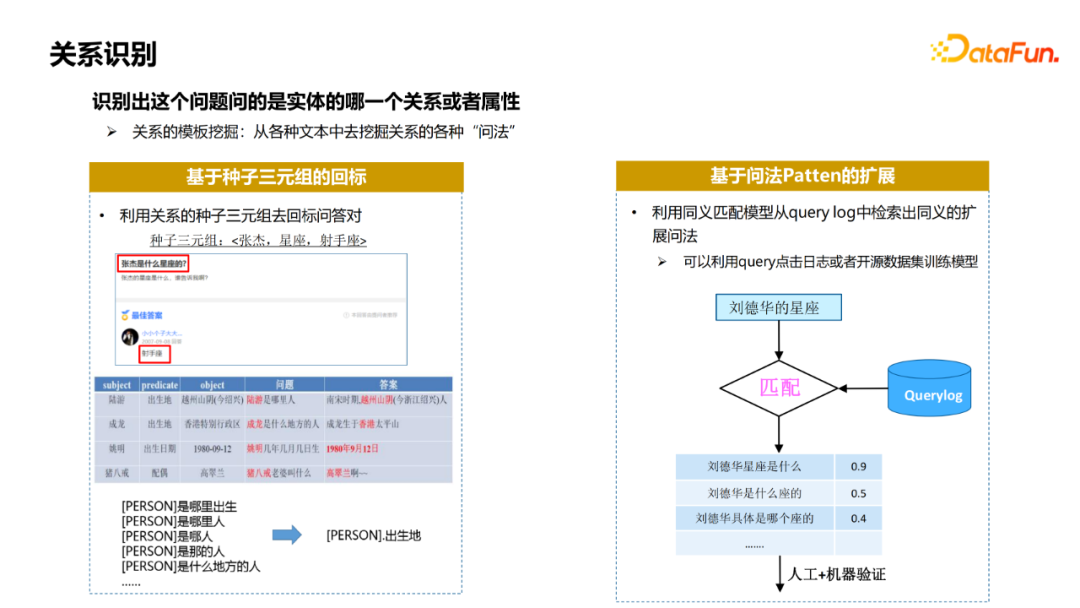
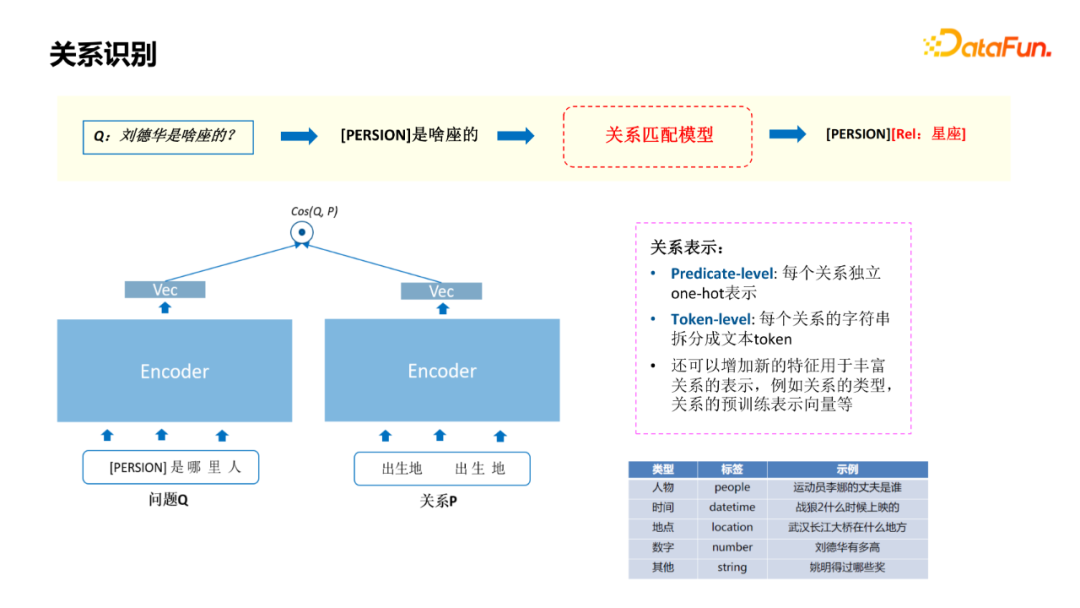
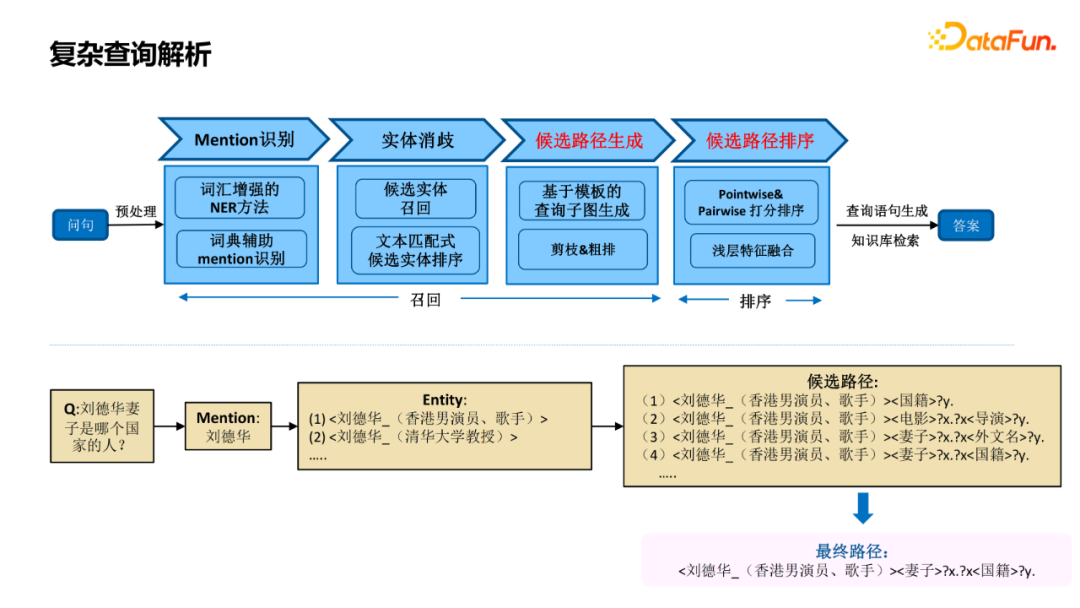
实体链接,识别出query中的实体,并关联到图谱中的节点; 关系识别,query询问的具体属性; Topic实体识别,当query涉及到多个实体时,判断哪个实体是问题的主实体; 条件/约束识别,解析query中涉及到的一些约束条件; 查询推理,将前几步的结果组合成查询推理的语句,通过知识图谱获得答案。


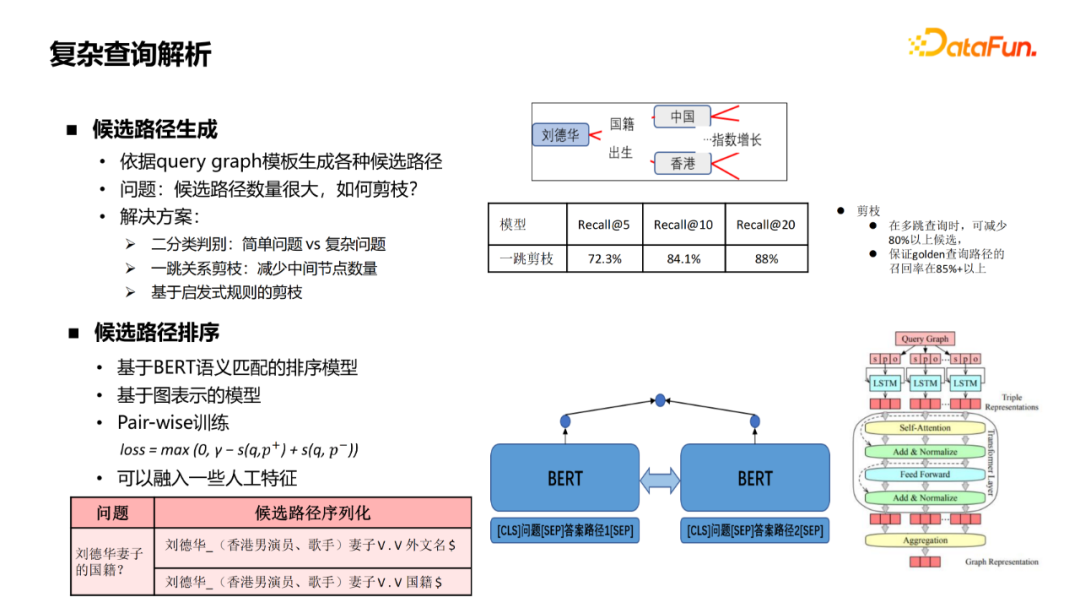
二分类判别:简单问题还是复杂问题 一跳关系剪枝:减少中间节点数量 基于启发式规则剪枝


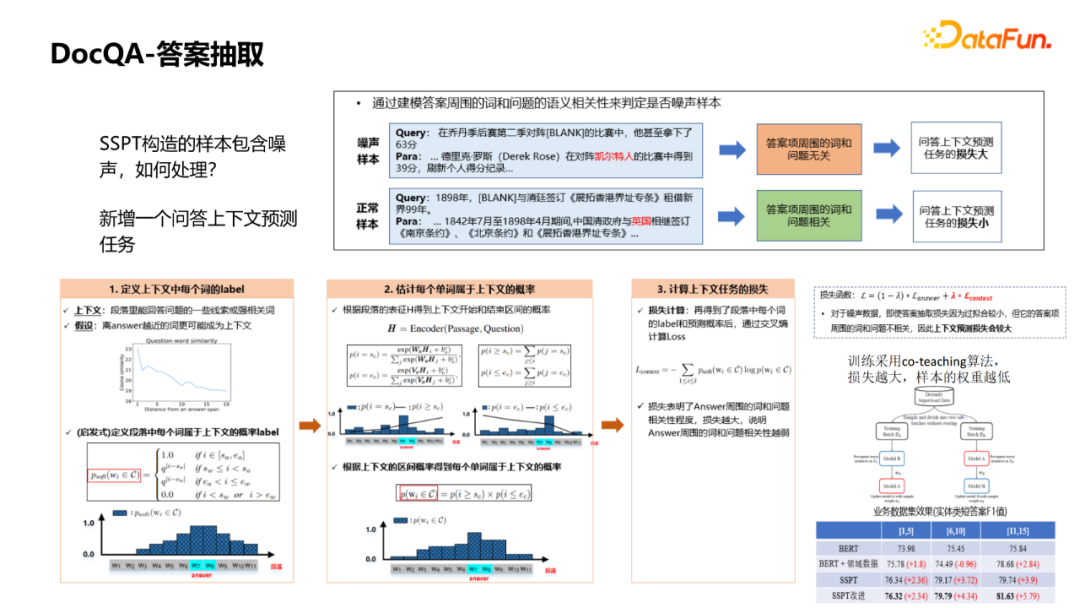

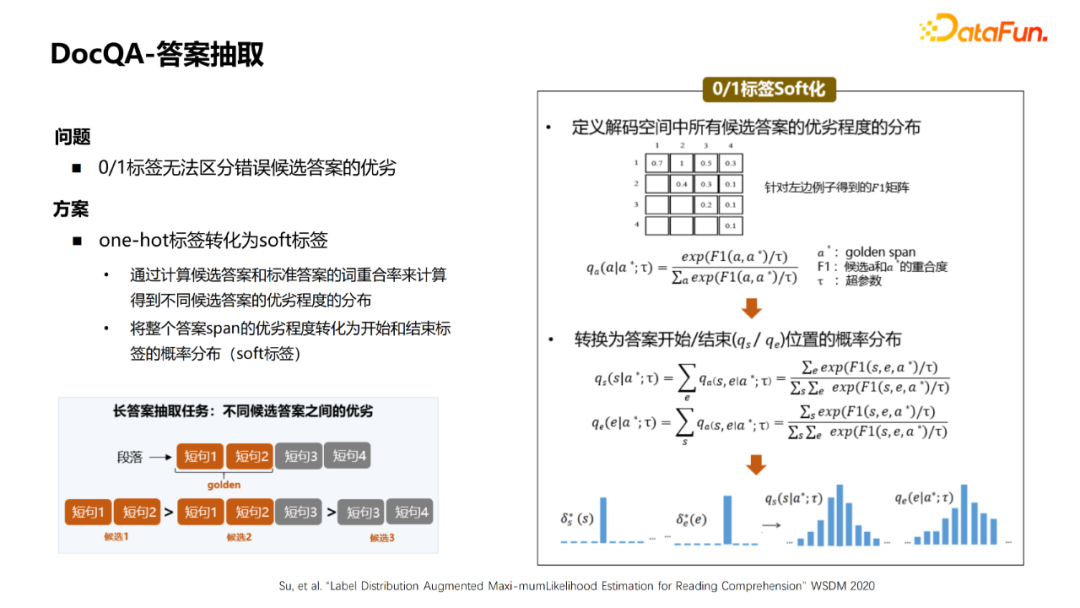

编辑:王菁
校对:林亦霖
评论